为什么需要quicklist
假设你已经知道了ziplist的缺陷:
- 虽然节省空间,但是申请内存必须是连续的,如果内存占用比较多,申请效率低
- 要存储大量数据,超过了ziplist的最佳上限后,性能有影响
借鉴分片思想,可以把大量的数据分片存储到多个ziplist中,每个ziplist的长度和大小都在最佳上限之下,这样虽然解决了单个ziplist空间申请和数据存储的问题,但是又有了新的挑战:数据拆分后比较分散,不方便查找和管理,多个ziplist如何建立连接呢?这就是下面要说的quicklist。
什么是quicklist
quicklist是一个双端链表结构,链表的每一个节点都是ziplist。
quicklist的结构
c
// quicklistNode 节点
typedef struct quicklistNode {
struct quicklistNode *prev; //前一个quicklistNode
struct quicklistNode *next; //后一个quicklistNode
unsigned char *zl; //quicklistNode指向的ziplist
unsigned int sz; //ziplist的字节大小
unsigned int count : 16; //ziplist中的元素个数
unsigned int encoding : 2; //编码格式,原生字节数组或压缩存储
unsigned int container : 2; //存储方式
unsigned int recompress : 1; //数据是否被压缩
unsigned int attempted_compress : 1; //数据能否被压缩
unsigned int extra : 10; //预留的bit位
} quicklistNode;
typedef struct quicklist {
quicklistNode *head; //quicklist的链表头
quicklistNode *tail; //quicklist的链表尾
unsigned long count; //所有ziplist中的总元素个数
unsigned long len; //quicklistNodes的个数
...
} quicklist;quicklist作为链表结构,它定义了整个链表的头、尾指针,这样一来,就可以O(1)的时间复杂度快速定位链表头和尾了。从quicklist的定义,可以画出quicklist的结构如下:
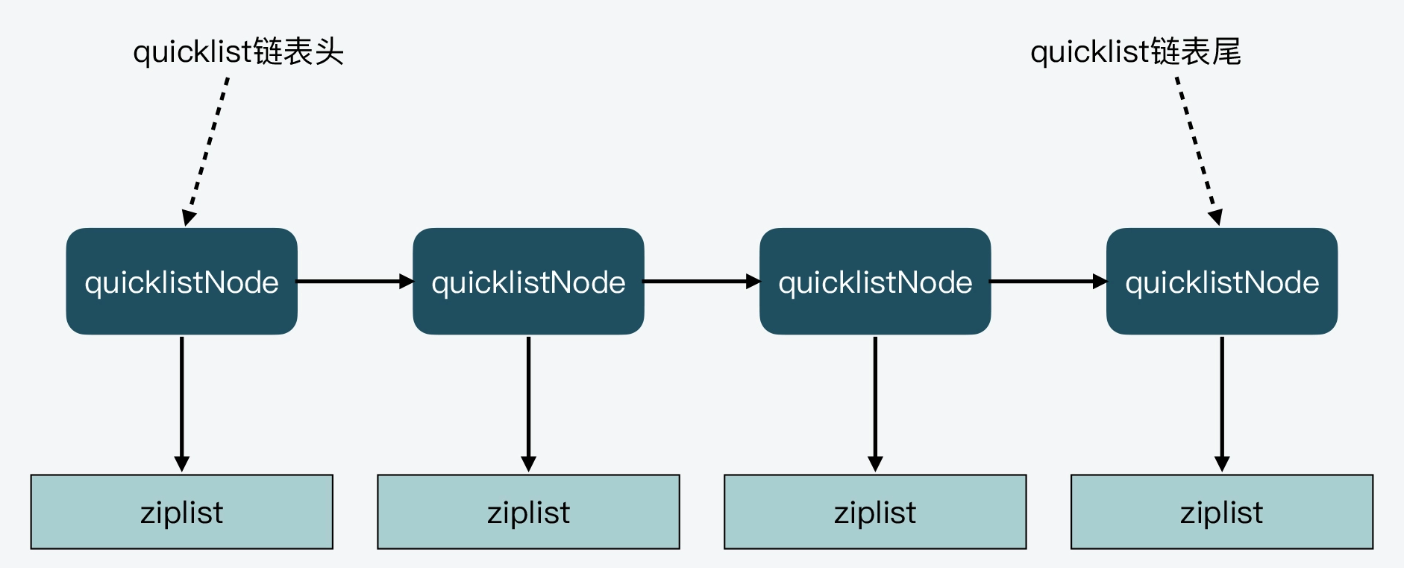
为了避免quicklist每个节点下的ziplist的entry过多,在Redis.conf中提供了一个配置项list-max-ziplist-size用来限制数量。如果为正数,则表示ziplist允许的entry的个数的最大值;如果为负数,则表示ziplist的最大内存大小,分下面5种情况:
| 值 | 每个ziplist的内存占用限制(不超过) |
|---|---|
| -1 | 4kb |
| -2 | 8kb,默认值 |
| -3 | 16kb |
| -4 | 32kb |
| -5 | 64kb |
除了控制ziplist的大小,quicklist还可以对节点的ziplist进行压缩,在Redis.conf种提供了配置项list-compress-depth进行控制。因为quicklist是双端链表,首尾一般访问较多,所以首尾不压缩。这个参数用来控制首尾不压缩的个数。
- 0:特殊值,代表不压缩。默认值
- 1:表示首尾各有一个节点不压缩,中间节点压缩
- 2:表示首尾各有两个节点不压缩,中间节点压缩
插入操作
_quicklistNodeAllowInsert函数用来完成新节点的插入,源码如下:
c
REDIS_STATIC int _quicklistNodeAllowInsert(const quicklistNode *node,
const int fill, const size_t sz) {
// new_sz 是新插入元素后 quicklistNode 的总大小,加上 ziplist 的额外开销
unsigned int new_sz = node->sz + sz + ziplist_overhead;
// 如果新大小符合优化要求,则允许插入
if (likely(_quicklistNodeSizeMeetsOptimizationRequirement(new_sz, fill)))
return 1;
// 如果不符合优化要求,进一步检查大小是否安全
// 如果不安全,则不允许插入
else if (!sizeMeetsSafetyLimit(new_sz))
return 0;
// 如果节点中的元素个数少于填充因子,允许插入
else if ((int)node->count < fill)
return 1;
// 否则不允许插入
else
return 0;
}_quicklistNodeAllowInsert函数会计算新插入元素后的大小(new_sz),等于 quicklistNode 的当前大小(node->sz)、插入元素的大小(sz),以及插入元素后 ziplist 的 prevlen 占用大小。然后依次判断新插入的数据大小是否满足要求,即单个 ziplist 是否不超过 8KB,或是单个 ziplist 里的元素个数是否满足要求。只要这里面的一个条件能满足,quicklist 就可以在当前的 quicklistNode 中插入新元素,否则 quicklist 就会新建一个 quicklistNode,以此来保存新插入的元素。
这样一来,quicklist通过控制每个节点种ziplist 的大小或是元素个数,可以有效减少在 ziplist 中新增或修改元素后,发生连锁更新的情况。
总结
本文主要讲解了为了解决ziplist的缺陷,quicklist通过对ziplist进行"分片"存储,限制每个节点的大小或数量来提供性能的方法,希望对你有帮助。