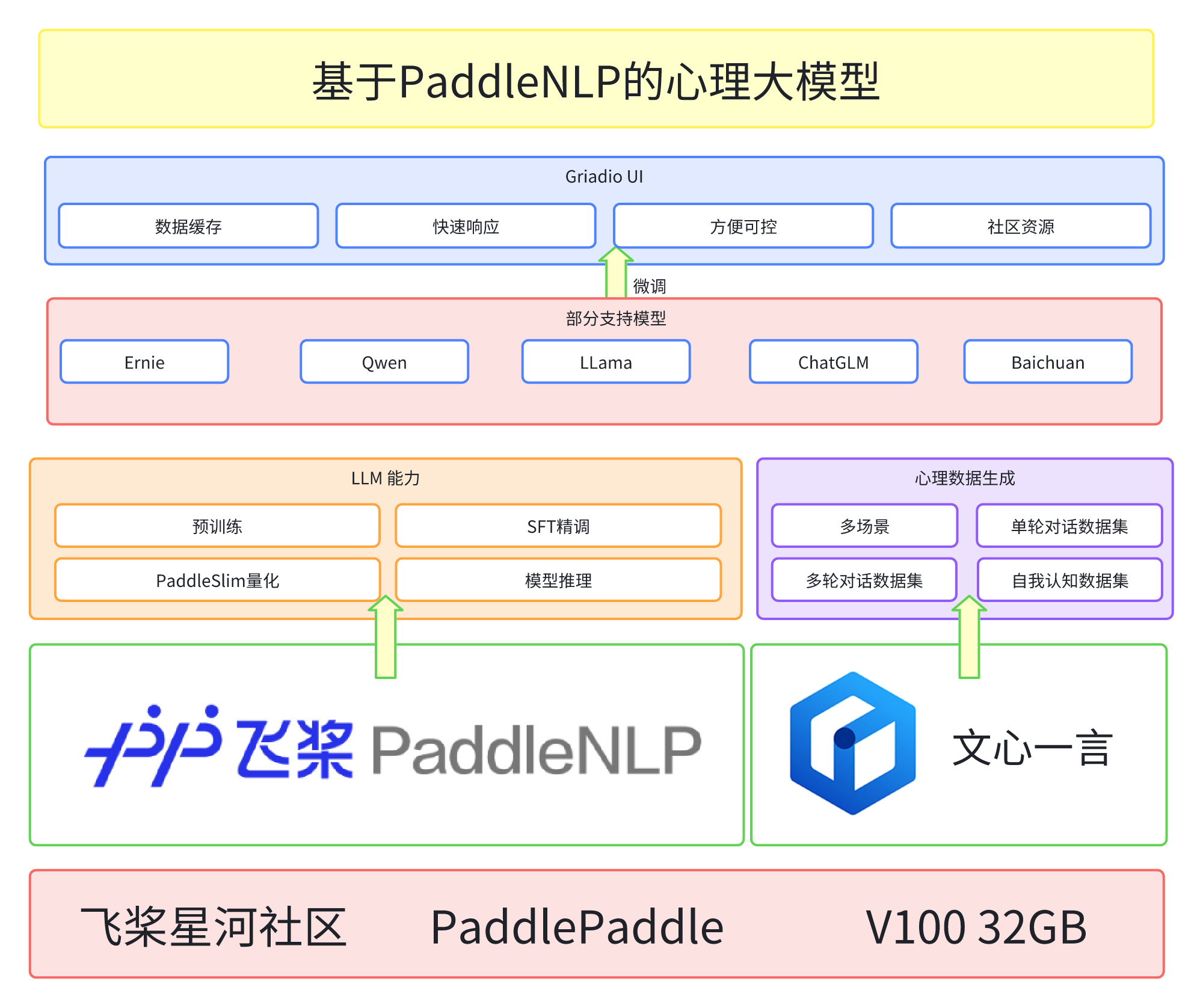
项目源于:EmoLLM心理大模型,一直就有用paddle实践心理大模型的想法,终于实现了哈~。接下来就手把手带大家一块做一个心理大模型吧!!! 简单画了个框架图:
环境配置
In
# !git clone -b develop https://github.com/PaddlePaddle/PaddleNLP.git
%cd PaddleNLP
!pip install -e .
# 为了解决一个环境依赖问题,在训练的时候随机出现的,稍微有点离谱,大概是环境的问题
%cd ~
# !git clone https://github.com/PaddlePaddle/PaddleSlim
%cd PaddleSlim/csrc
!python ./setup_cuda.py install 数据集构建
参考飞桨大模型精调文档,PaddleNLP支持的数据格式是每行包含一个字典,每个字典包含以下字段:
-
src : str, List(str), 模型的输入指令(instruction)、提示(prompt),模型应该执行的任务。
-
tgt : str, List(str), 模型的输出。
多轮对话时如下:
{"src": ["user-1", "user-2", ..., "user-n"], "tgt": ["bot-1", "bot-2", ..., "bot-n"]}为了使我们的心理大模型有更好的表达效果,我们必须要有高质量的数据集。自己构建数据集相当麻烦呜呜,因此决定借用文心大模型的强大能力,通过调用文心一言的API来生成对应的数据集。因为心理活动往往是复杂的,为了保证数据的多样性。我们选择了16 * 28 共 448个场景(如下)进行数据集生成,
emotions_list : [
"钦佩",
"崇拜",
"欣赏",
"娱乐",
"焦虑",
"敬畏",
"尴尬",
"厌倦",
"冷静",
"困惑",
"渴望",
"厌恶",
"同情",
"痛苦",
"着迷",
"嫉妒",
"兴奋",
"恐惧",
"痛恨",
"有趣",
"快乐",
"怀旧",
"浪漫",
"悲伤",
"满意",
"性欲",
"同情",
"满足"
]
areas_of_life : [
"工作",
"学业",
"生活",
"身体",
"家人",
"朋友",
"社交",
"恋爱",
"就业",
"责任",
"爱好",
"环境",
"隐私",
"安全",
"梦想",
"自由"
]需要配置config.yml,将自己的访问令牌放入即可。
配置文心一言
In
!pip install erniebotIn 2
import erniebot
erniebot.api_type = 'aistudio'
erniebot.access_token = "{个人中心的访问令牌}"#请输入自己的访问令牌数据生成
In
import json
import random
import yaml
import erniebot
with open('config.yml', 'r', encoding='utf-8') as f:
configs = yaml.load(f.read(), Loader=yaml.FullLoader)
erniebot.api_type = 'aistudio'
#此处需要将你的token也就是AIstudio主页的访问令牌放到下方
erniebot.access_token = configs['aistudio _token']
system = configs['system']
areas_of_life = configs['areas_of_life']
emotions_list = configs['emotions_list']
words = ''
# prompt = '''
# 你是一个研究过无数具有心理健康问题的病人与心理健康医生对话案例的专家,请你构造一些符合实际情况的具有心理健康问题的病人和心理健康医生的多轮对话案例。要求医生的回复尽可能包含心理辅导知识,并且能够一步步诱导病人说出自己的问题进而提供解决问题的可行方案。注意,构造的数据必须以医生的陈述为结束语。请以如下格式返回生成的数据:
# 病人:病人的咨询或陈述
# 医生:医生的安抚和建议
# '''
res = []
for data in areas_of_life[:2]:
for emo in emotions_list[:2]:
print(f'正在为{data}_{emo}场景生成对应数据集')
prompt = f'''你是一个研究过无数具有心理健康问题的病人与心理健康医生对话的专家,请你构造一些符合实际情况的具有心理健康问题的病人和心理健康医生的连续的多轮对话记录。
要求病人的问题属于{data}场景,具有{emo}情感,医生的回复尽可能包含心理辅导知识,并且能够一步步诱导病人说出自己的问题进而提供解决问题的可行方案。
注意,构造的数据必须以医生的陈述为结束语,每次只需要构造一个案例并且不需要写案例一、二等等,请返回完整的对话内容。
请以如下格式返回生成的数据:
病人:病人的咨询或陈述
医生:医生的安抚和建议
'''
try :
for i in range(1):
response = erniebot.ChatCompletion.create(
model='ernie-3.5',
messages=[{'role': 'user', 'content': f"{prompt}"}],
# top_p=random.uniform(0.5, 0.99),
# penalty_score = random.uniform(1.0, 2.0)
)
tmp = response.result
print(tmp)
ls = tmp.split('\n')
ls = [i for i in ls if i!='']
# conversation = {'src':[], 'tgt':[]}
src = []
tgt = []
except:
pass
for j in range(0, len(ls)-1, 2):
src.append(ls[j].split(":")[-1])
tgt.append(ls[j+1].split(":")[-1])
res.append({'src':src, 'tgt':tgt, "context": {"system": "现在你是一个心理专家,我有一些心理问题,请你用专业的知识帮我解决。" }})
print(f'第{i}条数据生成完成!!')
print('================================')
print(f'{data}_{emo}场景对应数据集生成完毕')
# 将数据写入JSON文件
# with open('./tmp_data.json', 'w', encoding='utf-8') as file:
# json.dump(res, file, ensure_ascii=False, indent=4)In 25
with open('output.json', 'w', encoding='utf-8') as f:
for item in res:
json.dump(item, f, ensure_ascii=False,)
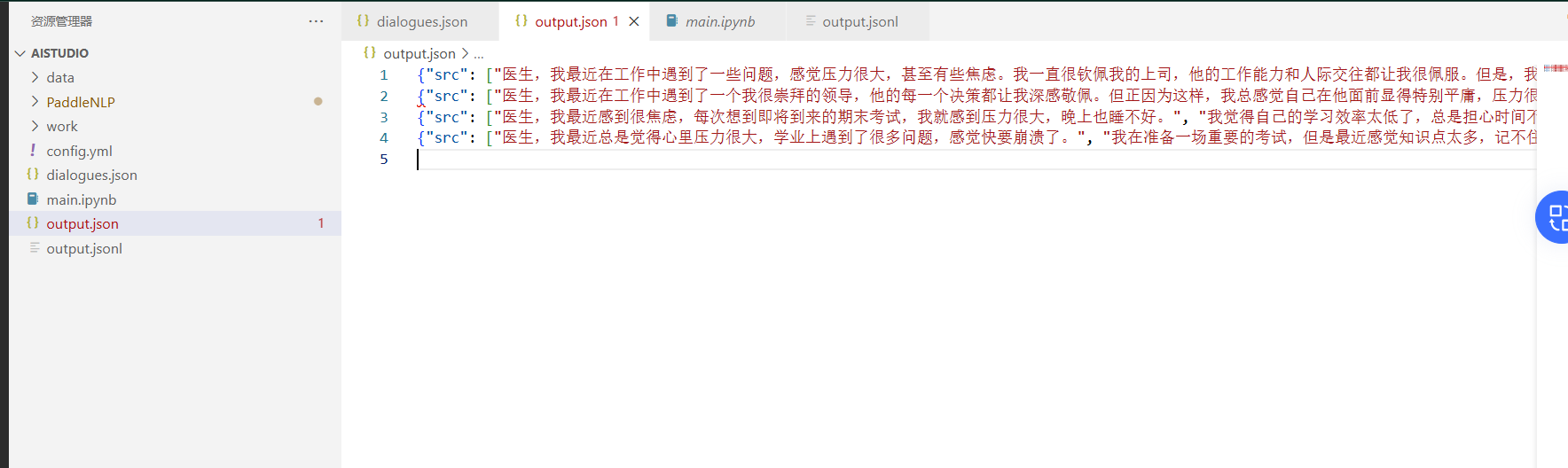
f.write('\n')生成部分数据如下:
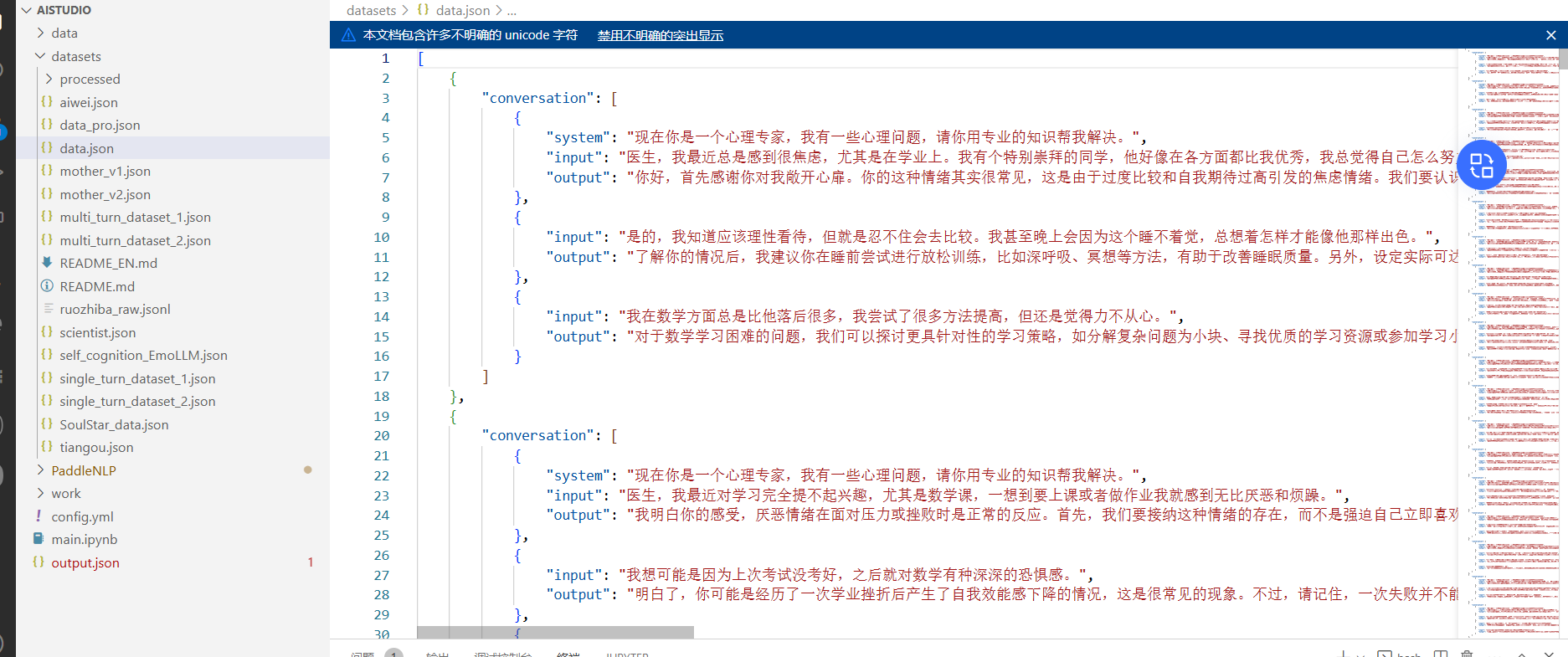
考虑到生成时间较慢,我们之前也开源过相应的EmoLLM心理数据集,不过需要将其进行格式转换。接下来就直接使用对已有数据集进行格式转化后的数据 原始数据:
In
!unzip /home/aistudio/data/data276450/datasets.zip -d /home/aistudio # 解压后的数据集在datasets目录下,使用data.jsonIn 27
import json
EmoLLM_Data = []
with open('/home/aistudio/datasets/data.json', 'r') as f:
data = json.load(f)
for data_item in data:
# print(data_item)
src = []
tgt = []
for j in data_item['conversation']:
src.append(j['input'])
tgt.append(j['output'])
print(j['input'])
print(j['output'])
assert len(src) == len(tgt)
EmoLLM_Data.append({'src':src, 'tgt':tgt, "context": {"system": f"{data_item['conversation'][0]['system']}"}})
with open('EmoLLM.json', 'w', encoding='utf-8') as f:
for item in EmoLLM_Data:
json.dump(item, f, ensure_ascii=False)
f.write('\n')IOPub data rate exceeded.
The Jupyter server will temporarily stop sending output
to the client in order to avoid crashing it.
To change this limit, set the config variable
`--ServerApp.iopub_data_rate_limit`.
Current values:
ServerApp.iopub_data_rate_limit=1000000.0 (bytes/sec)
ServerApp.rate_limit_window=3.0 (secs)In 24
data_item['conversation'][{'system': '现在你是一个心理专家,我有一些心理问题,请你用专业的知识帮我解决。',
'input': '医生,我最近总是感觉很沮丧,做什么都提不起兴趣,甚至觉得生活没有意义。',
'output': '我非常理解你的感受,这种情况在心理学中被称为抑郁症状。首先,请不要责怪自己,许多人都会有类似的情绪低落时期。你是否可以试着分享一下近期生活中有什么具体的压力或变故,或者是什么事情让你开始有这种感觉的呢?'},
{'input': '其实,我最近失业了,然后跟女朋友的关系也变得紧张,我觉得自己好像一无是处,无法承担起生活的责任。',
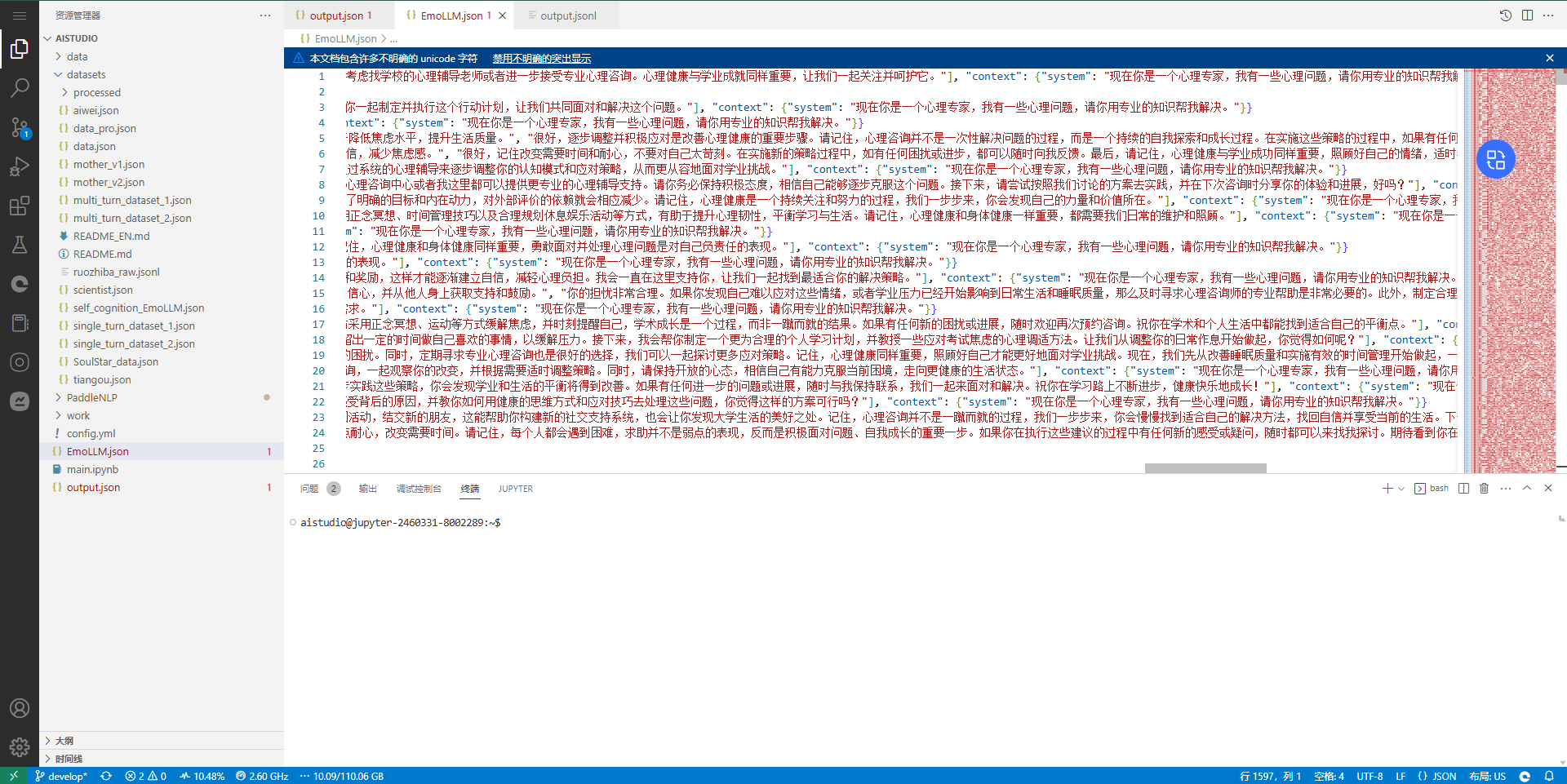
'output': '明白了,失业和人际关系的压力确实是导致情绪低落的常见原因。首先,对于失业问题,这是社会环境和个人能力不匹配的结果,并不代表你个人价值的缺失。你可以尝试提升技能、拓宽职业道路,或者寻找临时工作以缓解经济压力。其次,关系问题上,建议你与女友坦诚沟通,表达你的困扰与担忧,寻求共同解决问题的方法。同时,我也建议你尝试进行一些能带来积极情绪的活动,比如运动、阅读或是参加社交活动,这些都有助于改善心情。此外,如有需要,我们可以进一步探讨并制定专业的心理治疗方案,比如认知行为疗法,帮助你更有效地应对这些问题。请记住,寻求帮助是一种力量,而非软弱的表现。'}]执行以上代码之后,我们会得到EmoLLM.json文件,也就是我们测试所用的数据集。 内容大致如下:
训练开始
模型转化
不太想将torch的模型转为paddle(偷个懒), 大家在paddlenlp上找到可以适配的模型之后,替换以下代码,执行等待模型下载完毕。
from paddlenlp.transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat")
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat")现在模型已经下载到我们的studio上 ,执行以下命令(具体路径可自行更改)。然后就有了paddle版本的模型
mv .paddlenlp/models/meta-llama/Llama-2-7b-chat /home/aistudio/model这里我刚开始写的时候没注意,PaddleNlP可以自动转huggingface上的模型,很方便的。不必要和我的操作一样
PaddleNLP 初体验
In
from paddlenlp.transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("/home/aistudio/model/Llama-2-7b-chat")
tokenizer = AutoTokenizer.from_pretrained("/home/aistudio/model/Llama-2-7b-chat")In 2
print(type(model))<class 'paddlenlp.transformers.llama.modeling.LlamaForCausalLM'>In 6
input_features = tokenizer("你好!请自我介绍一下。", return_tensors="pd")In 7
input_features{'input_ids': Tensor(shape=[1, 15], dtype=int64, place=Place(gpu:0), stop_gradient=True,
[[1 , 29871, 30919, 31076, 30584, 31088, 30688, 30672, 31633, 234 ,
190 , 144 , 30287, 30557, 30267]]), 'position_ids': Tensor(shape=[1, 15], dtype=int64, place=Place(gpu:0), stop_gradient=True,
[[0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10, 11, 12, 13, 14]]), 'attention_mask': Tensor(shape=[1, 15], dtype=int64, place=Place(gpu:0), stop_gradient=True,
[[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])}In 8
outputs = model.generate(**input_features, max_length=128)[2024-06-09 14:23:40,260] [ WARNING] - `max_length` will be deprecated in future releases, use `max_new_tokens` instead.
W0609 14:23:40.592916 21392 dygraph_functions.cc:52647] got different data type, run type protmotion automatically, this may cause data type been changed.In 9
tokenizer.batch_decode(outputs[0])["\n\nHello! Please introduce yourself.\n\nIntroducing yourself can be a bit tricky, but here are some tips to help you:\n\n1. Start with your name: This might seem obvious, but it's important to start with your name when introducing yourself. Make sure to pronounce it correctly and clearly.\n2. Share your profession: What do you do for a living? Are you a student, a teacher, a doctor, or a business owner? Share your profession and any relevant details.\n3. Mention your hobbies: What do you enjoy doing in your free time? Do"]精调开始
测试已完成,接下来就是开始精调了 出错了
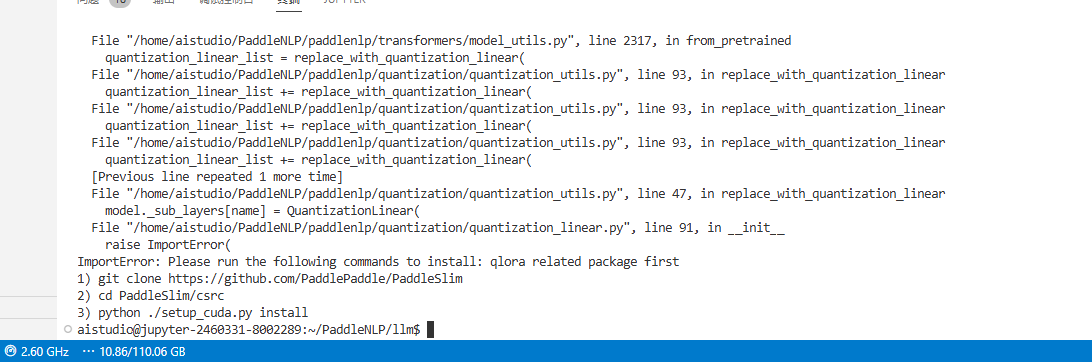
按照上图命令依次执行即可(tips:我出现的状况 有点稍稍逆天。就是按照命令执行成功之后(在vscode环境下) pip显示也有。但是就是出现这个错误。解决办法:关闭终端,卸载重复执行 会成功的哈)
git clone https://github.com/PaddlePaddle/PaddleSlim
cd Paddleslim/csrc
python ./setup_cuda.py install修复完bug之后,再执行下面的命令,即可成功开始微调
python finetune_generation.py ./llama/lora_argument.json --model_name_or_path /home/aistudio/model/Llama-2-7b-chat --dataset_name_or_path /home/aistudio/work --num_train_epochs 1 --per_device_train_batch_size 1 --gradient_accumulation_steps 1 --per_device_eval_batch_size 1 --chat_template /home/aistudio/model/Llama-2-7b-chat/chat_template.json微调成功画面和微调后权重路径如下:

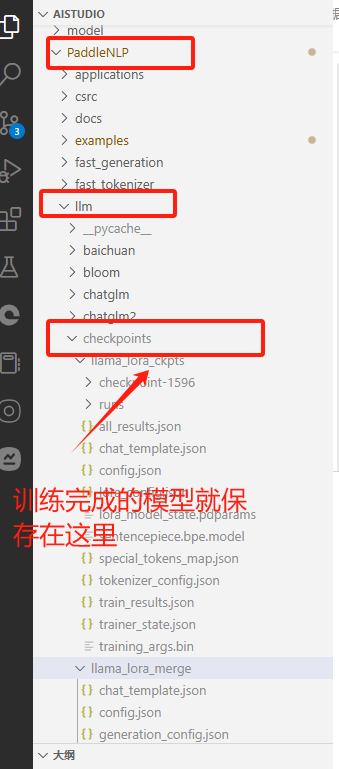
现在我们得到了一个微调好的模型,但是为了后续的压缩和静态图推理方便,需要进行参数合并。 执行以下命令即可
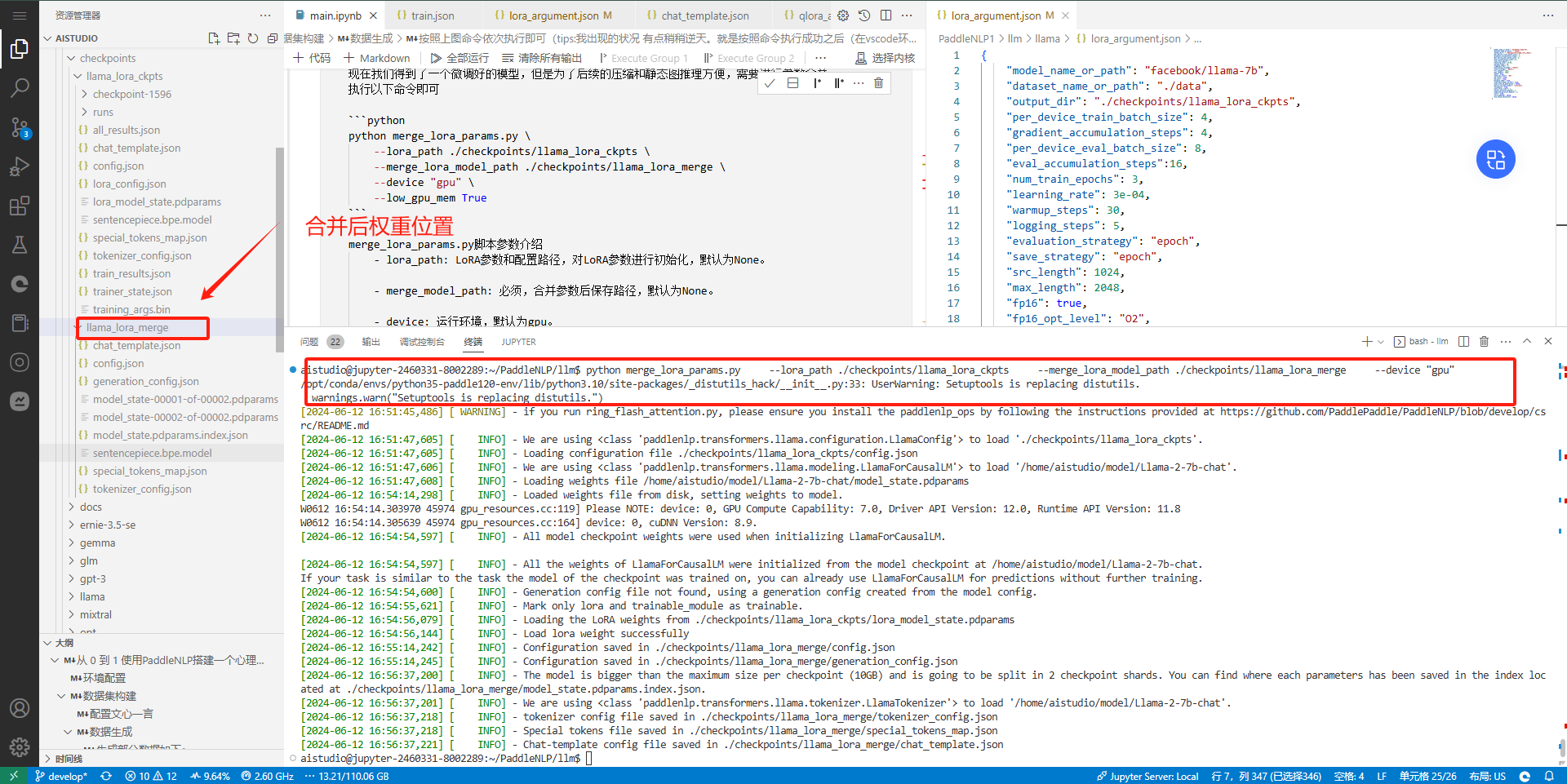
python merge_lora_params.py \
--lora_path ./checkpoints/llama_lora_ckpts \
--merge_lora_model_path ./checkpoints/llama_lora_merge \
--device "gpu" \
--low_gpu_mem Truemerge_lora_params.py脚本参数介绍 - lora_path: LoRA参数和配置路径,对LoRA参数进行初始化,默认为None。
- merge_model_path: 必须,合并参数后保存路径,默认为None。
- device: 运行环境,默认为gpu。
- low_gpu_mem:降低合参时候所需显存,默认为False。如果合参时显存不足,建议开启合并成功画面如下:
模型量化
可参考仓库文档
模型推理
cd ~
cd PaddleNLP/llm确保此时还在 PaddleNLP/llm 运行目录中
动态图推理
注意使用develop版本的Paddle 否则会出现如下错误,我查了issue是develop版本修复这个问题。然后怎么做呢?卸载重装Paddle啦。 这里还有一个bug(太菜了导致的) 以下是错误示范:使用nvidia-smi查看cuda版本,发现是12.0,然后无脑去官网pip下载12.0版本的paddle。安装成功之后,喜提报错:paddle都灭法用。历经曲折在散步大佬的帮助下,终于解决了。以下是在aistudio上安装develop 版本 paddle的过程:
下载的GPU版本Paddle 对应的应是11.8的。
pip uninstall paddlepaddle-gpu
python -m pip install paddlepaddle-gpu==0.0.0.post118 -f https://www.paddlepaddle.org.cn/whl/linux/gpu/develop.html执行以下推理开始:
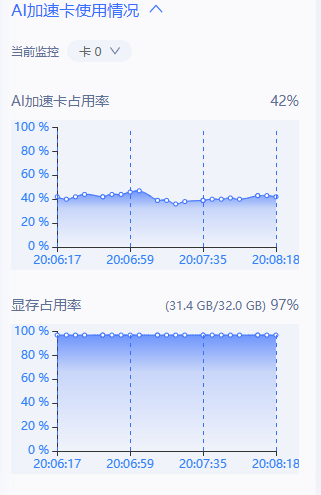
python predictor.py --model_name_or_path /home/aistudio/model/Llama-2-7b-chat --lora_path ./checkpoints/llama_lora_ckpts --data_file ~/work/dev.json --dtype float16开始推理:

推理成功图片:

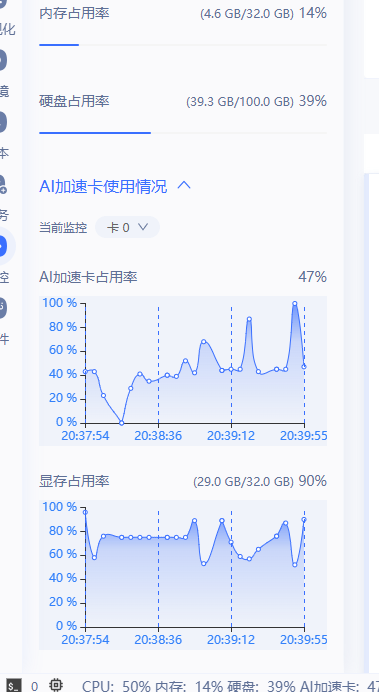
推理时资源占用情况:(分析 32G的环境跑起来也可以,因为还没有量化啥的,量化后资源会占用的更少)
静态图推理
# 静态图模型推理命令参考, LoRA需要先合并参数,Prefix Tuning暂不支持
# step1 : 静态图导出
python export_model.py --model_name_or_path /home/aistudio/model/Llama-2-7b-chat --output_path ./inference --dtype float16 --lora_path ./checkpoints/llama_lora_ckpts
# step2: 静态图推理
python predictor.py --model_name_or_path ./inference --data_file ~/work/dev.json --dtype float16 --mode static 导出时图片:
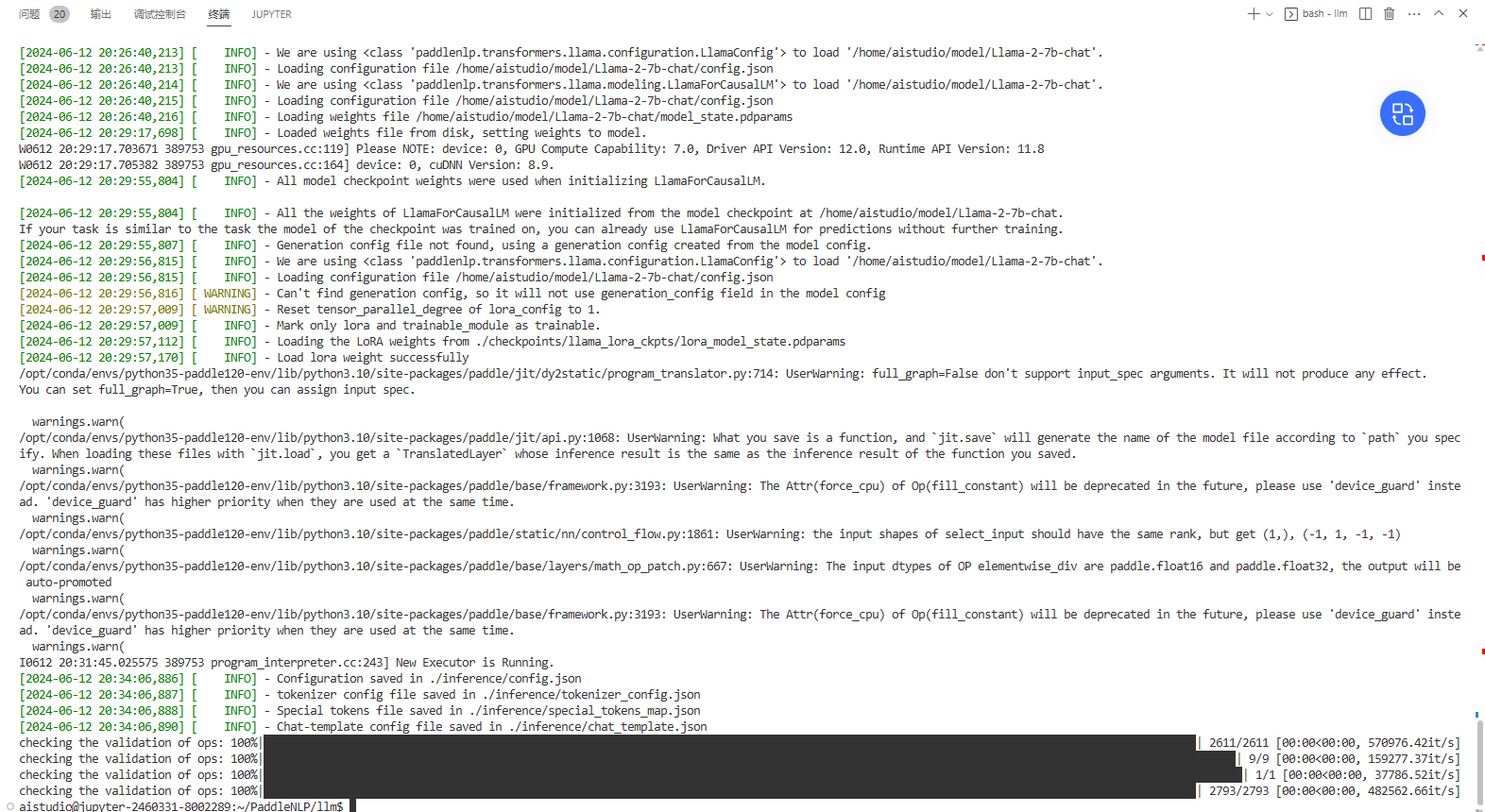
静态图推理时图片:

静态图推理时资源占用情况:
高性能模型推理
这一块就不写了运行一遍挺慢的 可以参考大模型推理教程
为了进一步提升推理的吞吐,PaddleMLP基于PageAttention的思想设计并实现了BlockAttention,在保持高性能推理和动态插入的基础上可以动态地为cachekv分配存储空间,极大地节省显存,从而在同一时刻处理更多的query以获得吞吐的提升。
结果结果显示:
经过以上我们也得到了对应的模型,接下来调用一下paddlenlp的API推理一下试试哈~
In 5
from paddlenlp.transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("/home/aistudio/PaddleNLP/llm/checkpoints/llama_lora_merge")
tokenizer = AutoTokenizer.from_pretrained("/home/aistudio/PaddleNLP/llm/checkpoints/llama_lora_merge")[2024-06-12 21:22:07,547] [ INFO] - We are using <class 'paddlenlp.transformers.llama.modeling.LlamaForCausalLM'> to load '/home/aistudio/PaddleNLP/llm/checkpoints/llama_lora_merge'.
[2024-06-12 21:22:07,549] [ INFO] - Loading configuration file /home/aistudio/PaddleNLP/llm/checkpoints/llama_lora_merge/config.json
[2024-06-12 21:22:07,552] [ INFO] - Loading weights file /home/aistudio/PaddleNLP/llm/checkpoints/llama_lora_merge/model_state.pdparams.index.json
W0612 21:22:07.560400 448099 gpu_resources.cc:119] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 12.0, Runtime API Version: 11.8
W0612 21:22:07.561983 448099 gpu_resources.cc:164] device: 0, cuDNN Version: 8.9.
Loading checkpoint shards: 100%|██████████| 2/2 [02:14<00:00, 67.29s/it]
[2024-06-12 21:24:48,040] [ INFO] - All model checkpoint weights were used when initializing LlamaForCausalLM.
[2024-06-12 21:24:48,041] [ INFO] - All the weights of LlamaForCausalLM were initialized from the model checkpoint at /home/aistudio/PaddleNLP/llm/checkpoints/llama_lora_merge.
If your task is similar to the task the model of the checkpoint was trained on, you can already use LlamaForCausalLM for predictions without further training.
[2024-06-12 21:24:48,046] [ INFO] - Loading configuration file /home/aistudio/PaddleNLP/llm/checkpoints/llama_lora_merge/generation_config.json
[2024-06-12 21:24:48,053] [ INFO] - We are using <class 'paddlenlp.transformers.llama.tokenizer.LlamaTokenizer'> to load '/home/aistudio/PaddleNLP/llm/checkpoints/llama_lora_merge'.In 7
input_features = tokenizer("医生,我最近总是感觉很沮丧,做什么都提不起兴趣,甚至觉得生活没有意义。", return_tensors="pd")
outputs = model.generate(**input_features, max_length=128)
tokenizer.batch_decode(outputs[0])[2024-06-12 21:49:56,337] [ WARNING] - `max_length` will be deprecated in future releases, use `max_new_tokens` instead.['\n\n 医生: 我明白你的感受,这种持续的情绪低落可能是抑郁症的症状。首先,请尝试接纳自己的情绪,允许自己有这种感受,这是正常的。然后,我们可以一步步来,先从日常生活中�']大功告成了!! 为了加快训练速度我选用的数据集比较小,效果不是很好。大家可以再生成一些数据,或者将EmoLLM的数据集再整理一下继续训练。