 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
- 引言
- ByteGraph现有架构
-
- 阿里云Lindorm
- 腾讯YottaDB
- 多模型化修改点
- ByteGraph论文中的优化点概述
-
- [Dynamic Thread Pools](#Dynamic Thread Pools)
- [Adaptive Secondary Edge-Trees](#Adaptive Secondary Edge-Trees)
- [Space Optimized Bw-tree Forest](#Space Optimized Bw-tree Forest)
- [Read Optimized Bw-tree / Workload-Aware Space Reclamation](#Read Optimized Bw-tree / Workload-Aware Space Reclamation)
- [I/O Efficient Synchronization Mechanism](#I/O Efficient Synchronization Mechanism)
- 结束语
引言
学习友商优点始终是审视自身的最好方法。ByteGraph不愧是业界著名的图数据库团队,vldb2022的《ByteGraph: A High-Performance Distributed Graph Database in ByteDance》和 sigmod2024的《BG3: A Cost Effective and I/O Efficient Graph Database in ByteDance》可以看出其扎实的工程能力,也同时为我们展现了ByteGraph的基本架构方法和一些细节的优化手段,相关经验对同领域从业人员有不小的启发。
《ByteGraph: A High-Performance Distributed Graph Database in ByteDance》阐述了ByteGraph的计算,内存,存储三级分离方案;而《BG3: A Cost Effective and I/O Efficient Graph Database in ByteDance》则通过改进BGS的BW树实现和利用贴合业务的使用方式提升访问性能和减少IO放大,以及改进读写节点和只读节点的数据同步方法入手阐述优化方案;
本篇文章简单阐述两篇论文中的细节优化点,而后从架构入手对比现有部分时序数据库,多模数据库的架构,讨论其通用性,并探讨其扩展至多模数据库的可能性。
当然ByteGraph作为大规模工业级图数据库,自然没有必要强转为多模型数据库,这个论题事实上也是在看多模数据库如果要实现一个图模态是否需要大规模的人力消耗。
ByteGraph现有架构
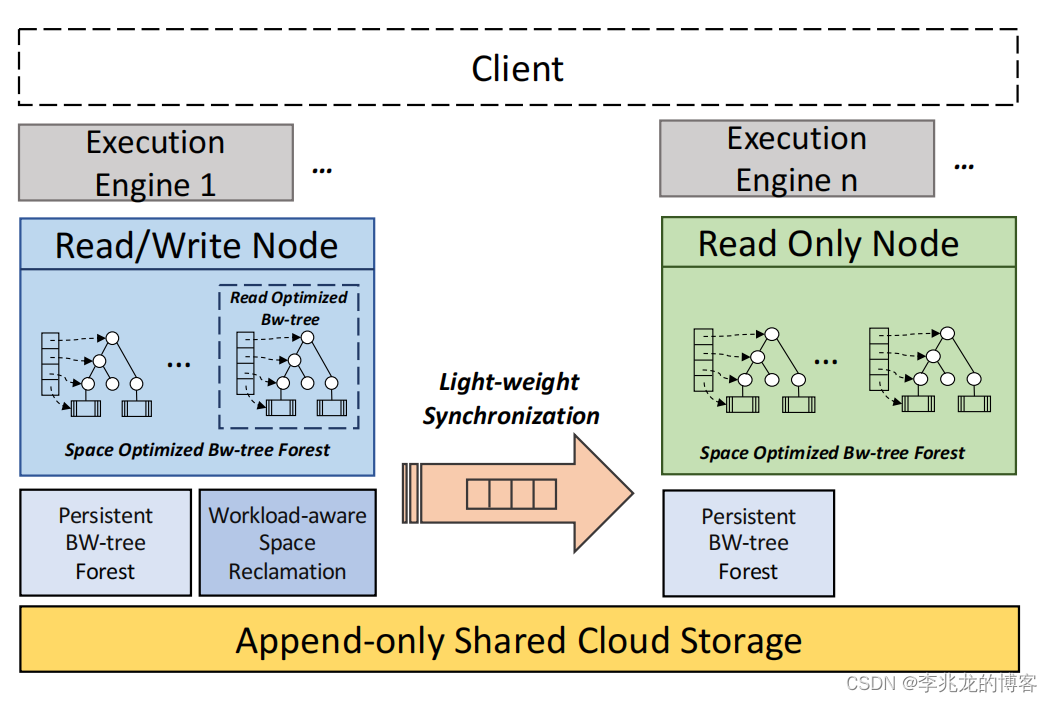
非常经典的计算,内存,存储三级分离方案;
ByteGraph的核心设计原则为:
- 存算分离:不同的工作负载对不同的资源有不同的利用率
- 使用缓存加速查询,并提高缓存命中率
- 高扩展性:需要应对爆炸性的增长,毕竟抖音/tiktok这种应用可能部分视频存在短时间千万级别的点赞/评论/转发等
- 平衡读写放大,获取整体最佳性能
事实上当今的nosql的架构非常相似,这也是为什么多模数据库人效比如此之高的原因,各个功能模块的组织和引擎的定制优化才是各个系统之间关键的对比点。
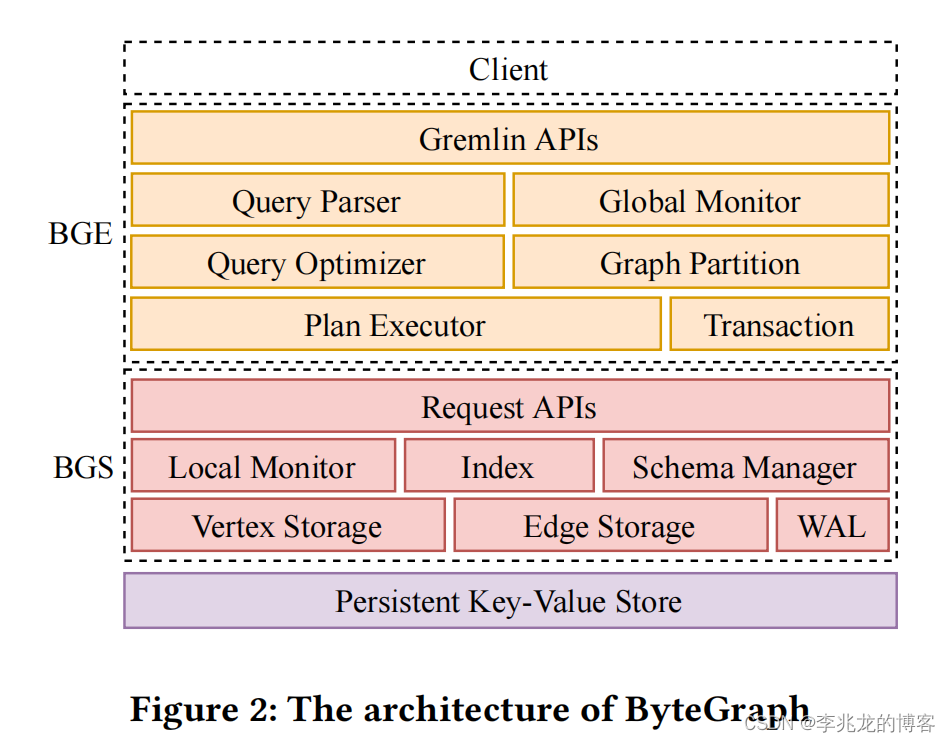
BGE:
- BGS的路由
- 查询解析,逻辑计划构建,查询优化,执行计划构建
- 执行计划执行
- 事务
BGS:
- 边,点,索引存储
- 构建存储格式,执行持久化至持久化存储层
- wal
Persistent Store
- 持久化存储
阿里云Lindorm
其实对比阿里云Lindorm的顶层架构:

可以发现基本架构完全相同,但是细节实现存在差异。
| Lindorm | ByteGraph | |
|---|---|---|
| 计算层/BGE | 多写入协议,统一sql支持,分布式计算引擎,AI引擎 | Gremlin协议,本地计算引擎 |
| 数据引擎层/BGS | 多种模态定制化存储引擎 | 缓存+图模态定制化存储引擎 |
| 存储层/Persistent Store | 统一访问协议分布式文件系统,存储介质可变,保证持久性 | KV Store |
从这里就可以看出,ByteGraph可以认为是高度优化的图数据库,但是想从当前架构转为多模型数据库需要的工作较多。
腾讯YottaDB
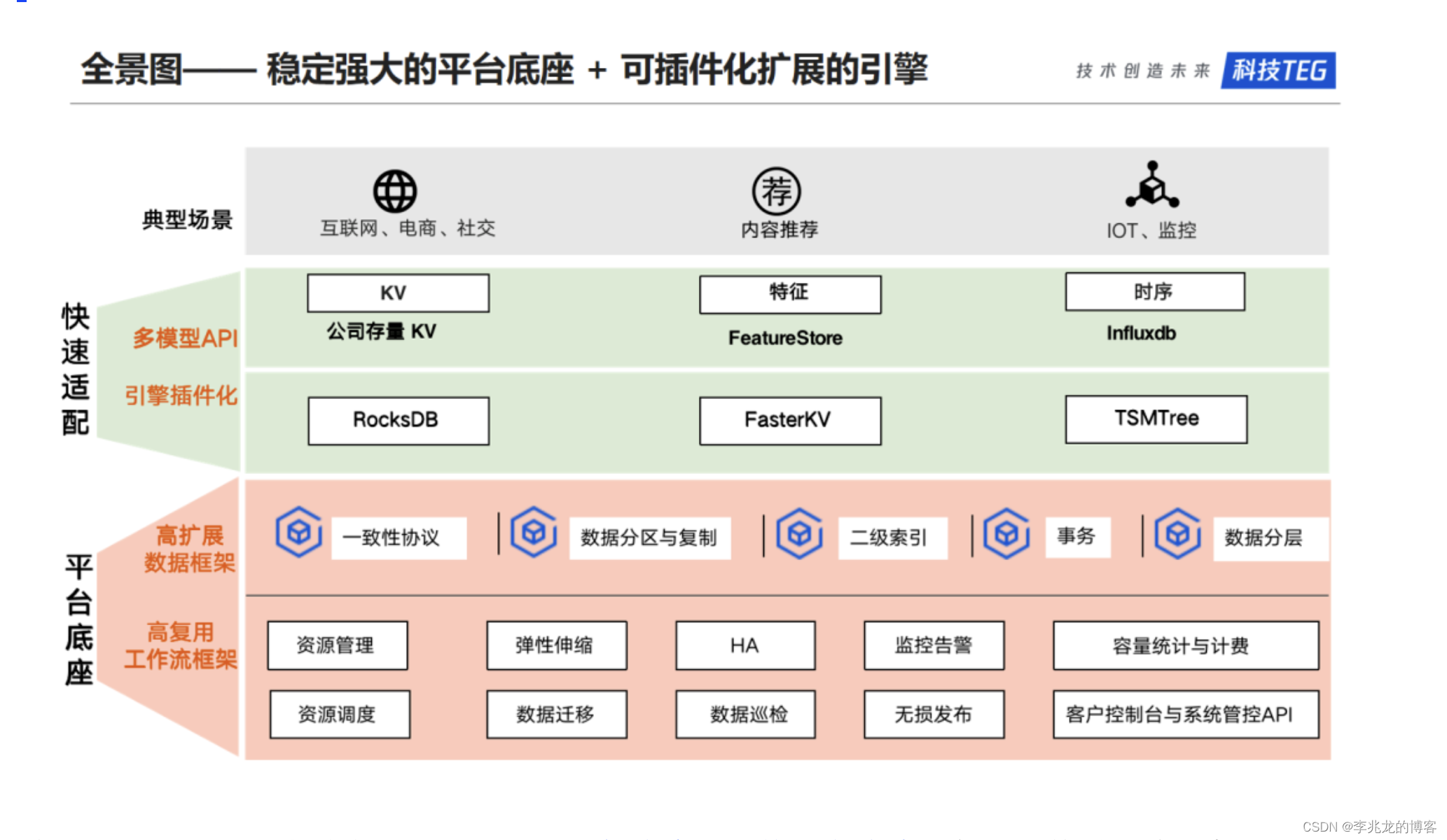
图片取自公开技术文章。
腾讯YottaDB也是一个多模型数据库,从架构图可以看到和Lindorm的架构高度类似,控制面以及共有链路抽离,各模态拥有定制化存储引擎。
当然YottaDB的架构可以从图中看出没有统一API的高可用存储层,这也意味着系统本身需要实现一致性和高可用性,并需要考虑不同的模态的降冷,迁移,分裂,合并等一系列需求。
多模型化修改点
- 未提及控制面的实现,一个支持多模型的分布式控制面并不容易。
- BGS的扩缩容基于一致性哈希,似乎并不是多租户,这无法实现多模型部署在一个集群。
- BGS缺乏计算能力,对于类sql的模态无法执行大规模并行计算,这点可以参考3,时序模态大多需要执行类似TiKV的coprocessor,当然实际会更加复杂。
- 存储层需要统一访问API,KV模态作为持久化层局限性太大,对于列存需求的模态存储量一定会成为瓶颈。
所以另起炉灶最好,不要基于现有系统改。
ByteGraph论文中的优化点概述
Dynamic Thread Pools
BGS中创建两个线程池,分别处理轻型请求和重型请求,因为请求具有突发特性,扩容来不及,所以基于排队任务的平均数量调整不同池子的线程,已保证服务质量,一方不会挤兑另外一方。
这样的做法还是比较常见的。
8中也用类似的手段分离从对象存储获取数据和本地计算的分离,不过其作用是为了最大化整体吞吐量;
在我们的时序数据库实现中我们用不同的池子来分离写请求,小查询和大查询,保证三者之间不会出现挤兑至无法服务的情况。
Adaptive Secondary Edge-Trees
Edge-Tree是 BGS 上构建索引的基本数据结构,以方便在邻接表中使用排序键进行搜索。但是,如果搜索关键字与排序关键字不匹配,则仍需要对整个Edge-Tree进行扫描,这将导致 CPU 占用率高和缓存丢失的可能性大。
因此, BGS 提供了一个Secondary Edge-Tree ,根据另一个边属性对邻接列表进行排序。二级边缘树建立后,指向新边缘树的指针会被添加到 Edge Storage 中,形成邻接列表的森林(图 6(b))。
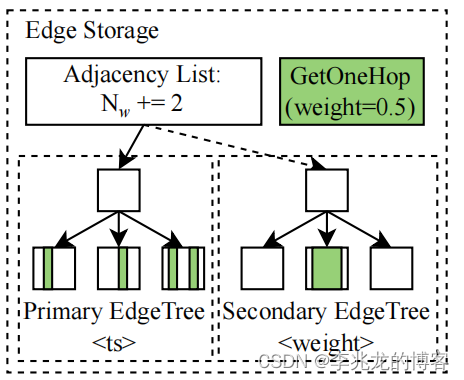
如果邻接表的大小较小或访问频率较低,构建新的 Edge-Tree 并不能提高缓存命中率,反而会占用更多空间。所以使用基于阈值估算的方法评估是否构建Secondary Edge-Tree,算法有兴趣可以查询原文1。
Space Optimized Bw-tree Forest
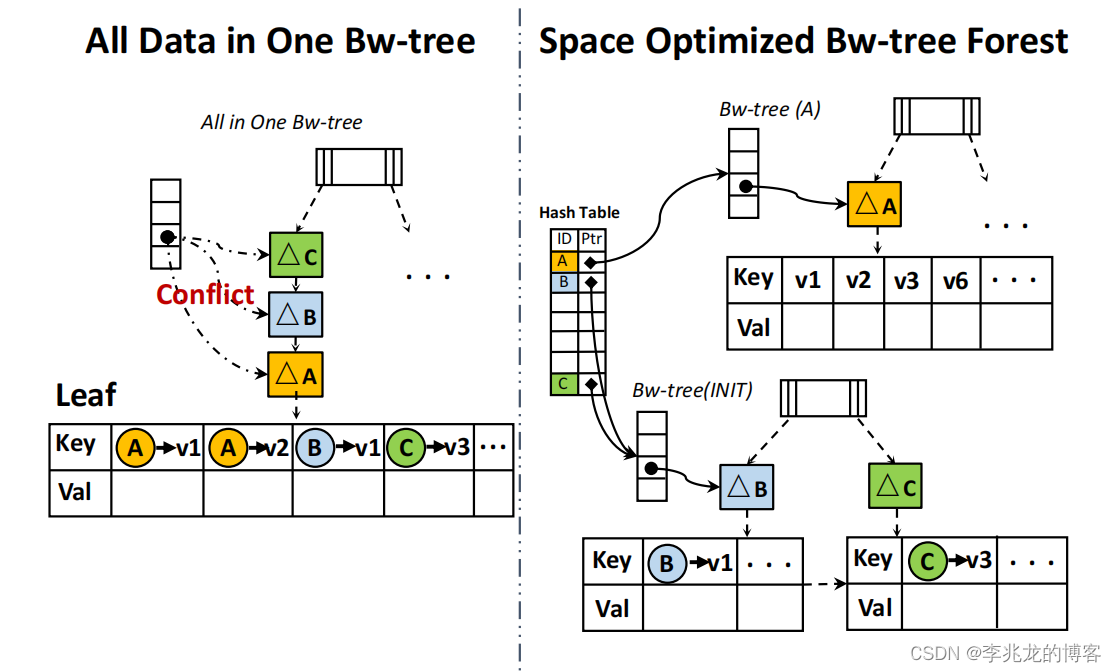
基于几个关键的业务特征:
- 超高并发场景会导致 Bw 树写入大量冲突,造成写入重试和等待,大大降低了并发写吞吐量。
- 不同用户节点之间的读写完全独立,互不干扰
- 简单地将每个用户对应的所有边划分到不同的 Bw 树中,可以有效解决大量并发写入冲突的问题。但是这种方法会造成额外的空间浪费。
首先将所有用户的 ID 作为键存储在哈希表中,哈希表的值指向用户的 Bw 树。每个新用户的同类操作都集中记录在一棵初始 Bw 树中。当用户高度活跃时,该用户喜欢的视频会迅速增加,这很可能会导致 Bw-tree (INIT) 中出现高频率的写入冲突。用户的 Bw 树上的边越多,其被访问的频率就越高。允许为每个工作负载配置一个阈值。一旦用户的边数超过了这个阈值,他们的数据就会被分割并放入一棵独立的 Bw 树中。
很不错的优化方式,对于树状结构并发(写出冲突影响性能)还是有很大的提升的,同样的思路可以应用在不少冲突可能会影响性能的地方。
Read Optimized Bw-tree / Workload-Aware Space Reclamation
这两个方案都是在 Bw 树上优化IO,但是我没有 Bw 树的工程经验,也不好评价,但是文章本身写的很细致,有兴趣的同学可以深入学习下2。
I/O Efficient Synchronization Mechanism
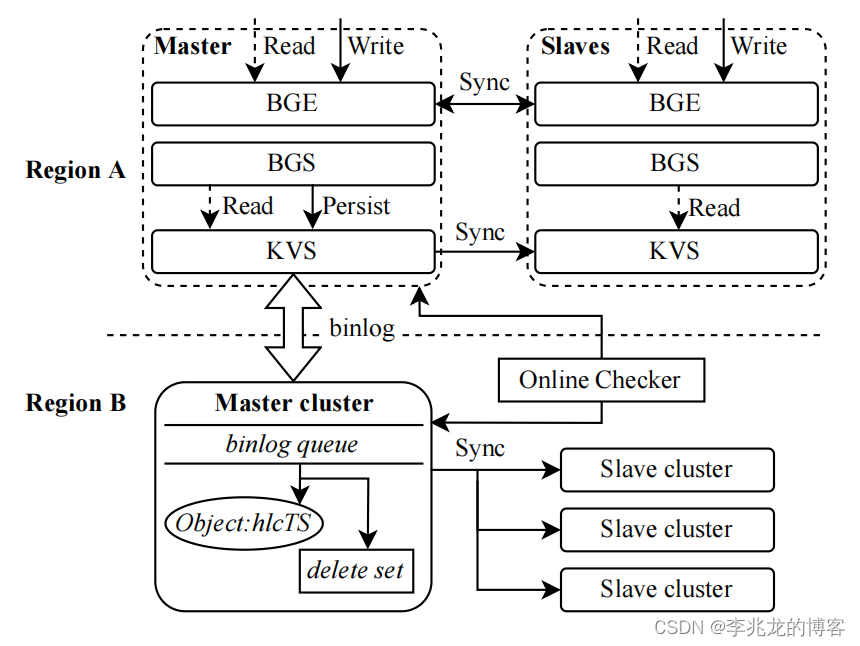
在1中提到ByteGraph初始版本主副本之间同步是最终一致性。(这个架构其实我有一个疑问,Slaves允许写,只不过不持久化到KVs,并把写转发给主,假如从成功,主失败,不就很长一段时间内不一致了吗。当然仍旧是最终一致性,因为持久化只有一个KVS)
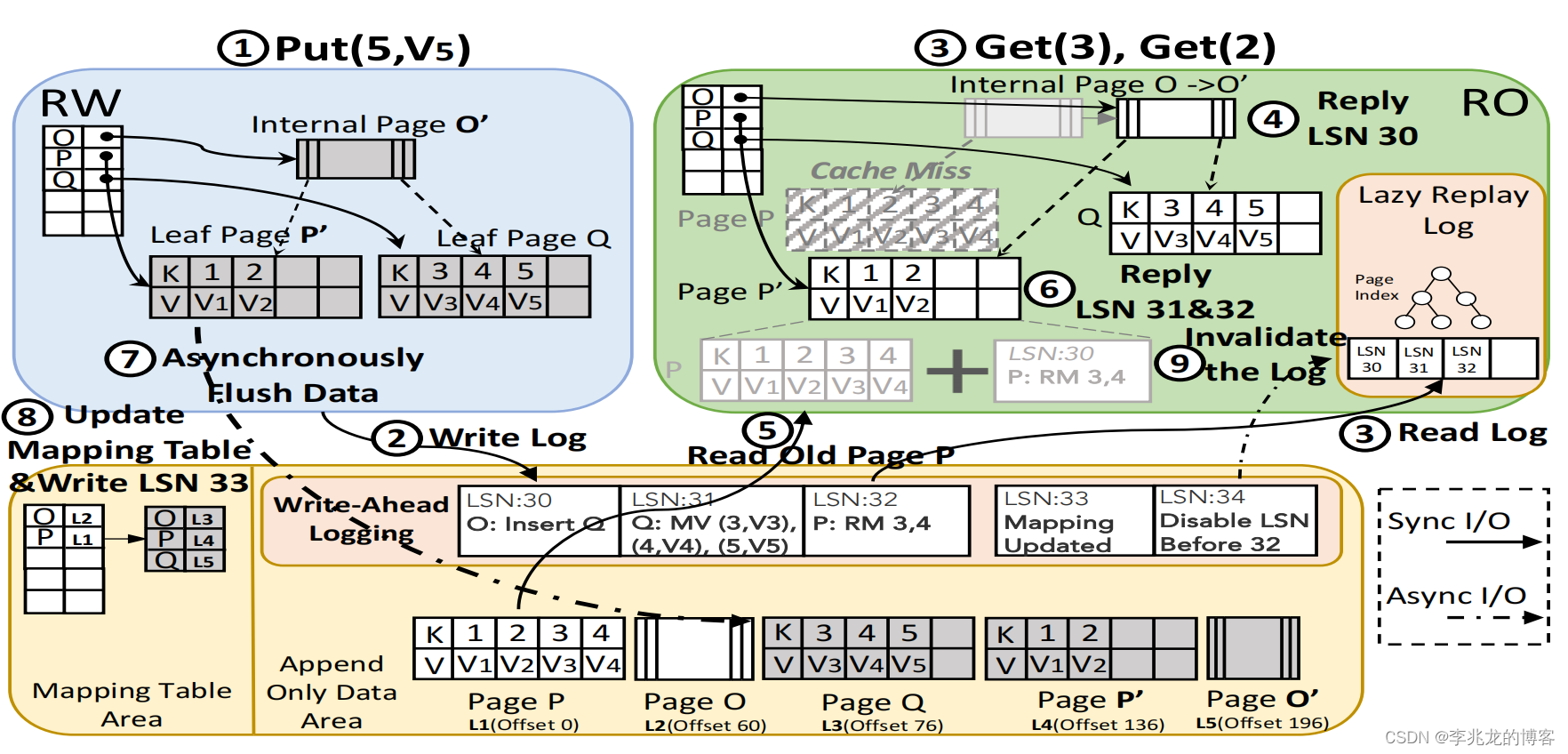
简单看下这个神奇的同步步骤:
- 当 RW 节点在接收到 Put(5,V5) 请求时,会触发 RW 内存中 Bw-tree 节点的拆分,产生脏页。通过WAL记录整个 Bw树的拆分过程,其中LSN范围为 30 到 32。
- WAL 在 RW 更新后立即写入共享存储空间。
- RO 节点立即读入 WAL,缓存在内存中。用户触发 Get(2) 和 Get(3) 操作。这些操作会导致 RO 缓存中的页面 P 和 Q 出现缓存缺失操作。
- wal的回放使用 lazy replay mechanism,使用日志 LSN 30 将 RO 中的缓存页面 O 更新为与 RW 的 O' 相同的状态,会导致 RO 缓存中的页面 P 和 Q 出现缓存缺失操作。
- RO 节点会查找共享存储中的旧映射以获取页面 P。
- 对 P 重放相关日志(LSN 32)。当存储中的旧映射不包含 WAL 中记录的页面(页面 Q)时,表明该页面是新生成的。RO 节点会直接在 6 处的内存中创建它。此时,RO 节点内存中的数据与 RW 节点中的最新数据完全一致。
- RW 内存中的 Bw 树拆分产生的三个脏页面由后台线程池异步刷新到共享存储中。
- 脏数据刷新到附加数据区后,更新映射表来更新共享存储上的数据版本,并在 WAL 中同步写入日志,表明共享存储中的数据已完成截至 LSN 34 的所有修改。
- 一旦 RO 读取了该日志项,它就可以丢弃懒重放日志中 LSN 编号小于 34 的所有记录。
这一套机制实现难度不小,本质上wal并不是数据,而是有逻辑的更新流,实际的数据流是写入KVS的。
这个想法让我思绪良多,虽然内存时序数据库的并不是一个稀奇事456,但是现有大规模应用的时序数据库据我所知没有专门的缓存模块,BG3中的多副本同步机制保证缓存副本间一致性(强一致性的缓存系统!)对于部分业务的时序数据来说是个杀器,就是这个WAL太不通用了,属于模态相关的特殊优化。
其实不止时序,KV模态也大有裨益,类似DAX7的系统可以加速SSD系统的用户查询。
结束语
ByteGraph是一个优秀的大规模图数据库系统,没有必要改为多模型数据库,虽然看起来多模型数据库可以快速实现一个图数据库,但是很难做到很多的特化优化,比如这个强大的wal同步机制,但是剩下的优化确实可以一个不落全部实现,就是存储层需要高度抽象以支持KV。
参考:
- ByteGraph: A High-Performance Distributed Graph Database in ByteDance vldb2022
- BG3: A Cost Effective and I/O Efficient Graph Database in ByteDance sigmod2024
- 从一到无穷大 #13 How does Lindorm TSDB solve the high cardinality problem?
- 从一到无穷大 #12 Planet-Scale In-Memory Time Series Database, Is it really Monarch?
- 从一到无穷大 #15 Gorilla,论黄金26H与时序数据库缓存系统的可行性
- 从一到无穷大 #16 ByteSeries,思考内存时序数据库的必要性
- Don't Put a Cache in Front of Database
- 从一到无穷大 #22 基于对象存储执行OLAP分析的学术or工程经验,我们可以从中学习到什么?