目录
- [1. 核心内容](#1. 核心内容)
- [2. 方法](#2. 方法)
-
- [2.1 先验估计](#2.1 先验估计)
- [2.2 后验估计](#2.2 后验估计)
- [2.3 目标函数](#2.3 目标函数)
- [3. 交叉熵损失函数与Kullback-Leibler(KL)损失函数](#3. 交叉熵损失函数与Kullback-Leibler(KL)损失函数)
location:beijing
涉及知识:大模型压缩、知识蒸馏
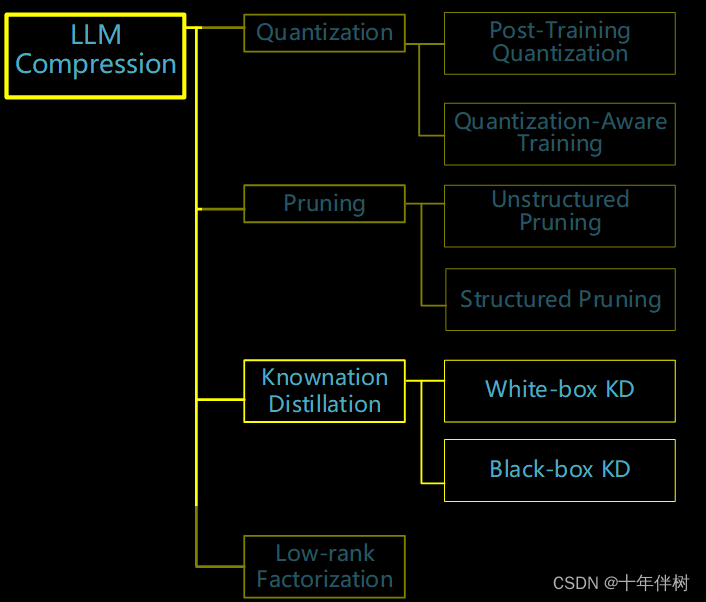
Fig. 1 大模型压缩-知识蒸馏
1. 核心内容
本文提出在一个贝叶斯估计框架内估计闭源语言模型的输出分布,包括先验估计和后验估计。先验估计的目的是通过闭源模型生成的语料库(可能包含模型的粗粒度信息)得到先验分布;后验估计使用代理模型来更新先验分布并生成后验分布。利用这两个分布来进行知识蒸馏。
2. 方法
该文章的创新点是在知识蒸馏的过程中,使用一个代理模型作为教师模型和学生模型的中介,该项目配置如Table. 1
Table. 1 项目配置
| 项目 | 方法 |
|---|---|
| benchmarks | BBH\ARC\AGIEval\MMLU\CSQA\GSM8K\ |
| teacher model | GPT-4 |
| proxy model | LLaMA-33B |
| student model | LLaMA-7B/13B |
一些参数表示如下表
Table. 2 参数表示
| 变量 | 含义 |
|---|---|
| T \mathcal{T} T | 闭源的教师模型 |
| S \mathcal{S} S | 学生模型 |
| M \mathcal{M} M | 开源的代理模型 |
| X X X | 输入的token序列 |
| Y Y Y | 输出的token序列 |
| p Y t p_{Y_t} pYt | T \mathcal{T} T输出的概率Pr ( Y t ( Y_{t} (Yt | X , Y < t ) X, Y_{< t}) X,Y<t) |
| q Y t q_{Y_t} qYt | S \mathcal{S} S输出的概率Pr ( Y t (Y_{t} (Yt | X , Y < t ) X,Y_{<t}) X,Y<t) |
| P Y t P_{Y_t} PYt | 与 p Y t p_{Y_t} pYt相关的离散随机变量 |
用指示函数 I Y t = w \mathbb{I}_{Y_t=\boldsymbol{w}} IYt=w(其实不是空心的I应该是空心的1,没法在CSDN打出来)表示 T \mathcal{T} T在 t t t时刻产生的one-hot编码标签。
传统的目标函数可以表示为
L t traditional = − ∑ w ∈ V I Y t = w log q Y t = w + ∑ w ∈ V p Y t = w log p Y t = w q Y t = w (1) \mathcal{L}{t}^{\text{traditional}}=-\sum{w\in\mathbb{V}}\mathbb{I}{Y{t}=w}\log q_{Y_{t}=w}+\sum_{w\in\mathbb{V}}p_{Y_{t}=w}\log\frac{p_{Y_{t}=w}}{q_{Y_{t}=w}}\tag{1} Lttraditional=−w∈V∑IYt=wlogqYt=w+w∈V∑pYt=wlogqYt=wpYt=w(1)式中 V \mathbb{V} V表示词典, w w w是词典中的一个token,可以看出, L t traditional \mathcal{L}{t}^{\text{traditional}} Lttraditional由两部分组成,第一部分表示由硬标签(Fig.2)产出的交叉熵损失(交叉熵与相对熵在第三章详细说明),第二部分表示用软标签计算出的KL损失,一般情况下由于 p Y t p{Y_{t}} pYt很难得到,第二项是被忽略的。
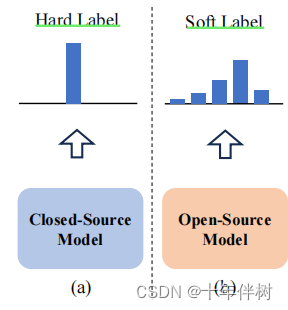
Fig.2 硬标签与软标签
这篇论文就是解决第二项的问题。
2.1 先验估计
先验估计的目的是使用 T \mathcal{T} T生成的语料库 C \mathcal{C} C,得到每一步 t t t的近似 p Y t p_{Y_{t}} pYt的粗粒度估计 p ^ Y t \hat{p}{Y_t} p^Yt,来自改良的n-gram算法(基于第n个项目的出现只与前面n-1个项目有关)来实现,对于给定一个输出token序列 Y ≤ t ∈ C Y{\leq t}\in\mathcal{C} Y≤t∈C,假设 Y t = w t Y_{t}=w_t Yt=wt其中 w t w_t wt是 V \mathbb{V} V中的一个token,对于 V \mathbb{V} V中的某个token w w w如果有 w = w t w=w_t w=wt,有
p ^ Y t = w = # ( Y t = w , Y t − 1 = w t − 1 , ... , Y t − n = w t − n ) γ # ( Y t − 1 = w t − 1 , ... , Y t − n = w t − n ) + γ − 1 γ (2) \hat{p}{Y_t=w}=\frac{\#(Y_t=w,Y{t-1}=w_{t-1},\ldots,Y_{t-n}=w_{t-n})}{\gamma\#(Y_{t-1}=w_{t-1},\ldots,Y_{t-n}=w_{t-n})}+\frac{\gamma-1}{\gamma}\tag{2} p^Yt=w=γ#(Yt−1=wt−1,...,Yt−n=wt−n)#(Yt=w,Yt−1=wt−1,...,Yt−n=wt−n)+γγ−1(2)或者
p ^ Y t = w = # ( Y t = w , Y t − 1 = w t − 1 , ... , Y t − n = w t − n ) γ # ( Y t − 1 = w t − 1 , ... , Y t − n = w t − n ) (3) \hat{p}{Y_t=w}=\frac{\#(Y_t=w,Y{t-1}=w_{t-1},\ldots,Y_{t-n}=w_{t-n})}{\gamma\#(Y_{t-1}=w_{t-1},\ldots,Y_{t-n}=w_{t-n})}\tag{3} p^Yt=w=γ#(Yt−1=wt−1,...,Yt−n=wt−n)#(Yt=w,Yt−1=wt−1,...,Yt−n=wt−n)(3)式中, # \# #代表语料库 C \mathcal{C} C中出现某一token的数量, n n n代表窗口大小, γ \gamma γ是个超参数,由此可得到一个 p Y t p_{Y_{t}} pYt的粗略估计 p ^ Y t \hat{p}_{Y_t} p^Yt。
2.2 后验估计
后验估计用来改善先验估计,后验估计使用贝叶斯估计框架,引入 T \mathcal{T} T的一个代理模型 M \mathcal{M} M(大于 S \mathcal{S} S), M \mathcal{M} M已经由 T \mathcal{T} T生成的 C \mathcal{C} C微调,该估计使用代理 M \mathcal{M} M生成的连续样本来细化 p ^ Y t \hat{p}{Y{t}} p^Yt。
假设 p Y t p_{Y_{t}} pYt的值可以用一个离散(更好理解)的随机变量 P Y t P_{Y_t} PYt描述, P Y t P_{Y_t} PYt的数值取自m个数值 p 1 , p 2 , ... , p m p^{1},p^{2},\ldots,p^{m} p1,p2,...,pm,在0~1服从均匀分布。根据 p ^ Y t \hat{p}{Y_t} p^Yt,可以重写 P Y t P{Y_t} PYt的概率质量函数(连续的叫概率密度函数,离散的叫这个)为
E ( P Y t ) = ∑ i = 1 m p i Pr ( P Y t = p i ) = p ^ Y t (4) \mathbb{E}(P_{Y_t})=\sum_{i=1}^mp^i\Pr(P_{Y_t}=p^i)=\hat{p}_{Y_t}\tag{4} E(PYt)=i=1∑mpiPr(PYt=pi)=p^Yt(4)
只要期望 E ( P Y t ) = p ^ Y t \mathbb{E}(P_{Y_t})=\hat{p}{Y_t} E(PYt)=p^Yt,概率质量函数就可以变化。把 X X X和 Y < t Y{<t} Y<t喂给 M \mathcal{M} M得到 t t t时刻的样本 w ^ ∈ V \hat{w}\in\mathbb{V} w^∈V,给定 w ^ \hat{w} w^和 w ∈ V w\in\mathbb{V} w∈V,事件 A A A定义为如果 w ^ = w \hat{w}=w w^=w,A=1;否则A=0。
如果事件A=1发生,根据贝叶斯定理:
Pr ( P Y t = w = p i ∣ A = 1 ) ∝ Pr ( A = 1 ∣ P Y t = w = p i ) Pr ( P Y t = w = p i ) = p i Pr ( P Y t = w = p i ) (5) \Pr(P_{Y_t=w}=p^i|A=1)\propto\Pr(A=1|P_{Y_t=w}=p^i)\Pr(P_{Y_t=w}=p^i)=p^i\Pr(P_{Y_t=w}=p^i)\tag{5} Pr(PYt=w=pi∣A=1)∝Pr(A=1∣PYt=w=pi)Pr(PYt=w=pi)=piPr(PYt=w=pi)(5)式中 w ∈ V , i ∈ { 1 , 2 , ... , m } w\in\mathbb{V},i\in\{1,2,\ldots,m\} w∈V,i∈{1,2,...,m},通过下式得出一个归一化因子,则 Pr ( P Y t = w = p i ∣ A = 1 ) \operatorname*{Pr}(P_{Y_{t}=w}=p^{i}|A=1) Pr(PYt=w=pi∣A=1)可以用 1 η p i Pr ( P Y t = w = p i ) \frac1\eta p^i\Pr(P_{Y_t=w}=p^i) η1piPr(PYt=w=pi)来计算
η = ∑ i = 1 m p i Pr ( P Y t = w = p i ) (6) \eta=\sum_{i=1}^mp^i\Pr(P_{Y_t=w}=p^i)\tag{6} η=i=1∑mpiPr(PYt=w=pi)(6)如果事件A=0发生,根据贝叶斯定理:
Pr ( P Y t = w = p i ∣ A = 0 ) ∝ Pr ( A = 0 ∣ P Y t = w = p i ) Pr ( P Y t = w = p i ) = ( 1 − p i ) Pr ( P Y t = w = p i ) (7) \Pr(P_{Y_{t}=w}=p^{i}|A=0)\propto\Pr(A=0|P_{Y_{t}=w}=p^{i})\Pr(P_{Y_{t}=w}=p^{i})=(1-p^{i})\Pr(P_{Y_{t}=w}=p^{i})\tag{7} Pr(PYt=w=pi∣A=0)∝Pr(A=0∣PYt=w=pi)Pr(PYt=w=pi)=(1−pi)Pr(PYt=w=pi)(7)式中 w ∈ V , i ∈ { 1 , 2 , ... , m } w\in\mathbb{V},i\in\{1,2,\ldots,m\} w∈V,i∈{1,2,...,m},同样通过下式得出一个归一化因子
η = ∑ i = 1 m ( 1 − p i ) Pr ( P Y t = w = p i ) (8) \begin{aligned}\eta=\sum_{i=1}^m{(1-p^i)}\Pr(P_{Y_t=w}=p^i)\end{aligned}\tag{8} η=i=1∑m(1−pi)Pr(PYt=w=pi)(8)则 Pr ( P Y t = w = p i ∣ A = 0 ) \operatorname*{Pr}(P_{Y_{t}=w}=p^{i}|A=0) Pr(PYt=w=pi∣A=0)可由 1 η ( 1 − p i ) Pr ( P Y t = w = p i ) \frac1\eta(1-p^i)\Pr(P_{Y_t=w}=p^i) η1(1−pi)Pr(PYt=w=pi)得出。
这样在A无论为0还是1都能有所替换,一次迭代结束, P r ( P Y t = p i ) \mathrm{Pr}(P_{Y_{t}}=p^{i}) Pr(PYt=pi)由 Pr ( P Y t = w = p i ∣ A = 0 ) \operatorname*{Pr}(P_{Y_{t}=w}=p^{i}|A=0) Pr(PYt=w=pi∣A=0)和 Pr ( P Y t = w = p i ∣ A = 1 ) \operatorname*{Pr}(P_{Y_{t}=w}=p^{i}|A=1) Pr(PYt=w=pi∣A=1)替换,然后进入下一次迭代。经过多轮采样,可以得到最终的概率质量函数 Pr ( P Y t = p i ∣ M ) \operatorname*{Pr}(P_{Y_{t}}=p^{i}|\mathcal{M}) Pr(PYt=pi∣M), p Y t p_{Y_{t}} pYt可以用期望来代替
E ( P Y t ∣ M ) = ∑ i = 1 m p i Pr ( P Y t = p i ∣ M ) (9) \mathbb{E}(P_{Y_t}|\mathcal{M})=\sum_{i=1}^mp^i\Pr(P_{Y_t}=p^i|\mathcal{M})\tag{9} E(PYt∣M)=i=1∑mpiPr(PYt=pi∣M)(9) E ( P Y t ∣ M ) \mathbb{E}(P_{Y_t}|\mathcal{M}) E(PYt∣M)即为后验估计。
该过程可以用下图3表示
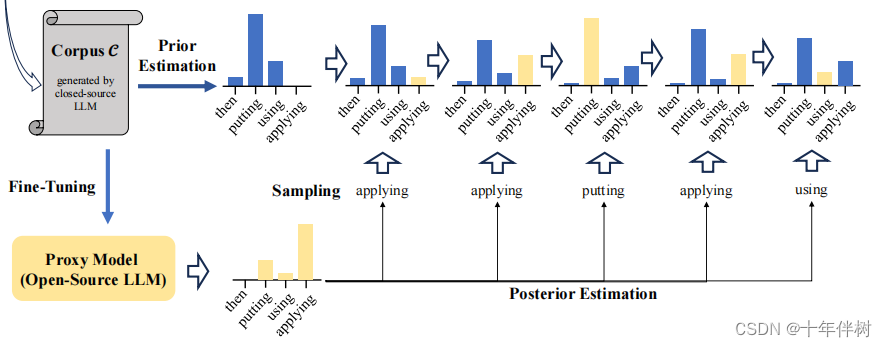
Fig.3 后验估计过程
2.3 目标函数
第 t t t步的目标函数由三部分组成,用指示函数 I Y t = w \mathbb{I}{Y_t=\boldsymbol{w}} IYt=w表示 T \mathcal{T} T在 t t t时刻产生的one-hot编码标签。第一部分的目标函数是交叉熵损失 L t c e = − ∑ w ∈ V I Y t = w log q Y t = w \mathcal{L}{t}^{\mathrm{ce}} = -\sum_{w\in\mathbb{V}}\mathbb{I}{Y{t}=w}\log q_{Y_{t}=w} Ltce=−∑w∈VIYt=wlogqYt=w,第二部分基于先验估计 L t k l = ∑ w ∈ V p ^ Y t = w log p ^ Y t = w q Y t = w \mathcal{L}{t}^{\mathrm{kl}} = \sum{w\in\mathbb{V}}\hat{p}{Y{t}=w}\log\frac{\hat{p}{Y{t}=w}}{q_{Y_{t}=w}} Ltkl=∑w∈Vp^Yt=wlogqYt=wp^Yt=w,第三部分基于后验估计 L t ∣ M k l = ∑ w ∈ V E ( P Y t = w ∣ M ) log E ( P Y t = w ∣ M ) q Y t = w \mathcal{L}{t|\mathcal{M}}^{\mathrm{kl}}=\sum{w\in\mathbb{V}}\mathbb{E}(P_{Y_{t}=w}|\mathcal{M})\log\frac{\mathbb{E}(P_{Y_{t}=w}|\mathcal{M})}{q_{Y_{t}=w}} Lt∣Mkl=∑w∈VE(PYt=w∣M)logqYt=wE(PYt=w∣M),最终得到目标函数
L = 1 T ∑ t = 1 T ( L t c e + α L t k l + β L t ∣ M k l ) (10) \mathcal{L}=\frac{1}{T}\sum_{t=1}^{T}(\mathcal{L}{t}^{\mathrm{ce}}+\alpha\mathcal{L}{t}^{\mathrm{kl}}+\beta\mathcal{L}_{t|\mathcal{M}}^{\mathrm{kl}})\tag{10} L=T1t=1∑T(Ltce+αLtkl+βLt∣Mkl)(10)式中 α \alpha α和 β \beta β都是超参数。
总结一下如图4

Fig. 4 总体目标函数
3. 交叉熵损失函数与Kullback-Leibler(KL)损失函数
在信息论中,期望使用公式来表示事件所包含的信息的量度。
信息量 ,期望一个事件发生的概率越小,信息量就越大;而大概率的信息量较小,同时期望两个事件同时发生的信息量等于两个事件的信息量相加,由此可以规定一个事件的信息量为
I ( x i ) = − log b P ( x i ) (11) I(x_i) = -\log_b P(x_i)\tag{11} I(xi)=−logbP(xi)(11)
信息熵 𝐻(𝑋),也称为熵,是随机变量𝑋的期望信息量,可以通过对其所有可能结果的信息量求加权平均来计算:
H ( X ) = − ∑ i = 1 n P ( x i ) log b P ( x i ) (12) H(X) = -\sum_{i=1}^{n} P(x_i) \log_b P(x_i)\tag{12} H(X)=−i=1∑nP(xi)logbP(xi)(12)信息熵用来评估一个随机变量的不确定性,不确定性越大(对投色子,各数字概率密度均匀 ,取出任何数的概率相同),熵越大;不确定性越小(对扑克牌,普通牌与大小王的概率密度差距很大,取出普通牌的不确定性小),熵越小。
交叉熵 假设随机变量𝑋的真实概率密度p,预测概率密度q,定义q对p的平均信息量的估计,叫做交叉熵,定义为公式
H ( p , q ) = ∑ p i I i q = − ∑ p i l o g 2 ( q i ) (13) H(p,q)=\sum p_iI_i^q=-\sum p_ilog_2(q_i)\tag{13} H(p,q)=∑piIiq=−∑pilog2(qi)(13)交叉熵越小,预测的分布与真实的分布差异越小。且交叉熵总是大于熵的值。
KL散度 也称为相对熵,是一种衡量两个概率分布差异的指标。KL散度是不对称的,即从分布P到分布Q的KL散度与从Q到P的KL散度不同。对于两个概率分布𝑃和𝑄定义在相同的概率空间上,KL散度定义为:
K L ( P ∥ Q ) = ∑ x P ( x ) ( I P − I Q ) = ∑ x P ( x ) log ( P ( x ) Q ( x ) ) (14) \mathrm{KL}(P\parallel Q)=\sum_{x}P(x)(I_P-I_Q)=\sum_{x}P(x)\log\left(\frac{P(x)}{Q(x)}\right)\tag{14} KL(P∥Q)=x∑P(x)(IP−IQ)=x∑P(x)log(Q(x)P(x))(14)
对于连续概率分布,求和变成积分。当两分布完全相同,则 K L ( P ∥ Q ) = 0 \mathrm{KL}(P\parallel Q)=0 KL(P∥Q)=0,KL熵用来衡量两分布的相似程度,KL熵越小,两分布越相似。