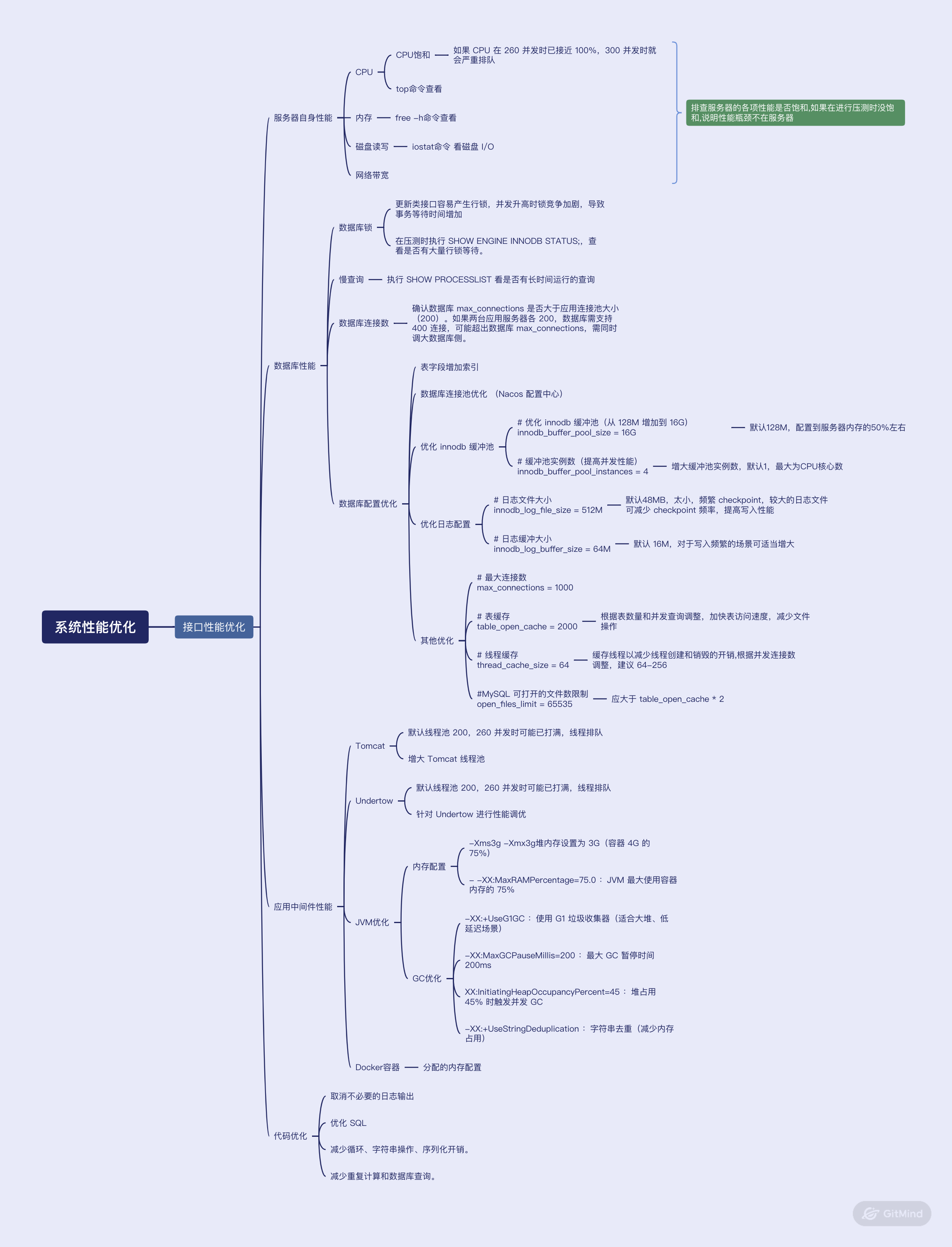
最近所做的项目在进行第三方软件测试,在进行性能测试时存在部分接口不达标的情况,需要进行性能优化,所以整理个性能优化流程步骤和方法。系统性能指标要求300并发用户数同时进行修改功能操作,平均响应时间需要小于0.8秒,也就是800毫秒。但接口测下来基本都在1.7秒左右,达不到要求,所以需要进行性能优化。那怎么进行性能优化呢?下图是我列的一个纲。
一、先对接口进行性能调用测试,测试工具可以用阿帕奇开源的JMeter测试工具
一、下载JMeter地址
https://jmeter.apache.org/download_jmeter.cgi
下载好后,安装JKD1.8的版本,该测试工具是通过JDK运行的。JDK的下载和配置在这里就不演示了,JDK配置完后,就可以运行了。进入它的bin文件后,Windows端双击jmeter.bat,macOS 使用sh jmeter.sh命令运行
启动之后可以先改下测试工具言语为中文,方便阅读查看,改完之后就可以进行测试的配置操作了。
二、接口测试的基础配置
1、先添加测试计划
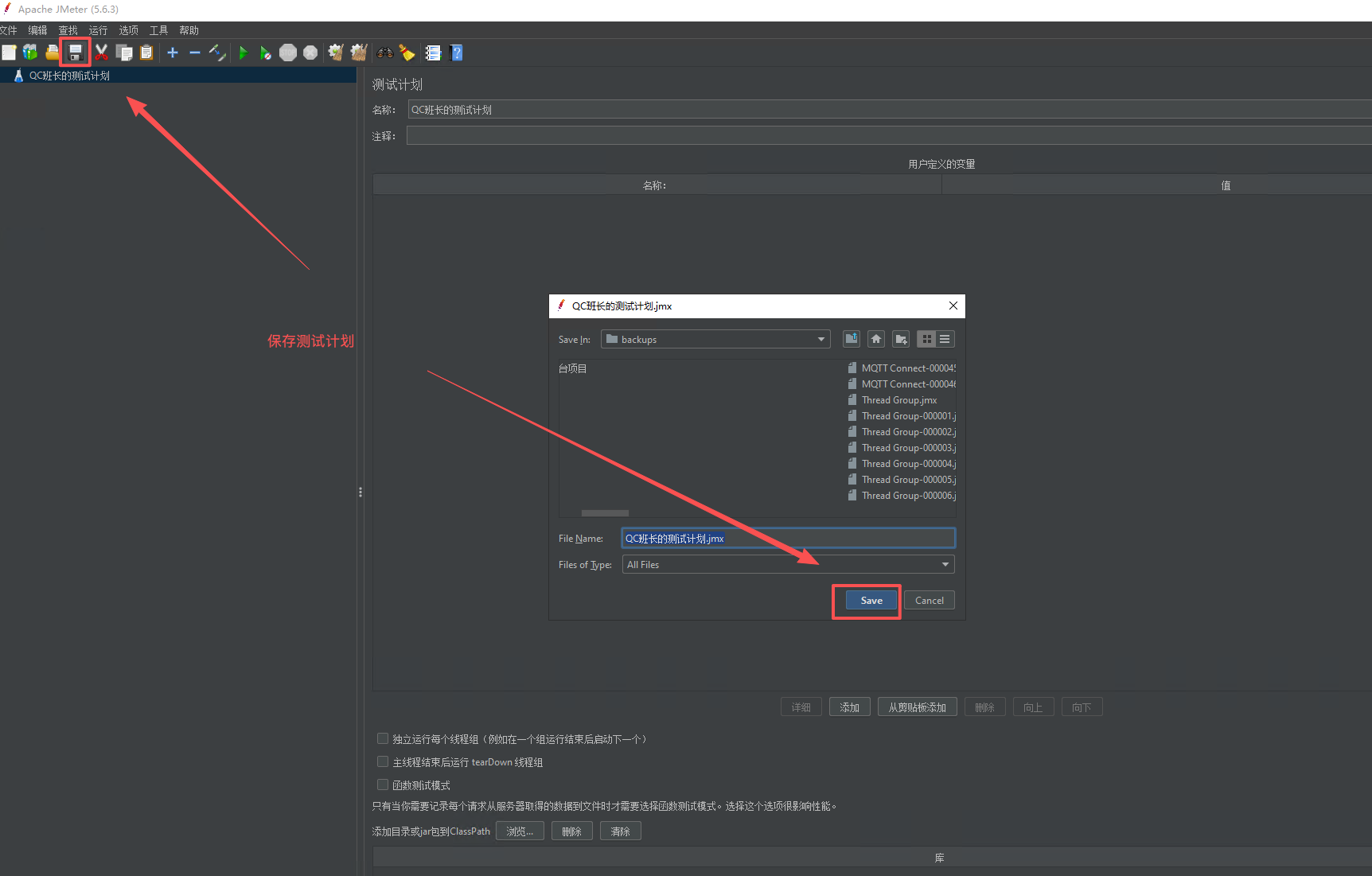
2、添加线程组
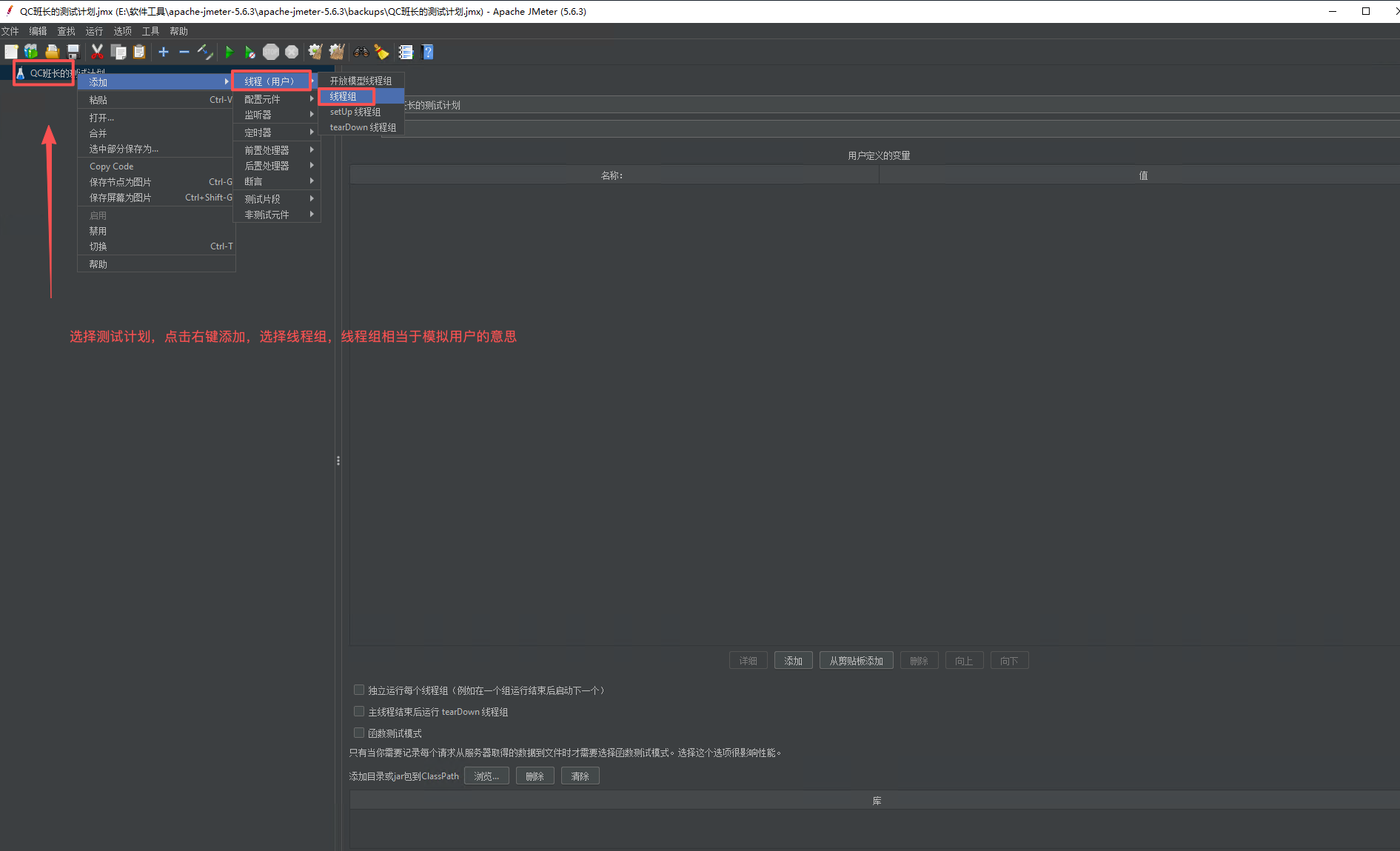
3、配置线程组,然后记得点击保存
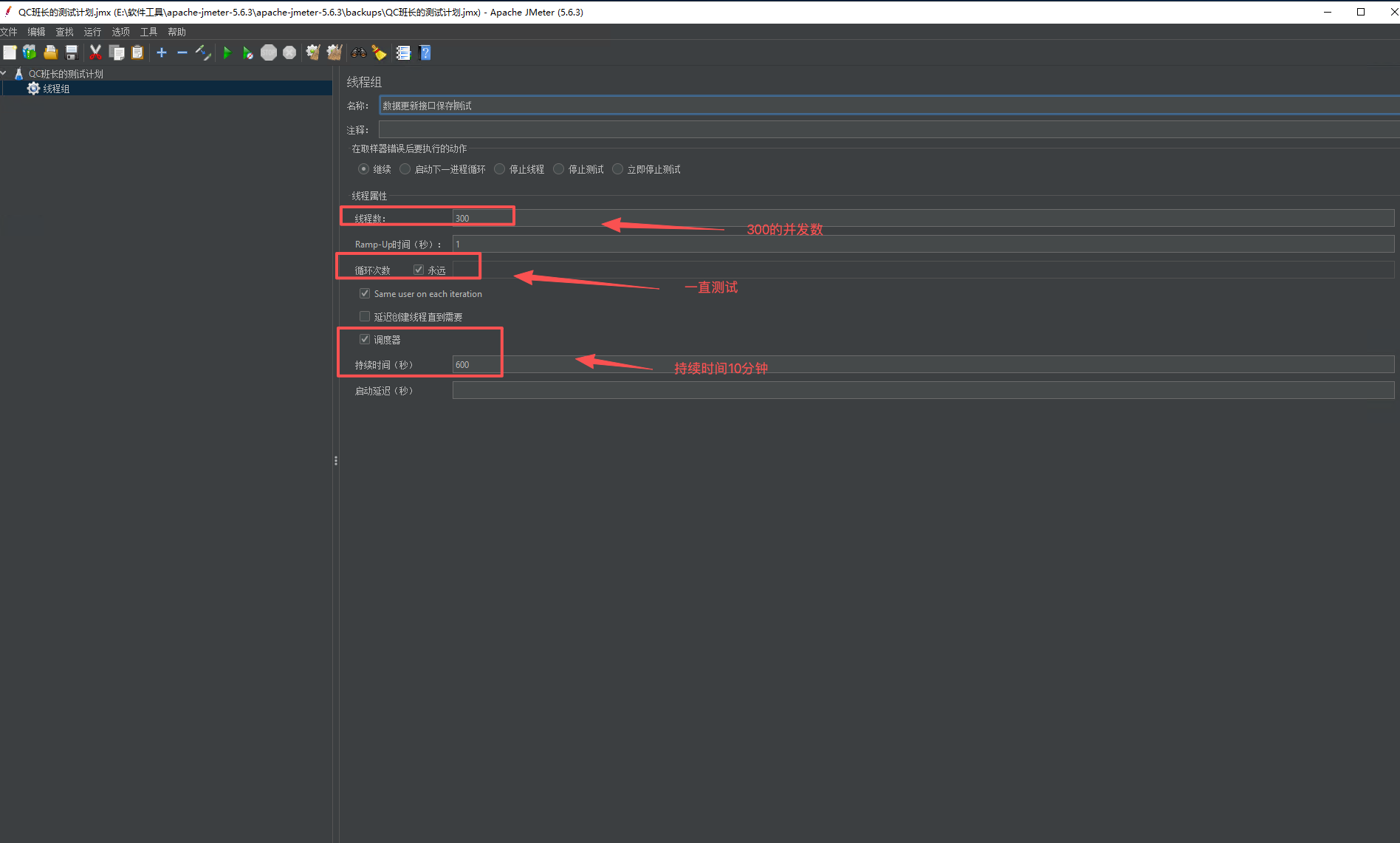
4、添加被测试接口
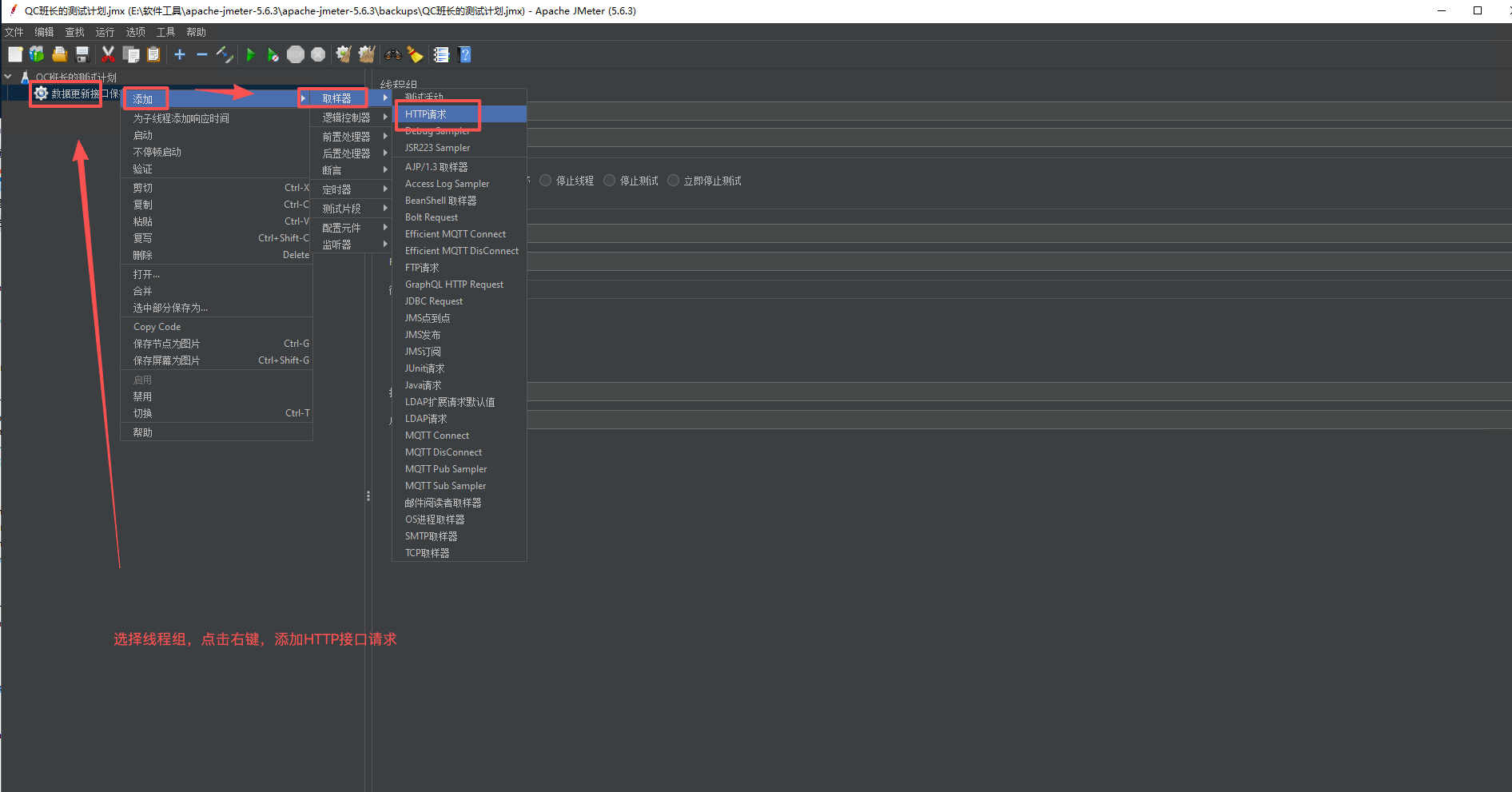
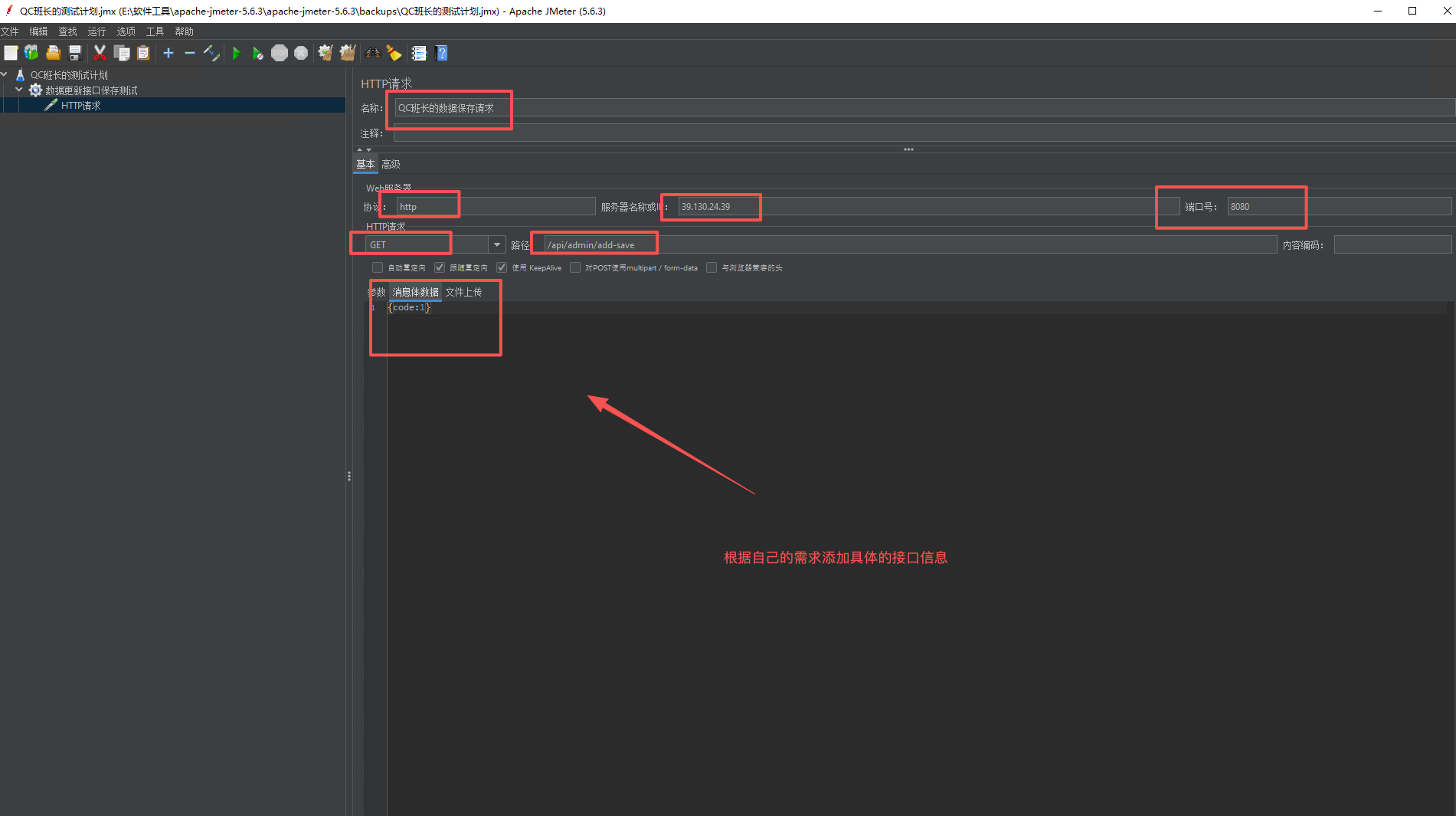
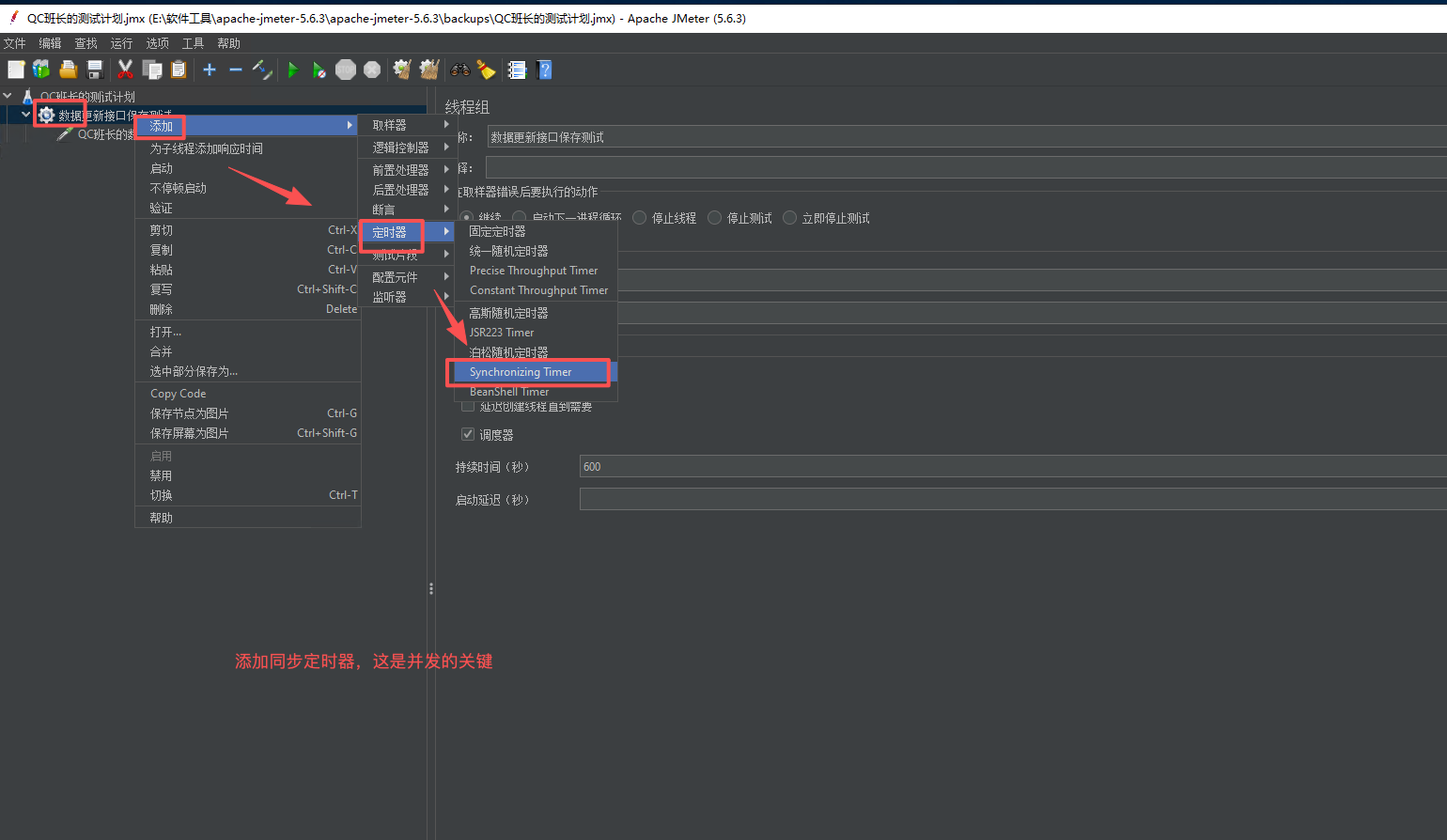
5、添加同步定时器,这是并发模拟的关键
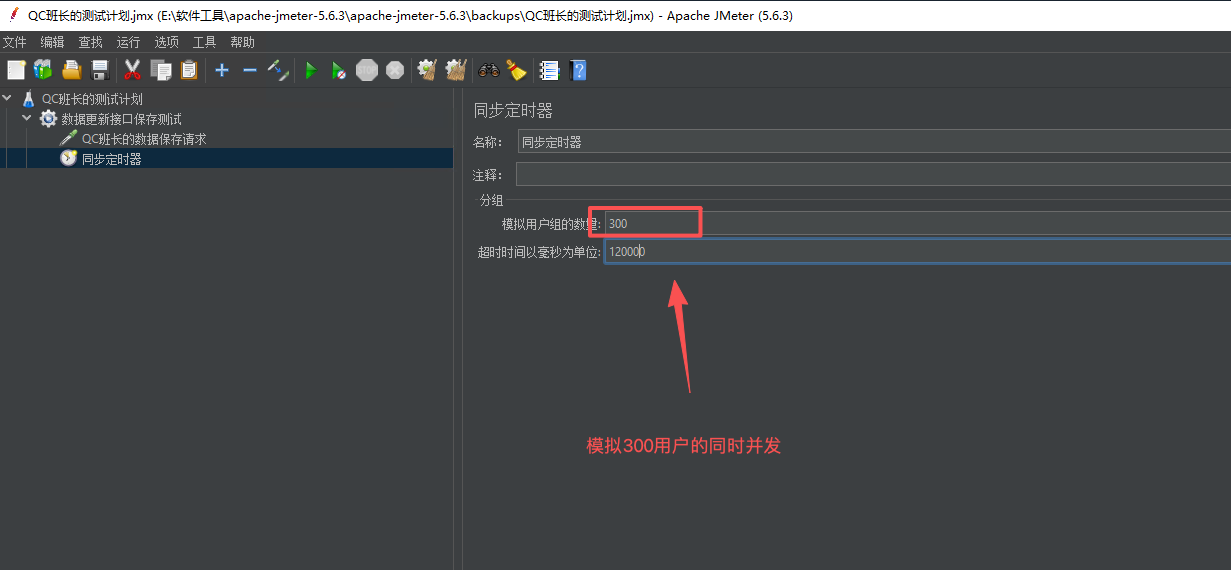
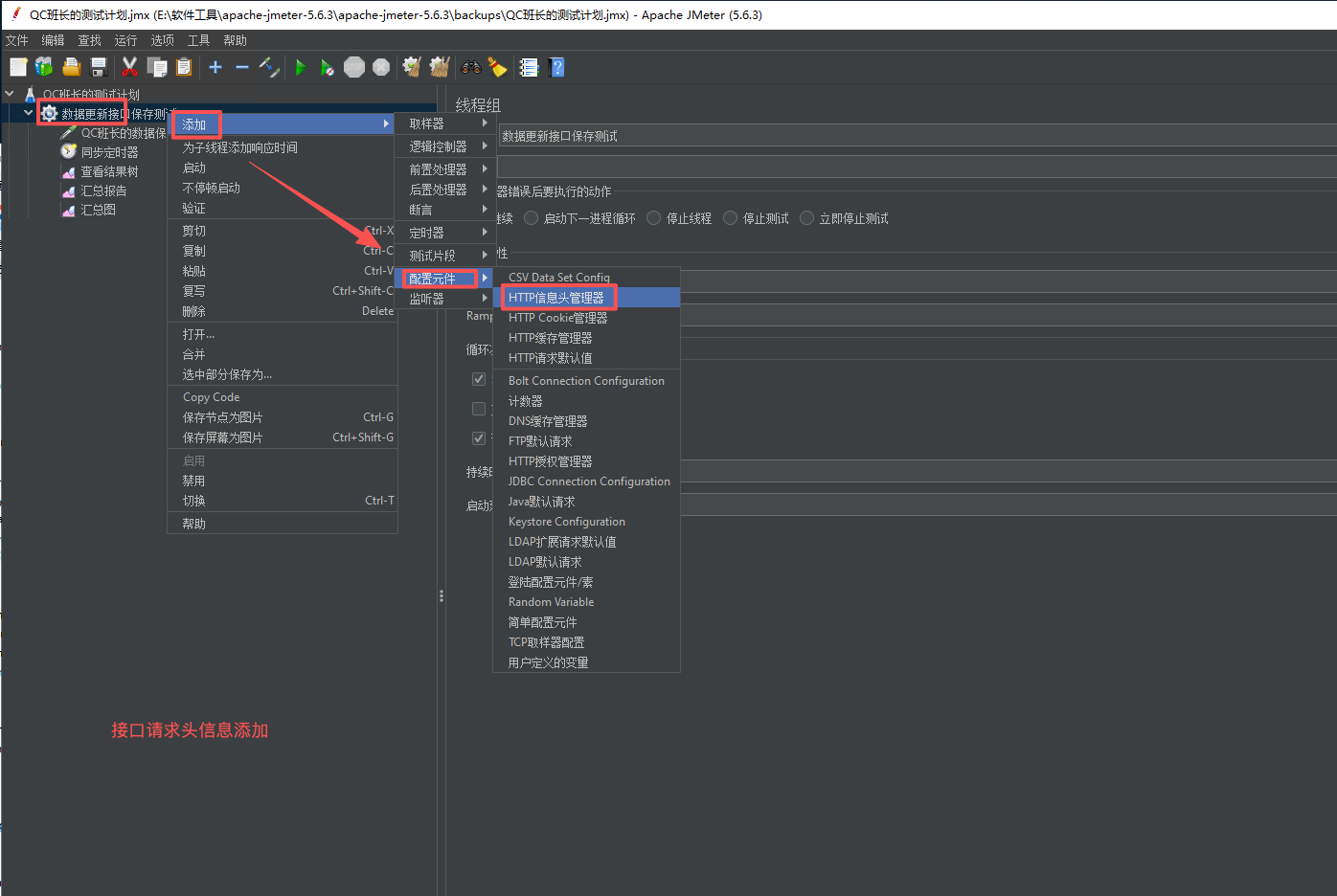
6、接口请求头信息添加,添加接口需要的token
7、添加结果树,方便查看测试结果
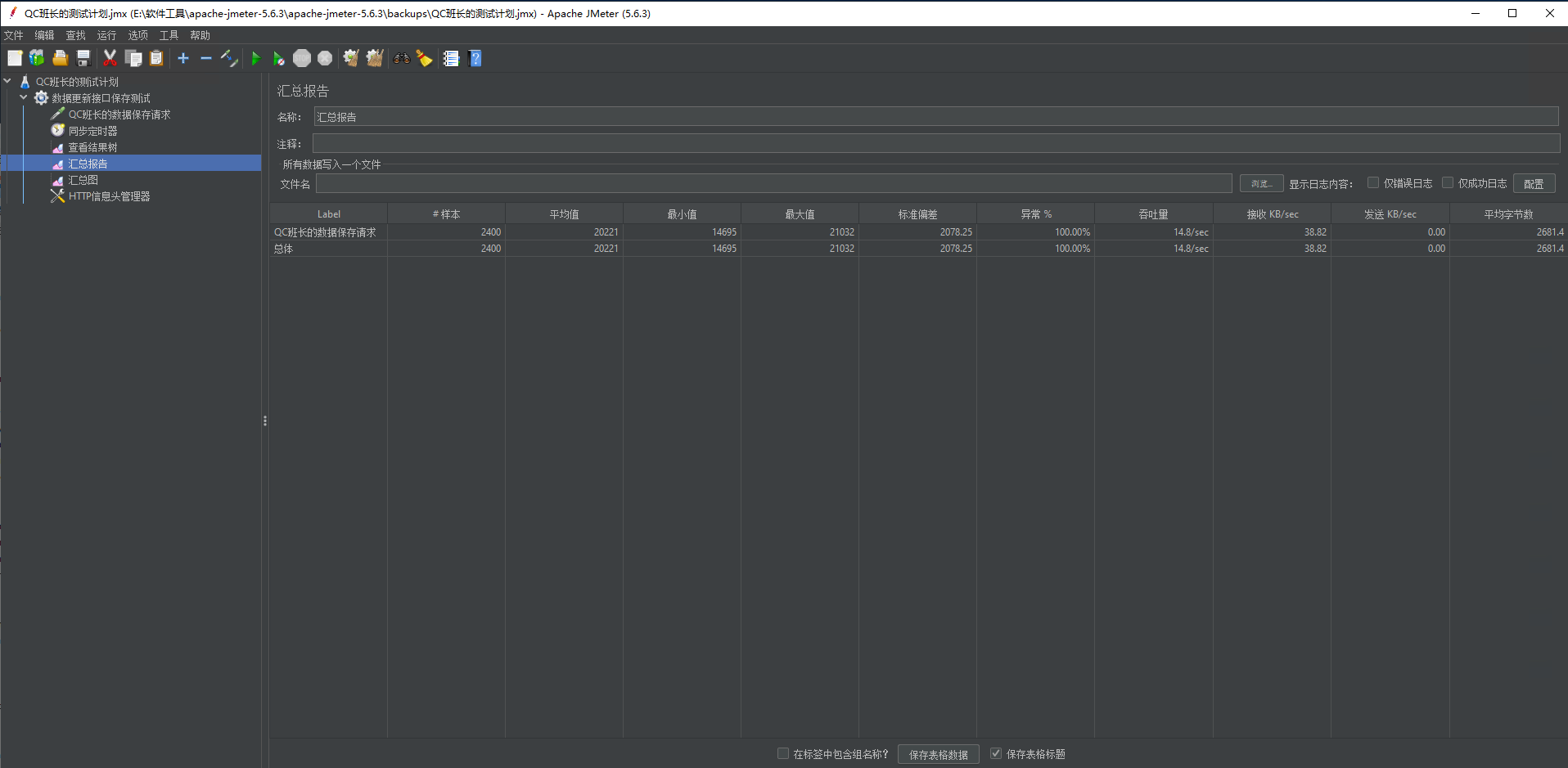
8、添加汇总报告,汇总报告可以查看相关关键指标。
9、添加汇总图结果图,方便查看.
测试工具的添加配置基本就完,更多配置可以自己去查,比如参数化配置,也就是测试时自动生成不同的参数,还有其他的,你可以自行去了解。
三、启动测试
这样就基本完成了,选择线程组单击右键,启动测试
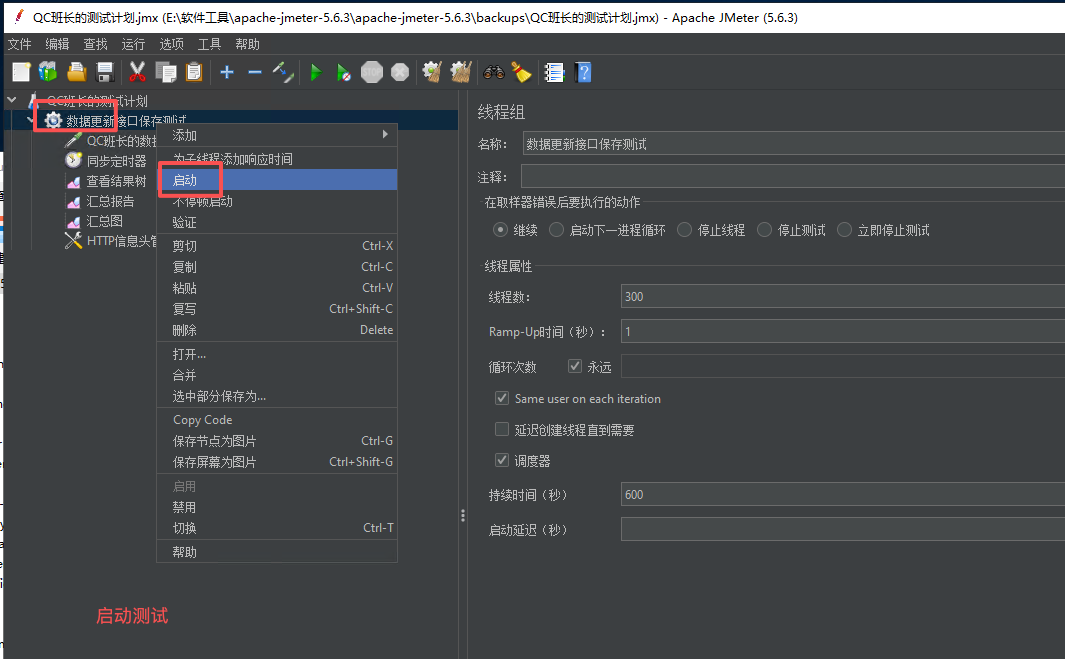
在结果树这里可以每次请求的结果
汇总报告这里可以查看相关指标
四、接口性能优化
1、测试时可以梯度增加并发用户数,比如300并发不满足要求,那就减半150看看能不能满足并发。像我这个项目的接口,250的并发是满足的,再往上走就不满足了。这时候,在测试时,就要查看整条链路的各个环节的性能瓶颈。逐个排查,排除可能性。下图是一个接口请求所经过的各个环节,可以根据各个环节去排查性能瓶颈。
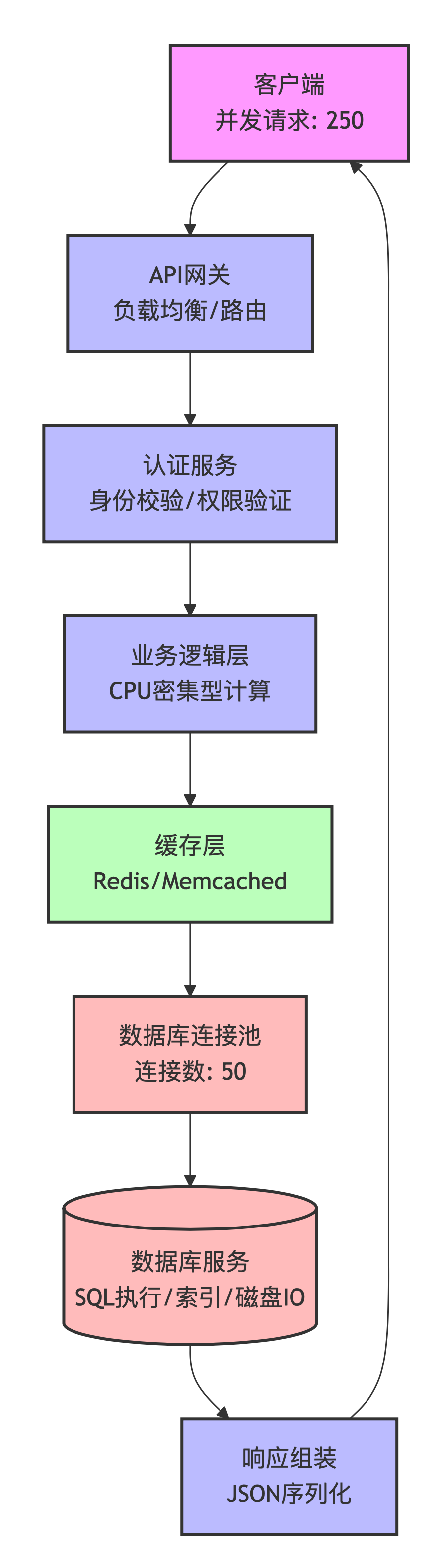
2、现在AI已经非常方便了,排查问题可以直接问大模型,把测试数据对给它,然后让它分析,逐个指导解决,基本上很快就能找到性能瓶颈点,然后优化。举一个我自己测试的接口,下面是各个环节的基本的性能优化点。
我的一个更新类的接口,260的并发刚好在800毫秒内,300就超过800毫秒了,这种是不是服务器性能问题了?
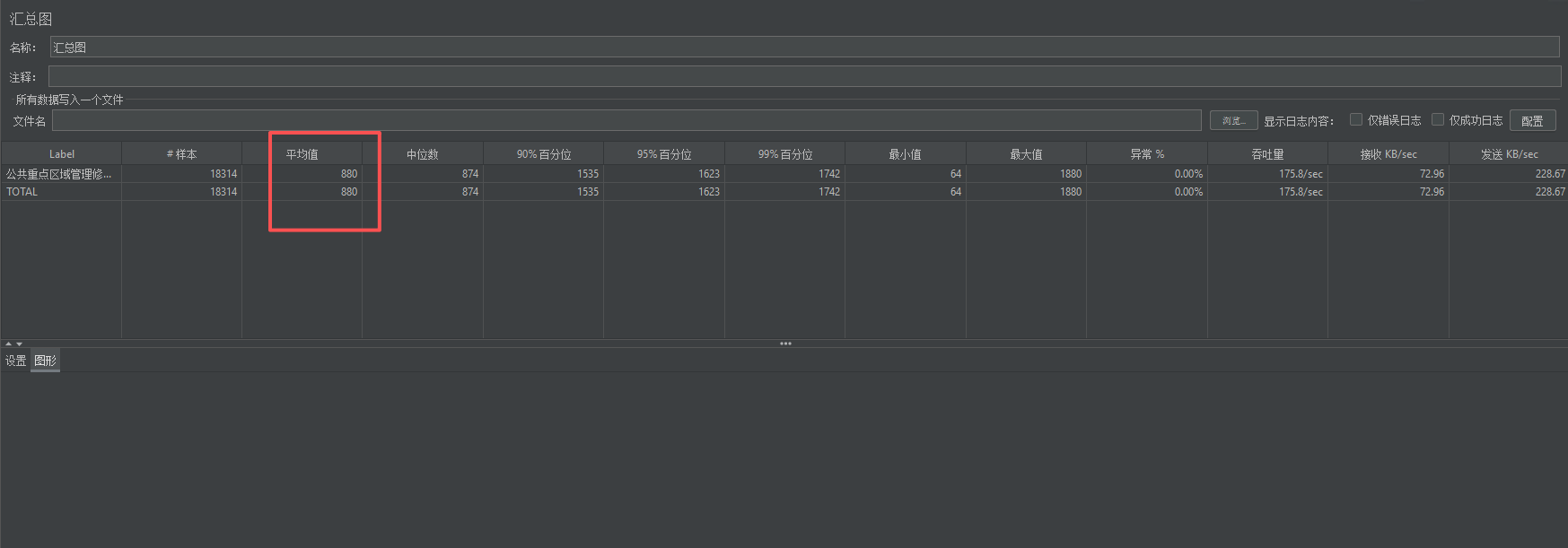
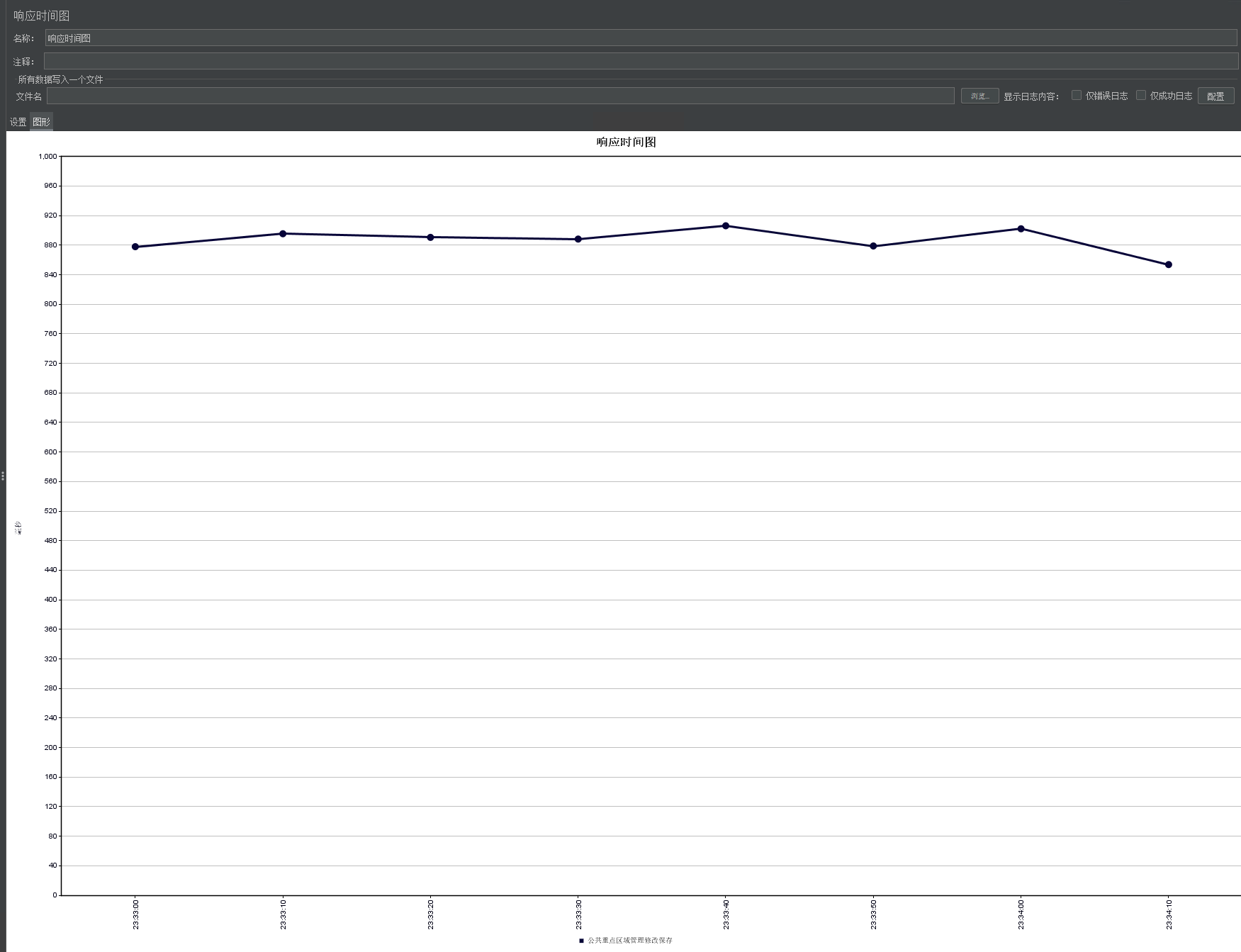
这个现象说明了什么?
1️⃣ 系统存在明确的性能拐点
-
在 260 并发时,系统还能勉强应对,响应时间控制在 800ms 以内。
-
当并发增加到 300(增加约 15%),响应时间跃升到 900ms 以上(增加 12.5% 以上),且吞吐量停滞在 170/sec 左右。
-
这符合 Little 定律 和排队论模型:当并发超过系统最大处理能力时,请求开始大量排队,响应时间与(并发数 - 处理能力)成正比增长。
2️⃣ 瓶颈不在客户端,而在服务端
-
JMeter 本身能够稳定产生 300 并发(你之前的测试已验证),所以不是压测工具的问题。
-
响应时间的增加完全由服务端处理变慢引起。
3️⃣ 瓶颈可能的位置
根据你之前的排查(数据库连接池已调至 200、日志级别已优化、网络延迟正常),当前最可能的瓶颈按概率排序:
| 可能性 | 瓶颈类型 | 判断依据 |
|---|---|---|
| ⭐⭐⭐ | 数据库锁或慢 SQL | 更新类接口容易产生行锁,并发升高时锁竞争加剧,导致事务等待时间增加 |
| ⭐⭐ | 应用服务器线程池 | 默认 Tomcat 线程池 200,260 并发时可能已打满,线程排队 |
| ⭐⭐ | CPU 饱和 | 如果 CPU 在 260 并发时已接近 100%,300 并发时就会严重排队 |
| ⭐ | 内存/GC 问题 | 并发升高导致对象分配加快,GC 频率增加,暂停时间延长 |
| ⭐ | 外部依赖瓶颈 | 如 Redis、其他微服务接口变慢 |
📊 如何精确定位拐点处的瓶颈?
既然你已经通过阶梯加压找到了拐点(260 → 300),接下来可以在300 并发测试时,同步收集以下数据,对比 260 并发时的状态:
1️⃣ 应用服务器监控
重点看:
-
CPU 是否从 260 时的 80% 飙升到 300 时的 95%+?
-
活跃线程数是否达到
max-threads(默认 200)? -
GC 时间是否明显增加(特别是 FGC 出现或 YGC 耗时变长)?
bash
# CPU 使用率
top -b -n 1 | grep Cpu
# Tomcat 线程池活跃数(需开启 Actuator)
curl http://localhost:8080/actuator/metrics/tomcat.threads.busy
# GC 情况
jstat -gcutil <pid> 1000 52️⃣ 数据库监控
重点看:
-
是否有大量
UPDATE语句处于Locked或Updating状态? -
数据库 CPU 使用率是否飙高?
-
连接数是否达到
max_connections?
bash
-- 查看当前正在执行的查询
SHOW FULL PROCESSLIST;
-- 查看 InnoDB 锁状态
SHOW ENGINE INNODB STATUS;
-- 查看慢查询日志(需提前开启)3️⃣ 代码热点(Arthas)
在 300 并发时运行:
观察是否有方法的执行时间从 260 时的 200ms 暴涨到 300 时的 400ms+。
bash
# 监控最耗时的方法调用
trace -E com.example.service|com.example.controller .* '#cost > 200' -n 5🧠 Undertow 的线程模型简介
Undertow 采用 IO 线程 和 工作线程 分离的模型:
-
IO 线程 (
io-threads):负责处理网络连接、读写数据,通常数量较少(默认 = CPU 核心数)。 -
工作线程 (
worker-threads):负责处理实际的业务逻辑(如 Controller 方法、数据库操作等),默认值较高(通常为 CPU 核心数 × 8,但有一个上限,如 200 左右)。
你的性能瓶颈(260 并发 → 响应时间跃升)很可能与 工作线程池过小 或 IO 线程处理能力不足 有关。
五、测试出一个个性能瓶颈点后就是针对其做优化
✅ 如何针对 Undertow 进行优化
1️⃣ 查看当前 Undertow 线程池配置(默认值)
Spring Boot 对 Undertow 的默认配置大致为:
-
server.undertow.io-threads:默认 = CPU 核心数 -
server.undertow.worker-threads:默认 = CPU 核心数 × 8(但最大不超过 200 左右)
你可以通过以下方式确认实际生效的值:
-
启动日志中会打印 Undertow 相关的线程池信息(需开启 debug 日志)。
-
使用 Actuator 端点:
/actuator/metrics/undertow.worker.threads.busy和undertow.worker.threads.total。
2️⃣ 在 Nacos 配置中增加 Undertow 专用配置
在 prod.yml 中添加(与 spring 平级):
yaml
server:
undertow:
# IO 线程数,默认 = CPU 核心数,一般不需要修改
io-threads: 4
# 工作线程数,默认 = CPU 核心数 × 8,可根据需要调大
worker-threads: 400
# 每个缓冲区大小,默认 1024 字节,通常无需修改
buffer-size: 1024
# 是否分配直接内存(DirectBuffer)
direct-buffers: true关键参数:
-
worker-threads:相当于 Tomcat 的max-threads,是处理业务请求的最大线程数。你可以尝试从默认值(如 200)调大到 400 或 800,观察性能变化。 -
io-threads:一般保持默认(CPU 核心数)即可,除非网络连接极高。
3️⃣ 重启应用使配置生效
修改 Nacos 配置后,必须重启应用,因为 Undertow 的线程池在启动时初始化,无法动态刷新。
4️⃣ 重新压测并观察
-
使用相同的 300 用户 + 同步定时器测试。
-
关注 平均响应时间 和 吞吐量 是否有改善。
-
同时监控服务器 CPU 和内存,确保调整后资源足够。
如果调整后改善不明显,继续排查其他瓶颈。
排查数据库瓶颈,执行数据库引擎性能分析,然后把结果丢给大模型,让它帮你分析。


java
# ============= MySQL 性能优化 ============================================
# InnoDB 缓冲池
# 作用 :设置 InnoDB 缓冲池大小 原理 :缓冲池是 InnoDB 存储引擎的核心内存结构,用于缓存表数据和索引 设置依据 :通常设置为服务器内存的 50-70%,32G 适合 16G 内存的服务器 性能影响 :增大缓冲池可减少磁盘 I/O,显著提升查询性能
innodb_buffer_pool_size = 16G
# 作用 :设置缓冲池实例数量 原理 :将缓冲池分成多个实例,减少锁竞争,提高并发性能 设置依据 :建议每 1-2G 缓冲池设置一个实例 性能影响 :适用于多核服务器,提高并发处理能力
innodb_buffer_pool_instances = 8
# InnoDB 日志
#作用 :设置 InnoDB 重做日志文件大小 原理 :日志文件用于崩溃恢复,大小影响 checkpoint 频率 设置依据 :建议设置为 256M-1G,平衡恢复速度和磁盘空间 性能影响 :较大的日志文件可减少 checkpoint 频率,提高写入性能
innodb_log_file_size = 512M
# 作用 :设置 InnoDB 日志缓冲大小 原理 :用于临时存储待写入磁盘的日志数据 设置依据 :默认 16M,对于写入频繁的场景可适当增大 性能影响 :增大缓冲可减少磁盘 I/O 次数,提升写入性能
innodb_log_buffer_size = 64M
# 连接和缓存
# 作用 :设置线程缓存大小 原理 :缓存线程以减少线程创建和销毁的开销 设置依据 :根据并发连接数调整,建议 64-256 性能影响 :提高连接处理速度,减少服务器负载
thread_cache_size = 64
# 作用 :设置表缓存大小 原理 :缓存打开的表描述符,减少表打开操作 设置依据 :根据表数量和并发查询调整 性能影响 :加快表访问速度,减少文件操作
table_open_cache = 2000
# 作用 :设置 MySQL 可打开的文件数限制 原理 :MySQL 需要打开数据文件、日志文件等 设置依据 :应大于 table_open_cache * 2 性能影响 :避免因文件描述符不足导致的错误
open_files_limit = 65535现在的大模型确实已经非常的实用了,很多事情都可以交给它帮你完成。