第五章 深度学习
十三、自然语言处理(NLP)
5. NLP应用
5.2 文本情感分析
目标:利用训练数据集,对模型训练,从而实现对中文评论语句情感分析。情绪分为正面、负面两种
数据集:中文关于酒店的评论,5265笔用户评论数据,其中2822笔正面评价、其余为负面评价
步骤:同上一案例
模型选择:

代码:
【数据预处理】
python
# 中文情绪分析:数据预处理部分
import paddle
import paddle.dataset.imdb as imdb
import paddle.fluid as fluid
import numpy as np
import os
import random
from multiprocessing import cpu_count
# 数据预处理,将中文文字解析出来,并进行编码转换为数字,每一行文字存入数组
mydict = {} # 存放出现的字及编码,格式: 好,1
code = 1
data_file = "data/hotel_discuss2.csv" # 原始样本路径
dict_file = "data/hotel_dict.txt" # 字典文件路径
encoding_file = "data/hotel_encoding.txt" # 编码后的样本文件路径
puncts = " \n" # 要剔除的标点符号列表
with open(data_file, "r", encoding="utf-8-sig") as f:
for line in f.readlines():
# print(line)
trim_line = line.strip()
for ch in trim_line:
if ch in puncts: # 符号不参与编码
continue
if ch in mydict: # 已经在编码字典中
continue
elif len(ch) <= 0:
continue
else: # 当前文字没在字典中
mydict[ch] = code
code += 1
code += 1
mydict["<unk>"] = code # 未知字符
# 循环结束后,将字典存入字典文件
with open(dict_file, "w", encoding="utf-8-sig") as f:
f.write(str(mydict))
print("数据字典保存完成!")
# 将字典文件中的数据加载到mydict字典中
def load_dict():
with open(dict_file, "r", encoding="utf-8-sig") as f:
lines = f.readlines()
new_dict = eval(lines[0])
return new_dict
# 对评论数据进行编码
new_dict = load_dict() # 调用函数加载
with open(data_file, "r", encoding="utf-8-sig") as f:
with open(encoding_file, "w", encoding="utf-8-sig") as fw:
for line in f.readlines():
label = line[0] # 标签
remark = line[1:-1] # 评论
for ch in remark:
if ch in puncts: # 符号不参与编码
continue
else:
fw.write(str(mydict[ch]))
fw.write(",")
fw.write("\t" + str(label) + "\n") # 写入tab分隔符、标签、换行符
print("数据预处理完成")【模型定义与训练】
python
# 获取字典的长度
def get_dict_len(dict_path):
with open(dict_path, 'r', encoding='utf-8-sig') as f:
lines = f.readlines()
new_dict = eval(lines[0])
return len(new_dict.keys())
# 创建数据读取器train_reader和test_reader
# 返回评论列表和标签
def data_mapper(sample):
dt, lbl = sample
val = [int(word) for word in dt.split(",") if word.isdigit()]
return val, int(lbl)
# 随机从训练数据集文件中取出一行数据
def train_reader(train_list_path):
def reader():
with open(train_list_path, "r", encoding='utf-8-sig') as f:
lines = f.readlines()
np.random.shuffle(lines) # 打乱数据
for line in lines:
data, label = line.split("\t")
yield data, label
# 返回xmap_readers, 能够使用多线程方式读取数据
return paddle.reader.xmap_readers(data_mapper, # 映射函数
reader, # 读取数据内容
cpu_count(), # 线程数量
1024) # 读取数据队列大小
# 定义LSTM网络
def lstm_net(ipt, input_dim):
ipt = fluid.layers.reshape(ipt, [-1, 1],
inplace=True) # 是否替换,True则表示输入和返回是同一个对象
# 词嵌入层
emb = fluid.layers.embedding(input=ipt, size=[input_dim, 128], is_sparse=True)
# 第一个全连接层
fc1 = fluid.layers.fc(input=emb, size=128)
# 第一分支:LSTM分支
lstm1, _ = fluid.layers.dynamic_lstm(input=fc1, size=128)
lstm2 = fluid.layers.sequence_pool(input=lstm1, pool_type="max")
# 第二分支
conv = fluid.layers.sequence_pool(input=fc1, pool_type="max")
# 输出层:全连接
out = fluid.layers.fc([conv, lstm2], size=2, act="softmax")
return out
# 定义输入数据,lod_level不为0指定输入数据为序列数据
dict_len = get_dict_len(dict_file) # 获取数据字典长度
rmk = fluid.layers.data(name="rmk", shape=[1], dtype="int64", lod_level=1)
label = fluid.layers.data(name="label", shape=[1], dtype="int64")
# 定义长短期记忆网络
model = lstm_net(rmk, dict_len)
# 定义损失函数,情绪判断实际是一个分类任务,使用交叉熵作为损失函数
cost = fluid.layers.cross_entropy(input=model, label=label)
avg_cost = fluid.layers.mean(cost) # 求损失值平均数
# layers.accuracy接口,用来评估预测准确率
acc = fluid.layers.accuracy(input=model, label=label)
# 定义优化方法
# Adagrad(自适应学习率,前期放大梯度调节,后期缩小梯度调节)
optimizer = fluid.optimizer.AdagradOptimizer(learning_rate=0.001)
opt = optimizer.minimize(avg_cost)
# 定义网络
# place = fluid.CPUPlace()
place = fluid.CUDAPlace(0)
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program()) # 参数初始化
# 定义reader
reader = train_reader(encoding_file)
batch_train_reader = paddle.batch(reader, batch_size=128)
# 定义输入数据的维度,数据的顺序是一条句子数据对应一个标签
feeder = fluid.DataFeeder(place=place, feed_list=[rmk, label])
for pass_id in range(40):
for batch_id, data in enumerate(batch_train_reader()):
train_cost, train_acc = exe.run(program=fluid.default_main_program(),
feed=feeder.feed(data),
fetch_list=[avg_cost, acc])
if batch_id % 20 == 0:
print("pass_id: %d, batch_id: %d, cost: %0.5f, acc:%.5f" %
(pass_id, batch_id, train_cost[0], train_acc))
print("模型训练完成......")
# 保存模型
model_save_dir = "model/chn_emotion_analyses.model"
if not os.path.exists(model_save_dir):
print("create model path")
os.makedirs(model_save_dir)
fluid.io.save_inference_model(model_save_dir, # 保存路径
feeded_var_names=[rmk.name],
target_vars=[model],
executor=exe) # Executor
print("模型保存完成, 保存路径: ", model_save_dir)【推理预测】
python
import paddle
import paddle.fluid as fluid
import numpy as np
import os
import random
from multiprocessing import cpu_count
data_file = "data/hotel_discuss2.csv"
dict_file = "data/hotel_dict.txt"
encoding_file = "data/hotel_encoding.txt"
model_save_dir = "model/chn_emotion_analyses.model"
def load_dict():
with open(dict_file, "r", encoding="utf-8-sig") as f:
lines = f.readlines()
new_dict = eval(lines[0])
return new_dict
# 根据字典对字符串进行编码
def encode_by_dict(remark, dict_encoded):
remark = remark.strip()
if len(remark) <= 0:
return []
ret = []
for ch in remark:
if ch in dict_encoded:
ret.append(dict_encoded[ch])
else:
ret.append(dict_encoded["<unk>"])
return ret
# 编码,预测
lods = []
new_dict = load_dict()
lods.append(encode_by_dict("总体来说房间非常干净,卫浴设施也相当不错,交通也比较便利", new_dict))
lods.append(encode_by_dict("酒店交通方便,环境也不错,正好是我们办事地点的旁边,感觉性价比还可以", new_dict))
lods.append(encode_by_dict("设施还可以,服务人员态度也好,交通还算便利", new_dict))
lods.append(encode_by_dict("酒店服务态度极差,设施很差", new_dict))
lods.append(encode_by_dict("我住过的最不好的酒店,以后决不住了", new_dict))
lods.append(encode_by_dict("说实在的我很失望,我想这家酒店以后无论如何我都不会再去了", new_dict))
# 获取每句话的单词数量
base_shape = [[len(c) for c in lods]]
# 生成预测数据
place = fluid.CPUPlace()
infer_exe = fluid.Executor(place)
infer_exe.run(fluid.default_startup_program())
tensor_words = fluid.create_lod_tensor(lods, base_shape, place)
infer_program, feed_target_names, fetch_targets = fluid.io.load_inference_model(dirname=model_save_dir, executor=infer_exe)
# tvar = np.array(fetch_targets, dtype="int64")
results = infer_exe.run(program=infer_program,
feed={feed_target_names[0]: tensor_words},
fetch_list=fetch_targets)
# 打印每句话的正负面预测概率
for i, r in enumerate(results[0]):
print("负面: %0.5f, 正面: %0.5f" % (r[0], r[1]))6. 附录
6.1 附录一:相关数学知识
向量余弦相似度
余弦相似度使用来度量向量相似度的指标,当两个向量夹角越大相似度越低;当两个向量夹角越小,相似度越高。
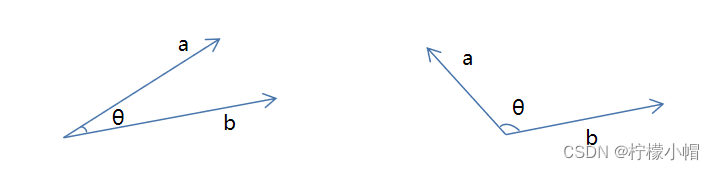
在三角形中,余弦值计算方式为 c o s θ = a 2 + b 2 − c 2 2 a b cos \theta = \frac{a^2 + b^2 - c^2}{2ab} cosθ=2aba2+b2−c2,向量夹角余弦计算公式为:
c o s θ = a b ∣ ∣ a ∣ ∣ × ∣ ∣ b ∣ ∣ cos \theta = \frac{ab}{||a|| \times ||b||} cosθ=∣∣a∣∣×∣∣b∣∣ab
分子为两个向量的内积,分母是两个向量模长的乘积。
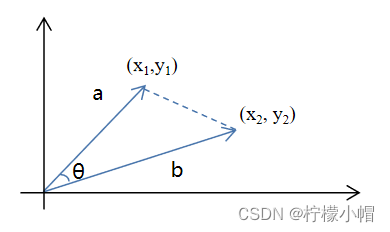
其推导过程如下:
c o s θ = a 2 + b 2 − c 2 2 a b = x 1 2 + y 1 2 + x 2 2 + y 2 2 + ( x 1 − x 2 ) 2 + ( y 1 − y 2 ) 2 2 x 1 2 + y 1 2 x 2 2 + y 2 2 = 2 x 1 x 2 + 2 y 1 y 2 2 x 1 2 + y 1 2 x 2 2 + y 2 2 = a b ∣ ∣ a ∣ ∣ × ∣ ∣ b ∣ ∣ cos \theta = \frac{a^2 + b^2 - c^2}{2ab} \\ = \frac{\sqrt{x_1^2 + y_1^2} + \sqrt{x_2^2 + y_2^2 }+ \sqrt{(x_1 - x_2)^2 + (y_1 - y_2)^2}}{2 \sqrt{x_1^2 + y_1^2} \sqrt{x_2^2 + y_2^2}} \\ = \frac{2 x_1 x_2 + 2 y_1 y_2}{2 \sqrt{x_1^2 + y_1^2} \sqrt{x_2^2 + y_2^2}} = \frac{ab}{||a|| \times ||b||} cosθ=2aba2+b2−c2=2x12+y12 x22+y22 x12+y12 +x22+y22 +(x1−x2)2+(y1−y2)2 =2x12+y12 x22+y22 2x1x2+2y1y2=∣∣a∣∣×∣∣b∣∣ab
以上是二维向量的计算过程,推广到N维向量,分子部分依然是向量的内积,分母部分依然是两个向量模长的乘积。由此可计算文本的余弦相似度。
6.2 附录二:参考文献
1)《Python自然语言处理实践------核心技术与算法》 ,涂铭、刘祥、刘树春 著 ,机械工业出版社
2)《Tensorflow自然语言处理》,【澳】图珊·加内格达拉,机械工业出版社
3)《深度学习之美》,张玉宏,中国工信出版集团 / 电子工业出版社
4)网络部分资源
6.3 附录三:专业词汇列表
| 英文简写 | 英文全写 | 中文 |
|---|---|---|
| NLP | Nature Language Processing | 自然语言处理 |
| NER | Named Entities Recognition | 命名实体识别 |
| PoS | part-of-speech tagging | 词性标记 |
| MT | Machine Translation | 机器翻译 |
| TF-IDF | Term Frequency-Inverse Document Frequency | 词频-逆文档频率 |
| Text Rank | 文本排名算法 | |
| One-hot | 独热编码 | |
| BOW | Bag-of-Words Model | 词袋模型 |
| N-Gram | N元模型 | |
| word embedding | 词嵌入 | |
| NNLM | Neural Network Language Model | 神经网络语言模型 |
| HMM | Hidden Markov Model | 隐马尔可夫模型 |
| RNN | Recurrent Neural Networks | 循环神经网络 |
| Skip-gram | 跳字模型 | |
| CBOW | Continous Bag of Words | 连续词袋模型 |
| LSTM | Long Short Term Memory | 长短期记忆模型 |
| GRU | Gated Recurrent Unit | 门控环单元 |
| BRNN | Bi-recurrent neural network | 双向循环神经网络 |
| FMM | Forward Maximum Matching | 正向最大匹配 |
| RMM | Reverse Maximum Matching | 逆向最大匹配 |
| Bi-MM | Bi-directional Maximum Matching | 双向最大匹配法 |