在数据日益密集的当下,我们总在寻求更高效、更智能的数据分析工具。随着大语言模型(LLM)的兴起,如何将这些前沿的 AI 能力与日常的数据分析工作相结合,已然成为一个极具探索价值的方向。
基于此,我们在 Apache Doris 4.0 版本中实现了一系列 LLM 函数。这使得数据分析能够凭借简洁的 SQL 语句,直接调用大语言模型开展文本处理工作。无论是从文本中精准提取重要信息,还是对评论进行细致的情感分类,亦或生成精炼的文本摘要,皆可在数据库内部无缝完成。
应用场景
在即将发布的 4.0 版本中,Apache Doris LLM 函数可应用的场景包括但不限于:
- 智能反馈:自动识别用户意图、情感。
- 内容审核:批量检测并处理敏感信息,保障合规。
- 用户洞察:自动分类、摘要用户反馈。
- 数据治理:智能纠错、提取关键信息,提升数据质量。
所有大语言模型必须在 Doris 外部提供,并且支持文本分析。此外,所有 LLM 函数调用结果和成本取决于外部 LLM 供应商及其所使用的模型。
函数支持
- LLM_CLASSIFY:在给定的标签中提取与文本内容匹配度最高的单个标签字符串。
- LLM_EXTRACT:根据文本内容,为每个给定标签提取相关信息。
- LLM_FILTER : 判断文本内容是否正确,返回值为
bool类型。 - LLM_FIXGRAMMAR:修复文本中的语法、拼写错误。
- LLM_GENERATE:基于参数内容生成内容。
- LLM_MASK : 根据标签,将原文中的敏感信息用
[MASKED]进行替换处理。 - LLM_SENTIMENT :分析文本情感倾向,返回值为
positive、negative、neutral、mixed其中之一。 - LLM_SIMILARITY:判断两文本的语义相似度,返回值为 0 - 10 之间的浮点数,值越大代表语义越相似。
- LLM_SUMMARIZE:对文本进行高度总结概括。
- LLM_TRANSLATE:将文本翻译为指定语言。
LLM 配置相关参数
Doris 通过资源机制对 LLM API 的访问进行集中管理,旨在确保密钥安全与权限可控。目前可选择的参数如下:
type: 必填,且必须为llm,作为 llm 的类型标识。llm.provider_type: 必填,外部 LLM 厂商类型。llm.endpoint: 必填,LLM API 接口地址。llm.model_name: 必填,模型名称。llm_api_key: 除llm.provider_type = local的情况外必填,API 密钥。llm.temperature: 可选,控制生成内容的随机性,取值范围为 0 到 1 的浮点数。默认值为 -1,表示不设置该参数。llm.max_tokens: 可选,限制生成内容的最大 token 数。默认值为 -1,表示不设置该参数。Anthropic 默认值为 2048。llm.max_retries: 可选,单次请求的最大重试次数。默认值为 3。llm.retry_delay_second: 可选,重试的延迟时间(秒)。默认值为 0。
厂商支持
目前直接支持的厂商有:OpenAI、Anthropic、Gemini、DeepSeek、Local(Ollama 等)、MoonShot、MiniMax、Zhipu、Qwen、Baichuan。
若有不在上列的厂商,但其 API 格式与 OpenAI/Anthropic/Gemini 相同的,在填入参数 llm.provider_type 时可直接选择三者中格式相同的厂商。原因是厂商选择只影响 Doris 内部所构建的 API 格式。
快速上手
为了帮助用户尽快上手,我们准备了一些示例 Demo,以下示例均为最小实现:
01 配置 LLM 资源
示例一:
SQL
CREATE RESOURCE 'openai_example'
PROPERTIES (
'type' = 'llm',
'llm.provider_type' = 'openai',
'llm.endpoint' = 'https://api.openai.com/v1/responses',
'llm.model_name' = 'gpt-4.1',
'llm.api_key' = 'xxxxx'
);示例二:
SQL
CREATE RESOURCE 'deepseek_example'
PROPERTIES (
'type'='llm',
'llm.provider_type'='deepseek',
'llm.endpoint'='https://api.deepseek.com/chat/completions',
'llm.model_name' = 'deepseek-chat',
'llm.api_key' = 'xxxxx'
);02 设置默认资源(可选)
SQL
SET default_llm_resource='llm_resource_name';03 执行 SQL 查询
case1:
假设存在如下数据表,表中存储了与数据库相关的文档内容:
SQL
CREATE TABLE doc_pool (
id BIGINT,
c TEXT
) DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 10
PROPERTIES (
"replication_num" = "1"
);若需筛选与 Doris 相关性最高的 10 条记录,可采用如下查询:
SQL
SELECT
c,
CAST(LLM_GENERATE(CONCAT('Please score the relevance of the following document content to Apache Doris, with a floating-point number from 0 to 10, output only the score. Document:', c)) AS DOUBLE) AS score
FROM doc_pool
ORDER BY score DESC
LIMIT 10;该查询将利用 LLM 生成每条文档内容与 Apache Doris 的相关性评分,并按得分降序筛选前 10 条结果。
Plain
+---------------------------------------------------------------------------------------------------------------+-------+
| c | score |
+---------------------------------------------------------------------------------------------------------------+-------+
| Apache Doris is a lightning-fast MPP analytical database that supports sub-second multidimensional analytics. | 9.5 |
| In Doris, materialized views can automatically route queries, saving significant compute resources. | 9.2 |
| Doris's vectorized execution engine boosts aggregation query performance by 5--10×. | 9.2 |
| Apache Doris Stream Load supports second-level real-time data ingestion. | 9.2 |
| Doris cost-based optimizer (CBO) generates better distributed execution plans. | 8.5 |
| Enabling the Doris Pipeline execution engine noticeably improves CPU utilization. | 8.5 |
| Doris supports Hive external tables for federated queries without moving data. | 8.5 |
| Doris Light Schema Change lets you add or drop columns instantly. | 8.5 |
| Doris AUTO BUCKET automatically scales bucket count with data volume. | 8.5 |
| Using Doris inverted indexes enables second-level log searching. | 8.5 |
+---------------------------------------------------------------------------------------------------------------+-------+case2:
该表模拟招聘场景的候选人简历和职业要求:
SQL
CREATE TABLE candidate_profiles (
candidate_id INT,
name VARCHAR(50),
self_intro VARCHAR(500)
)
DUPLICATE KEY(candidate_id)
DISTRIBUTED BY HASH(candidate_id) BUCKETS 1
PROPERTIES (
"replication_num" = "1"
);
CREATE TABLE job_requirements (
job_id INT,
title VARCHAR(100),
jd_text VARCHAR(500)
)
DUPLICATE KEY(job_id)
DISTRIBUTED BY HASH(job_id) BUCKETS 1
PROPERTIES (
"replication_num" = "1"
);
INSERT INTO candidate_profiles VALUES
(1, 'Alice', 'I am a senior backend engineer with 7 years of experience in Java, Spring Cloud and high-concurrency systems.'),
(2, 'Bob', 'Frontend developer focusing on React, TypeScript and performance optimization for e-commerce sites.'),
(3, 'Cathy', 'Data scientist specializing in NLP, large language models and recommendation systems.');
INSERT INTO job_requirements VALUES
(101, 'Backend Engineer', 'Looking for a senior backend engineer with deep Java expertise and experience designing distributed systems.'),
(102, 'ML Engineer', 'Seeking a data scientist or ML engineer familiar with NLP and large language models.');可以通过 LLM_FILTER 将职业要求和候选人简介进行语义匹配,快速筛选出合适的候选人。
SQL
SELECT
c.candidate_id, c.name,
j.job_id, j.title
FROM candidate_profiles AS c
JOIN job_requirements AS j
WHERE LLM_FILTER(CONCAT('Does the following candidate self-introduction match the job description?',
'Job: ', j.jd_text, ' Candidate: ', c.self_intro));输出结果参考:
Plain
+--------------+-------+--------+------------------+
| candidate_id | name | job_id | title |
+--------------+-------+--------+------------------+
| 3 | Cathy | 102 | ML Engineer |
| 1 | Alice | 101 | Backend Engineer |
+--------------+-------+--------+------------------+case3:
该表模拟保险公司的理赔申请数据
SQL
CREATE TABLE claims (
claim_id INT COMMENT '索赔编号',
policy_id INT COMMENT '保单编号',
claim_date DATE COMMENT '索赔日期',
incident_description VARCHAR(1000) COMMENT '事故描述'
) DUPLICATE KEY(claim_id)
DISTRIBUTED BY HASH(claim_id) BUCKETS 5
PROPERTIES (
"replication_num" = "1"
);
CREATE TABLE policies (
policy_id INT COMMENT '保单编号',
policy_type VARCHAR(50) COMMENT '保单类型',
insured_item VARCHAR(255) COMMENT '承保物品/对象'
) DUPLICATE KEY(policy_id)
DISTRIBUTED BY HASH(policy_id) BUCKETS 5
PROPERTIES (
"replication_num" = "1"
);
INSERT INTO claims VALUES
(1, 101, '2025-08-18', '昨天下午三点左右,我在东三环辅路开车时,与前车发生了追尾。'),
(2, 102, '2025-08-18', '上周五在公司楼下,我不小心扭伤了脚踝,需要理赔医疗费用。'),
(3, 103, '2025-08-18', '8月17日夜里家中管道破裂,导致部分家具被水浸泡。'),
(4, 104, '2025-08-18', '晚上喝酒后开车回家与其他车辆发生了碰撞。'),
(5, 105, '2025-08-18', '早上8点,在去上班的路上,发现车辆停放时被刮擦。');
INSERT INTO policies VALUES
(101, '车险', '宝马 X5'),
(102, '健康险', '个人意外险'),
(103, '家财险', '住宅房屋'),
(104, '车险', '丰田 凯美瑞'),
(105, '车险', '奥迪 A8');可以利用 LLM_CLASSIFY 函数对事件性质进行智能分类,并通过 LLM_FILTER 函数对事件进行有效性校验,以筛选出符合理赔标准的有效事件。
SQL
SELECT
c.claim_id,
c.incident_description,
llm_classify(c.incident_description, ['交通事故', '人身意外', '财产损失', '其他']) AS incident_category
FROM claims AS c
JOIN policies AS p ON c.policy_id = p.policy_id
WHERE
p.policy_type = '车险' AND LLM_FILTER(CONCAT('下列情形是否支持保险赔偿:', c.incident_description));输出结果参考:
Plain
+----------+-----------------------------------------------------------------------------------------+-------------------+
| claim_id | incident_description | incident_category |
+----------+-----------------------------------------------------------------------------------------+-------------------+
| 1 | 昨天下午三点左右,我在东三环辅路开车时,与前车发生了追尾。 | 交通事故 |
| 5 | 早上8点,在去上班的路上,发现车辆停放时被刮擦。 | 财产损失 |
+----------+-----------------------------------------------------------------------------------------+-------------------+设计原理
01 函数执行流程
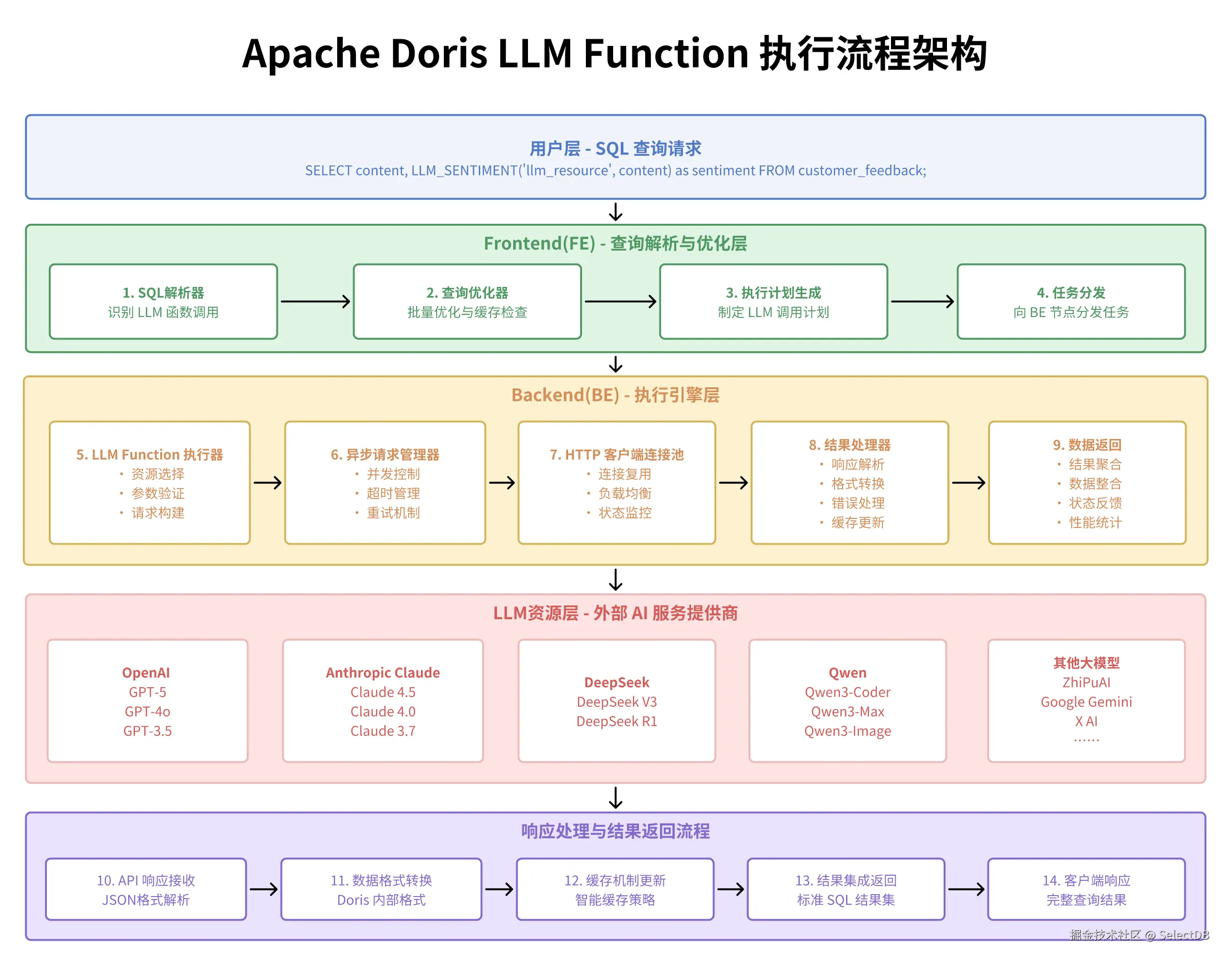
02 资源化管理
Doris 将 LLM 能力抽象为资源(Resource),统一管理各种大模型服务(如 OpenAI、DeepSeek、Moonshot、本地模型等)。每个资源都包含了厂商、模型类型、API Key、Endpoint 等关键信息,简化了多模型、多环境的接入和切换,同时也保证了密钥安全和权限可控。
03 兼容主流大模型
由于厂商之间的 API 格式存在差异,Doris 为每种服务都实现了请求构造、鉴权、响应解析等核心方法,让 Doris 能够根据资源配置,动态选择合适的实现,无需关心底层 API 的差异。用户只需声明提供厂商,Doris 就能自动完成不同大模型服务的对接和调用。
总结
Apache Doris 4.0 的 LLM 函数为数据分析与智能应用场景注入了强大的能力,覆盖智能反馈、内容审核、用户洞察和数据治理等多领域需求。通过灵活的资源化管理和对主流大模型(如 OpenAI、Anthropic、DeepSeek 等)的广泛兼容,Doris 提供了一站式的智能分析解决方案,极大简化了复杂模型的接入与使用流程。无论是高效的语义匹配、情感分析,还是自动化内容生成与数据优化,Doris LLM 函数都能以高性能、低成本的方式助力企业释放数据潜能。
现在就行动!
参与 Apache Doris 4.0 内测,体验 "SQL +AI" 的颠覆性组合,让数据分析从"被动查询"迈向"主动洞察"。