spark独立集群搭建(不依赖Hadoop)
1、上传spark-2.4.5-bin-hadoop2.7.tgz至 /usr/local/moudel ,再解压到 /usr/local/soft
tar -zxvf spark-2.4.5-bin-hadoop2.7.tgz -C /usr/local/soft/
重命名
mv spark-2.4.5-bin-hadoop2.7/ spark-2.4.5
配置环境变量
vim /etc/profile
添加
export SPARK_HOME=/usr/local/soft/spark-2.4.5
在path后面添加 :$SPARK_HOME/bin
2、进入 spark-2.4.5/conf 目录 ,修改配置文件
修改主节点配置文件
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
直接在文件最下方添加
export SPARK_MASTER_IP=master
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_CORES=2
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=2g
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171
修改从节点配置文件
cp slaves.template slaves
vim slaves
删除localhost 添加
node1
node2
3、复制到其它节点
cd /usr/local/soft
scp -r spark-2.4.5/ node1:`pwd`
scp -r spark-2.4.5/ node2:`pwd`
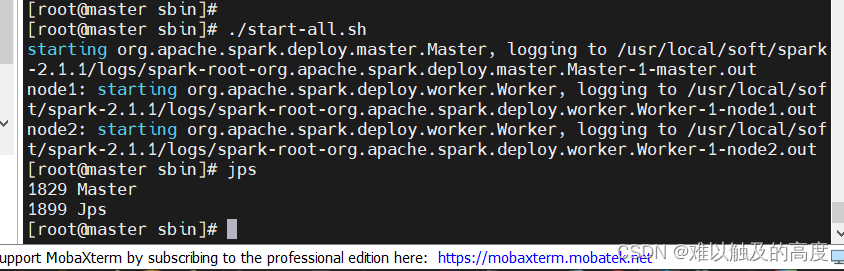
4、在master节点 spark的sbin目录下启动spark
cd /usr/local/soft/spark-2.4.5/sbin
./start-all.sh
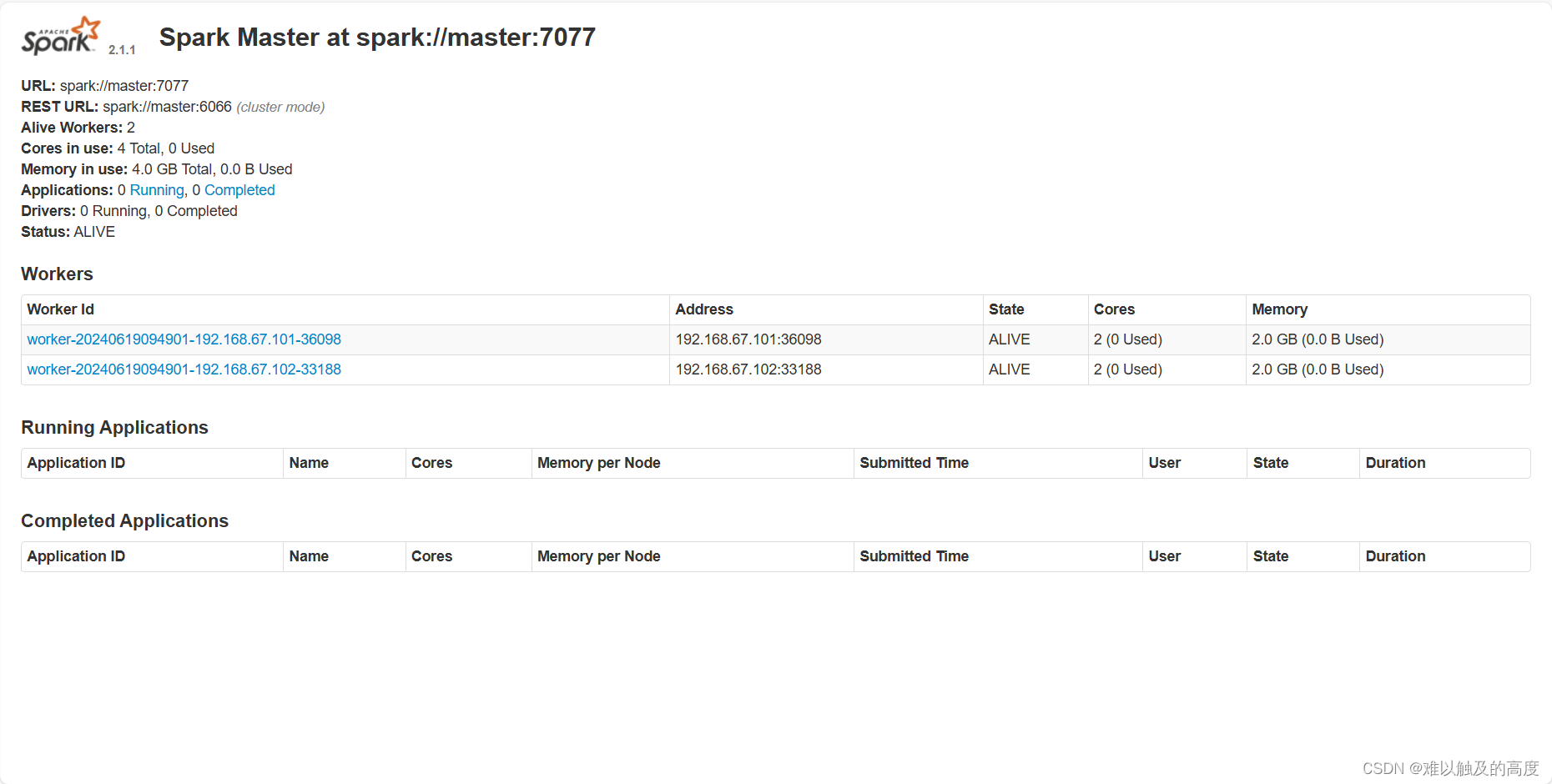
http://master:8080/ 访问spark UI ---- spark独立集群安装完成
5、测试
spark有两种模式 :
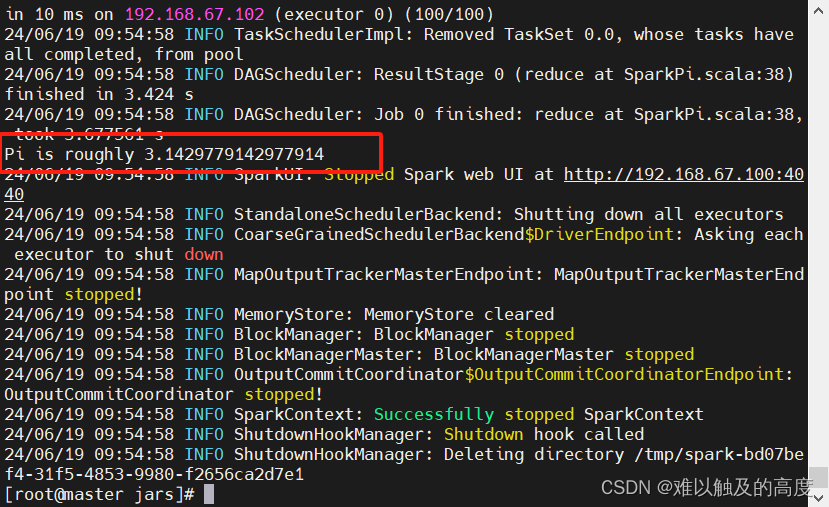
(1) standalone client模式 日志在本地输出,一般用于上线前测试(bin/下执行)
cd /usr/local/soft/spark-2.4.5/examples/jars
提交spark任务
spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 --executor-memory 512m --total-executor-cores 1 spark-examples_2.11-2.4.5.jar 100
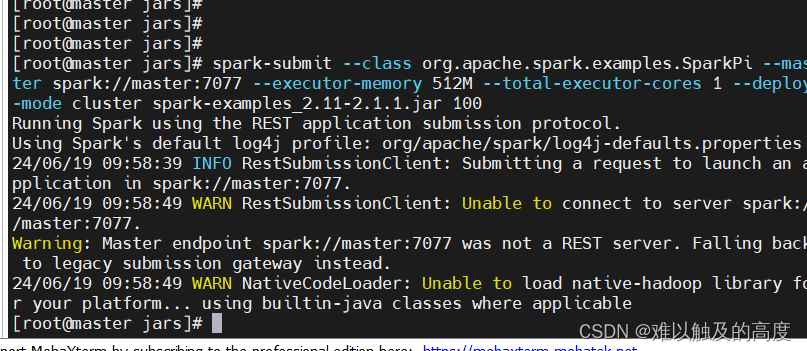
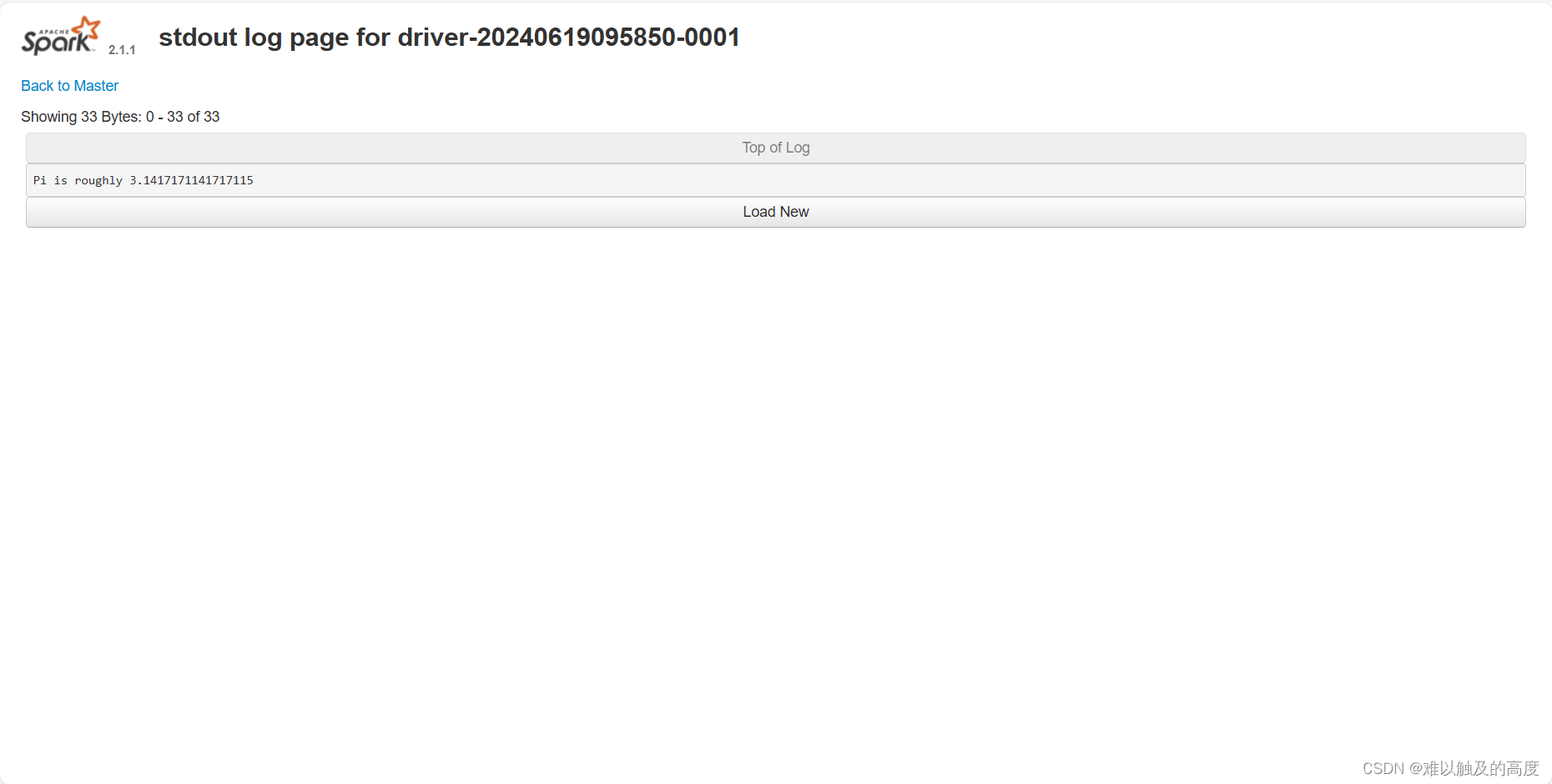
(2) standalone cluster模式 上线使用,不会再本地打印日志 需要到网页查看结果
cd /usr/local/soft/spark-2.4.5/examples/jars
提交spark任务
spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 --executor-memory 512M --total-executor-cores 1 --deploy-mode cluster spark-examples_2.11-2.4.5.jar 100
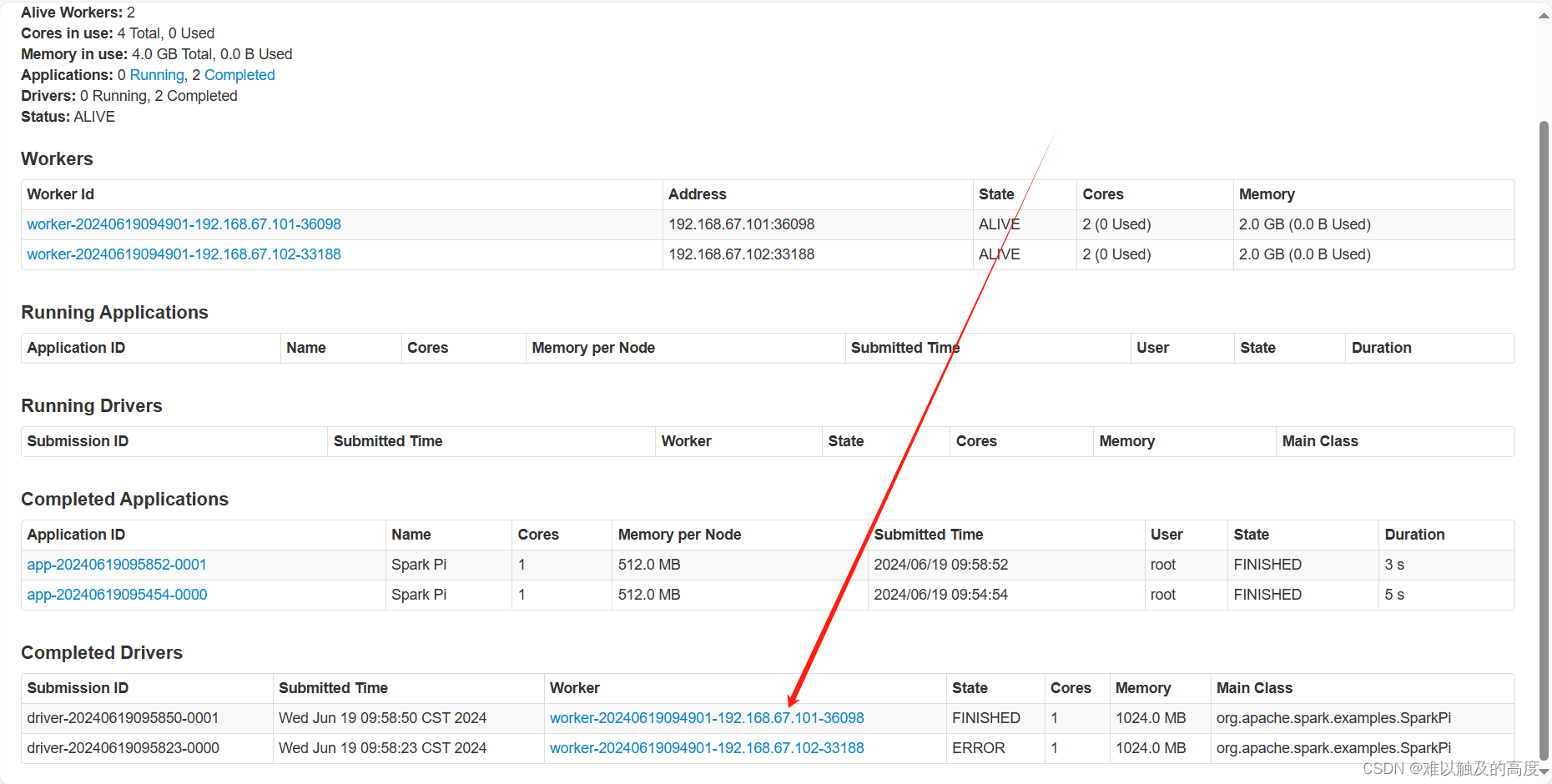
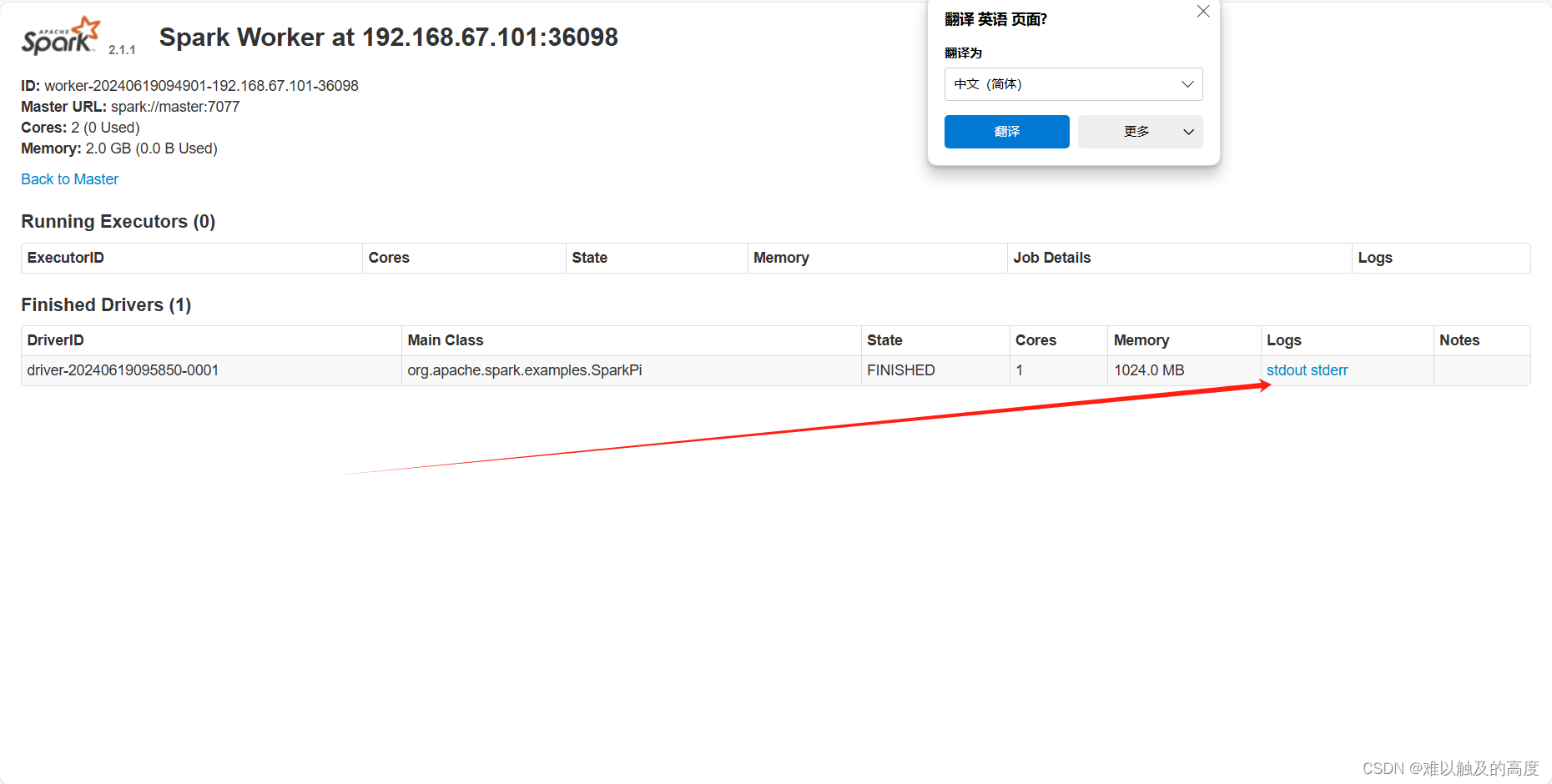
------------ 以后都不会使用的 -----------------
===================== 若集群已有yarn , 就不需要再搭建Spark独立集群了 ==================================================================
以后都会使用 整合 yarn