**
1.持久化方式
**
Redis虽然是内存数据库,一旦服务器进程退出,数据库的数据就会丢失。为了解决这个问题,Redis提供三种持久化的方式。
(1)RDB持久化

关键配置信息:
Redis每个时段的读写请求肯定是不均衡的。
60秒、300秒,900秒
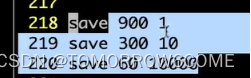
表示:当备份进程出错时,主进程就停止接受新的写入。
保护持久化数据的一致性。
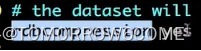
Rdb文件压缩相关。Yes表示备份时需要将Rdb文件进行压缩后才去做保存。
建议设置成no.Redis本身是cpu密集型服务器。开启压缩会带来更多cpu消耗
自动化触发RDB持久化的方式:

可以通过java计时器或者course定期掉写redis的bgsave指令去备份rdb文件。并按照时间戳存储rdb文件,作为redis某段时间的全量备份脚本。
BgSave的原理:
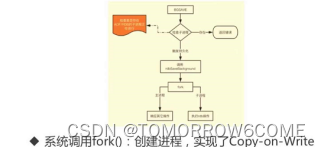
调用的是redis源码中的rdbSaveBackground()方法
Linux系统下,fork系统调用实现COPY-ON-WRITE写时复制。传统情况下,fork在创建子进程时,直接将所有资源复制给子进程。实现方式简单,效率低下。复制资源可能会毫无用处。
Linux为了降低创建子进程的成本,改进fork实现方式,当父进程创建子进程时,内核只为子进程创建虚拟空间,父子两个进程使用的是相同的物理空间。只有父子进程发生更改时,才会为子进程分配独立的地址空间。这种方式就是COPY-ON-WRITE
缺点:

(2)AOF持久化
AOF持久化:保存写状态
记录下除了查询以外的所有变更数据库状态的指令
以append的形式追加保存到AOF文件中(增量)
配置信息:
appendonly no (默认的情况是关闭的) 修改成:appendonly yes
appendfilename "appendonly.aof"
appendfsync everysec
日志重写原理:
例如:递增一个计数器100次。
AOF会将100次递增的命令完成的记录下来。事实上要恢复这个记录只需要一个命令就可。就是AOF里面的100条命令可以精简为一条。所以Redis支持这样一个功能,在不中断服务的情况下,在后台重建AOF文件,原理如下:

RDB和AOF的优缺点

(3)混合模式
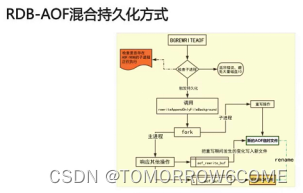
区别:全量数据是以Redis命令方式写入。
先以RDB格式写入全量数据,再追加增量数据。
子进程在AOF重写时,会通过管道从父进程去读取增量数据。
再以RDB格式保存全量数据时,也会从管道读取数据。同时不会造成管道的堵塞。
总结一下:AOF的前半段是RDB格式的全量数据,而后半段是Redis命令的增量数据。

**
2.主从同步
**

先同步全量数据快照,在做增量同步。(M,S分别都是独立的RedisServer实例)
M用来写操作,S用来进行读操作。都代表一个个独立的RedisServer实例。定期的数据备份操作也是选择一个S去完成的,这样可以最大程度发挥Redis的性能。为的是让其支持数据的弱一致性,既最终一致性。我们不需要实时保证M跟S之间的数据是同步的,但是在过了一段时间之后它们的数据是趋于同步的。
第一次同步时,主节点进行一次bgsave,并同时将后续的修改操作记录到内存的buffer里面去。待全部完成后,将RDB文件全量同步到从节点里面。从节点接受完成后,将RDB的镜像加载到内存中。加载完成后,再通知主节点将期间修改的操作(增量数据)同步到从节点进行重放。
Redis同步机制:


Redis Sentinel:Redis哨兵 。
Redis官方提供的集群管理工具。独立运行的进程,能够监控多个Master-Slave集群。发现Master宕机之后能进行自动切换。

3.补充
(1)redis过期策略
Redis中过期Key的删除是惰性删除和定期删除两种方式配合使用的.
惰性删除
当客户端发送命令请求时,服务端会先通过expireIfNeeded()方法,进行判断key是否过期,如果key过期就进行删除,然后在进行后续命令操作.
定期删除
每隔一段时间,程序就对数据库进行一次检查,删除里面的部分过期Key.

(2)缓存雪崩,缓存击穿,缓存穿透
缓存雪崩:
缓存中大量 key 同时过期或者Redis 实例挂掉了,无法处理请求导致大量请求发送到了数据库,数据库压力激增,甚至可能导致数据库崩溃,从而导致整个系统崩溃,引发雪崩一样的连锁效应。
预防方式:
对于大量 key 同时过期的场景。可以修改 key 过期的时间,使用随机过期策略。
应对方式:
可采用服务熔断或者请求限流。
缓存击穿:
缓存击穿是指,针对某个热点数据,突然在缓存中失效,然后这些请求到热点数据的请求会都请求到数据库。
应对方式:
可以使用互斥锁避免大量请求同时落到db。
布隆过滤器,判断某个容器是否在集合中
可以将缓存设置永不过期(有限制)
做好熔断、降级,防止系统崩溃。
缓存穿透:
通常是一个不存在的key,在数据库查询为null。每次请求 Redis 发现没有对应的 key之后,再去请求数据库,发现数据库也没有,每次请求落在数据库、并且高并发,数据库扛不住会挂掉。
应对方式:
将该key的值设置为NULL。
用布隆过滤器先过滤