本文为个人学习笔记整理,仅供交流参考,非专业教学资料,内容请自行甄别。
文章目录
一、服务端三大日志
在Kafka服务端的server.properties中,可以指定日志存放的位置,通常也是需要开发者手动进行配置的:
进入配置的目录,可以观察到有哪些日志文件和文件夹:
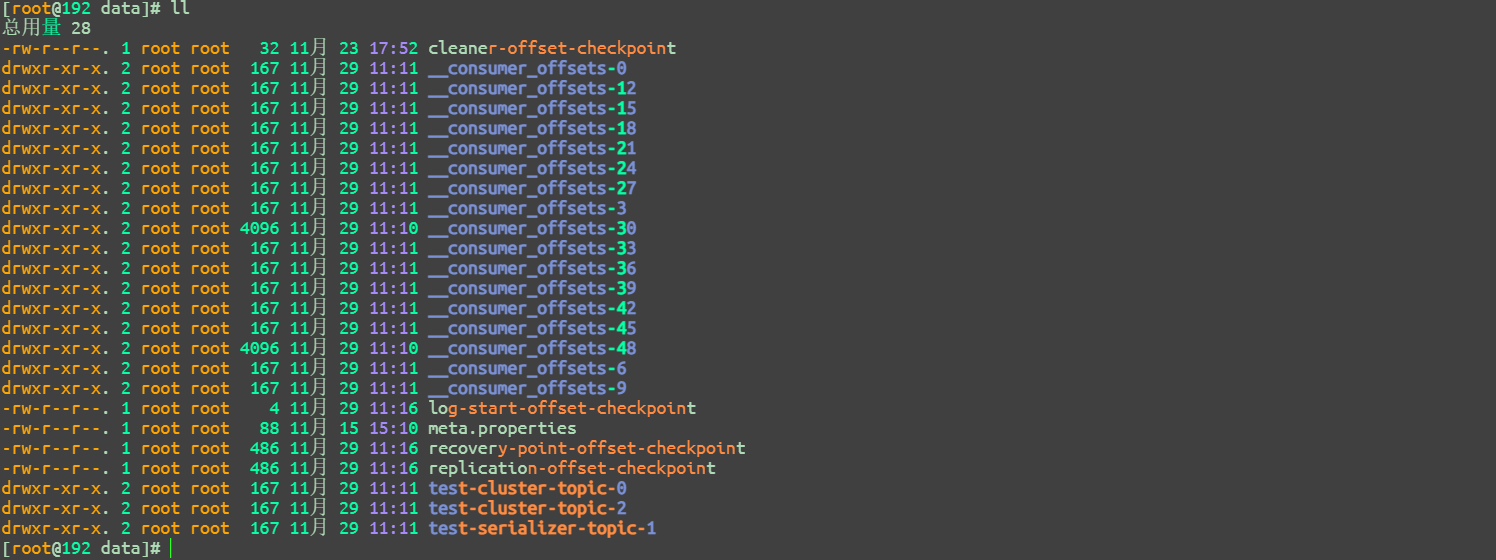
其中最下方的三个test-cluster-topic-0,test-cluster-topic-2,test-serializer-topic-1文件夹,其中保存了每一个topic-partition下的日志文件;
- xxx.index:时间戳和该时间戳下对应的偏移量(某个时间点,消息写到了哪个位置)
- xxx.log:存储具体的消息(二进制数组)
- xxx.timeindex:偏移量和消息长度(作为log中消息的边界)
- leader-epoch-checkpoint:用于实现上篇提到的HW机制
- partition.metadata:存储该partition的元信息

后两个是可以直接查看的:


前三个作为重点,但是是二进制文件,无法直接查看,需要借助kafka提供的脚本进行观察。
而在data的根目录下,还有__consumer_offsets-0这些文件,存储的是客户端每个消费者组,自己的offset。服务端日志文件中存的offset,是最大的offset。
1.1、.index文件
可以在bin目录下执行:
bash
./kafka-dump-log.sh --files /配置的日志路径/topic-partition文件夹/00000000000000000000.index 文件的内容类似于如下,记录的是偏移量,以及消息的长度。并非是连续记录偏移量,而是类似于一种跳表的结构。
bash
offset: 61 position: 4216
offset: 119 position: 8331
offset: 175 position: 124961.2、.timeindex文件
可以在bin目录下执行:
bash
./kafka-dump-log.sh --files /配置的日志路径/topic-partition文件夹/00000000000000000000.timeindex 文件的内容类似如下,记录的是某一时刻的偏移量。同样并非是连续记录偏移量,而是类似于一种跳表的结构。
bash
timestamp: 1661753911323 offset: 61
timestamp: 1661753976084 offset: 119
timestamp: 1661753977822 offset: 1751.3、.log文件
可以在bin目录下执行:
bash
./kafka-dump-log.sh --files /配置的日志路径/topic-partition文件夹/00000000000000000000.log文件的内容类似如下,记录的是具体的消息,但是具体的消息都是序列化成二进制存储,所以展示二进制是没有意义的,能看到的只是消息的一些信息:
bash
baseOffset: 0 lastOffset: 1 count: 2 baseSequence: 0 lastSequence: 1 producerId: 7000 producerEpoch: 0 partitionLeaderEpoch: 11 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 0 CreateTime: 1661753909195 size: 99 magic: 2 compresscodec: none crc: 342616415 isvalid: true
baseOffset: 2 lastOffset: 2 count: 1 baseSequence: 2 lastSequence: 2 producerId: 7000 producerEpoch: 0 partitionLeaderEpoch: 11 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 99 CreateTime: 1661753909429 size: 80 magic: 2 compresscodec: none crc: 3141223692 isvalid: true
baseOffset: 3 lastOffset: 3 count: 1 baseSequence: 3 lastSequence: 3 producerId: 7000 producerEpoch: 0 partitionLeaderEpoch: 11 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 179 CreateTime: 1661753909524 size: 80 magic: 2 compresscodec: none crc: 1537372733 isvalid: true 从上面可以看出,kafka消息的检索维度是时间或索引。为什么要在index中还要记录消息的长度?因为消息在.log日志中以二进制的形式存储,并没有消息边界。记录长度的目的是为了按照偏移量查询反序列化时,确定具体的消息。并且.log日志有大小限制,在服务端进行配置,指定单个文件的大小,超过大小则文件分片。
二、日志清理机制
通常在生产环境,微服务的应用日志,不会永久保存,而是会用脚本定时清理。Kafka的日志也是同样的道理。检测文件到期,以及文件保留多久,都是可以通过服务端的配置进行设置的:
- log.retention.check.interval.ms:控制定时任务扫描过期日志的频率,
默认是5分钟。 - log.retention.hours,log.retention.minutes, log.retention.ms:表示日志存储时间的时分秒,
默认是7天。
过期文件的处理策略,同样是在服务端的配置文件中进行设置的:
- log.cleanup.policy:日志清理的策略,
delete删除或compact压缩 - log.retention.bytes:如果日志清理的策略是
delete,还可以通过本参数进行控制,删除到达本参数阈值的文件,默认会删除最早的。
三、文件的高效读写机制
kafka的文件的高效读取,可以由以下的机制实现:
- 三大日志的存储结构,按照topic-partition的维度进行划分,缩小粒度,并且文件内部使用类似于跳表的形式,增加检索效率,减少检索的次数
- 消息顺序写磁盘,新的内容只能追加在文件的最后,不能在中间插入,效率高于随机写,避免寻址问题。
- 利用了零拷贝的机制,关于零拷贝,在NIO零拷贝中有记录
kafka刷盘的操作通过操作系统的fsync命令, 但是时机不可能是每写入一个字节,就调用一次。(区别于Rocket MQ的同步刷盘) 在kafka中,可以通过服务端的配置控制刷盘频率,以及写入消息的大小,触发刷盘等操作。不能按照条数刷盘
四、经典问题
kafka常见的问题,消息如何保证不丢失,消息积压的处理,顺序处理消息,是在面试中经常会被问到的。
4.1、如何保证消息不丢失
通过上一篇的分析,能得出的结论是无法保证kafka的消息绝对的零丢失。因为无法控制的点在于partition的leader和follower发生切换时的消息同步。,只能尽量保证消息不丢失。可以从生产者端,消费者端,服务器端三个角度进行控制:
- 生产者端:开启消息ack机制,幂等性,事务消息,防止从生产者端->服务器传输过程中网络问题造成的消息丢失。
- 服务器端:可以控制将消息持久化到硬盘上的刷盘频率。至于重新选举造成的丢失,无法解决。
- 消费者端:不要异步处理消息,必须保证业务消息处理完成后再commit。如果要异步,就通过第三方的中间件,例如redis,自主控制offset。避免因为处理消息的过程中,因为业务逻辑造成消息处理失败,但是offest依旧向前推进。
4.2、消息积压的处理
kafka的设计,本来就是基于高吞吐量的场景,所以通常并不需要考虑消息积压的问题。如果出现消息积压的问题:
- 消费者消费速度过慢:增加服务端的topic中的partition分区数,然后增加消费者的数量,每个消费者组的消费者数量最多和partition一样。(如果消费者数超过分区数,多余的消费者会没有分区可分配),但是分区数量不是越多越好。
- 消费者处理消息过程中出现问题:启动一个Consumer将Topic下的消息先转发到其他队列中,然后对消息进行人工处理。
4.3、保证消息的顺序性
如何保证消息的顺序性,依旧是通过消费者和生产者两方面进行考虑:
- 生产者:发到服务器的消息本身是有顺序的,因为kafka的本质是一个队列,队列的结构就是先进先出。但是如果是轮询发到不同的partition,是不能保证的,也就是消息要发到同一个partition,但是这样做,等于摒弃了多partition带来的吞吐量,可以通过在生产者端,定制分区路由实现。
- 消费者:kafka在消费者端并没有对于消息的顺序性进行设计。因为poll操作本来就是多线程并发拉取的,可以进行配置,但是配置的不是同一批次拉取消息的个数,而是大小(无法配置一次拉取一条消息)。所以严格来说不能保证消息顺序。
- consumer对象是线程不安全的,不能作为属性让多线程共享,要定义在方法中。