
笔记整理:郭凌冰,浙江大学博士,研究方向为知识图谱
1. 动机
多模态实体链接(Multimodal Entity Linking,MEL)旨在将带有多模态上下文的提及映射到知识库(如维基百科)中的参考实体。现有的MEL方法主要侧重于设计复杂的多模态交互机制,并需要对所有模型参数进行微调,这在大型语言模型(LLM)时代可能成本过高且难以扩展。在本文中,作者提出了一种简单而有效的基于LLM的生成式多模态实体链接框架(Generative Multimodal
Entity Linking framework based on LLMs),称为GEMEL,该框架直接生成目标实体名称。GEMEL将视觉和语言模型固定,仅训练一个特征映射器以实现跨模态交互。该方法与任何现成的语言模型兼容,为在MEL任务中利用LLM的高效和通用解决方案铺平了道路。
2. 贡献
本文的主要贡献有:
(1)作者提出了GEMEL,一个简单而有效的多模态实体链接框架,其利用生成式LLM来解决MEL任务。这是首个在MEL任务中引入基于LLM的生成方法的工作。
(2)大量实验证明,仅微调约0.3%的模型参数,GEMEL在两个成熟的MEL数据集上取得了最先进的结果(在WikiDiverse上提高了7.7%的准确率,在WikiMEL上提高了8.8%的准确率),展现了高参数效率和强大的可扩展性。
(3)论文进一步的研究揭示了LLM预测中的流行度偏差,而GEMEL框架可以有效缓解这种偏差,从而提高MEL任务的整体性能。
3. 方法
总体框架如图1所示,给定多模态提及上下文,GEMEL可以利用LLM的能力直接生成目标实体名称(例如,"轮椅击剑"),并使用n个检索到的多模态实例作为上下文示例。图中的<image>表示视觉前缀,文本中的提及被下划线标记。GEMEL将LLM和视觉编码器的参数固定,只训练一个特征映射器将图像特征映射到文本空间中。

图1 总体框架图
GEMEL由两个模块组成:即特征对齐和语言模型生成:
对于特征对齐,作者首先从冻结的视觉编码器中提取图像特征。然后,通过特征映射器将这些图像特征投影到文本嵌入空间中,并将其作为视觉前缀输入到LLM中。
其中视觉编码器是为了从与提及(Mention)对应的输入图像中提取视觉特征,GEMEL利用一个预训练的视觉骨干模型,该模型生成维度为 ,其权重被保持冻结状态。
特征映射器:为了促进跨模态对齐和融合,作者使用一个特征映射器将视觉特征投影到一个软提示中,即LLM的视觉前缀输入。具体来讲,通过训练一个特征映射器W对视觉嵌入投影,然后将结果重塑为一个视觉前缀,即一个包含k个嵌入向量 的序列,其中每个嵌入向量与LLM输入标记生成的文本嵌入具有相同的隐藏维度 。
对于语言模型生成,为了让LLM更好地理解MEL任务,作者利用其上下文学习(in-context learning,ICL)能力,并从训练集中构建一个提示模板,其中包含n个示例演示。以图1中的蓝色框为例,其包括提及m的图像、文本上下文、一个人工写的问题(如,"m指的是什么?")、以及实体名称作为答案。对于演示示例的选择,作者考虑了多种稀疏和密集检索方法:
随机选择:在训练集中,对于每个提及,随机选择将从训练集中随机选择一个上下文示例。
BM25:BM25是最先进的稀疏检索方法之一。作者将训练集中的所有提及作为语料库,并基于提及来检索示例。
SimCSE3:SimCSE3是一种用于语义匹配的密集检索方法。对于一对提及,作者将提及嵌入的余弦相似度作为相关性分数。
对于n个示例和查询q,作者按顺序连接视觉前缀v和文本嵌入t,以获得LLM的输入x:
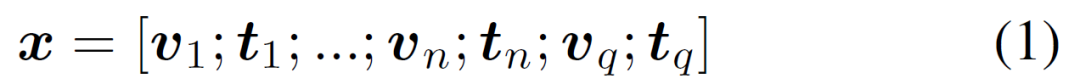
接着,作者使用自回归的 LLM,该语言模型最初是在仅使用文本数据的情况下通过最大似然目标进行训练,并且保持其参数 θ 不变。利用输入嵌入 x 和表示实体名称的 N 个标记作为目标输出 ,可以将教师强制训练目标(teacher forcing training objective)表示如下:
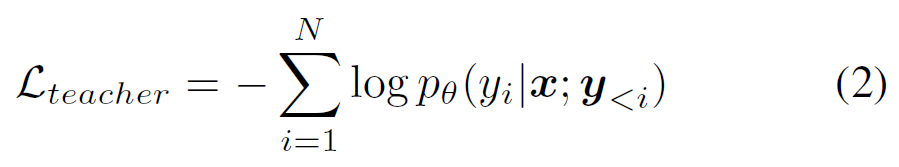
在推理阶段,遵循 GENRE方法,作者采用约束束搜索(constrained beam search)来确保生成的实体名称在知识库中始终保持一致且有效。
4. 实验
作者首先说明了实验设置:在数据集的选择上,为了评估GEMEL在MEL任务上的能力,作者在两个标准MEL数据集上进行实验,分别是WikiDiverse和WikiMEL。WikiDiverse是一个人工标注的MEL数据集,包含来自Wikinews的多样化上下文主题和实体类型。WikiMEL是一个大型的经过人工验证的MEL数据集,从Wikidata和Wikipedia中提取而来。Wikidiverse和WikiMEL数据集都已经划分为训练集、验证集和测试集,比例分别为8:1:1和7:1:2,并且作者的实验设置遵循这个划分,其统计信息如表1所示:

表1 数据集统计
在基线模型的选择上,作者将GEMEL与最近的最先进方法进行比较。这些方法可以分为以下两类:(1)仅使用文本特征的纯文本方法,和(2)利用文本和视觉特征的文本+视觉方法。其中包括:BERT、BLINK、GENRE、GPT-3.5-Turbo-0613等。
在评估指标上,作者遵循先前的研究采用Top-1准确率作为评估指标。
主实验结果如表2所示:

表2 主实验结果
从实验结果中可以看出:首先,GEMEL在两个MEL数据集上超过了所有其他方法,并取得了最先进的性能,WikiDiverse的改进为7.7%(从78.6%提高到86.3%),WikiMEL的改进为8.8%(从73.8%提高到82.6%),显示了其框架的有效性。这表明通过微调特征映射器(约占模型参数的0.3%),GEMEL能够使冻结的LLM有效而高效地理解视觉信息,并利用它来增强MEL性能。其次,基于LLM的方法(即GPT-3.5和GEMEL)在文本模态和多模态下表现出强大的性能。在文本模态中,GPT-3.5可以达到甚至超过先前多模态方法的性能。这主要有两个原因:1)文本模态在MEL任务中仍然起着主导作用,而视觉模态主要作为补充信息;2)在大规模预训练数据集上预训练的LLM可以捕捉广泛的语言模式、上下文和知识,从而在常见实体预测中表现出色。
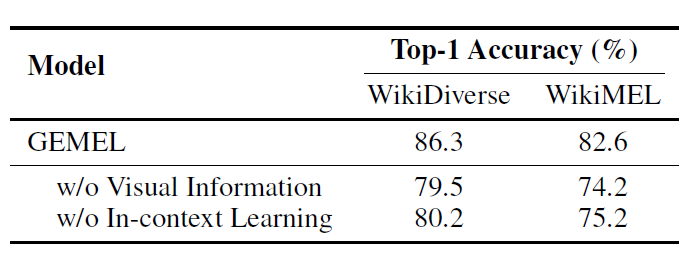
表3 消融实验结果
表3展示了消融研究的结果。首先,移除视觉信息显著损害了GEMEL的性能,这表明当文本信息较短且不足时,视觉信息的重要性(详见第5.4节中的案例)。其次,消除提示中的示例导致WikiDiverse和WikiMEL的性能分别下降了6.1%和7.4%。这表明在上下文中提供一些示例有助于LLM识别和理解MEL任务。
5. 总结
作者提出了GEMEL,一种基于LLMs的简单而有效的生成式多模态实体链接框架,利用LLMs的能力直接生成目标实体名称。实验结果表明,GEMEL在两个MEL数据集上优于最先进的方法,并具有高参数效率和强大的可扩展性。进一步的研究揭示了LLMs对尾部实体预测存在偏见,而GEMEL能够有效地缓解这种偏见,从而提高MEL任务的整体性能。此外,GEMEL是模型无关的,可以将其应用于将来更大或更强大的LLMs。进一步的研究可以探索如何缓解LLMs对尾部实体预测的偏见,并将GEMEL扩展到更多的模态(如视频、语音等)。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文 ,进入 OpenKG 网站。