1、发现问题
使用read读取文本文件,一般采用字符空间作为缓存,最后输出;
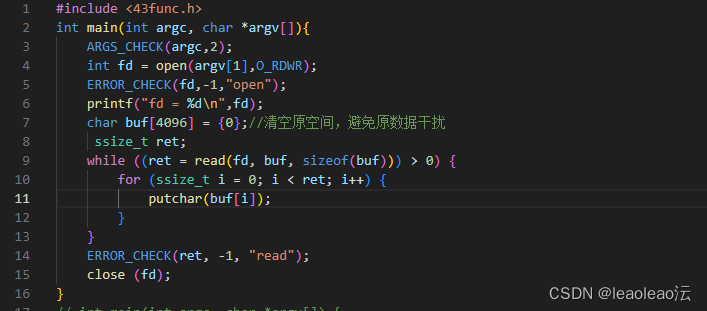
使用read读取二进制文件,这里采用整数读取的展示:
首先创建文本文件,用write写入i的值到文件中;

再通过lseek改变读写一个文件时的读写指针位置,用SEEK_SET把指针设置回起始位置;
然后再次把读取到的数据写入整型变量a的地址,直接%d输出。

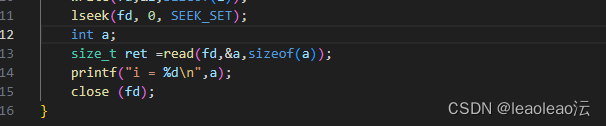

问题1:为什么文本文件要用字符数组,而二进制文件要用变量名的地址呢。
问题2:在打开文件对象时,文件是什么格式传输的。
问题3:可以通用转化read吗,这样会不会有些麻烦?
2、解决问题:
通过改变文本文件的内容发现规律:
首先把文本文件内容设置成1234;
通过字符数组read并打印时,屏幕输出结果正常为1234;


通过整型变量的方式来输出时:输出了一串数字;

刚开始认为时整型变量的首地址,但是经过增加或删除文本文档的1234,发现数据也会变,故认定不是首地址;
询问老师后老师让我采用16进制输出看一下:
于是出现了34333531,每两位十六进制代表一字节当我把他们分开发现:
34 33 32 31 (这不就是1234的ASCII码的逆序吗,恍然大悟)

于是又产生问题:为什么输出出来是4321;
查资料后得知,
关键点在于计算机内部的数据存储方式,即所谓的字节序(Endian)**问题。
-
小端序存储(Little Endian):
- 在小端序存储中,低位字节(即最小的有效字节)存储在内存的低地址处,而高位字节则存储在高地址处。
- 例如,对于整数值
0x1234,在小端序存储中,内存中的存储方式是34 12(最低有效字节34存储在低地址处,高有效字节12存储在高地址处)。
-
ASCII 码的影响:
- 当你的程序读取文本文件中的字符时,它实际上读取的是每个字符的 ASCII 码值。例如,字符
'1'的 ASCII 码是49,字符'2'的 ASCII 码是50,以此类推。
- 当你的程序读取文本文件中的字符时,它实际上读取的是每个字符的 ASCII 码值。例如,字符
-
输出的十六进制值
34333231解释:- 对于字符串 "1234.",它的 ASCII 码值依次是
49('1'),50('2'),51('3'),52('4'),46('.'). - 这些 ASCII 码值在内存中按照小端序排列:
31 32 33 34 2E(以十六进制表示)。 - 当程序以整数的方式读取并输出这些字节时,它会按照内存中的存储顺序解释这些字节,因此得到的结果是
34333231。这是因为在小端序存储中,低位字节31存储在低地址处,高位字节34存储在高地址处,因此以整数形式输出时,反映了这种存储顺序。
- 对于字符串 "1234.",它的 ASCII 码值依次是
-
为什么不是
31323334:- 如果是
31323334,那意味着程序以大端序方式(高位字节在低地址处)解释这些字节,这通常不是现代计算机的默认方式。现代计算机大多数采用小端序存储,因此输出的结果是34333231。
- 如果是
综上所述,输出的十六进制值 34333231 是根据小端序存储方式下字符的 ASCII 码值在内存中的排列顺序决定的。
假设我们有一个四字节(32位)的整数 0x12345678 在内存中的表示。在小端序存储下,它会按照以下方式存储在内存中的连续四个字节:

在这个例子中:
- 内存地址从低到高依次是
0x1000,0x1001,0x1002,0x1003。 - 整数
0x12345678的最低有效字节78存储在最低地址0x1000处。 - 随后的字节
56,34,12分别按照顺序存储在接下来的高地址处。
这种排列方式反映了小端序存储的特性,即低位字节存储在低地址处,高位字节存储在高地址处。这种存储方式对于计算机架构和处理器的设计有重要影响,因为它决定了如何解释存储在内存中的数据。
当解决了输出顺序的问题,开头的问题也随之解决;
不论是文本文件还是二进制文件在文件系统中都是以二进制数据流在传输,当使用read读取文本文件时,使用字符数组的原因在于字符数组可以按字节存储字符文本。最后输出字符数组即可;
当使用read去读文本文件时,用整型变量去存文本文件时,int在测试的系统中占4字节,所以输出结果中刚好存下1234这个四个字符的大小,但是直接用%xd输出则是这四个字符的ASCII码值的十六进制表示;再因为小端序储存所以输出34333231;
要解决问题可以直接把输出结果改成%c或%s输出;
存储到 int 变量中会按照整型数据的方式存储,而不是直接按字符存储。所以,如果将 "1234" 存储到 int 中,可能会得到一个整数值,而不是字符序列。
把int改成char
再把输出改成%c

这样就得到了文本文件中的字符;
3、得出结论:
在 C 语言中,字符数组是一种非常方便的数据结构,用于存储和操作字符串。对于将十六进制字符串转换为文本字符的问题,字符数组的使用有以下优势和特点:
-
内存管理和访问:
- 字符数组在 C 语言中使用非常广泛,因为它们允许直接存储和处理字符序列,包括字符串。在转换过程中,我们可以通过索引直接访问和修改数组的元素,这样能够高效地处理每对十六进制字符,并将其转换为相应的 ASCII 字符。
-
动态内存分配:
- 使用字符数组可以灵活地处理字符串的长度。在示例中,我们使用
malloc动态分配内存来存储转换后的文本字符串。这使得程序可以处理不同长度的输入,而不需要预先定义固定大小的数组。
- 使用字符数组可以灵活地处理字符串的长度。在示例中,我们使用
-
字符串终止符:
- C 语言中的字符串以
'\0'结尾,这使得处理和操作字符串变得更加方便和安全。在示例中,我们在转换完成后,手动添加了'\0'终止符来确保字符串的完整性。
- C 语言中的字符串以
-
简洁性和性能:
- 字符数组提供了一种简洁且高效的方法来处理字符串转换任务。通过使用循环和逐对处理的方式,可以在不牺牲性能的情况下完成必要的数据转换操作。
-
C 语言的特性:
- C 语言天生支持字符数组和指针操作,这使得处理字符串(包括 ASCII 和十六进制字符)的任务变得非常直接和灵活。
总之,字符数组在 C 语言中是一种非常适合处理字符串和字符序列的数据结构,特别是在需要进行类似于十六进制到 ASCII 字符的转换时。它们提供了足够的灵活性和性能,使得开发者能够有效地实现各种字符串操作。
虽然不同的数据在内存中的表现形式可能相同,但在读取时仍需按照数据最初存储的格式进行操作,以避免误读和解码错误等问题。
注意:
字符流的本质是一种数据流,它由一系列字符组成,每个字符都有对应的编码。在许多编程环境中,字符流通常指的是一系列字符构成的数据流,这些字符可以按顺序读取或写入。
-
文本文件中的结束符号 :在文本文件中,通常使用特定的字符来表示文件的结束,如换行符
\n或文件结束符\0。这些符号并不总是以特定的形式出现在存储介质上,而是由读取程序解释。 -
二进制流:二进制流可以是任何数据的序列,包括字符流。二进制流不一定有明确的结束符号,它可能以特定的长度或特定的约定来表示数据的结束。