C++初学者指南第一步---13.聚合类型
文章目录
- C++初学者指南第一步---13.聚合类型
-
- [1. 类型分类(简化)](#1. 类型分类(简化))
- [2. 如何定义和使用](#2. 如何定义和使用)
- [3. 为什么选择自定义类型/数据聚合?](#3. 为什么选择自定义类型/数据聚合?)
- [4. 聚合类型初始化](#4. 聚合类型初始化)
- 5.混合
- [6. 复制](#6. 复制)
- [7. 值和引用的语义](#7. 值和引用的语义)
- 8.聚合的向量(std::vector)
- 9.最令人烦恼的解析
1. 类型分类(简化)
| 基本类型 | void, bool, char, int, double, ... void、bool、char、int、double、... |
| 简单聚合 | 主要用途:对数据进行分组 聚合:可能包含一个/多个基本类型或其他兼容的聚合类型 无法控制组成类型的相互作用 简单,(编译器生成的)默认构造/析构/复制/赋值。 标准的内存布局(所有成员按照声明顺序连续布置),如果所有成员具有相同的访问控制(例如全部为public)。 |
| 更复杂的自定义类型 | 自定义不变量和对成员相互作用的控制 限制成员访问 具有成员函数 用户自定义构造/成员初始化 用户自定义的析构 / 复制 / 赋值 可以是多态的(包含虚成员函数) |
2. 如何定义和使用
示例:具有 2 个整数坐标的类型
代码段1
cpp
struct point {
int x; // ← "成员变量"
int y;
};
// 创建新对象 (在栈中)
point p {44, 55};
// 打印成员变量的值
cout << p.x <<' '<< p.y; // 44 55分配给成员变量值:(代码段2)
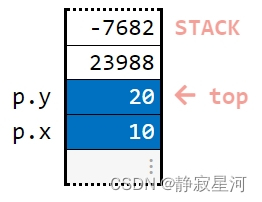
cpp
p.x = 10;
p.y = 20;
cout << p.x <<' '<< p.y; // 10 20成员变量的存储顺序与声明顺序相同。
代码段1的内存:
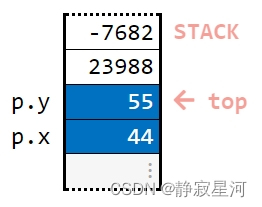
代码段2的内存:
运行上面代码
3. 为什么选择自定义类型/数据聚合?
接口变得更易于正确使用
- 语义数据分组: 点,日期...
- 避免了许多函数参数,从而减少了混乱。
- 函数可以使用一个专门的类型来返回多个值,而不是使用多个非常量引用输出参数。
不使用则会有糟糕的接口:
void closest_point_on_line (double lx2, double ly1, double lx2i, double ly2, double px, double py, double& cpx, double& cpy) { ... }- 许多相同类型的参数⇒容易编写错误
- 非常量引用输出参数 ⇒ 容易出错
- 线的内部表示也被嵌入到接口中
使用则好多了:
struct point { double x; double y; };
struct line { point a; point b; };
point closest_point_on_line (line const& l, point const& p) { ... }- 直接明了的接口
- 易于正确使用
- 如果线的内部表示更改了(例如,点+方向而不是2个点)⇒ 需要改变closest_point_on_line的实现方式,但其接口可以保持不变⇒ 大多数调用代码无需更改!
4. 聚合类型初始化
语法:
Type { arg1, arg2, ..., argN }-
花括号括起来的成员值列表
-
按成员声明顺序排列
enum class month {jan = 1, feb = 2,..., dec = 12};
struct date {
int yyyy;
month mm;
int dd;
};
int main () {
date today {2020, month::mar, 15};
// C++98的写法,依然正确:
date tomorrow = {2020, month::mar, 16};
}
5.混合
示例:作为 person 成员的日期
cpp
enum class month { jan=1, feb=2,... , dec=12 };
struct date {
int yyyy;
month mm;
int dd;
};
struct person {
std::string name;
date bday;
};
int main () {
person jlp { "Jean-Luc Picard", {2305, month::jul, 13} };
cout << jlp.name; // Jean-Luc Picard
cout << jlp.bday.dd; // 13
date yesterday { 2020, month::jun, 16 };
person rv = { "Ronald Villiers", yesterday };
}6. 复制
副本总是所有成员的深层拷贝!
cpp
enum class month {jan = 1, ... };
struct date {
int yyyy; month mm; int dd;
};
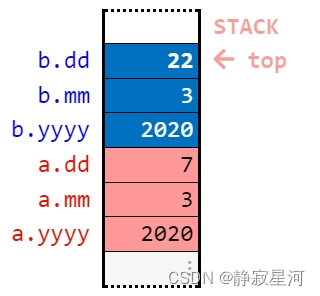
int main () {
date a {2020, month::mar, 7};
date b = a; // deep copy of a
b.dd = 22; // change b
}main 函数最后一行后的状态:
拷贝构造 = 创建一个具有与源相同值的新对象
拷贝赋值 = 使用源对象的值覆盖现有对象的值
struct point { int x; int y; };
point p1 {1, 2}; // 构造
point p2 = p1; // 拷贝构造
point p3 ( p1 ); // 拷贝构造
point p4 { p1 }; // 拷贝构造
auto p5 = p1; // 拷贝构造
auto p6 ( p1 ); // 拷贝构造
auto p7 { p1 }; // 拷贝构造
p3 = p2; // 拷贝赋值
// (p2和p3之前都存在)7. 值和引用的语义
值语义
= 变量是指对象本身:
- 深拷贝:生成一个新的、独立的对象;对象(成员)的值被复制。
- 深度赋值:使目标的值等于源对象的值。
- 深度所有权:成员变量引用与包含对象生命周期相同的对象。
- 基于值的比较:如果它们的值相等,则变量相等。
值语义是几乎所有编程语言中基本类型(int、double等)的默认行为,也是C++中聚合类型/用户自定义类型的默认行为。
引用语义
= 变量是对对象的引用:
- 浅层复制:变量的副本引用同一对象。
- 浅层赋值:赋值使变量引用不同的对象。
- 浅层所有权:成员变量也只是引用。
- 基于身份的比较:如果变量引用同一对象,则比较相等。
大多数其他主流语言(Java、Python、C#、Swift 等) 对用户自定义类型使用(内置)引用语义。
C++ 的情况是一致的,能够提供全面的控制:
- 默认情况下:所有类型都采用值语义(除了C风格数组)。
- 所有类型都可以使用可选的引用语义(通过引用或指针)来实现。
8.聚合的向量(std::vector)
值语义 ⇒
- vector 的存储包含类型 T 的对象本身,而不仅仅是对它们的引用或指针(就像在 Java/C#/... 中一样)。
- 如果向量对象被释放 ⇒ 包含的 T 对象也会被释放。
| vector v { 0,1,2,3,4 }; | 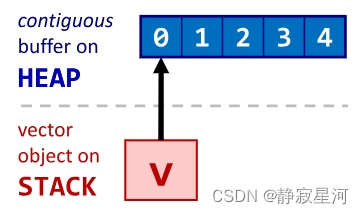 |
| struct p2d { int x; int y; }; vector v {{1,2},{5,6},{8,9}}; | 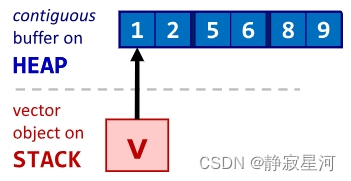 |
9.最令人烦恼的解析
无法使用空括号进行对象构造,因为在C++语法中存在歧义。

struct A { ... };
A a(); // 声明了一个函数 'a'
// 没有参数
// 返回类型为 'A'
A a; // 构造了一个 A 类型的对象
A a{} // 也构造了一个 A 类型的对象如果文章对您有用,请随手点个赞,谢谢!^_^