Mysql 窗口函数
1,窗口函数
1.1,什么是窗口函数
MySQL窗口函数是一种强大的工具,用于在查询中执行复杂的统计分析,而不需要改变表的结构或数据。MySQL从8.0版本开始支持窗口函数,这些函数也被称为分析函数,因为它们能够处理相对复杂的报表统计分析场景。
窗口的意思是将数据进行分组,每个分组即是一个窗口,这和使用聚合函数时的group by分组类似,但与聚合函数不同的地方是: 聚合函数(例如:sum/avg/min/max)会针对每个分组(窗口)聚合出一个结果(每一组返回一个结果)。 窗口函数会对每一条数据进行计算,并不会使返回的数据变少(每一行返回一个结果)
1.2,基本语法
sql
-- 匿名窗口
SELECT
<窗口函数> over (partition by <分组列名> order by <排序列名>)
FROM `表名`
-- 显式窗口
SELECT
<窗口函数> OVER w
FROM `表名`
WINDOW w AS (partition by <分组列名> order by <排序列名>)<窗口函数>的位置,可以放以下两种函数:
- 聚合函数:如SUM、AVG、COUNT、MAX、MIN等,可以在不合并行的情况下计算每行的聚合值。
- 专用窗口函数:
- 排序函数:包括RANK、DENSE_RANK、ROW_NUMBER等,用于为数据集中的每行分配一个唯一的排名或编号。
- 偏移函数:包括LAG和LEAD等,用于获取当前行之前的或之后的指定偏移量的值
- 值函数:FIRST_VALUE和LAST_VALUE返回窗口分区中第一行或最后一行的值,而NTH_VALUE则返回窗口内偏移指定offset后的值。
因为窗口函数是对where或者group by子句处理后的结果进行操作,所以窗口函数一般出现在select子句或者order by子句中。
where, group by, having都不可引用该列,因为这些语句执行在select之前,此时函数尚未计算出值。
2,函数详解
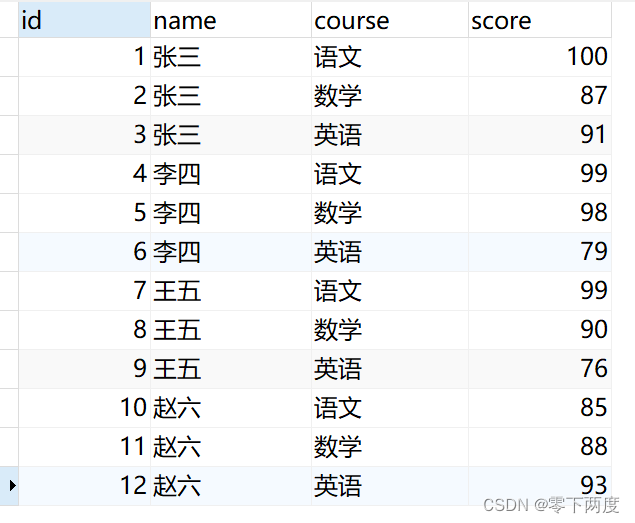
原始数据如下,表名:class
2.1,聚合函数
窗口操作不会将多组查询行折叠成单个输出行。相反,它们为每一行产生一个结果:
sql
SELECT
*,
-- 总计
SUM(score) OVER () AS sum1,
-- 按course分组求和
SUM(score) OVER (PARTITION BY course) AS sum2,
-- 按course分组累计求和
SUM(score) OVER (PARTITION BY course ORDER BY score DESC) AS sum3
FROM `class` 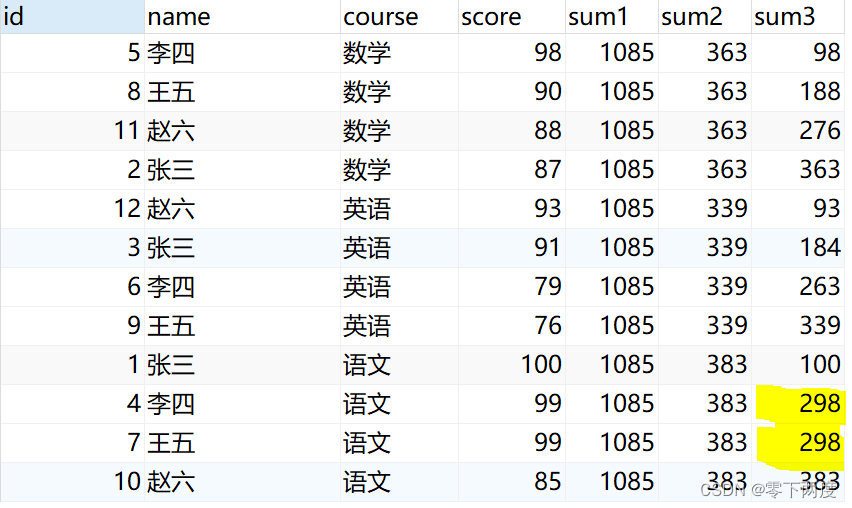
sql
SELECT
*,
SUM(score) OVER w AS sum,
AVG(score) OVER w AS avg,
MIN(score) OVER w AS min,
MAX(score) OVER w AS max,
COUNT(score) OVER w AS count
FROM `class`
WINDOW w AS (PARTITION BY course ORDER BY score DESC)
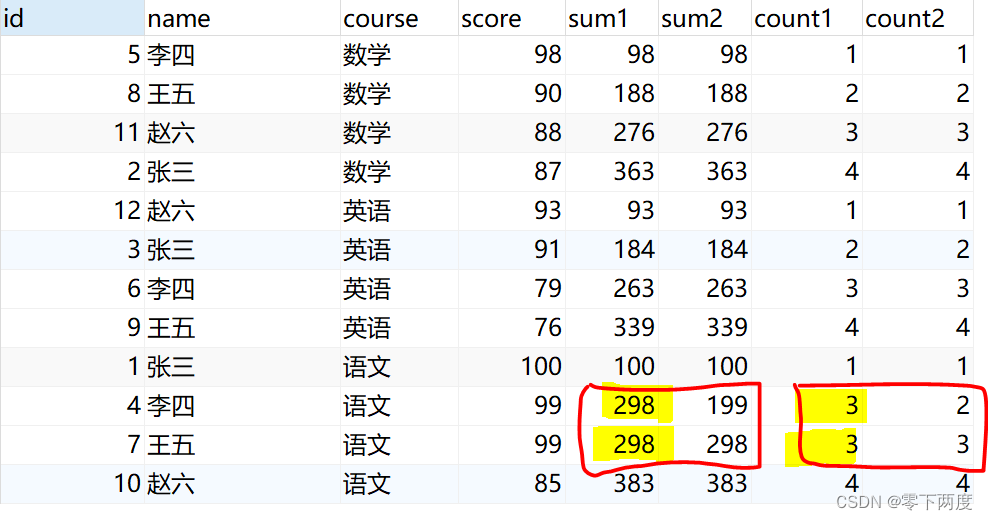
注意分数相同时,分组累计(标黄处)的处理逻辑(见:《3,进阶用法》)
2.2,排序函数
sql
SELECT
*,
ROW_NUMBER() OVER w AS 'row_number',
RANK() OVER w AS 'rank',
DENSE_RANK() OVER w AS 'dense_rank'
FROM `class`
WINDOW w AS (PARTITION BY course ORDER BY score DESC)
三者的区别如下:
row_number() 排序相同时不会重复,会根据顺序排序,即:1、2、3、4;
rank() 排序相同时会重复,序号有空隙,即1、2、2、4这样的排序结果;
dense_rank() 排序相同时会重复,序号无空隙,即1、2、2、3这样的排序结果;
求每门课程的前两名:
sql
SELECT * FROM (
SELECT
*,
RANK() OVER (PARTITION BY course ORDER BY score DESC) AS `rank`
FROM `class` ) f
WHERE `rank` <= 2
// 窗口函数得到的列别名不能用于where, group by, having等子句,
// 因为这些语句执行在select之前,此时函数尚未计算出值。
// 以下写法是错误的:
SELECT
*,
RANK() OVER (PARTITION BY course ORDER BY score DESC) AS `rank`
FROM `class`
WHERE `rank` <= 2
如果每门课程只需要前两条数据,可把RANK() 函数换成 ROW_NUMBER()
2.3,偏移函数
语法:LEAD(字段, 偏移量, 填充值)
偏移量默认为1,填充值默认为NULL
sql
SELECT
*,
-- 获取前面一行的score
LAG(score) OVER W AS `lag`,
-- 获取后面第二行score,且无数据填充0
LEAD(score, 2, 0) OVER W AS `lead`
FROM `class`
WINDOW w AS (PARTITION BY course ORDER BY score DESC)
2.4,值函数
sql
SELECT
*,
-- 获取第一行的score
FIRST_VALUE(score) OVER w AS `first`,
-- 截止到当前行,获取最后一行score
LAST_VALUE(score) OVER w AS `last`,
-- 截止到当前行,获取最后2行score
NTH_VALUE(score, 2) OVER w AS `second`,
-- 截止到当前行,获取最后3行score
NTH_VALUE(score, 3) OVER w AS `third`
FROM `class`
WINDOW w AS (PARTITION BY course ORDER BY score DESC)
注意了:从结果看,我们对FIRST_VALUE()很清晰,就是获取的第一个值,但是LAST_VALUE()和NTH_VALUE获取的值跟我们想象中的不太一样呢? 没错,LAST_VALUE()和NTH_VALUE是获取的截止到当前为止的值,而不是整个组的最后一个值后指定的值(见:《3,进阶用法》)。
3,进阶用法
sql
<窗口函数> over (
partition by <用于分组的列名>
order by <用于排序的列名>
rows/range 窗口子句
)rows/range:窗口子句,主要用来限制分组(也称窗口)的行数和数据范围。
窗口子句必须和order by 子句同时使用,如果指定了order by 子句未指定窗口子句,则默认为RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW,即从当前分组起点到当前行。
行比较分析函数lead和lag无窗口子句。
窗口子句常用语法:
- CURRENT ROW:当前行
- UNBOUNDED:无界限(起点或终点)
- PRECEDING:往前
- FOLLOWING:往后
如上文《2.4,值函数》,如果想获取整个窗口的LAST_VALUE()和NTH_VALUE:
sql
SELECT
*,
-- 获取第一行的score
FIRST_VALUE(score) OVER w AS `first`,
-- 获取最后一行score
LAST_VALUE(score) OVER w AS `last`,
-- 获取最后2行score
NTH_VALUE(score, 2) OVER w AS `second`,
-- 获取最后3行score
NTH_VALUE(score, 3) OVER w AS `third`
FROM `class`
WINDOW w AS (
PARTITION BY course
ORDER BY score DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
)
rows 和range区别:
- rows是物理窗口,即根据order by 子句排序后,取的前N行及后N行的数据计算(与当前行的值无关,只与排序后的行号相关)。
- range是逻辑窗口,即根据order by 子句排序后,取的前N行及和当前行有相同order by值的所有行数据计算。
例如在《2.1,聚合函数》飘黄部分,因为默认窗口字句是RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW,所以改成把"RANGE"改成"ROWS"就是逐条统计:
sql
SELECT
*,
-- 默认RANGE
SUM(score) OVER w AS sum1,
-- 指定ROWS
SUM(score) OVER (w ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS sum2,
-- 默认RANGE
COUNT(score) OVER w AS count1,
-- 指定ROWS
COUNT(score) OVER (w ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS count2
FROM `class`
WINDOW w AS (PARTITION BY course ORDER BY score DESC)