本文来自《老饼讲解-BP神经网络》https://www.bbbdata.com/
机器学习中的模型非常的多,但如果要问有没有这样的一个模型,它的训练误差为0,那么就非RBF神经网络莫属了!下面我们来聊聊,为什么RBF神经网络的训练误差为0。
一、RBF神经网络是什么
知道RBF神经网络的人都知道,但不知道RBF神经网络的人还是不知道。所以简单提一下,RBF神经网络是一个什么东西。
1.1.RBF神经网络的原理
如下所示,就是一个RBF函数(钟型函数),RBF函数很多,最常用的就是高斯函数
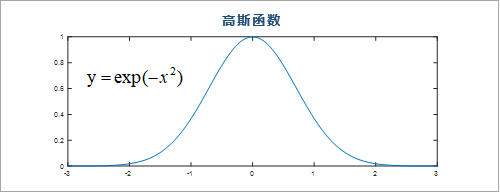
RBF神经网络就是通过RBF径向基函数来"凑"出可以拟合所有训练样本点的目标曲线。
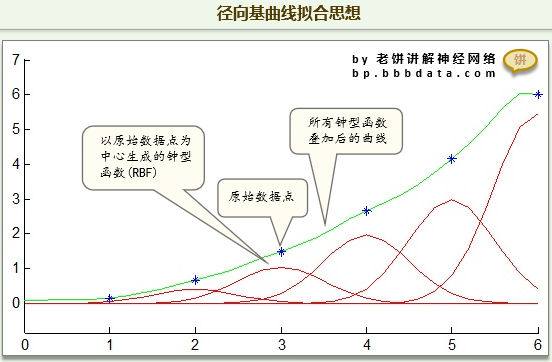
从图中可以看到,RBF神经网络就是利用RBF函数的局部非0性,只要每个样本点都拱一个RBF,最后就能轻轻松松拼出目标曲线了。
1.2.RBF神经网络的数学表达式
从RBF的原理,可以轻易得到RBF神经网络的数学表达式。 以2输入3个隐节点为例,RBF 神经网络模型的数学表达式形式如下
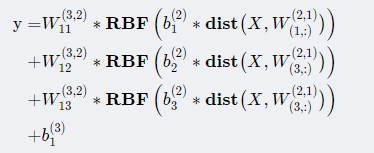
从表达式可以看到,模型的输出y就是多个RBF函数之和。
二、RBF神经网络为什么误差为0
2.1.RBF神经网络是如何求得0误差参数的
在RBF神经网络中,有多少个样本点,就有多少个隐节点(即RBF函数)。而隐层的权重就是输入样本(即隐层参数是不需要求解的),最终只需求解输出层的权重与阈值。由于每个RBF的值都可以直接计算得到(因为隐层参数已知),因此RBF输出层的参数只需要求解以下的线性方程组就可以得到:

当样本有n个时,就有n个RBF,因此上述线性方程组的列大于行,所以必然有非0解使得上述方程组成立。因此,RBF神经网络的训练误差也就必然为0
2.2.为什么有的RBF神经网络误差不为0
当我们在matlab中用newrb构建一个RBF神经网络时,会发现误差并不为0。这是因为newrb使用了正交最小二乘法来求解RBF,它的目的是尽量地减少一些隐节点。

因为RBF神经网络的隐节点个数与样本个数一致,因此在样本较多时,网络也比较复杂,因此newrb会在保持误差不太大的前提下,尽量减少一些隐节点。虽然牺牲了一部分训练精度,但加强了网络的泛化能力,所以也不偿是件好事。
RBF神经网络真是一个有趣又有效的模型!
相关链接:
《老饼讲解-机器学习》:老饼讲解-机器学习教程-通俗易懂
《老饼讲解-神经网络》:老饼讲解-matlab神经网络-通俗易懂
《老饼讲解-神经网络》:老饼讲解-深度学习-通俗易懂