学习率
学习率是训练神经网络的重要超参数之一,它代表在每一次迭代中梯度向损失函数最优解移动的步长。它的大小决定网络学习速度的快慢。在网络训练过程中,模型通过样本数据给出预测值,计算代价函数并通过反向传播来调整参数。重复上述过程,使得模型参数逐步趋于最优解从而获得最优模型。在这个过程中,学习率负责控制每一步参数更新的步长。合适的学习率可以使代价函数以合适的速度收敛到最小值。
lr 即 stride (步长) ,即反向传播算法中的 η :
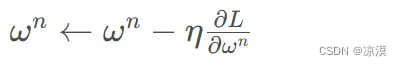
学习率大小

学习率对网络的影响
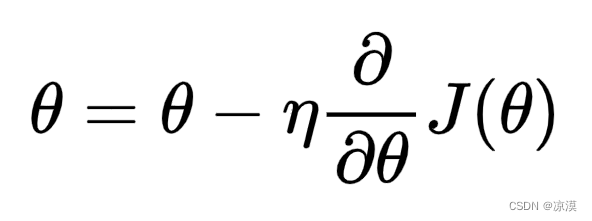
根据上述公式我们可以看到
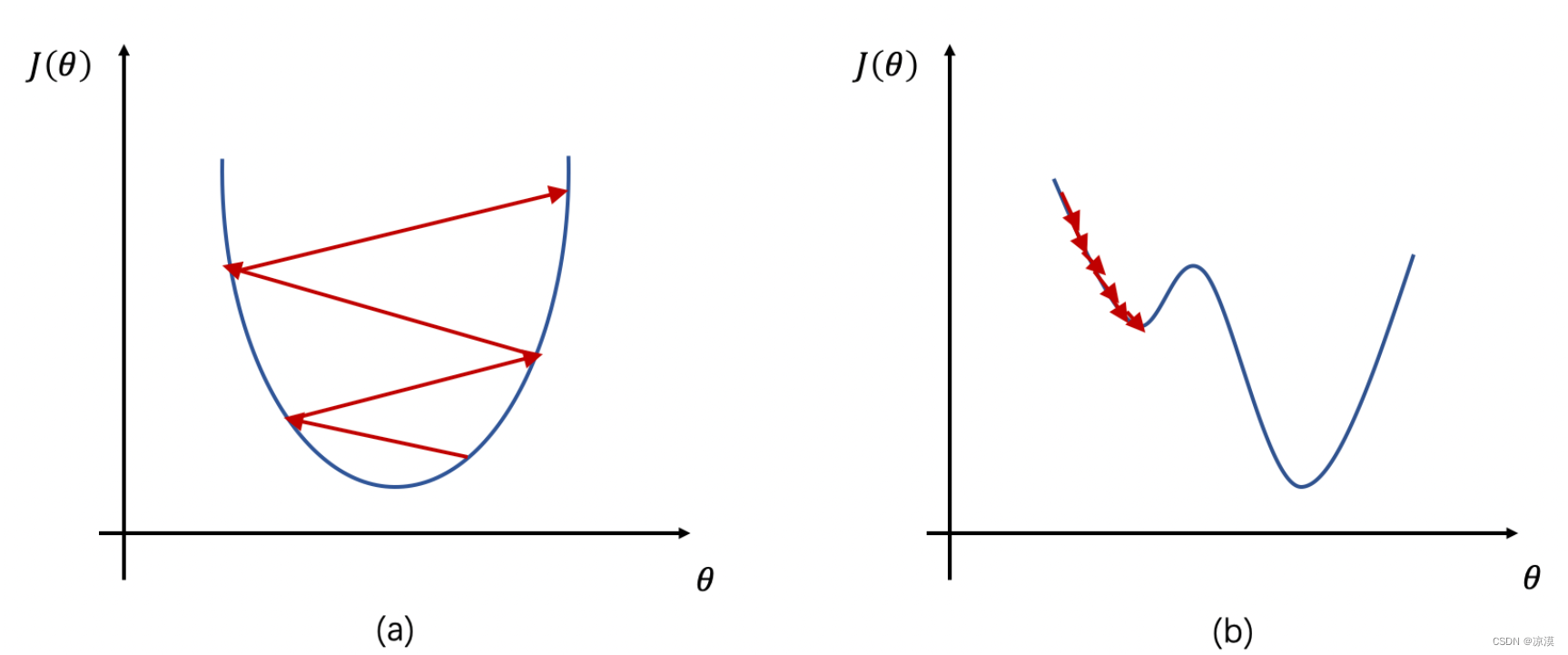
- 如果学习率 η 较大,那么参数的更新速度就会很快,可以加快网络的收敛速度,但如果学习率过大,可能会导致参数在最优解附近震荡,代价函数难以收敛,甚至可能会错过最优解,导致参数向错误的方向更新,代价函数不仅不收敛反而可能爆炸(如图1a所示)。
- 如果学习率 η 较小,网络可能不会错过最优点,但是网络学习速度会变慢。同时,如果学习率过小,则很可能会陷入局部最优点(如图1b所示)。因此,只有找到合适的学习率,才能保证代价函数以较快的速度逼近全局最优解。
学习率设置
在训练过程中,一般根据训练轮数设置动态变化的学习率。
- 刚开始训练时:学习率以 0.01 ~ 0.001 为宜。
- 一定轮数过后:逐渐减缓。
- 接近训练结束:学习速率的衰减应该在100倍以上。
随机梯度下降算法
目前深度学习模型多采用批量随机梯度下降算法进行优化,随机梯度下降算法的原理如下,
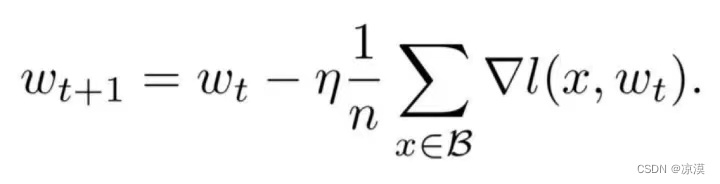
n是批量大小(batchsize),η是学习率(learning rate)。可知道除了梯度本身,这两个因子直接决定了模型的权重更新,从优化本身来看它们是影响模型性能收敛最重要的参数。
学习率直接影响模型的收敛状态,batchsize则影响模型的泛化性能,两者又是分子分母的直接关系,相互也可影响,因此这一次来详述它们对模型性能的影响。
参考:
深度学习基础入门篇六:模型调优,学习率设置(Warm Up、loss自适应衰减等),batch size调优技巧,基于方差放缩初始化方法。-腾讯云开发者社区-腾讯云 (tencent.com)
【深度学习】学习率 (learning rate)_深度学习中学习率-CSDN博客
深度学习中学习率(lr:learn rate)和batchsize如何影响模型性能?_batchsize和learning rate关系-CSDN博客