前言
本篇博客讲解一下外排序,看这篇排序你的先去看一下 :八大经典排序算法-CSDN博客
⏩ 文章专栏:排序_普通young man的博客-CSDN博客
若有问题 评论区见📝
🎉欢迎大家点赞👍收藏⭐文章
目录
[1. fscanf](#1. fscanf)
[2. fprintf](#2. fprintf)
[3. sscanf](#3. sscanf)
[4. sprintf](#4. sprintf)
[1. 内存限制](#1. 内存限制)
[2. 提高效率与可管理性](#2. 提高效率与可管理性)
[3. 算法适用性](#3. 算法适用性)
[. 基础函数定义](#. 基础函数定义)
[2. 快速排序算法](#2. 快速排序算法)
[3. 文件归并排序](#3. 文件归并排序)
在本文中,我们将深入探讨如何使用C语言实现快速排序算法,并将其应用于大文件的排序问题上,通过文件归并的方式处理大数据量的排序需求。这不仅是一个理论知识的应用,也是解决实际问题的一个实例。
快速回忆快速排序和归并排序
函数接口回顾
fscanf/fprintf/sscanf/sprintf
1.
fscanf
fscanf函数用于从指定的文件中读取数据并根据特定格式解析。它允许你按照预定义的格式从文件中读取各种类型的数据,如整数、浮点数或字符串等。原型:
cppint fscanf(FILE *stream, const char *format, ...);
参数:
stream: 指向需要读取的文件的文件指针。format: 一个控制字符串,用于指定输入数据的格式。...: 可变参数列表,对应于格式字符串中定义的数据类型的地址。返回值: 成功读取并转换的项目数量,如果遇到文件结束或者读取错误则返回EOF。
2.
fprintf
fprintf函数用于将数据按照指定的格式输出到一个文件中。它与printf类似,但输出目标是文件而非标准输出。原型:
cppint fprintf(FILE *stream, const char *format, ...);
参数:
stream: 指向要写入的文件的文件指针。format: 控制输出格式的字符串。...: 与格式字符串匹配的变量列表。返回值: 成功写入的字符数量,若发生错误则返回负值。
3.
sscanf
sscanf函数用于从字符串中读取数据,与fscanf类似,但它的输入源是一个字符串而不是文件。原型:
cppint sscanf(const char *str, const char *format, ...);
参数:
...: 存储读取数据的变量地址列表。
format: 指定如何解析字符串的格式控制符。str: 要读取的字符串。- 返回值: 成功读取的输入项数量。
4.
sprintf
sprintf函数用于将格式化的数据写入到一个字符串中,类似于printf,但是输出目标是一个字符数组。原型:
cppint sprintf(char *str, const char *format, ...);
参数:
str: 目标字符串的地址,写入格式化后的数据。format: 格式字符串,定义输出数据的格式。...: 一系列变量,与格式字符串中的占位符对应。返回值 : 写入到字符串中的字符数量,不包括结尾的空字符
\0。
外排序详解
我们先看一下思想:
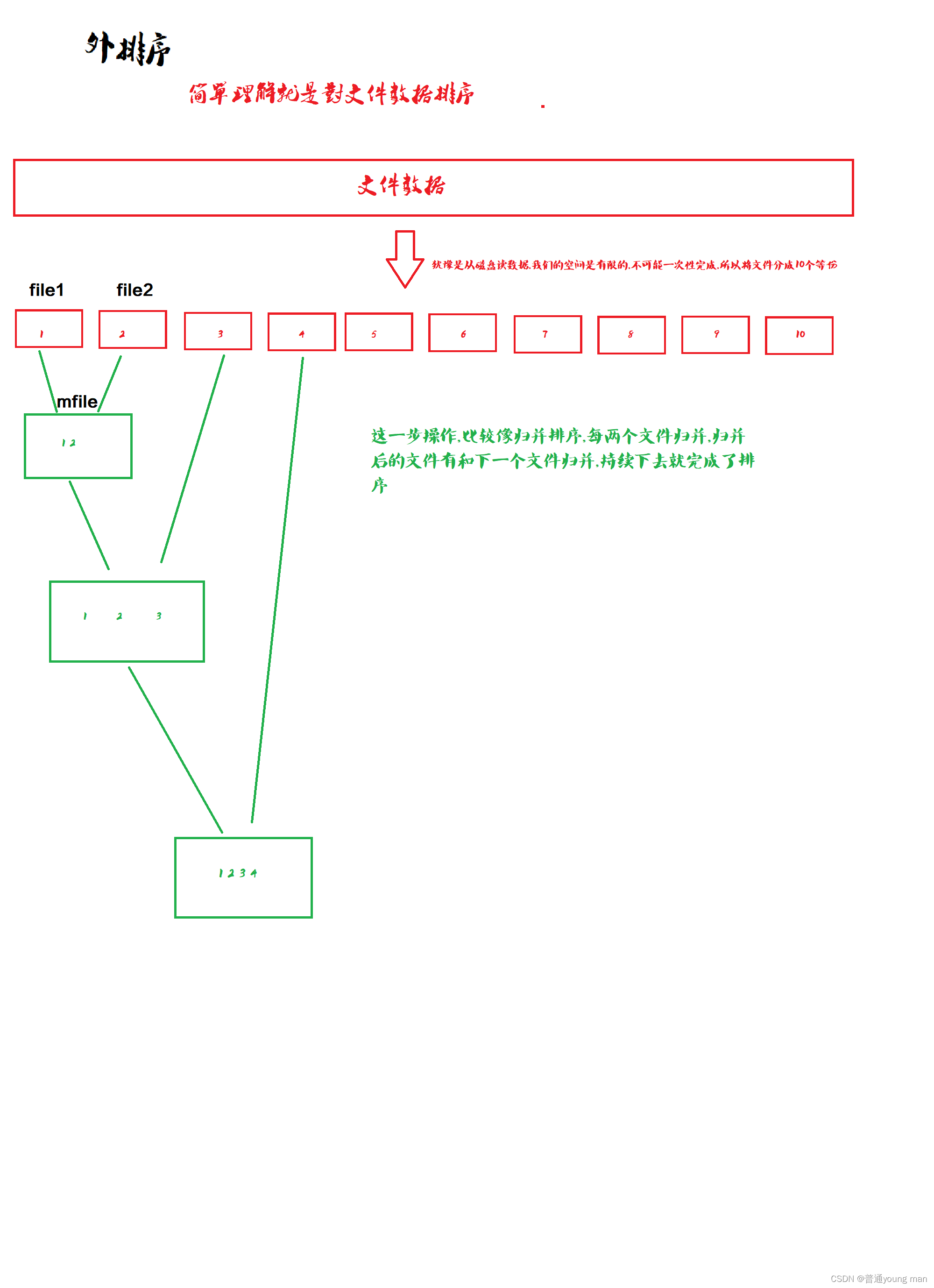
通过这个图我们可以看到是我们先要将文件的数据分成10等份将每一个等份的文件里的数据排序,然后再将10个 文件进行归并,这样所有数据就排好了
为什么要分等份排序嘞?
1. 内存限制
最直接的原因是计算机内存的限制。对于非常大的数据集,一次性将所有数据载入内存进行排序通常是不可行的。操作系统为每个进程分配的内存空间有限,超出这个限制会导致内存溢出错误。因此,通过将大文件切分为多个小文件,可以确保每个小文件都能在内存中进行高效排序,利用快速排序等算法完成局部排序。
2. 提高效率与可管理性
- 减少磁盘I/O操作:频繁的磁盘读写是影响程序性能的主要因素之一。将大文件分割成小文件,使得每个小文件可以较快地被读入内存进行处理,减少了整体的磁盘读写次数,提高了效率。
- 并行处理机会:分片后的小文件可以并行排序,尤其在多核处理器或多计算机系统中,每个小文件可以由不同的处理器或机器独立处理,大大加快了排序速度。
3. 算法适用性
快速排序、归并排序等高效的排序算法在小规模数据集上表现优异,但在大规模数据集上直接应用会受到内存限制。分块排序后,每一块数据量较小,可以更好地利用这些算法的优势。
代码
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include<assert.h>
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
//交换
void Swap(int* p1,int* p2) {
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
//三数取中
int GetMidIndex(int* a,int left,int right) {
//计算mid
int mid = (left + right) / 2;
//比较
if (a[left] > a[mid])
{
if (a[mid] > a[right]) {
return mid;
}
else if(a[left] < a[right])
{
return left;
}
else
{
return right;
}
}
else //a[left] < a[mid]
{
if (a[mid] < a[right])
{
return mid;
}
else if(a[left] > a[right])
{
return left;
}
else
{
return right;
}
}
}
//快排
void QuickSort(int* a,int left, int right) {
assert(a);
if (left >= right)
{
return;
}
int Midindex = GetMidIndex(a,left,right);
Swap(&a[Midindex], &a[left]);
//前后指针
int prev = left;
int cur = left+1;
int keyi = left;
//循环
while (cur <= right)
{
if (a[keyi] > a[cur] && ++prev != cur)
Swap(&a[cur],&a[prev]);
++cur;
}
//交换prev和keyi,得出keyi
Swap(&a[keyi], &a[prev]);
//分治 [left-keyi-1] keyi [keyi+1-right]
keyi = prev;
QuickSort(a, left, keyi - 1);
QuickSort(a, keyi+1, right);
}
//文件归并
void _MergeSortFile(const char* file1,const char* file2,const char* mfile) {
//打开第一个文件
FILE* four1 = fopen(file1, "r");
if (four1 == NULL)
{
assert("file1:打开文件失败\n");
}
//打开第二个文件
FILE* four2 = fopen(file2, "r");
if (four2 == NULL)
{
assert("file2:打开文件失败\n");
}
//创建归并文件
FILE* fin = fopen(mfile, "w");
if (fin == NULL)
{
assert("mfile:打开文件失败\n");
}
//进行归并
int num1, num2;
int ret1 = fscanf(four1, "%d\n", &num1);
int ret2 = fscanf(four2, "%d\n", &num2);
while (ret1 != EOF && ret2 != EOF)
{
if (num1 < num2) {
fprintf(fin, "%d\n", num1);
ret1 = fscanf(four1, "%d\n", &num1);
}
else //num1 > num2
{
fprintf(fin, "%d\n", num2);
ret2 = fscanf(four2, "%d\n", &num2);
}
}
//将剩余数据放进归并文件
while (ret1 != EOF)
{
fprintf(fin, "%d\n", num1);
ret1 = fscanf(four1, "%d\n", &num1);
}
while (ret2 != EOF)
{
fprintf(fin, "%d\n", num2);
ret2 = fscanf(four2, "%d\n", &num2);
}
//关闭文件
fclose(fin);
fclose(four1);
fclose(four2);
}
void MergeSortFile(const char* file) {
//导入文件数据
FILE* four = fopen(file, "r");
if (four == NULL)
{
assert("MergeSortFile:fopen");
}
//定义变量
int a[10] = {0};//分组数组
int n = sizeof(a) / sizeof(a[0]);//分组大小
int num = 0;//指针指向数据
char subfile[20];//存储文件名的指针
int filei = 1;//文件名编号
int i = 0;//数组下标
while (fscanf(four,"%d\n",&num) != EOF)
{
if (i < n-1) {
a[i++] = num;//进入8个数据
}
else
{
a[i] = num;
QuickSort(a, 0, n - 1);
sprintf(subfile,"sub\\sub_sort%d", filei++);
//创建文件
FILE* sub_fin = fopen(subfile, "w");
if (sub_fin == NULL)
{
assert("sub_fin:fopen");
}
//将数据写入文件
for (int j = 0; j < n; j++)
{
fprintf(sub_fin, "%d\n", a[j]);
}
fclose(sub_fin);
//初始化一些数据,方便下一次数据写入
i = 0;
memset(a, 0, sizeof(int)*n);
}
}
//对十个文件进行归并操作
char file1[100] = "sub\\sub_sort1";//第一个文件
char file2[100] = "sub\\sub_sort2";//第二个文件
char mfile[100] = "sub\\sub_sort12";//两个文件归并后存放的位置
for (int k = 2; k <= n; k++)
{
//归并
_MergeSortFile(file1,file2,mfile);
//改变file1的位置到mfile
strcpy(file1, mfile);
//file2向后走
sprintf(file2, "sub\\sub_sort%d", k+1);
//改变mfile文件名,使他在下一次循环创建一个新的文件
sprintf(mfile,"%s%d",mfile, k+1);
}
printf("排序成功\n");
fclose(four);
}
int main()
{
MergeSortFile("SortData.txt");
//int arr[] = { 3,5,6,8,10,12,58,1,8,7 };
//int sz = sizeof(arr) / sizeof(arr[0]);
//QuickSort(arr, 0, sz - 1);
//for (int i = 0; i < sz; i++)
//{
// printf("%d ", arr[i]);
//}
return 0;
}代码中函数的作用
. 基础函数定义
- Swap:用于交换两个整型指针所指向的值。
- GetMidIndex:实现了"三数取中"策略,用于在数组的一段范围内找出中位数的索引,以优化快速排序的性能。它通过比较数组两端和中间三个元素的值来决定返回哪个索引。
2. 快速排序算法
- QuickSort :实现快速排序的核心逻辑。首先调用
GetMidIndex选取基准元素,通过一次遍历来将数组分为两部分,一部分小于基准,另一部分大于基准,然后递归地对这两部分继续进行快速排序。此过程确保了最终数组的升序排列。3. 文件归并排序
- _MergeSortFile:负责两个已排序文件的归并操作。它打开两个输入文件,创建一个输出文件,然后逐行读取两个文件中的数字,比较后将较小的数字写入输出文件,直到某个文件读完。之后,将剩余文件的全部内容追加到输出文件末尾,最后关闭所有文件。
- MergeSortFile :这是主函数,用于处理大文件的排序。它首先打开原始数据文件,然后分批读取数据到数组
a中,每满一组就调用QuickSort排序,将排序后的数据写入到名为sub_sortX的小文件中。之后,通过循环调用_MergeSortFile函数,两两归并这些小文件,最终得到一个完全有序的大文件。此过程动态更新文件名,确保每次归并产生的新文件都能正确参与后续归并。
注意
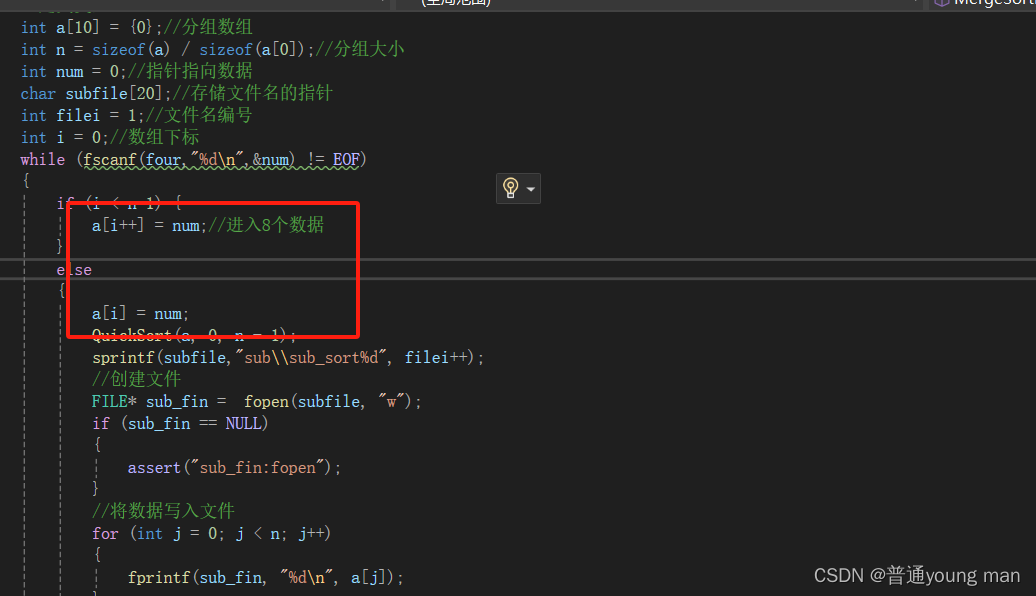
大家看这儿可能会疑惑,为什么要这么写?
你们可能会想为什么我不这样写
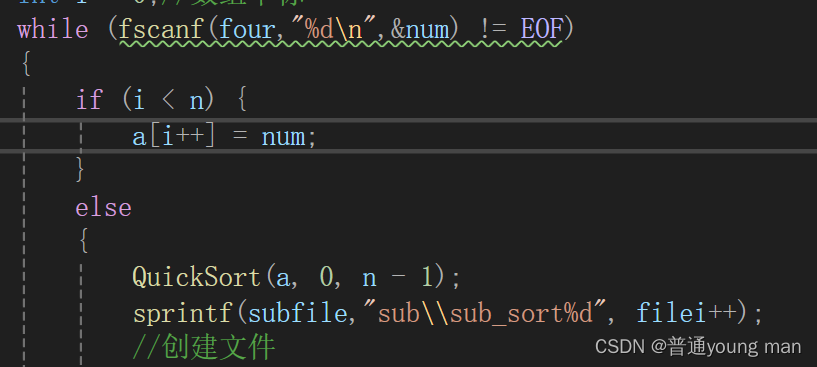
其实这样写num会有一个吞数据行为

这个是我在小本本上写的,字比较撇哈,不过能帮大家解决疑惑就行,从这个图我们可以就看出,每一次循环我们的num都会吞掉一个数据,走十次就会吞掉十个数据,这样的话,我们就只会有9个文件

照成这个原因:
1,后置++
2,fscanf每调用一次指针都会向后走
所以改进了一下这个写法
我们先让数据进去8个,最后一个数据在排序之前放进去,就不会出现这种情况了

好了今天的博客就到这里了,希望能给大家解决到问题,哈哈哈
