一、Cassandra的介绍
Cassandra是一套开源分布式NoSQL数据库系统。它最初由Facebook开发,用于储存收件箱等简单格式数据,集GoogleBigTable的数据模型与Amazon Dynamo的完全分布式的架构于一身Facebook于2008将 Cassandra 开源,此后,由于Cassandra良好的可扩展性,被Digg、Twitter等知名Web 2.0网站所采纳,成为了一种流行的分布式结构化数据存储方案。
Cassandra的官网:Apache Cassandra | Apache Cassandra Documentation
Cassandra特点
-
弹性可扩展性 - Cassandra是高度可扩展的; 它允许添加更多的硬件以适应更多的客户和更多的数据根据要求。
-
始终基于架构 - Cassandra没有单点故障,它可以连续用于不能承担故障的关键业务应用程序。
-
快速线性性能 - Cassandra是线性可扩展性的,即它为你增加集群中的节点数量增加你的吞吐量。因此,保持一个快速的响应时间。
-
灵活的数据存储 - Cassandra适应所有可能的数据格式,包括:结构化,半结构化和非结构化。它可以根据您的需要动态地适应变化的数据结构。
-
便捷的数据分发 - Cassandra通过在多个数据中心之间复制数据,可以灵活地在需要时分发数据。
-
事务支持 - Cassandra支持属性,如原子性,一致性,隔离和持久性(ACID)。
-
快速写入 - Cassandra被设计为在廉价的商品硬件上运行。 它执行快速写入,并可以存储数百TB的数据,而不牺牲读取效率。
二、Cassandra下载、安装、访问

进入下载页后,选择最新稳定版本4.1.5
三、Cassandra 安装部署
1、安装准备
注意:Cassandra 使用 JAVA 语言开发,首先保证当前机器中已经安装 JDK 11 or JDK 8
bash
# 安装JDK 11
# yum install java-11-openjdk -y
# java -version注意:Cassandra的客户端的使用需要用的Python3版本。需要先安装Python3
bash
# 安装python3
# yum install python3 -y
# python3 -V2、部署Cassandra
bash
# 解压
# tar -zxvf apache-cassandra-4.1.5-bin.tar.gz
# 重命名
# mv apache-cassandra-4.1.5 apache-cassandra配置 Cassandra
进入解压后的目录,创建3个 Cassandra 的数据文件夹
bash
# mkdir data
# mkdir commitlog
# mkdir saved-caches
修改配置文件
在 conf 目录中找到 cassandra.yaml 配置文件,配置上面创建的3个数据目录
- 配置 data_file_directories
bash
data_file_directories:
- /home/Cassandra/apache-cassandra/data- 配置 commitlog_directory
bash
commitlog_directory: /home/Cassandra/apache-cassandra/commitlog- 配置 saved_caches_directory
bash
saved_caches_directory: /home/Cassandra/apache-cassandra/saved_caches- 配置 RPC,用于客户端连接
bash
rpc_address: 192.168.204.1313、启动 Cassandra
bash
[root@localhost apache-cassandra]# pwd
/home/Cassandra/apache-cassandra
[root@localhost apache-cassandra]# ./bin/cassandra -R输入命令来查看正在运行的cassandra的 pid
bash
ps -ef|grep cassandra显示如图,pid 是 11733:

4、关闭Cassandra
刚才已经查到了 pid,现在可以使用命令杀掉这个pid对应的进程
bash
kill -9 117335、查看状态
bash
[root@localhost apache-cassandra]# ./bin/nodetool status
如果cassandra启动出错,可以在bin目录下 使用 journalctl -u cassandra 命令查看
bash
[root@localhost apache-cassandra]# cd bin
[root@localhost bin]# journalctl -u cassandra
bash
# 问题
[root@localhost bin]# ./nodetool status
nodetool: Failed to connect to '127.0.0.1:7199' - URISyntaxException: 'Malformed IPv6 address at index 7: rmi://[127.0.0.1]:7199'.
# 解决办法
[root@localhost bin]# ./nodetool -Dcom.sun.jndi.rmiURLParsing=legacy status
[root@localhost bin]# ./nodetool -h ::FFFF:127.0.0.1 status6、客户端连接服务器
进入Cassandra的目录,输入
bash
[root@localhost apache-cassandra]# ./bin/cqlsh 192.168.204.131 9042
Connected to Test Cluster at 192.168.204.131:9042
[cqlsh 6.1.0 | Cassandra 4.1.5 | CQL spec 3.4.6 | Native protocol v5]
Use HELP for help.
cqlsh>上面的操作在启动cqlsh的时候并没有指定需要连接的节点以及端口,默认 cqlsh 会自动探测本机及端口。上面的操作时已经启动了 Cassandra 服务并绑定相关端口,注:【 端口列表】,cqlsh默认就会连接本机的9042端口。
从上面的命令可以看出 cqlsh 连接到名为 Test Cluster 的集群,这个名字是默认值,可以自定义,配置在 conf/cassandra.yaml 文件的 cluster_name 参数,注:【yaml全内容】
输入quit退出客户端
Cassandra的端口
7199 - JMX
7000 - 节点间通信(如果启用了TLS,则不使用)
7001 - TLS节点间通信(使用TLS时使用)
9160 - Thrift客户端API
9042 - CQL本地传输端口7、服务运行脚本
为了方便管理,可以编写脚本来管理,在 /home/Cassandra/apache-cassandra 下创建一个 startme.sh,输入一下内容:
bash
#!/bin/sh
CASSANDRA_DIR="/home/Cassandra/apache-cassandra"
echo "************cassandra***************"
case "$1" in
start)
echo "* *"
echo "* starting *"
nohup $CASSANDRA_DIR/bin/cassandra -R >> $CASSANDRA_DIR/logs/system.log 2>&1 &
echo "* started *"
echo "* *"
echo "************************************"
;;
stop)
echo "* *"
echo "* stopping *"
PID_COUNT=`ps aux |grep CassandraDaemon |grep -v grep | wc -l`
PID=`ps aux |grep CassandraDaemon |grep -v grep | awk {'print $2'}`
if [ $PID_COUNT -gt 0 ];then
echo "* try stop *"
kill -9 $PID
echo "* kill SUCCESS! *"
else
echo "* there is no ! *"
echo "* *"
echo "************************************"
fi
;;
restart)
echo "* *"
echo "********* restarting ******"
$0 stop
$0 start
echo "* *"
echo "************************************"
;;
status)
$CASSANDRA_DIR/bin/nodetool status
;;
*)
echo "Usage:$0 {start|stop|restart|status}"
exit 1
esac接下来就可以使用这个脚本进行 启动,重启,关闭 的操作
bash
[root@localhost apache-cassandra]# sh startme.sh start
[root@localhost apache-cassandra]# sh startme.sh restart
[root@localhost apache-cassandra]# sh startme.sh stop四、Cassandra根据用户名密码登录cqlsh
修改conf目录下cassandra.yaml文件
bash
authenticator: PasswordAuthenticator //将authenticator修改为PasswordAuthenticator 重新启动cassandra并且根据默认用户登录cqlsh,用户名密码都是cassandra
bash
[root@localhost apache-cassandra]# ./bin/cqlsh 192.168.204.131 9042 -ucassandra -pcassandra
Warning: Using a password on the command line interface can be insecure.
Recommendation: use the credentials file to securely provide the password.
Connected to Test Cluster at 192.168.204.131:9042
[cqlsh 6.1.0 | Cassandra 4.1.5 | CQL spec 3.4.6 | Native protocol v5]
Use HELP for help.
cassandra@cqlsh> 如果要修改默认用户,进入cqlsh后
bash
#超级用户可以更改用户的密码或超级用户身份。为了防止禁用所有超级,超级用户不能改变自己的超级用户身份。普通用户只能改变自己的密码。附上用户名在单引号如果它包含非字母数字字符。附上密码在单引号。
CREATE USER test WITH PASSWORD '123456' SUPERUSER; //创建一个超级用户
CREATE USER test1 WITH PASSWORD '123456' NOSUPERUSER; //创建一个普通用户
ALTER USER test WITH PASSWORD '654321' ( NOSUPERUSER | SUPERUSER ) //修改用户
DROP USER cassandra //删除默认用户五、Cassandra的基本概念
1、数据模型
1.1列(Column)
列是Cassandra的基本数据结构单元,具有三个值:名称,值、时间戳

在Cassandra中不需要预先定义列(Column),只需要在KeySpace里定义列族,然后就可以开始写数据了。
1.2列族( Column Family)
列族相当于关系数据库的表(Table),是包含了多行(Row)的容器。
1.3建空间 (KeySpace)
Cassandra的键空间(KeySpace)相当于数据库,我们创建一个键空间就是创建了一个数据库。
2、数据类型
2.1数值类型
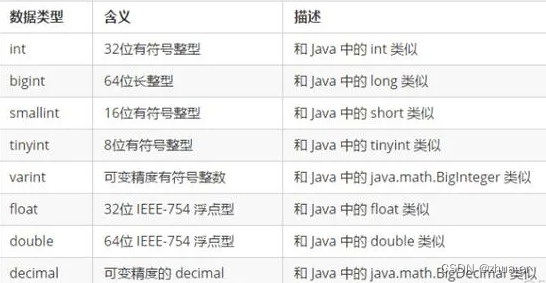
2.2文本类型
CQL提供2种类型存放文本类型,text和varchar基本一致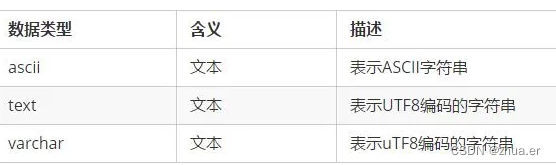
2.3时间类型
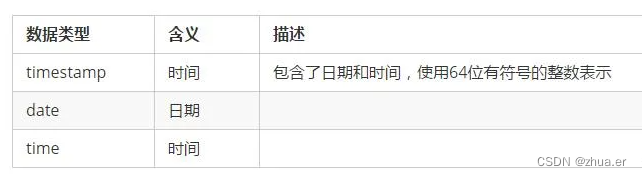
2.4标识符类型

2.5集合类型
set
集合数据类型,set 里面的元素存储是无序的。
set 里面可以存储前面介绍的数据类型,也可以是用户自定义数据类型,甚至是其他集合类型。
list
list 包含了有序的列表数据,默认情况下,数据是按照插入顺序保存的。
map
map 数据类型包含了 key/value 键值对。key 和 value 可以是任何类型,除了 counter 类型
使用集合类型要注意: 1、集合的每一项最大是64K。 2、保持集合内的数据不要太大,免得Cassandra 查询延时过长,Cassandra 查询时会读出整个集合内的数据,集合在内部不会进行分页,集合的目的是存储小量数据。 3、不要向集合插入大于64K的数据,否则只有查询到前64K数据,其它部分会丢失。
2.6其他基本类型

3、数据定义命令
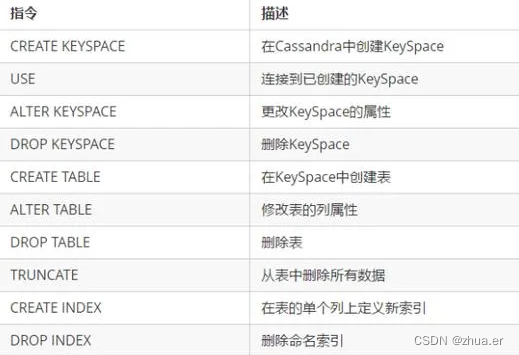
4、数据操作指令
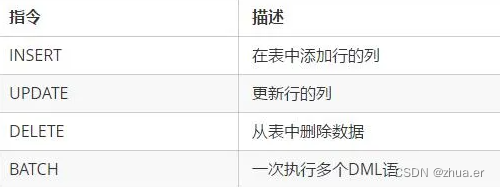
5、查询指令
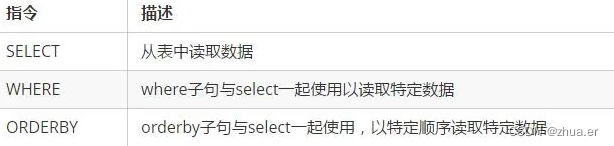
六、Cassandra的基本操作
1、操作键空间
1.1创建Keyspace
sql
语法
CREATE KEYSPACE <identifier> WITH <properties>;
更具体的语法:
Create keyspace KeyspaceName with replicaton={'class':strategy name,
'replication_factor': No of replications on different nodes};要填写的内容:
KeyspaceName 代表键空间的名字
strategy name 代表副本放置策略,内容包括:简单策略、网络拓扑策略,选择其中的一个。
No of replications on different nodes 代表 复制因子,放置在不同节点上的数据的副本数。
编写完成的创建语句 创建一个键空间名字为:school,副本策略选择:简单策略 SimpleStrategy,副本因子:3
sql
CREATE KEYSPACE school WITH replication = {'class':'SimpleStrategy', 'replication_factor' : 3};1.2连接Keyspace
sql
语法
USE <identifier>;1.3修改键空间
sql
语法
ALTER KEYSPACE <identifier> WITH <properties>1.4删除键空间
sql
语法
DROP KEYSPACE <identifier>2、操作表、索引
2.1查看键空间下所有表 代码
sql
DESCRIBE TABLES;2.2创建表
sql
语法
CREATE (TABLE | COLUMNFAMILY) <tablename> ('<column-definition>' , '<column-definition>')
(WITH <option> AND <option>)完整创建表语句,创建student 表,student包含属性如下: 学生编号(id), 姓名(name),年龄(age),性别(gender),家庭地址(address),interest(兴趣),phone(电话号码),education(教育经历) id 为主键,并且为每个Column选择对应的数据类型。 注意:interest 的数据类型是set ,phone的数据类型是list,education 的数据类型是map
sql
CREATE TABLE student(
id int PRIMARY KEY,
name text,
age int,
gender tinyint,
address text ,
interest set<text>,
phone list<text>,
education map<text, text>
);2.3cassandra的索引(KEY)
Cassandra的5种Key
- Primary Key
- Partition Key
- Composite Key
- Compound Key
- Clustering Key
1)Primary Key
是用来获取某一行的数据, 可以是单一列(Single column Primary Key)或者多列(Composite Primary Key)。
sql
在 Single column Primary Key 决定这一条记录放在哪个节点。
create table testTab (
id int PRIMARY KEY,
name text
);2)Composite Primary Key
如果 Primary Key 由多列组成,那么这种情况称为 Compound Primary Key 或 Composite Primary Key。
sql
create table testTab (
key_one int,
key_two int,
name text,
PRIMARY KEY(key_one, key_two)
);3)Partition Key
在组合主键的情况下(上面的例子),第一部分称作Partition Key(key_one就是partition key),第二部分是CLUSTERING KEY(key_two)
Cassandra会对Partition key 做一个hash计算,并自己决定将这一条记录放在哪个节点。
如果 Partition key 由多个字段组成,称之为 Composite Partition key
sql
create table testTab (
key_part_one int,
key_part_two int,
key_clust_one int,
key_clust_two int,
key_clust_three uuid,
name text,
PRIMARY KEY((key_part_one,key_part_two), key_clust_one, key_clust_two, key_clust_three)
);4)Clustering Key
决定同一个分区内相同 Partition Key 数据的排序,默认为升序,可以在建表语句里面手动设置排序的方式
2.4修改表结构
sql
添加列,语法
ALTER TABLE table name ADD new column datatype;
删除列,语法
ALTER table name DROP columnname;2.5删除表
sql
语法
DROP TABLE <tablename>2.6清空表
sql
语法
TRUNCATE <tablename>2.7创建索引
sql
普通列创建索引
CREATE INDEX <identifier> ON <tablename>
集合列创建索引
CREATE INDEX ON student(interest); -- set集合添加索引
CREATE INDEX mymap ON student(KEYS(education)); -- map结合添加索引效果:2.8 删除索引
sql
语法
DROP INDEX <identifier>3、查询数据
sql
使用 SELECT 、WHERE、LIKE、GROUP BY 、ORDER BY等关键词
SELECT FROM <tablename>
SELECT FROM <table name> WHERE <condition>;查询时使用索引
- Primary Key 只能用 = 号查询
- 第二主键 支持= > < >= <=
- 索引列 只支持 = 号
- 非索引非主键字段过滤可以使用ALLOW FILTERING
ALLOW FILTERING是一种非常消耗计算机资源的查询方式。 如果表包含例如100万行,并且其中95%具有满足查询条件的值,则查询仍然相对有效,这时应该使用ALLOW FILTERING。
如果表包含100万行,并且只有2行包含满足查询条件值,则查询效率极低。Cassandra将无需加载999,998行。如果经常使用查询,则最好在列上添加索引。
ALLOW FILTERING在表数据量小的时候没有什么问题,但是数据量过大就会使查询变得缓慢。
查询时排序
cassandra也是支持排序的,order by。 排序也是有条件的
- 必须有第一主键的=号查询,cassandra的第一主键是决定记录分布在哪台机器上,cassandra只支持单台机器上的记录排序。
- 只能根据第二、三、四...主键进行有序的,相同的排序。
- 不能有索引查询,cassandra的任何查询,最后的结果都是有序的,内部就是这样存储的。
分页查询
使用limit 关键字来限制查询结果的条数 进行分页
4、添加数据
sql
语法
INSERT INTO <tablename>(<column1 name>, <column2 name>....) VALUES (<value1>, <value2>....) USING <option>5、更新列数据
更新表中的数据,可用关键字:
- Where - 选择要更新的行
- Set - 设置要更新的值
- Must - 包括组成主键的所有列
在更新行时,如果给定行不可用,则UPDATE创建一个新行
sql
语法
UPDATE <tablename>
SET <column name> = <new value>
<column name> = <value>....
WHERE <condition>更新简单数据
sql
把id = 1012 的数据的gender列 的值改为1,代码:
UPDATE student set gender = 1 where id= 1012;更新set类型数据
sql
在student中interest列是set类型
1)添加一个元素
使用UPDATE命令 和 '+' 操作符
代码:
UPDATE student SET interest = interest + {'游戏'} WHERE id = 1012;
2)删除一个元素
使用UPDATE命令 和 '-' 操作符
代码:
UPDATE student SET interest = interest - {'电影'} WHERE id = 1012;
3)删除所有元素
可以使用UPDATA或DELETE命令,效果一样
代码:
UPDATE student SET interest = {} WHERE id = 1012;
或
DELETE interest FROM student WHERE id = 1012;更新list类型数据
sql
使用UPDATA命令向list插入值
代码:
UPDATE student SET phone = ['020-66666666', '13666666666'] WHERE id = 1012;
在list前面插入值
代码:
UPDATE student SET phone = [ '030-55555555' ] + phone WHERE id = 1012;
在list后面插入值
代码:
UPDATE student SET phone = phone + [ '040-33333333' ] WHERE id = 1012;
使用列表索引设置值,覆盖已经存在的值
这种操作会读入整个list,效率比上面2种方式差
现在把phone中下标为2的数据,也就是 "13666666666"替换,代码:
UPDATE student SET phone[2] = '050-22222222' WHERE id = 1012;
【不推荐】使用DELETE命令和索引删除某个特定位置的值
非线程安全的,如果在操作时其它线程在前面添加了一个元素,会导致移除错误的元素
代码:
DELETE phone[2] FROM student WHERE id = 1012;
【推荐】使用UPDATE命令和'-'移除list中所有的特定值
代码:
UPDATE student SET phone = phone - ['020-66666666'] WHERE id = 1012;更新map类型数据
sql
map输出顺序取决于map类型。
1)使用Insert或Update命令
UPDATE student SET education=
{'中学': '城市第五中学', '小学': '城市第五小学'} WHERE id = 1012;
2)使用UPDATE命令设置指定元素的value
UPDATE student SET education['中学'] = '爱民中学' WHERE id = 1012;
3)可以使用如下语法增加map元素。如果key已存在,value会被覆盖,不存在则插入
UPDATE student SET education = education + { '幼儿园' : '大海幼儿园', '中学': '科技路中学'} WHERE id = 1012;
4)删除元素
可以用DELETE 和 UPDATE 删除Map类型中的数据
使用DELETE删除数据
DELETE education['幼儿园'] FROM student WHERE id = 1012;
使用UPDATE删除数据
UPDATE student SET education=education - {'中学','小学'} WHERE id = 1012;6、删除行
sql
语法
DELETE FROM <identifier> WHERE <condition>;7、批量操作
把多次更新操作合并为一次请求,减少客户端和服务端的网络交互。 batch中同一个partition key的操作具有隔离性
sql
SQL语法
使用BATCH,您可以同时执行多个修改语句(插入,更新,删除)
BEGIN BATCH
<insert-stmt>/ <update-stmt>/ <delete-stmt>
APPLY BATCH
JAVA语法
@Resource
private CassandraTemplate cassandraTemplate;
// 批量插入
public void insert(){
CassandraBatchOperations batchOps = cassandraTemplate.batchOps();
batchOps.insert(List<entity>);
batchOps.execute();
}