这段时间学习了 KNN,线性回归,逻辑回归,贝叶斯,聚类(K-means,DBSCAN),决策树,集成学习(随机森林,XGboost),SVM支持向量机, TF-IDF,词向量转化,PCA降维。这十一种算法。下面进行一一回顾。
KNN
这个又叫做K近邻,大多用于分类,例如房价预测(这里可以预测房价的属于什么类,如果预测房价价格,可以取范围内房价的平均数)。
算法简述:
通过计算特征之间的距离(欧式距离或者其他),然后通过距离内的存在的标签进行投票,然后进行分类,去存在最多的那种标签。
重要参数:
from sklearn.neighbors import KNeighborsClassifier
model=KNeighborsClassifier(n_neighbors=5)
model.fit(train_X,train_y)
result1=model.score(test_X,test_y)
print(result1)这里重要参数就一个n_neighbors,可以用来控制取周围几个最近的标签点。
线性回归
这个平时用来预测回归问题,例如根据人体的各个指标来预测他们的血压收缩。
算法简述
通过拟合y=wx+b,这一条线来预测,这个过程中会有点偏离我们的线,然后引入了一个误差项Q=y-(wx+b),同时这个误差项满足标准正态分布,也就是说把Q带入标准正态分布表达式之后,这个正态分布的值越大,这个Q也就越小(具体看正态分布函数图像),然后就通过最小二乘法,梯度下降来求出最优W值。
重要参数:
from sklearn.linear_model import LinearRegression
model=LinearRegression()
model.fit(X,y)
result1=model.score(X,y)
a=model.coef_[0]
b=model.intercept_这个没什么重要参数,注意后面可以使用斜率和截距来预测结果。
逻辑回归
这个和线性回归很像,这个看着像是回归算法,但其实这个是一个分类算法。
算法简述
这个逻辑回归就是在线性回归的基础上进行了改进,主要内容就是,在求出上面逻辑回归的那条直线后,我们可以加一条z轴,然后引入一个sigmod激活函数,然后这个sigmod曲线在直线的正上方,然后我们把平面上的点映射到直线上,然后得出一个值,然后再带入到sigmod曲线中,然后把值映射到0-1之间,判断属于这一类的概率。
重要参数
from sklearn.linear_model import LogisticRegression
model=LogisticRegression(max_iter=1000,C=1.0,penalty='l2')
model.fit(data_train,label_train)
print(model.score(data_test,label_test))正则化强度倒数C(值越小,正则化越强,默认=1)是最重要的。这个可以控制权重的幅度,例如(1,0,0)和(0.3,0.3,0.3)显然是第二种比较好,然后我们的惩罚系数在第一种的时候就比第二种大,就会选用第二种。
正则化方法panalty,主要有两种L1正则化,L2正则化,L1和L2的区别就是L1是权重的绝对值之和,L2是权重的平方之和。这个C就是前面的系数
贝叶斯
这个算法主要用在语言处理上,在其他方面准确率表现比较低
算法简述
这个算法原理比较简单,就是根据已有数据,求出概率,然后带入高斯贝叶斯,多项式贝叶斯,或者什么贝叶斯来计算,就行了。
重要参数
from sklearn.naive_bayes import BernoulliNB
model=BernoulliNB()
model.fit(train_X,train_y)
print(model.score(test_X,test_y))这里没什么重要参数
K-means
这个是一个聚类算法,无监督学习不需要标签就可以进行
算法简述
开始随机选取K个点作为质心(可调,我们传入的参数),然后计算每个点到质心的距离,选取离质心最近的几个点分配给他。然后更新质心为分类簇的质心,逐渐迭代,到质心不发生变化为止。
重要参数
modle=KMeans(n_clusters=best_K)
modle.fit(X)
labels = modle.labels_
print('轮廓系数:',metrics.silhouette_score(X,labels))n_clusters,就是最初质心个数的选择。
max_iter 迭代次数,如果迭代的不够,模型结果可能不会那么准确
DBSCAN
这个与上面K-means算法差不多都是聚类,唯一不同就是聚类的方法不同。这个可以用于人脸识别,可以聚类出那种线性的类。
算法简述
DBSCAN开始会随机选一个点,开始传染,找距离内的几个点,然后就这样一直传染,最终变成一簇。每个簇都是这样。也可以这么说,每个点就找自己距离内的那个点,然后作为一类,最终可以看出分为几个类
重要参数
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(eps=2.5, min_samples=5, metric='euclidean')
clusters = dbscan.fit_predict(X)
print(clusters)eps;用来控制距离,搜索周边多少距离内的点
min_samples;用来表示搜索的时候距离内有多少点,才允许传染。
决策树
这个算法独自用的比较少,主要用来结合起来一起用于后面的随即森林。
算法简述
决策树有三种方法ID3,C4.5,CART,这三种算法。ID3是计算信息增益的,C4.5是在ID3的基础上计算信息增益率,CART是计算基尼指数。
重要参数
from sklearn.tree import DecisionTreeClassifier
model=DecisionTreeClassifier(criterion="gini",max_depth=best[0],random_state=42,min_samples_split=best[1],min_samples_leaf=best[2],max_leaf_nodes=best[3])
model.fit(train_X,train_y)- **
criterion**:分裂标准,可选'gini'(基尼系数)或'entropy'(信息增益)。 - **
max_depth**:树的最大深度(限制过拟合关键参数)。 - **
min_samples_split**:节点分裂所需最小样本数(值越大,树越简单)。 - **
min_samples_leaf**:叶节点最小样本数(控制叶子大小)
集成学习(随机森林)
这个就是上面算法的究极形态了,这个就是并行训练,这个还可以进行重要特征提取
算法简述
这个算法就是前面决策数进行整合,创建许多决策树模型,然后每个模型取百分之80的特征进行训练,然后把训练结果进行综合得出一个最佳。因为部分特征可能会影响训练结果。所以这选取0.8的特征就很有效果。
重要参数
from sklearn.ensemble import RandomForestClassifier
model=RandomForestClassifier(max_features='sqrt',n_jobs=-1,n_estimators=100,max_depth=10,min_samples_leaf=10,max_leaf_nodes=10)
model.fit(train_X,train_y)
im = pd.DataFrame({
'feature':train_X.columns,
'importances': model.feature_importances_
})
im = im.sort_values(by=['importances'], ascending=False)[:10]
print(im)n_estimators=100- 创建100棵决策树组成的森林max_depth=5- 限制每棵树的最大深度,防止单个树过拟合max_features='sqrt'- 每次分裂时只考虑√(总特征数)个特征min_samples_split=2- 节点至少需要2个样本才能继续分裂- model.feature_importances_这个可以获取重要特征
集成学习(XGboost)
这个是串行训练
算法简述
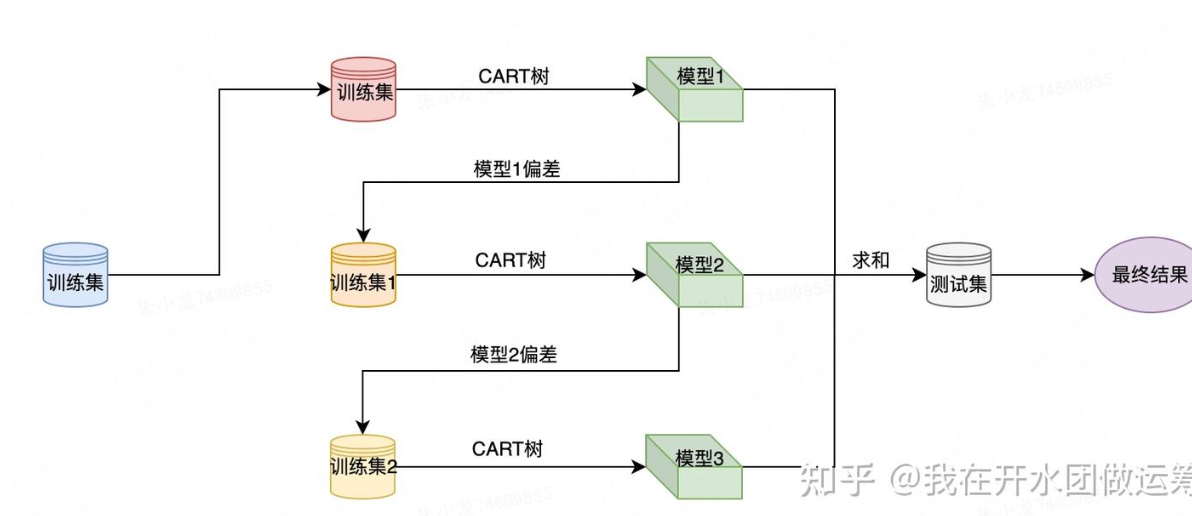
针对一个训练集,xgboost首先使用CART树训练得到一个模型,这样针对每个样本都会产生一个偏差值;然后将样本偏差值作为新的训练集,继续使用CART树训练得到一个新模型;以此重复,直至达到某个退出条件为止。引入了正则化项(L1/L2)控制模型复杂度以防止过拟合,优化了特征选择和分裂点算法(近似分位点、列采样),支持并行计算,处理缺失值等。
重要参数
from xgboost import XGBClassifier
xgb_model = XGBClassifier(
# 树结构参数
max_depth=3, # 树的最大深度
min_child_weight=1, # 子节点样本权重和的最小值
# 正则化参数
gamma=0.1, # 分裂所需最小损失减少量
reg_lambda=1.0, # L2正则化权重
# 学习控制
learning_rate=0.1, # 学习率
n_estimators=100, # 树的数量
# 抽样策略
subsample=0.8, # 训练样本采样比例
colsample_bytree=0.8, # 特征采样比例
# 其他参数
random_state=42, # 确保结果可复现
use_label_encoder=False # 避免警告
)SVM支持向量机
这个适用于小样本的训练
算法简述
在一个线性可分的两组数据中找到一个线(高维的两组数据就是超平面),这个超平面的限制条件就是在两组数据中夹着,并且距离相隔最大。如果线性不可分就映射到高维空间,映射到可分为止。这个映射函数就是核函数,核函数一般是高斯核函数或者其他核函数。
重要参数
from sklearn.svm import SVC
model = SVC(kernel='linear', C=float('inf'))
model.fit(X, y)kernel这是核函数(如 'linear'(线性)、'rbf'(高斯核)、'poly'(多项式核)),选取适当的核函数,事半功倍。
C是惩罚系数,这个的大小决定了我们是否容忍软间隔。(值越大,对误分类的容忍度越低,可能过拟合)
TF-IDF
这个算法是用来提取文本特征的,重要词,和关键词的
算法简述
词a在文章出现的次数/这个文章的总词数 (TF)
log(文档总数/包含词a的文章数+1) (IDF)
大致意思就是,先看在本文中重要不重要,再看这个词普遍不普遍,如果很普遍那就不重要了。
重要参数
from sklearn.feature_extraction.text import TfidfVectorizer
model=TfidfVectorizer()
data=open('结果1.txt',encoding='utf-8')
jg=model.fit_transform(data)
print(jg)
wordlist=model.get_feature_names_out()
print(wordlist)
import pandas as pd
df=pd.DataFrame(jg.T.todense(),index=wordlist)
print(df)
# featurelist = df.iloc[:,5].tolist()
# print(featurelist)这个我们要知道model.fit_transform(data)的结果是一个字典,其中第一列(n,n)表示第n篇文章第n个单词,后面表示这个的重要指标。
model.get_feature_names_out()是一个列表。表示出现的所有词的name
pd.DataFrame(jg.T.todense(),index=wordlist)这个就转化为了一个表格,行为第几篇文章,列为name
词向量转化
把单词转化为可训练的数据
算法简述
把每句话转化为一个矩阵,首先先对每句话进行结巴分词,然后分出多少次就有多少个特征,根据这个特征是否在文章中出现作为那个位置的特征为0/1,然后0 1 1 1 1 1这样就是一句话的特征了。然后有了数据又有了标签的化就可以训练了,前面也说过贝叶斯比较适合文本训练
重要参数
from sklearn.feature_extraction.text import CountVectorizer
texts=["dog cat fish","dog cat cat","fish bird",'bird']
model=CountVectorizer(max_features=6,ngram_range=(1,3))
model.fit(texts)
print(model.get_feature_names_out())
print(model.transform(texts))
print(model.transform(texts).toarray())max_features=6表示要分出几个特征(取全文出现频率最多的几个)
ngram_range=(1,3)表示每个特征的词数控制在1-3个单词
lowercase=False表示要不要全转化为小写,如果是中文的话就要写成false
PCA降维
这个和随机森林降维差不多,选取重要特征
算法简述
这个通过把数据映射一下,到另一个坐标中,映射标准是映射的足够离散,然后把数据量少的那一个维度去除。
重要参数
pca = PCA(n_components=20)
pca.fit(X)
X_pca = pca.fit_transform(X)n_components=20 用于控制降低到多少维度
X_pca = pca.fit_transform(X)这个就可以把训练结果导出来了。
评价方式
回归
准确率,召回率
分类
MSE,RMSE,MAE,R方

聚类
轮廓系数,衡量聚类紧密度和分离度。值在-1,1之间,越接近1表示聚类效果越好。
选取建议

数据处理
数据不均衡
过采样
使用SMOTE来过采样,这个算法的原理也是距离方法,例如这个有两个点,然后过采样我就把这两个点连接,在这个线段内取出n个点作为过采样的点。
from imblearn.over_sampling import SMOTE#imblearn这个库里面调用,
oversampler =SMOTE(random_state=0)#保证数据拟合效果,随机种子
train_X, train_y = oversampler.fit_resample(train_X,train_y)#人工拟合数据下采样
pe=train_data[train_data['Class'] == 1]
ne=train_data[train_data['Class'] == 0]
d1 = ne.sample(len(pe))
train_data = pd.concat([d1,pe])就是把训练集两类特征分开,从多的那一个里面随机取样出少的那一个样本的个数
数据异常值和空值
异常值
把异常值转化为空值
for i in X.columns:
X[i]=pd.to_numeric(X[i],errors='coerce')空值
空值可以选取中位数,平均数,众数,或者用线性回归预测来填充。