- easy-rl PDF版本 笔记整理 P1 - P2
- joyrl 比对 补充 P1 - P3
- 相关 代码 整理

最新版PDF下载
地址:https://github.com/datawhalechina/easy-rl/releases
国内地址(推荐国内读者使用) :
链接: https://pan.baidu.com/s/1isqQnpVRWbb3yh83Vs0kbw 提取码: us6a
参考链接 2:https://datawhalechina.github.io/joyrl-book/
其它:
【勘误记录 链接】
5、深度强化学习基础 ⭐️
开源内容:https://linklearner.com/learn/summary/11
文章目录
-
- [Gym 仿真库_OpenAI](#Gym 仿真库_OpenAI)
-
- [------ 补充:基本环境配置](#—— 补充:基本环境配置)
- [本书代码 gym 版本 0.25.2 可用](#本书代码 gym 版本 0.25.2 可用)
- [查看 包含的 仿真环境](#查看 包含的 仿真环境)
- [车杆平衡 CartPole-v0](#车杆平衡 CartPole-v0)
- [------ 补充: 本地渲染 代码修改 【gym 最新版本 0.26.2 】](#—— 补充: 本地渲染 代码修改 【gym 最新版本 0.26.2 】)
- [如何 与 gym 库 交互。 MountainCar-v0 【车上 山顶】](#如何 与 gym 库 交互。 MountainCar-v0 【车上 山顶】)
- [------ 补充: Gym 升级版本 Gymnasium](#—— 补充: Gym 升级版本 Gymnasium)
- [------ 补充: Jupyter 中显示 gym 渲染窗口及保存为 gif _ matplotlib 【gym 版本 0.25.2】](#—— 补充: Jupyter 中显示 gym 渲染窗口及保存为 gif _ matplotlib 【gym 版本 0.25.2】)
- [第 2 章 马尔可夫决策过程](#第 2 章 马尔可夫决策过程)
- JoyRL


即时反馈 难以获取
延迟奖励 增加了 网络训练的难度
强化学习 输入: 序列数据
探索 exploration 利用 exploitation
在机器学习中, 如果观测数据有非常强的关联,会使得训练非常不稳定。
------> 独立同分布
轨迹 trajectory τ = ( s 0 , a 0 , s 1 , a 1 , ⋯ ) \tau=(s_0,a_0,s_1,a_1,\cdots) τ=(s0,a0,s1,a1,⋯)
轨迹到底包不包含 奖励 reward 呢?
回合 episode 或 试验 (trial)
2012 年 AlexNet 卷积神经网络
端到端: 特征提取 + 分类
GPU 更快地做更多的试错尝试
智能体 走路、机械臂学习一个统一的抓取算法
先在虚拟环境中得到一个很好的智能体, 再应用到真实的机器人中。
- 真实的机械臂易损坏且昂贵, 无法大批购买。

最大化 累积奖励的期望
即时奖励 和 延迟奖励
当智能体能够观察到环境的所有状态时,强化学习通常 建模成 一个马尔可夫决策过程 (Markov decision process,MDP)的问题
部分可观测马尔可夫决策过程 ( S , A , T , R , Ω , O , γ ) (S, A, T, R, \Omega, O, \gamma) (S,A,T,R,Ω,O,γ)
- 状态 S S S
- 动作 A A A
- 状态转移概率 T ( s ′ ∣ s , a ) T(s^\prime|s, a) T(s′∣s,a)
- 奖励 R R R
- 观测概率 Ω ( o ∣ s , a ) \Omega(o|s, a) Ω(o∣s,a)
- 观测空间 O O O
- 折扣因子 γ \gamma γ
离散动作
连续动作: 机器人 360° 任意角度移动
策略增加随机性, 可以更好地探索环境,避免被对手预测下一步动作。
状态值 v π ( s ) = E π G t ∣ s t = s = E π ∑ k = 0 ∞ γ k ⋅ r t + k + 1 ∣ s t = s ∀ s ∈ S v_\pi(s)=\mathbb E_\piG_t\|s_t=s=\mathbb E_\pi\Big\\sum\\limits_{k=0}\^{\\infty}\\gamma\^k·r_{t+k+1}\|s_t=s\\Big~~\forall~s\in\cal S~~~ vπ(s)=EπGt∣st=s=Eπk=0∑∞γk⋅rt+k+1∣st=s ∀ s∈S 注意 从 r t + 1 r_{ t + 1} rt+1 开始累积
动作值 q π ( s , a ) = E π G t ∣ s t = s , a t = a = E π ∑ k = 0 ∞ γ k ⋅ r t + k + 1 ∣ s t = s , a t = a q_\pi(s, a)=\mathbb E_\piG_t\|s_t=s, a_t=a=\mathbb E_\pi\Big\\sum\\limits_{k=0}\^\\infty\\gamma\^k·r_{t+k+1}\|s_t=s, a_t=a\\Big~~~~~~~~ qπ(s,a)=EπGt∣st=s,at=a=Eπk=0∑∞γk⋅rt+k+1∣st=s,at=a 将 动作 a a a 加入考量范围, 其它同上
状态转移概率 p ( s t + 1 = s ′ ∣ s t = s , a t = a ) p(s_{t+1}=s^\prime|s_t=s, a_t=a) p(st+1=s′∣st=s,at=a)
总回报 R ( s , a ) = E r t + 1 ∣ s t = s , a t = a R(s, a)=\mathbb Er_{t+1}\|s_t=s, a_t=a R(s,a)=Ert+1∣st=s,at=a
value-based: 维护一个关于值 的表格 或函数, 直接选取 值 最大的动作。
policy-based:根据 策略 确定 动作
是否 对环境 进行建模了?
model-based 状态转移
model-free 值函数 和 策略函数
模型 不易 确定
智能体 执行行动前, 能否对下一步的状态和奖励进行预测,若可以, 则可采用 有模型学习。
免模型 数据
两亿帧游戏画面。
利用: 直接采取已知的奖励最大的动作。
Gym 仿真库_OpenAI
OpenAI 的 Gym 库是一个环境仿真库
离散控制 场景(输出的动作是可数的,比如Pong游戏中输出的向上或向下动作)一般使用雅达利环境评估;
连续控制 场景(输出的动作是不可数的,比如机器人走路时不仅有方向,还有角度,角度就是不可数的,是一个连续的量 )一般使用 MuJoCo 环境评估。
Gym Retro是对 Gym 环境的进一步扩展,包含更多的游戏。
使用 env = gym.make(环境名) 调用模拟的环境 ,
使用 env.reset() 初始化环境,
使用 env.step(动作) 执行一步 动作,
使用 env.render() 环境渲染,
使用 env.close() 关闭环境。
------ 补充:基本环境配置
是否需要 GPU? ------> 当前学习版的代码大多不用。
方式一: 本地 IDE 【可直接用 pygame 可视化渲染的环境】
能跑 Python代码 即可。 VS Code 或 PyCharm 等
示例在后文 ------补充: 本地渲染 代码修改 部分
方式二:自配置 或 第三方平台 的 Jupyter Notebook 阿里云天池/Colab。【需要其它库辅助可视化渲染的环境;可以薅 GPU】
阿里云天池

Python
import gym
print(gym.__version__)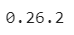
已是当前最新版本
简单示例:
python
pip install gym
python
import gym
from IPython import display
import matplotlib
import matplotlib.pyplot as plt
%matplotlib inline
env = gym.make('CartPole-v1', render_mode='rgb_array')
env.reset()
img = plt.imshow(env.render()) # only call this once
for _ in range(300):
img.set_data(env.render()) # just update the data
display.display(plt.gcf())
display.clear_output(wait=True)
action = env.action_space.sample()
env.step(action)
env.close()Colab
当前默认版本
Python3
import gym
print(gym.__version__)
python
import gym
from IPython import display
import matplotlib
import matplotlib.pyplot as plt
%matplotlib inline
env = gym.make('CartPole-v1')
env.reset()
img = plt.imshow(env.render(mode='rgb_array')) # only call this once
for _ in range(300):
img.set_data(env.render(mode='rgb_array')) # just update the data
display.display(plt.gcf())
display.clear_output(wait=True)
action = env.action_space.sample()
env.step(action)
env.close()升级 gym 后可运行 天池的同一示例代码
python
pip install --upgrade gym
由于 版本升级, 部分 API 有变动, 若是语法报错,一般是 当前环境的 gym 版本 和 代码要求的不一致。
版本控制: 根据代码指定版本。
python
pip install gym==0.25.2书里内容整理:
本书代码 gym 版本 0.25.2 可用
直接安装 版本 0.25.2 【初学者这种比较好】。 或 根据最新的 API 修改代码
python
pip install gym==0.25.2
python
pip install pygame
python
import gym在刚开始测试强化学习 的时候,我们可以选择这些简单环境,因为强化学习在这些环境中可以在一两分钟之内见到效果。

Acrobot 需要让一个双连杆机器人立起来;
CartPole 需要通过控制一辆小车,让杆立起来;
MountainCar 需要通过前后移动车,让它到达旗帜的位置。
查看 包含的 仿真环境
python
from gym import envs
env_specs = envs.registry.all()
envs_ids = [env_spec.id for env_spec in env_specs]
print(envs_ids)
车杆平衡 CartPole-v0
python
import gym # 导入 Gym 的 Python 接口环境包
env = gym.make('CartPole-v0') # 构建实验环境
env.reset() # 重置一个回合
for _ in range(1000):
env.render() # 显示图形界面
action = env.action_space.sample() # 从动作空间中随机选取一个动作
env.step(action) # 用于提交动作,括号内是具体的动作
env.close() # 关闭环境- 报错, 暂时不清楚 是啥问题。。【阿里云天池的 gym 版本是最新的, 最新版 gym 部分 API 有变动】

------> Colab 可以跑, 不报错。【gym 版本 0.25.2 和 代码匹配】
python
import gym
env = gym.make('CartPole-v0')
env.reset()
for _ in range(1000):
env.render()
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
print(observation)
env.close() - 和之前的报错一样
------> Colab 可以跑, 能输出数据,就是 env.render() 没反应。
------> Jupyter Notebook 需要自己可视化。
------ 补充: 本地渲染 代码修改 【gym 最新版本 0.26.2 】
这里直接安装最新版本的 gym 和 pygame。
pip install gym
pip install pygame
参考最新版本的示例代码: API 已修改
参考链接
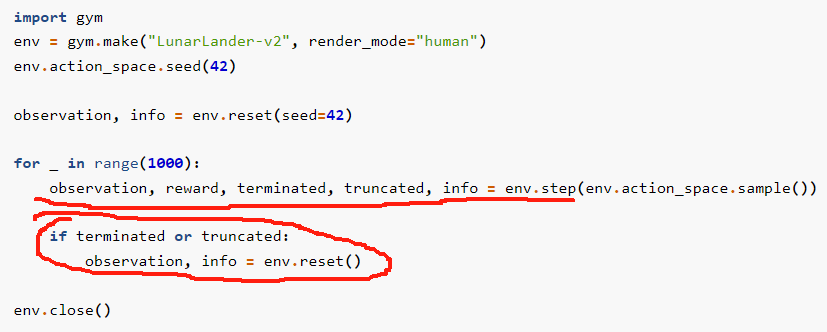
修改后的示例代码:
Linux 命令行 ✔
python
python test.py其它 的 IDE 配置了 gym + pygame 的估计都能正常运行。
test.py
python
import gym
env = gym.make("CartPole-v0", render_mode="human") # √
# env = gym.make("CartPole-v0") # 最新版本 渲染模式 的设置 似乎特别重要, 这里要 设成上面的才可以
env.action_space.seed(42)
observation, info = env.reset(seed=42)
for _ in range(1000):
observation, reward, terminated, truncated, info = env.step(env.action_space.sample())
if terminated or truncated:
observation, info = env.reset()
env.close()此外, 尽管没有在代码里 显式地调用 pygame,这里默认用了 pygame 显示。
且跑代码时 未安装 pygame, 会报错:

从报错信息来看, pygame 是 gym 默认用于可视化 渲染环境 的依赖库。
因此需要安装 pygame: pip install pygame

如前所述:
至少安装:
pip install gym
pip install pygame
如何 与 gym 库 交互。 MountainCar-v0 【车上 山顶】
python
import gym
env = gym.make('MountainCar-v0')
print('观测空间 = {}'.format(env.observation_space))
print('动作空间 = {}'.format(env.action_space))
print('观测范围 = {} ~ {}'.format(env.observation_space.low,
env.observation_space.high))
print('动作数 = {}'.format(env.action_space.n))
在 Gym 库中,
环境的观测空间 用 env.observation_space 表示,
动作空间 用 env.action_space 表示。
离散空间 gym.spaces.Discrete 类表示,
连续空间用 gym.spaces.Box 类表示。
对于离散空间,Discrete (n) 表示可能取值的数量为 n;
对于连续空间,Box 类实例成员中的 low 和 high 表示每个浮点数的取值范围。
python
import gym
import numpy as np
class SimpleAgent:
def __init__(self, env):
pass
def decide(self, observation): # 决策
position, velocity = observation
lb = min(-0.09 * (position + 0.25) ** 2 + 0.03,
0.3 * (position + 0.9) ** 4 - 0.008)
ub = -0.07 * (position + 0.38) ** 2 + 0.07
if lb < velocity < ub:
action = 2
else:
action = 0
return action # 返回动作
def learn(self, *args): # 学习
pass
def play(env, agent, render=False, train=False): # 环境, render 是否图示, train: 学习时 为 True, 测试时 为 False
episode_reward = 0. # 记录回合总奖励,初始化为0
observation = env.reset() # 重置游戏环境,开始新回合
while True: # 不断循环,直到回合结束
if render: # 判断是否显示
env.render() # 显示图形界面,图形界面可以用 env.close() 语句关闭
action = agent.decide(observation)
next_observation, reward, done, _ = env.step(action) # 执行动作
episode_reward += reward # 收集回合奖励
if train: # 判断是否训练智能体
agent.learn(observation, action, reward, done) # 学习
if done: # 回合结束,跳出循环
break
observation = next_observation
return episode_reward # 返回回合总奖励
env = gym.make('MountainCar-v0')
env.seed(3) # 设置随机种子,让结果可复现
agent = SimpleAgent(env)
print('观测空间 = {}'.format(env.observation_space))
print('动作空间 = {}'.format(env.action_space))
print('观测范围 = {} ~ {}'.format(env.observation_space.low,
env.observation_space.high))
print('动作数 = {}'.format(env.action_space.n))
episode_reward = play(env, agent, render=True)
print('回合奖励 = {}'.format(episode_reward))
episode_rewards = [play(env, agent) for _ in range(100)] # 100 个 回合 !
print('平均回合奖励 = {}'.format(np.mean(episode_rewards)))- 和之前的报错一样
------> Colab

测试智能体在 Gym 库中某个任务的性能时,出于习惯使然,学术界一般最关心 100 个回合的平均回合奖励。
对于有些任务,还会指定一个参考的回合奖励值,当连续 100 个回合的奖励大于指定的值时,则认为该任务被解决了。
SimpleAgent 类对应策略的平均回合奖励在−110 左右,而对于小车上山任务,只要连续 100 个回合的平均回合奖励大于 -110,就可以认为该任务被解决了。
------ 补充: Gym 升级版本 Gymnasium

备选的报错解决方案
python
pip install gymnasium官方示例:
python
import gymnasium as gym
env = gym.make("CartPole-v1")
observation, info = env.reset(seed=42)
for _ in range(1000):
action = env.action_space.sample()
observation, reward, terminated, truncated, info = env.step(action)
if terminated or truncated:
observation, info = env.reset()
env.close()------ 补充: Jupyter 中显示 gym 渲染窗口及保存为 gif _ matplotlib 【gym 版本 0.25.2】
Colab:
python
import numpy as np
import time
import gym
import matplotlib.pyplot as plt
from matplotlib import animation
%matplotlib inline
from IPython import display
# 显示gym渲染窗口的函数,在运行过程中将 env.render() 替换为 show_state(env, step, info).
def show_state(env, step=0, info=""):
plt.figure(3)
plt.clf()
plt.imshow(env.render(mode='rgb_array'))
plt.title("Step: %d %s" % (step, info))
plt.axis('off')
display.clear_output(wait=True)
display.display(plt.gcf())
def display_frames_as_gif(frames, SavePath = './test.gif'):
patch = plt.imshow(frames[0])
plt.axis('off')
def animate(i):
patch.set_data(frames[i])
anim = animation.FuncAnimation(plt.gcf(), animate, frames = len(frames), interval=1)
anim.save(SavePath, writer='ffmpeg', fps=30)
############################################
# 运行环境实例 1
import gym
frames=[]
env = gym.make('CartPole-v1')
info = env.reset() # 重置环境
for step in range(100):
frames.append(env.render(mode='rgb_array')) # 加载各个时刻图像到帧
show_state(env, step, info = 'CartPole_test') # 显示渲染窗口
action = env.action_space.sample() # 随机动作,需要学习的动作模型
# action=np.random.choice(2) # 随机返回: 0 小车向左,1 小车向右
observation,reward,done,info = env.step(action) # 执行动作并返回结果
env.close()
display_frames_as_gif(frames, SavePath = './CartPole_result.gif') # 保存运行结果动图
Colab + gym
python
!pip install -q swig
!pip install box2d==2.3.2 gym[box2d]==0.25.2 box2d-py pyvirtualdisplay tqdm numpy==1.22.4
!pip install box2d==2.3.2 box2d-kengz
python
import numpy as np
import time
import gym
import matplotlib.pyplot as plt
from matplotlib import animation
%matplotlib inline
from IPython import display
# 显示gym渲染窗口的函数,在运行过程中将 env.render() 替换为 show_state(env, step, info).
def show_state(env, step=0, info=""):
plt.figure(3)
plt.clf()
plt.imshow(env.render(mode='rgb_array'))
plt.title("Step: %d %s" % (step, info))
plt.axis('off')
display.clear_output(wait=True)
display.display(plt.gcf())
def display_frames_as_gif(frames, SavePath = './test.gif'):
patch = plt.imshow(frames[0])
plt.axis('off')
def animate(i):
patch.set_data(frames[i])
anim = animation.FuncAnimation(plt.gcf(), animate, frames = len(frames), interval=1)
anim.save(SavePath, writer='ffmpeg', fps=30)
############################################
# 运行环境实例2
import gym
frames=[]
env = gym.make("LunarLander-v2")
env.reset()
env.action_space.seed(42)
observation, info = env.reset(seed=42, return_info=True)
for step in range(100):
frames.append(env.render(mode='rgb_array')) # 加载各个时刻图像到帧
# env.render(mode='human') # 这行不能和env定义写在一行,否则会报错,原因不明
time.sleep(0.1) # 控制显示速度变慢
show_state(env, step, info="LunarLander_test")
observation, reward, done, info = env.step(env.action_space.sample())
# observation, reward, terminated, truncated, info = env.step(env.action_space.sample())
if done:
# if terminated or truncated:
observation, info = env.reset(return_info=True)
env.close()
display_frames_as_gif(frames, SavePath = './LunarLander_result.gif') # 保存运行结果动图
强化学习:环境、动作、奖励。
强化学习 的使用场景: 多序列决策问题。
第 2 章 马尔可夫决策过程
状态非常多 的 ( s , a , r ) (s, a,r) (s,a,r) 过程 求解: 迭代
1、动态规划
2、蒙特卡洛 (采样)
3、时序差分 (TD-learning) = 蒙特卡洛 + 动态规划

bootstrapping 自举: 根据其它估计值 来更新 估计值。

动态规划: 最优子结构 + 重叠子问题
策略迭代:
1、策略评估
2、策略改进
值迭代 中间过程 的策略 和 值 是没有意义的。
策略迭代的每一次迭代的结果都是有意义的, 都是一个完整的策略。

JoyRL
试错学习
序列决策
在机器人中实现强化学习 的成本 比较高:
1、观测环境的状态 需要 大量传感器
2、试错学习 的实验成本 高昂
3、训练过程中 决策失误造成设备损坏
仿真
金融: 根据价格变化进行股票买卖决策, 最大化资产。
逆强化学习 【奖励函数 也通过学习来确定】。 专家数据的噪声
探索: 避免局部最优
离线强化学习
在离线环境中训练一个世界模型 ,然后将世界模型部署到在线环境中进行决策。
世界模型的思路是将环境分为两个部分,一个是世界模型,另一个是控制器。世界模型 的作用是预测下一个状态 ,而控制器 的作用是根据当前的状态来决策动作 。
如何提高世界模型的预测精度?
多任务强化学习
在实际应用中,智能体往往需要同时解决多个任务,例如机器人需要同时完成抓取、搬运、放置等任务,而不是单一的抓取任务。在这种情况下,如何在多个任务之间做出权衡是一个难题。
目前比较常用的方法有 联合训练 和 分层强化学习 等等。
- 联合训练 的思路是将多个任务的奖励 进行加权求和 ,然后通过强化学习来学习 一个策略。
- 分层强化学习 的思路是将多个任务分为两个层次,一个是高层策略,另一个是低层策略。
高层策略 的作用是决策当前的任务 ,而低层策略 的作用是决策当前任务的动作 。这样就可以通过强化学习来学习高层策略和低层策略,从而解决多任务强化学习的问题。
如何提高 高层策略 的决策精度?。
随机变量 大写
马尔可夫性质:
P ( S t + 1 ∣ S t ) = P ( S t + 1 ∣ S 0 , S 1 , ⋯ , S t − 1 , S t ) P(S_{t+1}|S_t)=P(S_{t+1}|\textcolor{blue}{S_0, S_1, \cdots, S_{t-1}},S_t) P(St+1∣St)=P(St+1∣S0,S1,⋯,St−1,St)
在给定历史状态 S 0 , S 1 , ⋯ , S t − 1 , S t S_0, S_1, \cdots, S_{t-1},S_t S0,S1,⋯,St−1,St 的情况下, 某个状态的未来只和当前状态 S t S_t St 有关, 与历史状态无关。
AlphaGO 算法:用深度学习神经网络 来表示当前的棋局,并用蒙特卡洛搜索树等技术来模拟玩家的策略和未来可能的状态,来构建一个新的决策模型
状态转移概率 : 当前状态 s s s ------> 下一状态 s ′ s^\prime s′
P s s ′ = P ( S t + 1 = s ′ ∣ S t = s ) P_{ss^\prime}=P(S_{t+1}=s^\prime|S_t=s) Pss′=P(St+1=s′∣St=s)
动态规划问题 的 3 个 性质:
1、最优化原理
2、无后效性 【某阶段状态一旦确定,就不受这个状态以后决策的影响。马尔可夫性质】
3、有重叠子问题
状态值函数: V π ( s ) = E π ( G t ∣ S t = s ) V_\pi(s)=\mathbb E_{\pi}(G_t|S_t=s) Vπ(s)=Eπ(Gt∣St=s)。
- 从特定状态出发, 按照某个策略 π \pi π 【一般带一定随机性】进行决策所能得到的回报期望值。
动作值函数: Q π ( s , a ) = E π G t ∣ s t = s , a t = a Q_\pi(s, a)=\mathbb E_\pi G_t\|s_t=s, a_t=a Qπ(s,a)=EπGt∣st=s,at=a
V π ( s ) = ∑ a ∈ A π ( a ∣ s ) Q π ( s , a ) V_\pi(s)=\sum\limits_{a\in\mathcal A}\pi(a|s)Q_\pi(s, a) Vπ(s)=a∈A∑π(a∣s)Qπ(s,a)