
Spark SQL介绍
Spark SQL是一个用于结构化数据处理的Spark组件。所谓结构化数据,是指具有Schema信息的数据,例如JSON、Parquet、Avro、CSV格式的数据。与基础的Spark RDD API不同,Spark SQL提供了对结构化数据的查询和计算接口。
Spark SQL的主要特点:
- 将SQL查询与Spark应用程序无缝组合
Spark SQL允许使用SQL或熟悉的API在Spark程序中查询结构化数据。与Hive不同的是,Hive是将SQL翻译成MapReduce作业,底层是基于MapReduce的;而Spark SQL底层使用的是Spark RDD。
- 可以连接到多种数据源
Spark SQL提供了访问各种数据源的通用方法,数据源包括Hive、Avro、Parquet、ORC、JSON、JDBC等。
- 在现有的数据仓库上运行SQL或HiveQL查询
Spark SQL支持HiveQL语法以及Hive SerDes和UDF (用户自定义函数) ,允许访问现有的Hive仓库。
DataFrame和DataSet
- DataFrame的结构
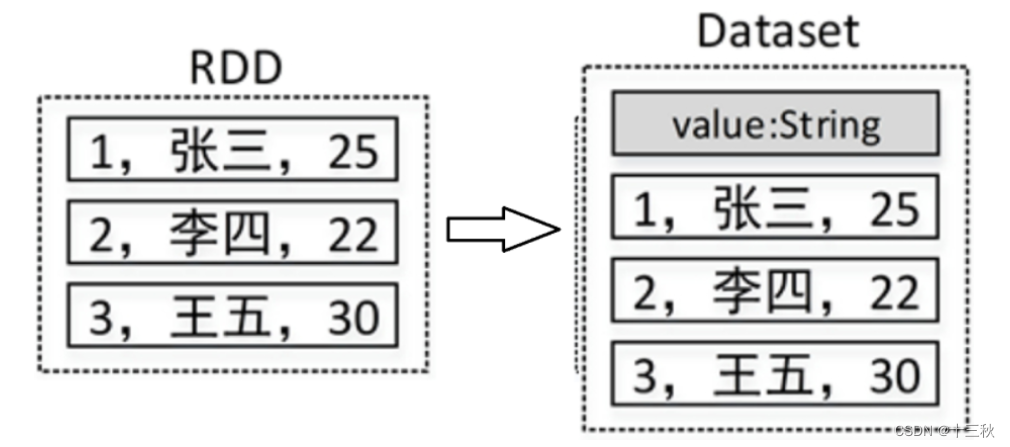
DataFrame是Spark SQL提供的一个编程抽象,与RDD类似,也是一个分布式的数据集合。但与RDD不同的是,DataFrame的数据都被组织到有名字的列中,就像关系型数据库中的表一样。
DataFrame在RDD的基础上添加了数据描述信息(Schema,即元信息) ,因此看起来更像是一张数据库表。例如,在一个RDD中有3行数据,将该RDD转成DataFrame后,其中的数据可能如图所示:

- DataSet的结构
Dataset是一个分布式数据集,是Spark 1.6中添加的一个新的API。相比于RDD, Dataset提供了强类型支持,在RDD的每行数据加了类型约束。
在Spark中,一个DataFrame代表的是一个元素类型为Row的Dataset,即DataFrame只是DatasetRow的一个类型别名。
Spark SQL的基本使用
Spark Shell启动时除了默认创建一个名为sc的SparkContext的实例外,还创建了一个名为spark的SparkSession实例,该spark变量可以在Spark Shell中直接使用。
SparkSession只是在SparkContext基础上的封装,应用程序的入口仍然是SparkContext。SparkSession允许用户通过它调用DataFrame和Dataset相关API来编写Spark程序,支持从不同的数据源加载数据,并把数据转换成DataFrame,然后使用SQL语句来操作DataFrame数据。
Spark SQL函数
内置函数
Spark SQL内置了大量的函数,位于API org.apache.spark.sql.functions
中。其中大部分函数与Hive中的相同。
使用内置函数有两种方式:一种是通过编程的方式使用;另一种是在SQL
语句中使用。
-
以编程的方式使用lower()函数将用户姓名转为小写/大写,代码如下:
df.select(lower(col("name")).as("greet")).show()
df.select(upper(col("name")).as("greet")).show()
上述代码中,df指的是DataFrame对象,使用select()方法传入需要查询的列,使用as()方法指定列的别名。代码col("name")指定要查询的列,也可以使用$"name"代替,代码如下:
df.select(lower($"name").as("greet")).show()-
以SQL语句的方式使用lower()函数,代码如下:
df.createTempView("temp")
spark.sql("select upper(name) as greet from temp").show()
除了可以使用select()方法查询指定的列外,还可以直接使用filter()、groupBy()等方法对DataFrame数据进行过滤和分组,例如以下代码:
df.printSchema() # 打印Schema信息
df.select("name").show() # 查询name列
# 查询name列和age列,其中将age列的值增加1
df.select($"name",$"age"+1).show()
df.filter($"age">25).show() # 查询age>25的所有数据
# 根据age进行分组,并求每一组的数量
df.groupBy("age").count().show() 自定义函数
当Spark SQL提供的内置函数不能满足查询需求时,用户可以根据需求编写自定义函数(User Defined Functions, UDF),然后在Spark SQL中调用。
例如有这样一个需求:为了保护用户的隐私,当查询数据的时候,需要将用户手机号的中间4位数字用星号()代替,比如手机号180***2688。这时就可以编写一个自定义函数来实现这个需求,实现代码如下:
package spark.demo.sql
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SparkSession}
/**
* 用户自定义函数,隐藏手机号中间4位
*/
object SparkSQLUDF {
def main(args: Array[String]): Unit = {
//创建或得到SparkSession
val spark = SparkSession.builder()
.appName("SparkSQLUDF")
.master("local[*]")
.getOrCreate()
//第一步:创建测试数据(或直接从文件中读取)
//模拟数据
val arr=Array("18001292080","13578698076","13890890876")
//将数组数据转为RDD
val rdd: RDD[String] = spark.sparkContext.parallelize(arr)
//将RDD[String]转为RDD[Row]
val rowRDD: RDD[Row] = rdd.map(line=>Row(line))
//定义数据的schema
val schema=StructType(
List{
StructField("phone",StringType,true)
}
)
//将RDD[Row]转为DataFrame
val df = spark.createDataFrame(rowRDD, schema)
//第二步:创建自定义函数(phoneHide)
val phoneUDF=(phone:String)=>{
var result = "手机号码错误!"
if (phone != null && (phone.length==11)) {
val sb = new StringBuffer
sb.append(phone.substring(0, 3))
sb.append("****")
sb.append(phone.substring(7))
result = sb.toString
}
result
}
//注册函数(第一个参数为函数名称,第二个参数为自定义的函数)
spark.udf.register("phoneHide",phoneUDF)
//第三步:调用自定义函数
df.createTempView("t_phone") //创建临时视图
spark.sql("select phoneHide(phone) as phone from t_phone").show()
// +-----------+
// | phone|
// +-----------+
// |180****2080|
// |135****8076|
// |138****0876|
// +-----------+
}
}窗口(开窗)函数
开窗函数是为了既显示聚合前的数据,又显示聚合后的数据,即在每一行的最后一列添加聚合函数的结果。开窗口函数有以下功能:
- 同时具有分组和排序的功能
- 不减少原表的行数
- 开窗函数语法:
聚合类型开窗函数
sum()/count()/avg()/max()/min() OVER([PARTITION BY XXX] [ORDER BY XXX [DESC]]) 排序类型开窗函数
ROW_NUMBER() OVER([PARTITION BY XXX] [ORDER BY XXX [DESC]])- 以row_number()开窗函数为例:
开窗函数row_number()是Spark SQL中常用的一个窗口函数,使用该函数可以在查询结果中对每个分组的数据,按照其排列的顺序添加一列行号(从1开始),根据行号可以方便地对每一组数据取前N行(分组取TopN)。row_number()函数的使用格式如下:
row_number() over (partition by 列名 order by 列名 desc) 行号列别名上述格式说明如下:
partition by:按照某一列进行分组;
order by:分组后按照某一列进行组内排序;
desc:降序,默认升序。
例如,统计每一个产品类别的销售额前3名,代码如下:
package spark.demo.sql
import org.apache.spark.sql.types._
import org.apache.spark.sql.{Row, SparkSession}
/**
* 统计每一个产品类别的销售额前3名(相当于分组求TOPN)
*/
object SparkSQLWindowFunctionDemo {
def main(args: Array[String]): Unit = {
//创建或得到SparkSession
val spark = SparkSession.builder()
.appName("SparkSQLWindowFunctionDemo")
.master("local[*]")
.getOrCreate()
//第一步:创建测试数据(字段:日期、产品类别、销售额)
val arr=Array(
"2019-06-01,A,500",
"2019-06-01,B,600",
"2019-06-01,C,550",
"2019-06-02,A,700",
"2019-06-02,B,800",
"2019-06-02,C,880",
"2019-06-03,A,790",
"2019-06-03,B,700",
"2019-06-03,C,980",
"2019-06-04,A,920",
"2019-06-04,B,990",
"2019-06-04,C,680"
)
//转为RDD[Row]
val rowRDD=spark.sparkContext
.makeRDD(arr)
.map(line=>Row(
line.split(",")(0),
line.split(",")(1),
line.split(",")(2).toInt
))
//构建DataFrame元数据
val structType=StructType(Array(
StructField("date",StringType,true),
StructField("type",StringType,true),
StructField("money",IntegerType,true)
))
//将RDD[Row]转为DataFrame
val df=spark.createDataFrame(rowRDD,structType)
//第二步:使用开窗函数取每一个类别的金额前3名
df.createTempView("t_sales") //创建临时视图
//执行SQL查询
spark.sql(
"select date,type,money,rank from " +
"(select date,type,money," +
"row_number() over (partition by type order by money desc) rank "+
"from t_sales) t " +
"where t.rank<=3"
).show()
}
}
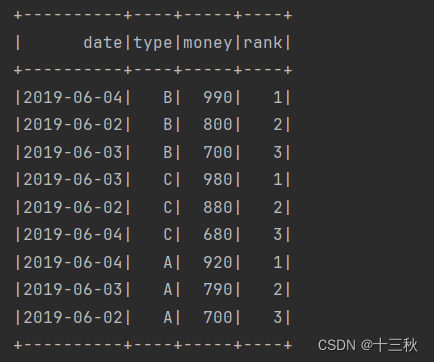
结果展示
小结
本次学习了Spark SQL基础,学习Spark SQL基础是掌握大数据处理的关键一步。Spark SQL是Apache Spark的一个模块,它提供了对结构化和半结构化数据的高效处理能力。通过学习Spark SQL,你将能够使用SQL查询和DataFrame API来分析数据集。Spark SQL的核心优势在于其能够处理大规模数据集,同时保持高性能。它支持多种数据源,包括HDFS、S3、Parquet等,使得数据的读写变得简单。此外,Spark SQL还提供了丰富的数据类型和复杂的数据操作功能,如过滤、分组、排序和聚合。学习过程中,你将了解如何创建DataFrame,执行转换和操作,以及如何使用SQL语句进行查询。你还将学习到如何优化Spark SQL查询,包括使用分区、索引和缓存技术来提高性能。
掌握Spark SQL基础对于数据工程师和分析师来说非常重要,因为它不仅可以提高数据处理的效率,还可以帮助你更好地理解和分析大规模数据集。随着你的学习深入,你将能够更有效地利用Spark的强大功能来解决实际问题。