索引的分类和回表查询
Mysql 的索引按照类型可以分为以下几类,但是我们使用的 InnoDB 只支持主键索引,唯一索引,普通索引,并不支持全文索引。

1、聚集索引和二级索引
InnoDB 可以将索引分为两类分别是聚集索引和二级索引,也可以叫做聚簇索引和非聚簇索引。
聚集索引的叶子节点存储的是一整行的数据。

二级索引的叶子节点存储的是该行的主键。
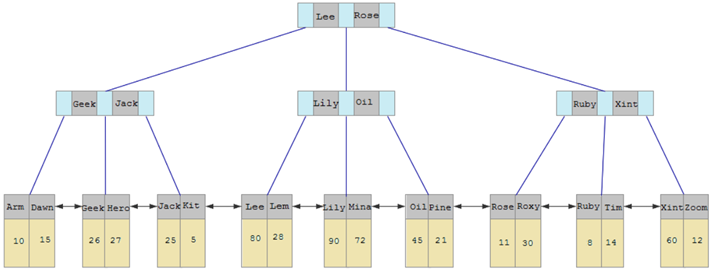
聚集索引选取规则:
- 如果存在主键,主键索引就是聚集索引。
- 如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引。
- 如果表没有主键,或没有合适的唯一索引,则 InnoDB 会自动生成一个 rowid 作为隐藏的聚集索引。
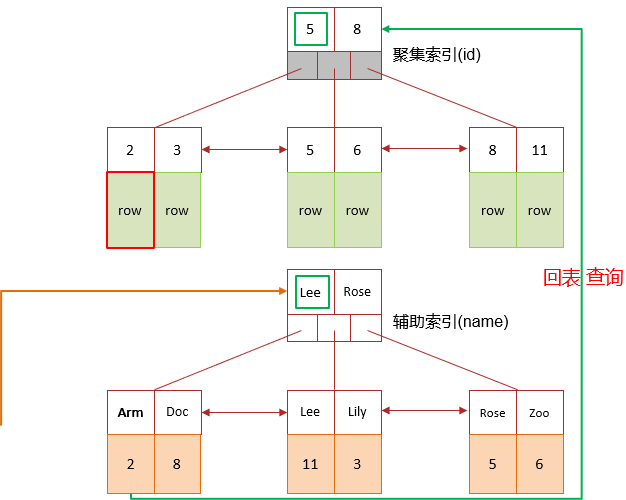
2、覆盖索引和回表查询
覆盖索引是指查询使用了索引,并且需要返回的列,在该索引中已经全部能够找到。
例如:
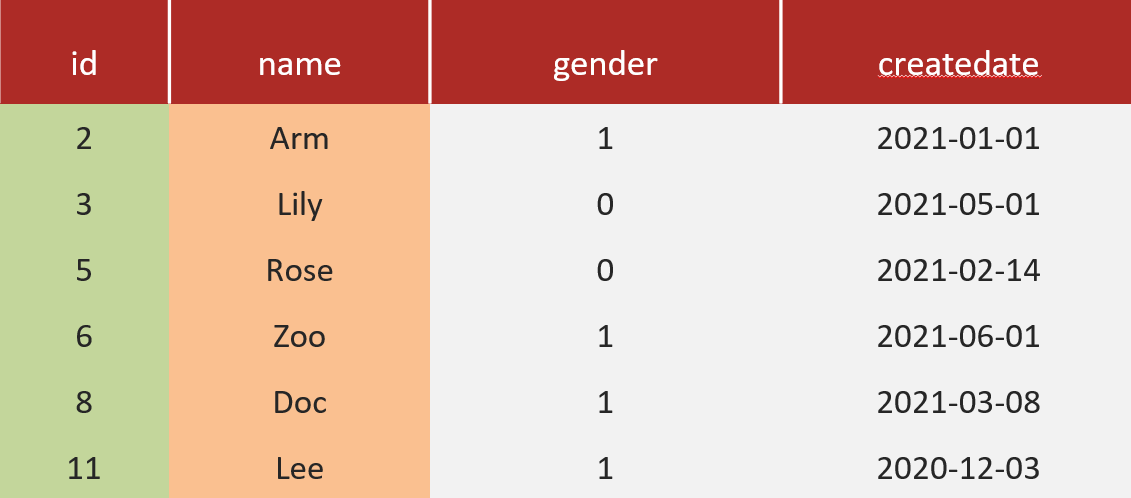
我们针对这张表创建两个索引,分别是 id 为主键索引(默认),name 字段为普通索引。
sql
select * from tb_user where id = 1
select id,name from tb_user where name = 'Arm'
select id,name,gender from tb_user where name = 'Arm'1、sql 1 需要查询所有字段,可以使用主键索引,查询到所有字段,因为主键索引是聚集索引,也就是说该行的所有字段都在主键索引的叶子节点上,自然我们能就可以使用 id 查到索引中包含的所有的列,是覆盖索引。
2、sql 2 中我们只查询了 id 和 name 两个字段,查询条件是 name 字段,name 字段我们创建了普通索引,上面我们讲了普通索引是二级索引,叶子节点上的数据只有 id,索引本身包含了 name 字段。所以也可以返回需要的所有的列,是覆盖索引。
3、sql 3 中我们需要查询 id,name 和 gender 三个字段,条件是 name 字段,走普通索引,但是由于索引上我们只能找到 id 和 name 两个字段。所以我们还需要拿查找到的 id 去主键索引上进行二次查找,才能找到对应的 gender 字段。这个就叫做回表查询
3、超大分页优化
超大分页问题就是我们在使用 limit 关键字的时候,例如我们的表中有 10w 条数据, limit 0,10 分页获取前十条数据,这样查询非常快。
但是如果 limit 99990,10 去获取最后十条数据的时候,运行速度就变得非常的慢了。
因为 limit 在使用的时候,针对于分页的数据会进行遍历。所以获取越往后的数据,效率就越低。

优化思路: 一般分页查询时,通过创建覆盖索引能够比较好地提高性能,可以通过覆盖索引加子查询形式进行优化
sql
select * from tb_sku t, (select id from tb_sku order by id limit 9000000,10) a where t.id = a.id;因为索引自带排序功能,这样就不需要进行遍历了。