一、目录
- llama1 模型与transformer decoder的区别
- llama2 模型架构
- llama2 相比llama1 不同之处
- llama3 相比llama2 不同之处
- llama、llama2、llama3 分词器词表大小以及优缺点
- 采用的损失函数是什么?
- 为什么Layer Norm 改为RMS Norm?
- 如何消除模型幻觉?
二、实现
-
llama1 模型与transformer decoder的区别
Transformer Decoder 架构,做了以下修改:
1.和GPT3-样将Normalization从每个子层的输出位置移动到了输入位置。
2.将Layer Norm 改为 RMS Norm。
3.采用旋转位置编码,
4.采用silu激活函数。(根据光滑,实验效果更好)
-
llama2 模型架构
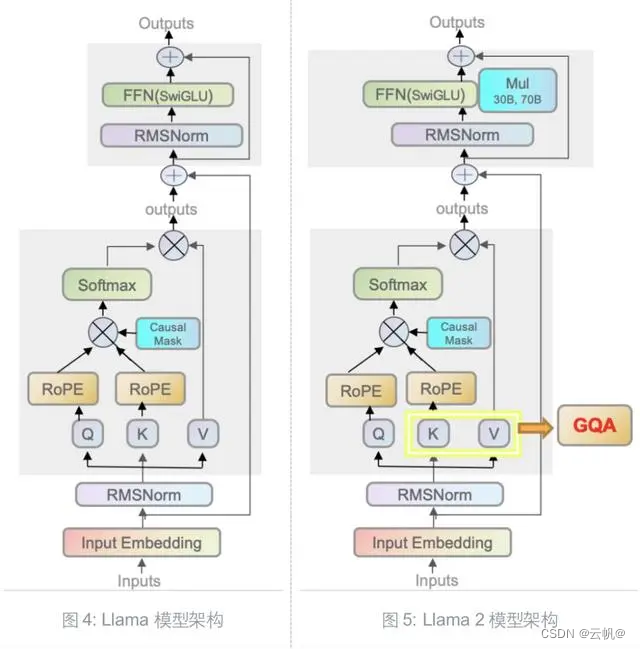
-
llama2 相比llama1 不同之处
数据方面
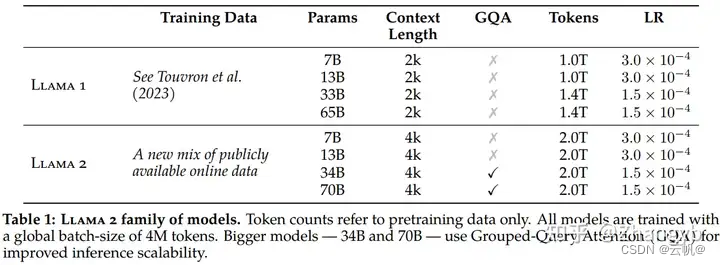
LLama2训练语料相比LLaMA多出40%,上下文长度是由之前的2048升级到4096,可以理解和生成更长的文本。
新增预预训练数据,并注重安全&隐私问题。
训练出了chat版本:llama-2-chat:SFT, RLHF。
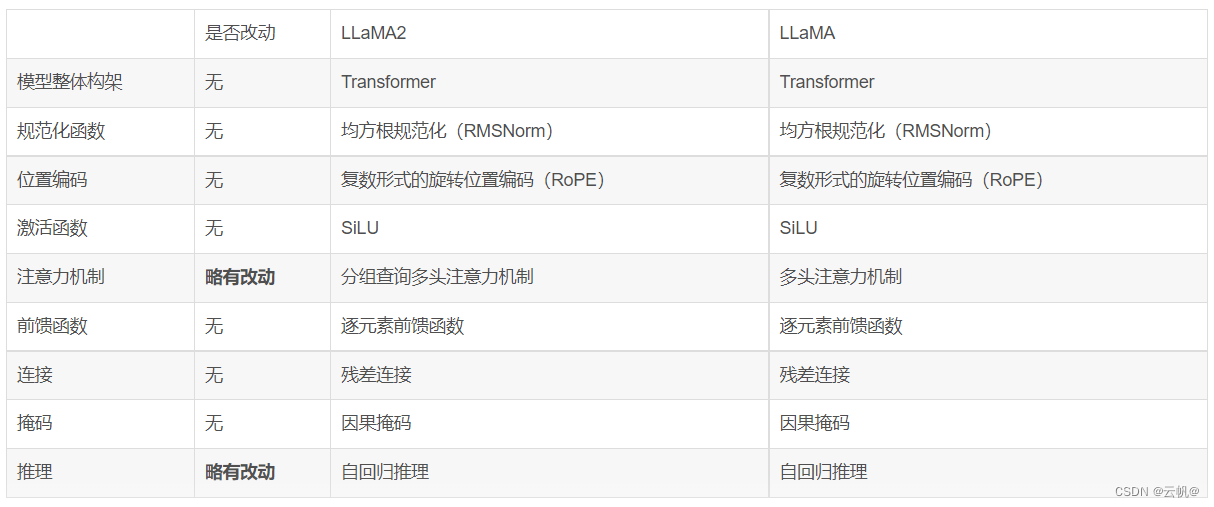
模型结构方面
模型结构基本和llama一样,transformer decoder结构,RMSNorm 应用预归一化、使用 SwiGLU 激活函数和旋转位置嵌入RoPE。
上下文长度是由之前的2048升级到4096,可以理解和生成更长的文本。
7B和13B 使用与 LLaMA 相同的架构,34B和70B模型采用分组查询注意力(GQA)。
For speed up decoding! 自回归解码的标准做法(past key-value 机制)是缓存序列中先前标记的k,v矩阵,从而加快注意力计算速度。但上下文长度、批量大小、模型大小较大时,多头注意力
(MHA) 中的kv缓存无疑巨大。
所以采用分组查询注意力机制(GQA)可以提高大模型的推理可扩展性。它的工作原理是将键和值投影在多个头之间共享,而不会大幅降低性能。可以使用具有单个KV投影的原始多查询格式
(MQA)或具有8KV投影的分组查询注意力变体(GQA)。
训练方式:
【优化器:AdamW;学习率计划:cosine learning rate schedule。使用 0.1 的权重衰减和1.0的梯度裁剪。】
0、Llama2使用与Llama1相同的分词器;它采用BPE算法,使用 SentencePiece 实现。与Llama 1 一样,将所有数字拆分为单独的数字,并使用字节来分解未知的 UTF-8 字符。词汇量为 32k token
1、使用公开的在线数据进行预训练。
2、SFT:然后通过使用有监督微调创建 Llama-2-chat 的初始版本。
3、RLHF:接下来,llama-2-chat 使用人类反馈强化学习 (RLHF) 进行迭代细化,其中包括拒绝采样和近端策略优化 (PPO)。
-
llama3 相比llama2 不同之处
vocab_size:32000 ->128256
LLaMA 3具有128K词汇量大小的Tokenizer,可以更有效的对文本进行编码,从而显着提高模型性能。
max_position_embeddings:4096->8192
在8,192 个Token的较长序列上训练模型,使用掩码机制确保自注意力不会跨越文档边界。需要注意的是LLaMA 3采用了8K Token进行训练,并不代表只能生成8K Token以内文本。
num_key_value_heads:32 -> 8
使用了GQA,因为num_attention_heads维持32,也就是计算时key、value要复制 4份。参数量会下降,K_proj、V_proj的参数矩阵会降为llama2-7B的1/4。
intermediate_size:11008->14336
只是FFN(MLP)时的中间维度变了,计算范式不变。
训练数据:
15T的训练Token,全部来自公开数据。是Lama2的7倍大小。代码数据多了4倍5%高质量非英语数据,涵盖30多种语言。
对数据进行了清洗过滤,lama2生成训练数据来帮助训练文本质量分类器。
微调阶段除了开源数据集,还人工标注了1000万样本。
-
llama、llama2、llama3 分词器词表大小以及优缺点
llama 2使用与 llama 1 相同的分词器; 它采用字节对编码(BPE)算法,使用 SentencePiece 实现。 与llama 1 一样,将所有数字拆分为单独的数字,并使用字节来分解未知的 UTF-8 字符,总数词汇量为 32k 个token。
基于word粒度会导致词表(vocab)过大,进而致使训练冗余,主要是因为每个单词的衍生词过多,比如look,looking,looks等等;最重要的是会导致OOV问题(out of vocabulary)即未出现在词表当中的词将无法处理。
另外,对于低频词/稀疏词,无法在训练当中得到充分的学习,模型无法充分理解这些词的语义。
而基于char会导致词表过小,无法充分理解语义信息。字符粒度分词无法直接表达词的语义,可能导致在一些语义分析任务中效果较差;由于文本被拆分为字符,处理的粒度较小,增加后续处理的计算成本和时间。
在很多情况下,既不希望将文本切分成单独的词(太大),也不想将其切分成单个字符(太小),而是希望得到介于词和字符之间的子词单元。这就引入了 subword(子词)粒度的分词方法。
-
采用的损失函数是什么?
自回归语言模型,LLaMA 通过接收一系列单词作为输入并预测下一个单词来递归生成文本。
-
为什么Layer Norm 改为RMS Norm?
RMS Norm 是Layer Norm 的改进,依据 数据分布平移不变性,对layer Norm 去除平移参数。
-
如何消除模型幻觉?
首先,为什么会产生幻觉?这主要原因是用于训练语言模型的大数据语料库在收集时难免会包含一些错误的信息,这些错误知识都会被学习,存储在模型参数中,相关研究表明模型生成文本时会优先考虑自身参数化的知识,所以更倾向生成幻觉内容。
数据阶段: 使用置信度更高的数据,消除原始数据中本来的错误和不一致地方。
训练阶段:有监督学习算法非常容易使得求知型查询产生幻觉。在模型并不包含或者知道答案的情况下,有监督训练仍然会促使模型给出答案。而使用强化学习方法,则可以通过定制奖励函数,将正确答案赋予非常高的分数,将放弃回答的答案赋予中低分数,将不正确的答案赋予非常高的负分,使得模型学会依赖内部知识选择放弃回答,从而在一定程度上缓解模型的幻觉问题。
基于后处理:在生成输出后,对其进行迭代评估和调整。对于摘要等任务,只有在生成整个摘要后才能准确评估,因此后期修正方法更为有效。缺点是不改变模型本身。
基于知识检索增强的方式:模型幻觉很大程度来源之一是外部知识选择不正确,因此用更强的检索模型搜索知识,返回更加有用的知识,也是消除对话回复幻觉的有效途径。