目录
一,音频获取
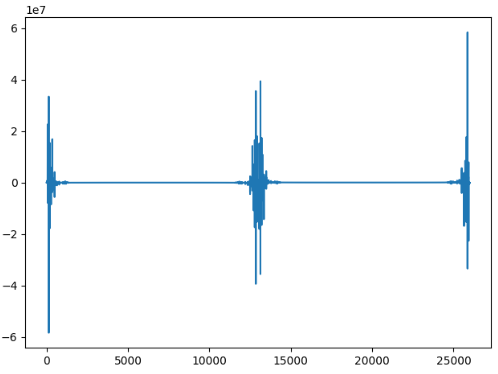
我用电子琴(音色模式是卧式钢琴),把中音区的7个音节分别按了5次,录音得到音频文件
首先查看振幅:
cpp
from pydub import AudioSegment
import matplotlib.pyplot as plt
from pydub import AudioSegment
import numpy as np
audio = AudioSegment.from_file("D:/1234567.m4a")
audio.export("D:/1234567_.mp3", format="mp3")
arr=audio.get_array_of_samples()
plt.plot(arr)
plt.show()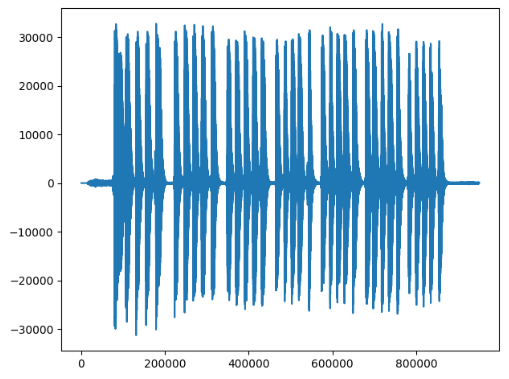
规律很明显,每一个峰值就是一个音节。
9秒的音频有90万个采样点,大概1秒采样10万次,考虑实际情况,应该是96000次。
二,信号的基本形态
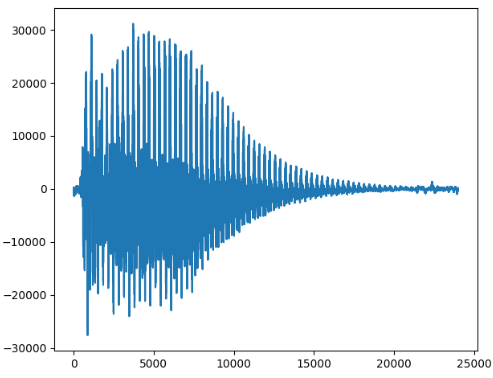
第一个音节5次:
cpp
v=arr[75000:205000]
plt.plot(v)
plt.show()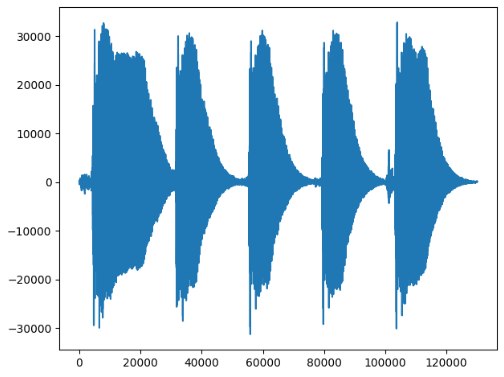
第一个音节第1次:
cpp
v=arr[80000:106000]
plt.plot(v)
plt.show()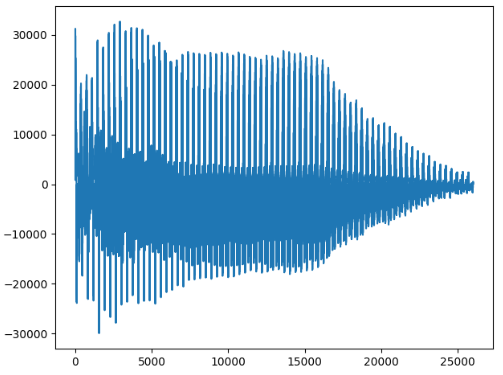
第二次:
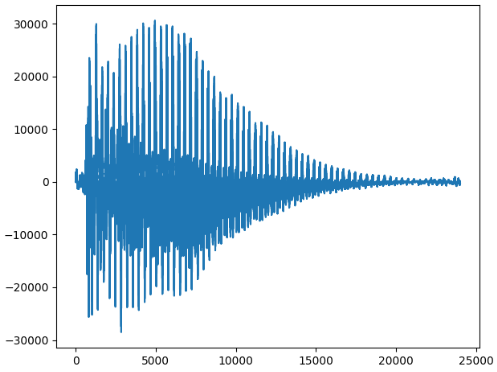
第三次:
第四次:
第五次:
每个音节都是一个衰减的趋势,而且每个键的衰减周期是差不多的。
三,衰减信号的频域信号
衰减信号示例:
cpp
num = 100
x = linspace(0,num-1,num)
f = cos(pi*x) * cos(pi*x/200)
plot(x, f)
show()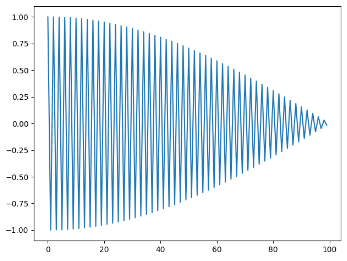
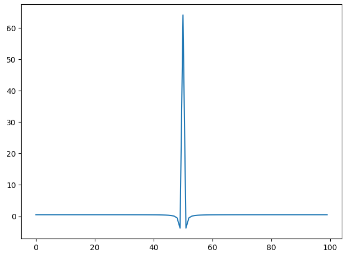
频域实部:
频域虚部:
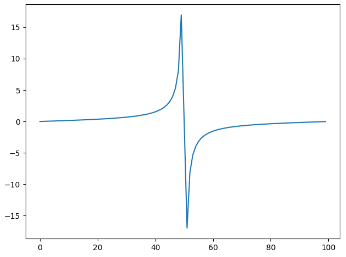
可以看出,即使有衰减,频域信号也能非常清晰的看出信号频率。
四,低频信号
一个衰减周期内有很多震动周期,所以我们先局部放大:
cpp
plt.plot(arr[131000:132000])
plt.show()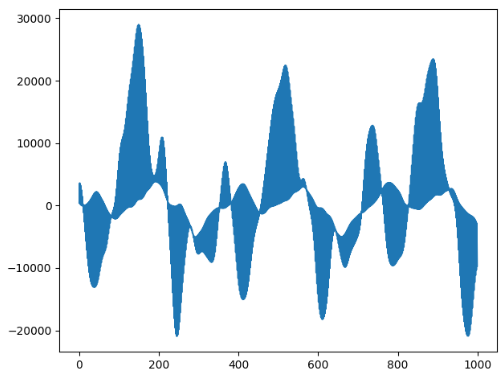
可以看出来主频信号大概是每400个采样点是一个周期,即250HZ
再对整个音节的信号做一个傅里叶变换:
cpp
H = np.fft.fft(v)
plt.plot(H.real)
plt.show()
plt.plot(H.imag)
plt.show()实部:
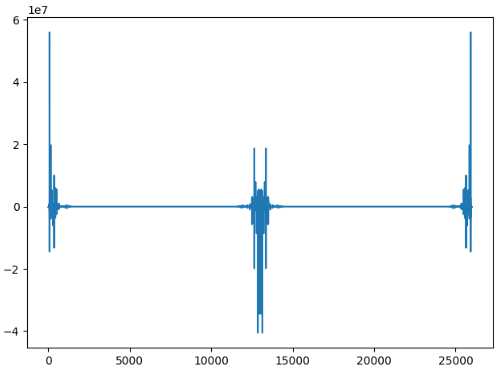
虚部:
如果周期大概是400个采样点,那么信号对应的频点应该是在60左右。
低频信号放大:
cpp
r = H.real
plt.plot(r[0:2000])
plt.show()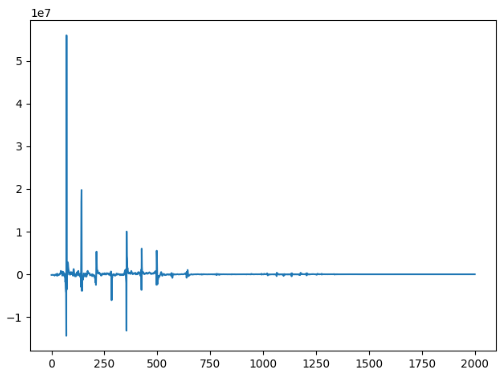
再放大,并统计频点:
cpp
r2 = r[0:750]
plt.plot(r2)
plt.show()
print("96000/len=",end='')
print(96000.0 / len(r))
for id in range(0,len(r2)):
if(abs(r2[id])>6000000):
print(id)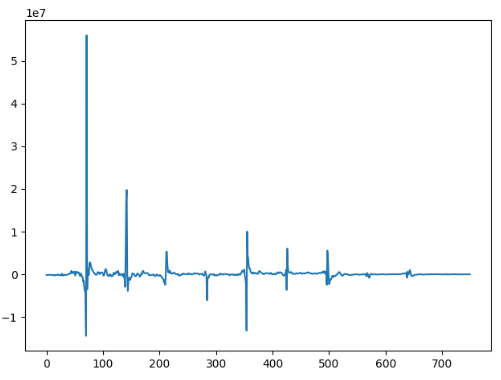
输出:
96000/len=3.6923076923076925
70
71
141
142
284
354
355
426
所以第一个频点应该是71
对应的频率是3.6923076923076925 * 71 = 262.2赫兹
对于第一个音节后面出现的几次,按照类似的方式计算,算出的结果分别是:262.4 262.4 262.1 262.0
所以,这个方法应该没错,单个音节5次的频率是一样的。
五,高频信号
用实部继续分析高频信号:
cpp
r = H.real
plt.plot(r[10000:13000])
plt.show()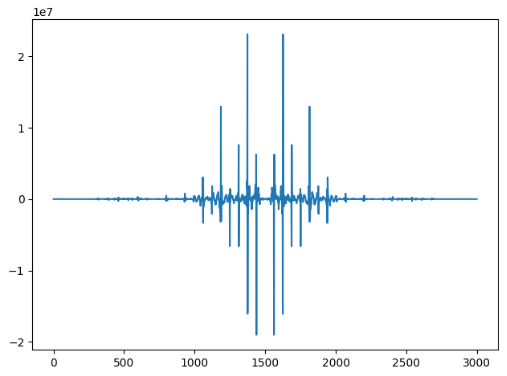
这是一个对称的图形,我们再把局部放大:
cpp
r = H.real
plt.plot(r[11000:11500])
plt.show()
我们把几个频点提取出来:
cpp
r2 = r[11000:11500]
print(r2)
for id in range(0,len(r2)):
if(abs(r2[id])>4000000):
print(id)输出:
186
249
312
313
314
373
374
375
376
436
438
其中 186 249 312 375 438这几个频点刚好构成等差数列,差值是63
加上偏移量,分别是11186 11249 11312 11375 11438
按照同样的方法:
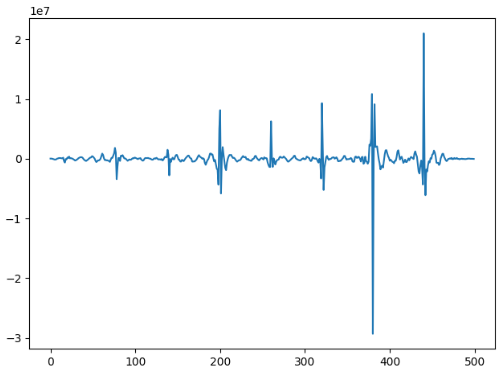
对应的频点分别是10700 10760 10820 10880 10940
也是刚好等差数列,但是差值是60
同样的方法:
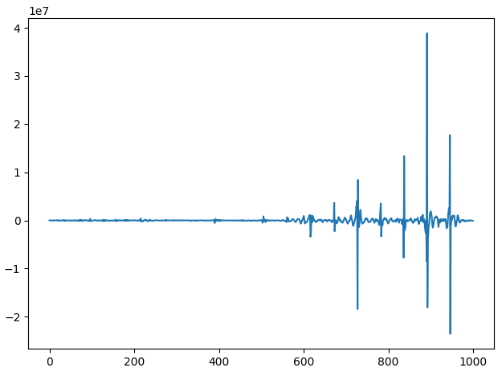
对应的频点分别是9672 9727 9782 9837 9892 9946
如果最后一个频点加上1,那就刚好构成等差数列,差值是55
汇总一下:
第一个音节的其中三次信号的高频信号:
11186 11249 11312 11375 11438 差值63
10700 10760 10820 10880 10940 差值60
9672 9727 9782 9837 9892 9947 差值55
第二个音节,按照同样的方法分析:
10179 10243 10307 10371 10435 差值64
所以这些频点到底代表啥?等差数列又代表啥?
我也不清楚。
六,七个音节的频率
前面已经算出来,第一个音节频率是262赫兹。
按照同样的方法,分别可以算出其他音节的频率。
第二个:
294赫兹
第三个:
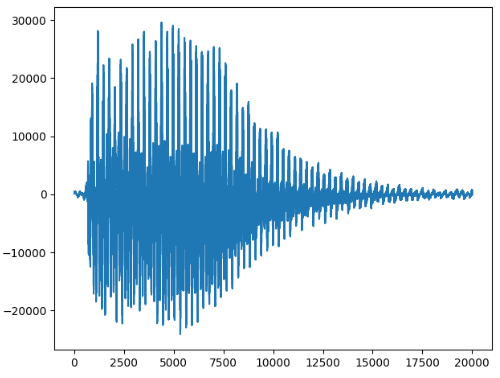
329赫兹
第四个:
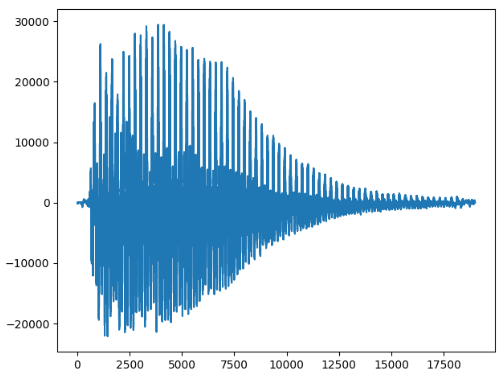
350赫兹
第五个:
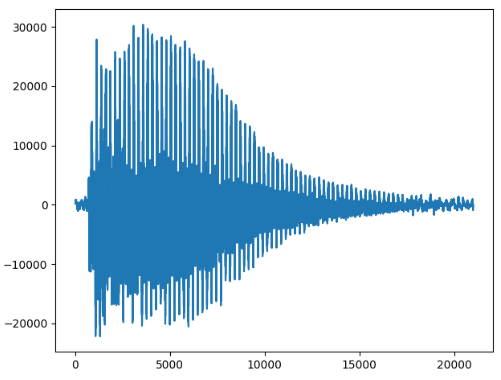
393赫兹
第六个:
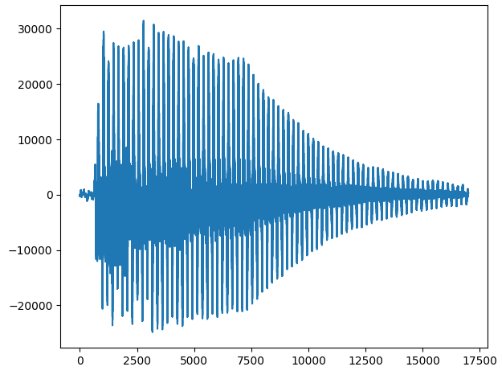
439赫兹
第七个:

493赫兹
所以相邻的7个音节,分别是262 294 329 350 393 439 493赫兹
显然,和钢琴的十二平均律对比,误差在1赫兹之内。
另外,我这里的第6个音,即中音区A,其实应该是国际标准音440赫兹,误差是1赫兹。