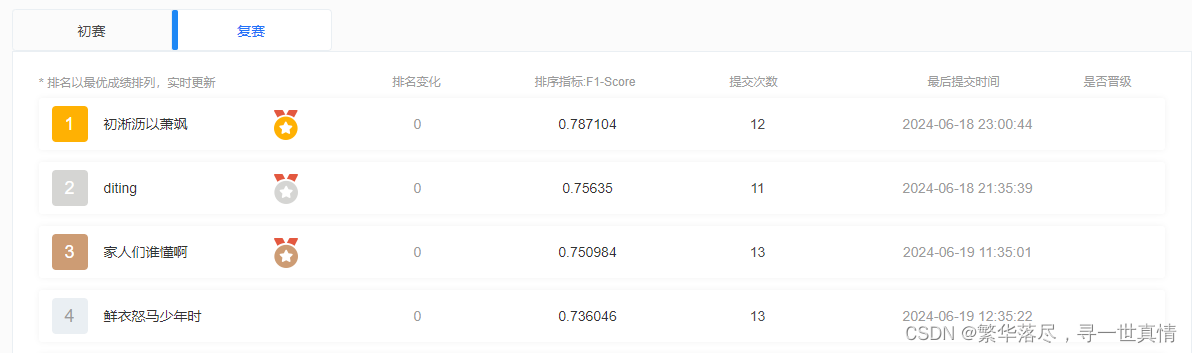
遗憾没有进复赛,只是第41名。先贴个A榜的成绩。A榜的前三十名晋级,个个都是99分的大佬,但是B榜的成绩就有点低了,应该是数据不同源的问题,第一名0.78分。官网链接:语音深度鉴伪识别

官方baselin:https://github.com/xinyebei/2024_finvcup_baseline
baseline源码:https://github.com/xieyuankun/Codecfake
实验的 源码:https://github.com/Shybert-AI/Codecfake_ResNet
任务描述:

简单的说一下本次比赛方案的想法,首先明确是语音深度鉴伪识别任务,于是发动互联网的强大的搜索功能,尽可能多的搜索到更多的语音深度鉴伪识别算法。也相应的搜索对应的数据集,在看到此帖子深度伪造音频普遍检测的Codecfake数据集和对策,同时在github上找到相应的源码,因此方案基于Codecfake进行。通过将网络结构修改成ResNet等实验,提出Codecfake_ResNet模型,让语音鉴别模型的分类指标达到0.968961。(https://blog.csdn.net/robinfang2019/article/details/138673202)
模型架构:
 训练步骤:
训练步骤:
python
1.下载finvcup9th_1st_ds5数据集,解压到data目录下
2.执行data_prepare.py 脚本生成训练的csv文件,修改finvcup9th_1st_ds5_valid_data.csv为finvcup9th_1st_ds5_dev_data.csv
python data_prepare.py
3.执行提取特征文件
python preprocess.py
4.训练
python main_train.py --path_to_features preprocess_xls-r-5 -f1 preprocess_xls-r-5 --out_fold ./pretrained_model/codec_w2v2aasist_ResNet50_CSAM_xls-r-5_300m/ --CSAM True --train_task codecfake --num_epochs 50 --batch_size 16 --lr 0.001 --gpu 0 --seed 2024 --num_workers 1
5.预测
python predict.py实验结果:
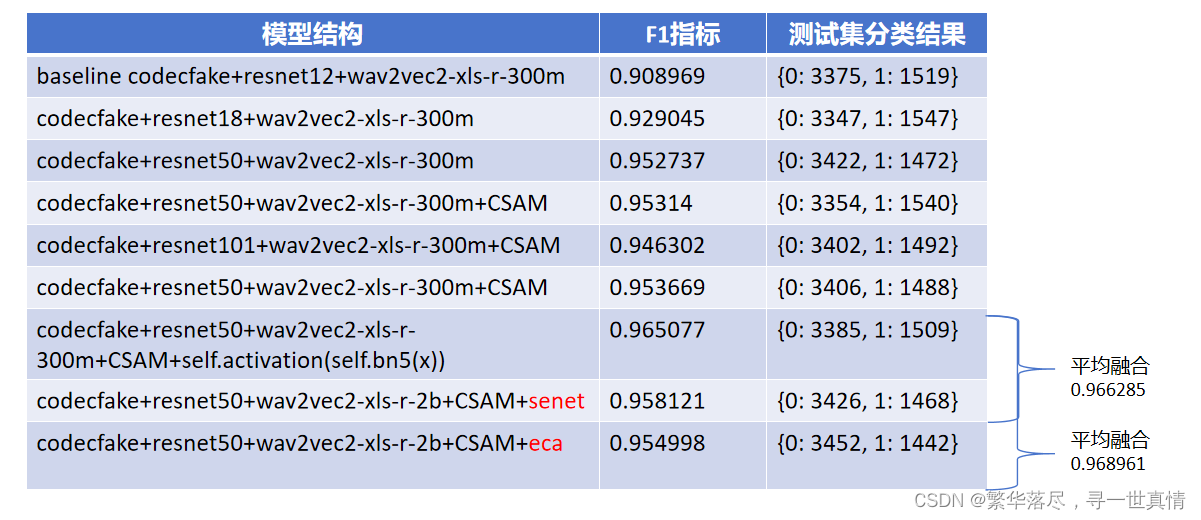
通过实验分析提升网络的层数和多模型融合可以提升。