1.Java String与byte\[\]互相转换存在的问题
java中,按照byte\[\] =》string =》byte\[\]的流程转换后,byte数据与最初的byte不一致。
多说无益,上代码,本地macos机器执行,统一使用的UTF-8编码。
java
import java.nio.charset.StandardCharsets;
import java.util.Arrays;
public class StringConversionExample {
public static void main(String[] args) {
byte[] original2 = new byte[]{(byte)0xef, (byte)0x8f, (byte)0xff};
byte[] transformed2 = new String(original2).getBytes();
System.out.println(Arrays.toString(original2));
System.out.println(Arrays.toString(transformed2));
System.out.println(Arrays.equals(original2, transformed2));
}
}执行结果
java
[-17, -113, -1]
[-17, -65, -67, -17, -65, -67]
false发现问题了没有?byte转成string后,再转回byte,竟然最初的数据不一致,代码开发中,肯定是与预期不一致,容易写出bug。
2.首先熟悉相关字符、字符集、字符编码与字符概念
了解了大概的问题,我们带着疑问,先了解一下相关的概念。
计算机里的unicode编码和UTF-8的关系-CSDN博客
字符编码和字符集到底有什么区别?Unicode和UTF-8是什么关系?-CSDN博客
主要理解一下下面几个概念的区别:
- 字符:就是我们看到的一个字母或一个汉字、一个标点符号都叫字符。如汉字"一"就是一个字符。
- 字符码:在指定的字符集中,一个字符对应唯一一个数字,这个数字就叫字符码。如上边的字符"一",在 Unicode 字符集中,对应的字符码为
\u4e00。 - 字符集:规定了字符和字符码之间的对应关系。
- 字符编码:规定了一个字符码在计算机中如何存储,比如UTF-8。
3.java中byte\[\]与string互转出现问题的表面原因是什么,我们控制变量做了一个对比实验
首先看下如下代码:
java
byte[] original1 = new byte[]{(byte)0xef, (byte)0x8f, (byte)0x8f};
byte[] transformed1 = new String(original1).getBytes();
System.out.println(Arrays.toString(original1));
System.out.println(Arrays.toString(transformed1));
System.out.println(Arrays.equals(original1, transformed1));它的执行结果是:
java
[-17, -113, -113]
[-17, -113, -113]
true这两个字节数组内容是完全相等的,第一个byte array在经过到String的转换,再到bytes的转换后,内容保持不变。
再看如下代码:
java
byte[] original2 = new byte[]{(byte)0xef, (byte)0x8f, (byte)0xff};
byte[] transformed2 = new String(original2).getBytes();
System.out.println(Arrays.toString(original2));
System.out.println(Arrays.toString(transformed2));
System.out.println(Arrays.equals(original2, transformed2));它的执行结果是:
java
[-17, -113, -1]
[-17, -65, -67, -17, -65, -67]
false这一次,两个byte array的结果不一样了,且结果差异很大。
这两段代码的唯一区别是,original1的最后一个字节值是0x8f, 而original2的最后一个字节值为0xff。
所以,0xff是导致byte\[\]与string互转出现问题的表面原因。
4.0xff为什么会导致出现问题?
(1)了解java byte与string的转换原理
上面的示例代码的执行环境中,系统默认的字符集是UTF-8,所以字节到字符的转换,会按 UTF-8编码来进行转换。
(2)UTF-8可变长度字符编码
UTF-8(Unicode Transformation Format-8)是一种变长编码方案(多位元组序列),用于将Unicode字符集中的字符编码为字节序列,以便在计算机系统中存储和传输。
UTF-8的定义和使用如下:
-
字符编码范围:UTF-8可以表示Unicode字符集中的所有字符,包括各种语言的字符、符号、标点符号等。
-
变长编码:UTF-8使用变长编码方式 ,根据字符的不同范围使用不同长度的字节表示字符。具体规则如下:
-
对于ASCII字符(Unicode码范围为U+0000至U+007F),使用一个字节表示,其最高位为0。
-
对于非ASCII字符 ,使用多个字节表示。UTF-8的编码规则如下:
-
对于2字节字符,使用两个字节表示,其最高位为110。
-
对于3字节字符,使用三个字节表示,其最高位为1110。
-
对于4字节字符,使用四个字节表示,其最高位为11110。
-
对于更高范围的字符,UTF-8可以使用最多6个字节进行表示。
-
兼容性:UTF-8编码方案保持了与ASCII字符集的兼容性。ASCII字符在UTF-8中仍然使用一个字节表示,因此任何以ASCII编码的文本都是有效的UTF-8文本。
-
字节顺序:UTF-8不涉及字节顺序问题,因为它是一种字节序列的编码方式,而不是多字节字符的编码方式。因此,字节顺序对UTF-8没有影响。
在使用UTF-8时,常见的操作包括将字符串从编码为UTF-8字节序列,以及将UTF-8字节序列解码为字符串。编程语言通常提供了相应的API和函数来进行这些操作,例如Java中的`getBytes()`方法和`new String()`构造函数,以及Go语言中的`\[\]byte`类型和`string()`类型转换。
总结:UTF-8是一种用于将Unicode字符编码为字节序列的编码方案,它具有变长编码、兼容性和广泛支持的特点。使用UTF-8可以在计算机系统中存储和传输各种语言的文本数据,并且保持与ASCII字符集的兼容性。
(3)UTF-8可变长度字符编码的官方说法
这里引用一下更为官方的解释:https://zh.wikipedia.org/wiki/UTF-8#UTF-8%E7%9A%84%E7%B7%A8%E7%A2%BC%E6%96%B9%E5%BC%8F
设计UTF-8的理由
UTF-8的设计有以下的多字符组序列的特质:
- 单字节字符的最高有效比特永远为0。
- 多字节序列中的首个字符组的几个最高有效比特决定了序列的长度。最高有效位为
110的是2字节序列,而1110的是三字节序列,如此类推。- 多字节序列中其余的字节中的首两个最高有效比特为
10。UTF-8的这些特质,保证了一个字符的字节序列不会包含在另一个字符的字节序列中。这确保了以字节为基础的部分字符串比对(sub-string match)方法可以适用于在文字中搜索字或词。有些比较旧的可变长度8位编码(如Shift JIS)没有这个特质,故字符串比对的算法变得相当复杂。虽然这增加了UTF-8编码的字符串的信息冗余,但是利多于弊。另外,资料压缩并非Unicode的目的,所以不可混为一谈。即使在发送过程中有部分字节因错误或干扰而完全丢失,还是有可能在下一个字符的起点重新同步,令受损范围受到限制。
另一方面,由于其字节序列设计,如果一个疑似为字符串的序列被验证为UTF-8编码,那么我们可以有把握地说它是UTF-8字符串。一段两字节随机序列碰巧为合法的UTF-8而非ASCII的几率为32分1。对于三字节序列的几率为256分1,对更长的序列的几率就更低了。
UTF-8的编码方式
UTF-8是UNICODE的一种变长度的编码表达方式《一般UNICODE为双字节(指UCS2)》,它由肯·汤普逊(Ken Thompson)于1992年建立,现在已经标准化为RFC 3629。UTF-8就是以8位为单元对UCS进行编码,而UTF-8不使用大尾序和小尾序的形式,每个使用UTF-8存储的字符,除了第一个字节外,其余字节的头两个比特都是以"10"开始,使文字处理器能够较快地找出每个字符的开始位置。
但为了与以前的ASCII码兼容(ASCII为一个字节),因此UTF-8选择了使用可变长度字节来存储Unicode:
(注意:不论是Unicode (Table 3.7) 12,还是ISO 10646 (10.2 UTF-8) 13,目前都只规定了最高码位是0x10FFFF的字符的编码。下表中表示大于0x10FFFF的UTF-8编码是不符合标准的。)
| 码点的位数 | 码点起值 | 码点终值 | 字节序列 | Byte 1 | Byte 2 | Byte 3 | Byte 4 | Byte 5 | Byte 6 |
| 7 | U+0000 | U+007F | 1 |0xxxxxxx|
| 11 | U+0080 | U+07FF | 2 |110xxxxx|10xxxxxx|
| 16 | U+0800 | U+FFFF | 3 |1110xxxx|10xxxxxx|10xxxxxx|
| 21 | U+10000 | U+1FFFFF | 4 |11110xxx|10xxxxxx|10xxxxxx|10xxxxxx|
| 26 | U+200000 | U+3FFFFFF | 5 |111110xx|10xxxxxx|10xxxxxx|10xxxxxx|10xxxxxx|
31 U+4000000 U+7FFFFFFF 6 1111110x10xxxxxx10xxxxxx10xxxxxx10xxxxxx10xxxxxx[##### Unicode 和 UTF-8 之间的转换关系表 ( x字符表示码点占据的位 )]
- 在ASCII码的范围,用一个字节表示,超出ASCII码的范围就用字节表示,这就形成了我们上面看到的UTF-8的表示方法,这样的好处是当UNICODE文件中只有ASCII码时,存储的文件都为一个字节,所以就是普通的ASCII文件无异,读取的时候也是如此,所以能与以前的ASCII文件兼容。
- 大于ASCII码的,就会由上面的第一字节的前几位表示该unicode字符的长度,比如110xxxxx前三位的二进制表示告诉我们这是个2BYTE的UNICODE字符;1110xxxx是个三位的UNICODE字符,依此类推;xxx的位置由字符编码数的二进制表示的位填入。越靠右的x具有越少的特殊意义。只用最短的那个足够表达一个字符编码数的多字节串。注意在多字节串中,第一个字节的开头"1"的数目就是整个串中字节的数目。
从这里可以得出,需要看byte是否符合UTF-8标准编码:需要先把16进制byte转为二进制,然后参考是否与UTF-8设计规范一致,参阅Unicode 和 UTF-8 之间的转换关系表 ( x 字符表示码点占据的位 )。
(4)示例中的(byte)0xef, (byte)0x8f, (byte)0xff为什么不是UTF-8标准编码?
(4.1)先补充一个知识点,十六进制转二进制
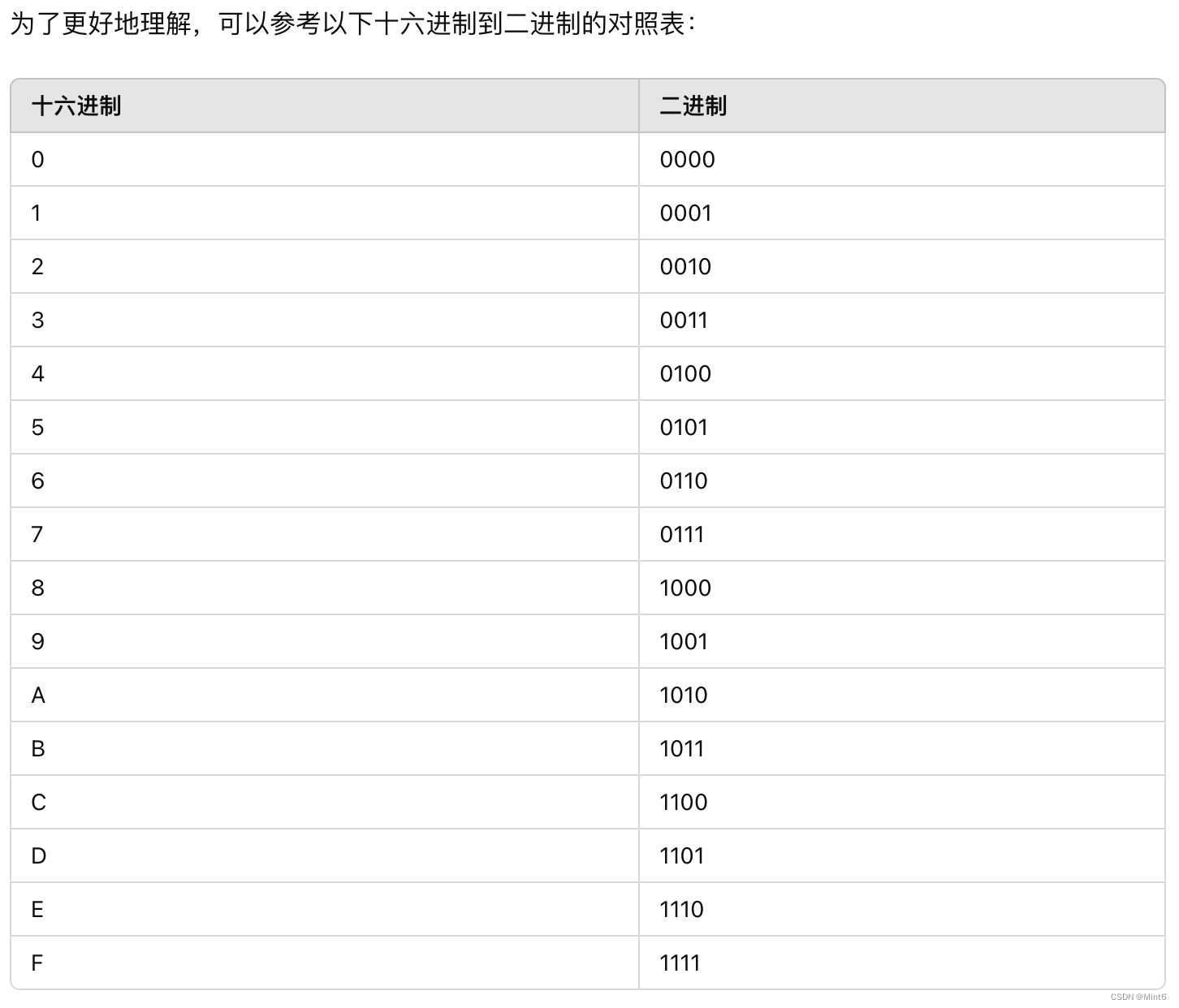
计算方式一:
将十六进制数 `0xef` 转换为其对应的二进制表示形式可以按照以下步骤进行:
-
将十六进制数 `0xef` 拆分为两个十六进制位:`0xe` 和 `0xf`。
-
将每个十六进制位转换为对应的四位二进制数。
-
`0xe` 转换为二进制为 `1110`。
-
`0xf` 转换为二进制为 `1111`。
- 将两个四位二进制数连接起来,得到八位二进制数。
- `11101111`
因此,十六进制数 `0xef` 转换为二进制为 `11101111`。
计算方式二:
如果你觉得方式一太复杂,可以先拆分为e、f,然后使用网站快速转换:在线进制转换

计算方式三:
查表,先转为10进制,然后手动计算二进制。
(4.1.1)如下图,0xEF的十进制为239
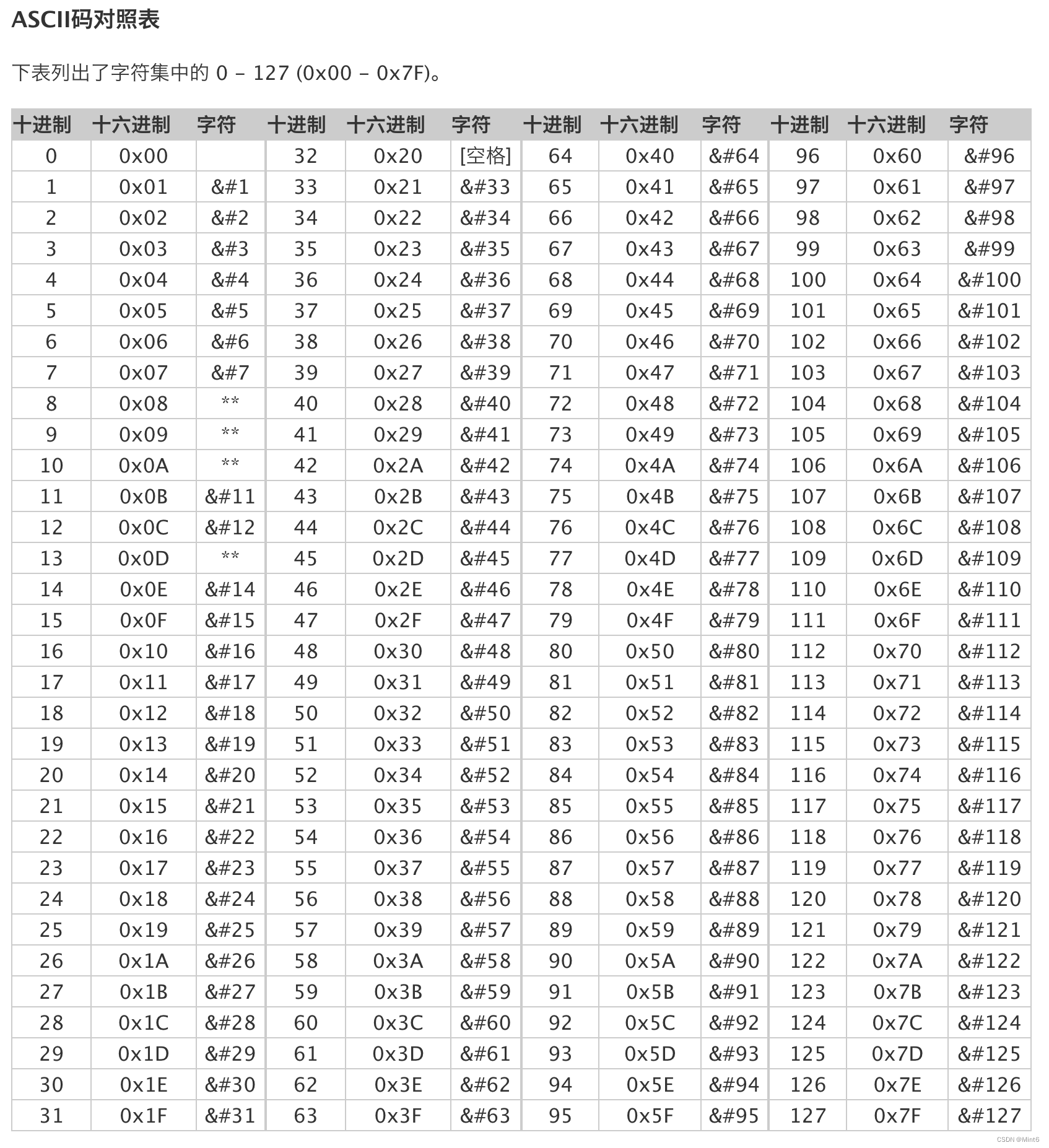
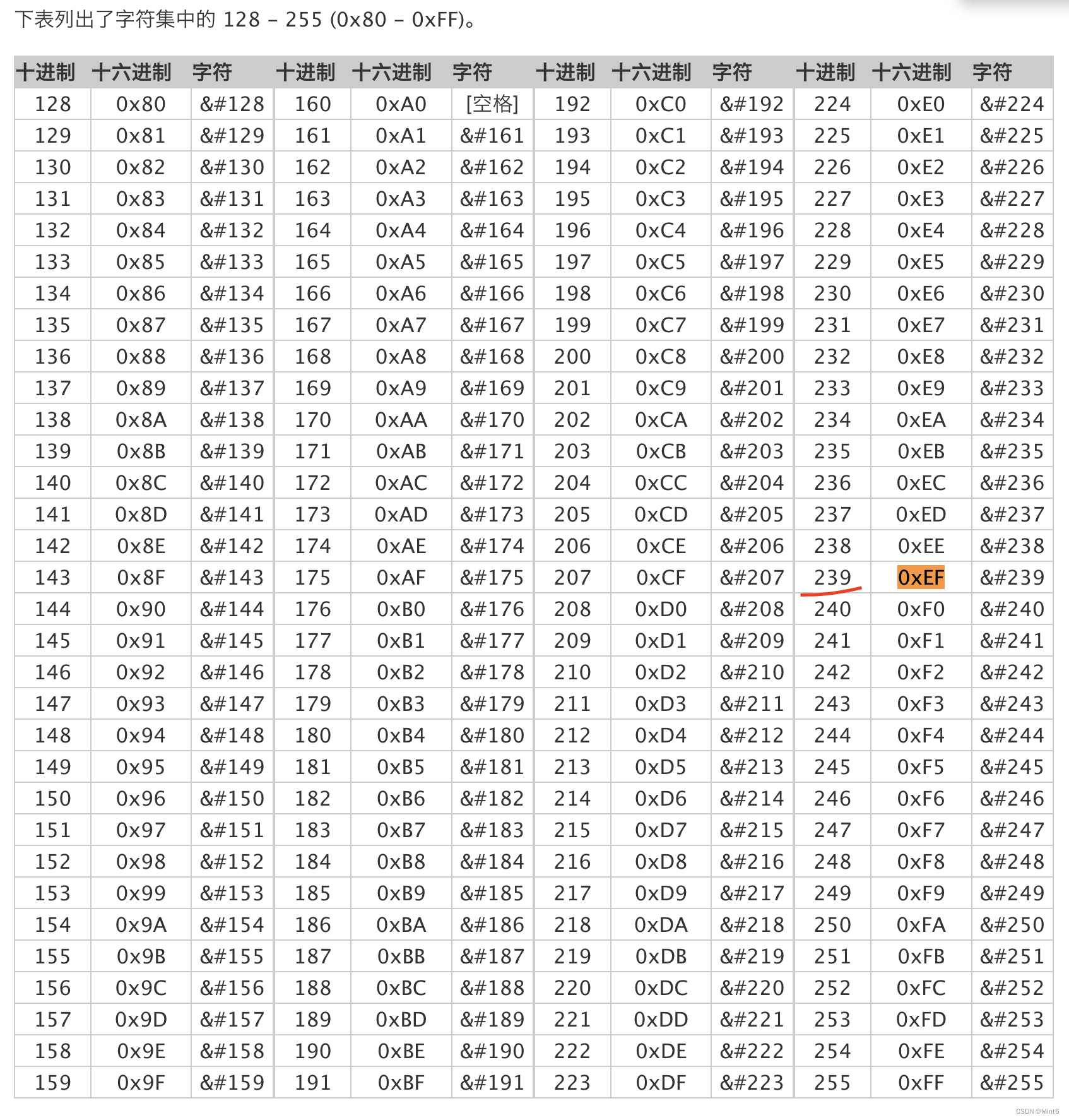
将十进制数 239 转换为二进制数,可以使用逐次除以 2 的方法,将每次的余数记录下来,直到商为 0。这个过程如下所示:
(4.1.2)转换步骤
-
将十进制数 239 除以 2:
- 239 ÷ 2 = 119,余数 1
- 记录余数:1
-
将商 119 除以 2:
- 119 ÷ 2 = 59,余数 1
- 记录余数:1
-
将商 59 除以 2:
- 59 ÷ 2 = 29,余数 1
- 记录余数:1
-
将商 29 除以 2:
- 29 ÷ 2 = 14,余数 1
- 记录余数:1
-
将商 14 除以 2:
- 14 ÷ 2 = 7,余数 0
- 记录余数:0
-
将商 7 除以 2:
- 7 ÷ 2 = 3,余数 1
- 记录余数:1
-
将商 3 除以 2:
- 3 ÷ 2 = 1,余数 1
- 记录余数:1
-
将商 1 除以 2:
- 1 ÷ 2 = 0,余数 1
- 记录余数:1
(4.1.3)汇总余数
将上述步骤中的余数从下到上(即从最后一步到第一步)排列起来,就得到了二进制数:
- 从下到上,余数依次是:
11101111
(4.1.4)结论
十进制数 239 转换为二进制数是 11101111。
(4.1.5)验证

(4.2)根据上面的计算方式,计算出本次的16进制对应的二进制
下面是 `(byte)0xef, (byte)0x8f, (byte)0xff` 这三个字节的 8 位二进制表示形式:
-
`(byte)0xef` 对应的 8 位二进制数为:`11101111`
-
`(byte)0x8f` 对应的 8 位二进制数为:`10001111`
-
`(byte)0xff` 对应的 8 位二进制数为:`11111111`
(4.3)查看二进制是否符合UTF-8的编码规范
这些二进制数表示了各自字节的位模式,然后查看Unicode 和 UTF-8 之间的转换关系表。
0xef对应:`11101111`,所以属于转换关系表的字节序列3,也就是说的UTF-8的三字节字符。剩下的两位字符需要对应Byte 2和Byte 3,应该以10xxxxxx格式开头。
0x8f为`10001111`,符合。
0xff为`11111111`,不符合。
发现这些字节序列并不符合 UTF-8 编码规范,所以它们并不是有效的 UTF-8 编码。
可以回答第4章最初的问题,因为(byte)0xef, (byte)0x8f, (byte)0xff不符合三字节字符对应的转换关系表规范,所以不是UTF-8标准编码。
| 码点的位数 | 码点起值 | 码点终值 | 字节序列 | Byte 1 | Byte 2 | Byte 3 | Byte 4 | Byte 5 | Byte 6 |
| 7 | U+0000 | U+007F | 1 | 0xxxxxxx |
| 11 | U+0080 | U+07FF | 2 | 110xxxxx | 10xxxxxx |
| 16 | U+0800 | U+FFFF | 3 | 1110xxxx | 10xxxxxx | 10xxxxxx |
| 21 | U+10000 | U+1FFFFF | 4 | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
| 26 | U+200000 | U+3FFFFFF | 5 | 111110xx | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
| 31 | U+4000000 | U+7FFFFFFF | 6 | 1111110x |
10xxxxxx |
10xxxxxx |
10xxxxxx |
10xxxxxx |
10xxxxxx |
|---|---|---|---|---|---|---|---|---|---|
[Unicode 和 UTF-8 之间的转换关系表 ( x 字符表示码点占据的位 )] |
(5)不是UTF-8标准编码,跟java转换有什么关系?
经过上面一串的解释,你应该会得出一个结论:因为(byte)0xef, (byte)0x8f, (byte)0xff中的(byte)0xff不是标准的UTF-8字符编码,所以转换过程有问题。它活该呀,谁让它不标准呢。
但是还有一个疑问没解决,那就是为什么它不标准,java就转换不正确?
让我们回到最初的java代码
java
public static void main(String[] args) {
byte[] original2 = new byte[]{(byte)0xef, (byte)0x8f, (byte)0xff};
byte[] transformed2 = new String(original2).getBytes();
System.out.println(Arrays.toString(original2));
System.out.println(Arrays.toString(transformed2));
System.out.println(Arrays.equals(original2, transformed2));
}其中转换逻辑使用到的关键java代码:
java
new String(original2).getBytes();分析String源码
简单的从 String 的构造方法可以看出,没有设置编码的情况下,会采用系统默认编码,macOS上的为 UTF-8,解码过程中使用到一个关键的CharsetDecoder,来看一下CharsetDecoder 的构造方法:
代码位置:JDK 1.8,java.lang.String#String(byte\[\], int, int, java.nio.charset.Charset),636行、611行
JDK 1.8,java.nio.charset.CharsetDecoder#CharsetDecoder(java.nio.charset.Charset, float, float),234行
java
// java.lang.String#String(byte[], int, int, java.nio.charset.Charset),653行
// decode using CharsetDecoder
int en = scale(length, cd.maxCharsPerByte());
cd.onMalformedInput(CodingErrorAction.REPLACE)
.onUnmappableCharacter(CodingErrorAction.REPLACE);
// CodingErrorAction.REPLACE)参数
/**
* Action indicating that a coding error is to be handled by dropping the
* erroneous input, appending the coder's replacement value to the output
* buffer, and resuming the coding operation.
*/
public static final CodingErrorAction REPLACE
= new CodingErrorAction("REPLACE");
// java.nio.charset.CharsetDecoder#CharsetDecoder(java.nio.charset.Charset, float, float),234行
/**
* Initializes a new decoder. The new decoder will have the given
* chars-per-byte values and its replacement will be the
* string <code>"\uFFFD"</code>.
*
* @param cs
* The charset that created this decoder
*
* @param averageCharsPerByte
* A positive float value indicating the expected number of
* characters that will be produced for each input byte
*
* @param maxCharsPerByte
* A positive float value indicating the maximum number of
* characters that will be produced for each input byte
*
* @throws IllegalArgumentException
* If the preconditions on the parameters do not hold
*/
protected CharsetDecoder(Charset cs,
float averageCharsPerByte,
float maxCharsPerByte)
{
this(cs,
averageCharsPerByte, maxCharsPerByte,
"\uFFFD");
}其中比较关键的是 CodingErrorAction.REPLACE,javadoc中的解释:
java
/**
* Action indicating that a coding error is to be handled by dropping the
* erroneous input, appending the coder's replacement value to the output
* buffer, and resuming the coding operation.
*/
public static final CodingErrorAction REPLACE
= new CodingErrorAction("REPLACE");进行string转byte时,针对错误部分的byte:(byte)0xff,会被java使用"\uFFFD"进行替换。所以再将byte转回string时,自然无法准备恢复最初的数据了。
(6)使用java代码验证,是否使用"\uFFFD"替换了错误部分的byte?
java
package com.shopee.mmdb.chunnel.store.kafka;
import java.nio.charset.Charset;
import java.util.Arrays;
public class StringConversionExample {
public static void main(String[] args) {
byte[] original2 = new byte[] {(byte) 0xef, (byte) 0x8f, (byte) 0xff};
byte[] transformed2 = new String(original2).getBytes();
System.out.println(Arrays.toString(original2));
System.out.println(Arrays.toString(transformed2));
System.out.println(Arrays.equals(original2, transformed2));
String unicodeString = "\uFFFD";
Charset charset = Charset.forName("UTF-8");
byte[] byteArr = unicodeString.getBytes(charset);
System.out.println(Arrays.toString(byteArr));
}
}运行结果,显而易见,"\uFFFD"就是 -17, -65, -67。
java
[-17, -113, -1]
[-17, -65, -67, -17, -65, -67]
false
[-17, -65, -67](7)解决问题
既然是UTF-8编码不标准的问题,那么可以通过单字节编码模式,获取到正确的结果,操作如下:
java
byte[] newBytes = new String(bytes, StandardCharsets.ISO_8859_1).getBytes(StandardCharsets.ISO_8859_1)
// 完整代码
package com.shopee.mmdb.chunnel.store.kafka;
import java.nio.charset.Charset;
import java.nio.charset.StandardCharsets;
import java.util.Arrays;
public class StringConversionExample {
public static void main(String[] args) {
byte[] original2 = new byte[] {(byte) 0xef, (byte) 0x8f, (byte) 0xff};
byte[] transformed2 =
new String(original2, StandardCharsets.ISO_8859_1).getBytes(StandardCharsets.ISO_8859_1);
// byte[] transformed2 = new String(original2).getBytes();
System.out.println(Arrays.toString(original2));
System.out.println(Arrays.toString(transformed2));
System.out.println(Arrays.equals(original2, transformed2));
String unicodeString = "\uFFFD";
Charset charset = Charset.forName("UTF-8");
byte[] byteArr = unicodeString.getBytes(charset);
System.out.println(Arrays.toString(byteArr));
}
}执行结果
java
[-17, -113, -1]
[-17, -113, -1]
true
[-17, -65, -67]5.java byte转string问题的总结
java中通过 byte[] 转换为 String 时,可能因为一些编码规则,比如UTF-8,造成部分被替换,反向转换为 byte[] 后和之前不同;在转换时,可以通过指定 StandardCharsets.ISO_8859_1 等单字节编码来解决问题;
这里引入另一个思考的问题 ,一个 String 转换为 byte[] 后,再转换为 String 会有问题么?答案是不会,因为转换为 byte[] 的字节编码是符合 UTF-8 的;
6.那么golang中是否也存在该问题呢?
(1)看goalng的例子
同样的使用不标准的UTF-8编码 0xef, 0x8f, 0xff,golang执行 byte 转 string,然后string再转回byte。
Go
package main
import (
"fmt"
"reflect"
"unicode/utf8"
)
func main() {
original2 := []byte{0xef, 0x8f, 0xff}
transformed2 := []byte(string(original2))
fmt.Println("Original2:", original2)
fmt.Println("Transformed2:", transformed2)
fmt.Println("Are equal:", reflect.DeepEqual(original2, transformed2))
fmt.Println("Original2 string:", string(original2))
if utf8.Valid(original2) {
fmt.Println("Original is valid UTF-8")
} else {
fmt.Println("Original is not valid UTF-8")
}
}运行结果,byte经过一通转换后,又回到了最初的byte,数据完全一致。
所以在golang里并没有复现出,java里的byte转换后数据最终被篡改的问题。
Go
Original2: [239 143 255]
Transformed2: [239 143 255]
Are equal: true
Original2 string: ��
Original is not valid UTF-8(2)golang里为什么byte转string不会出现数据被篡改的情况?
基本信息和源码
GO的字符串 :内存中string用UTF-8编码
go sdk 1.21.5的string源码,如下:
Go
// string is the set of all strings of 8-bit bytes, conventionally but not
// necessarily representing UTF-8-encoded text. A string may be empty, but
// not nil. Values of string type are immutable.
type string string同时根据golang官方博客https://blog.golang.org/strings的原文:
Go
Go source code is always UTF-8.
A string holds arbitrary bytes.
A string literal, absent byte-level escapes, always holds valid UTF-8 sequences.大致意思如下:
- go中的代码总是用UTF-8编码,并且字符串能够存储任何字节
- 没有经过字节级别的转义,那么字符串是一个标准的utf8序列
JAVA的字符串: 内存中string使用的UTF-16编码
JDK 1.8源码:java.lang.String#String(byte\[\])
java
value = StringUTF16.toBytes(ca, 0, caLen);可能到这里,你就会急了"你上面JAVA长篇大论,一直给我讲UTF-8不标准字符,导致了java的转换问题,我刚接受这个概念。怎么到这里,又变成了java使用的UTF-16,golang反倒使用的UTF-8,并且golang还没有出问题?"。
很好,我接着解释。
JAVA转换路径:
1、输入非标准UTF-8字符**=》**
2、根据用户显式指定字符编码集或者Macos机器默认内置的字符编码UTF-8,通知程序本次输入的byte数组是UTF-8编码规则**=》**
3、JAVA调用decodeUTF8_UTF16方法,把byte\[\]转换为UTF-16 =》
4、方法decodeWithDecoder使用"\uFFFD"替换掉不标准的字符,并从byte\[\]转为char\[\] =》
5、最终使用方法StringUTF16.toBytes(ca, 0, caLen),把char\[\]再次转为UTF16,并设置到string的private final byte\[\] value;里
java
// jdk 1.8 string类 573行,方法路径java.lang.String#decodeUTF8_UTF16
dp = decodeUTF8_UTF16(bytes, offset, sl, dst, dp, true);GOLANG转换路径:
1、根据传入的内存大小,判断是否需要分配重新分配内存;
2、构建stringStruct,分类长度和内存空间;
3、赋值\[\]byte里面的数据到新构建stringStruct的内存空间中。
查看源码 src/runtime/string.go
Go
type stringStruct struct {
str unsafe.Pointer
len int
}
func slicebytetostring(buf *tmpBuf, b []byte) (str string) {
l := len(b)
if l == 0 {
return ""
}
if l == 1 {
stringStructOf(&str).str = unsafe.Pointer(&staticbytes[b[0]])
stringStructOf(&str).len = 1
return
}
var p unsafe.Pointer
// 判断传入的缓冲区大小,决定是否重新分配内存
if buf != nil && len(b) <= len(buf) {
p = unsafe.Pointer(buf)
} else {
// 重新分配内存
p = mallocgc(uintptr(len(b)), nil, false)
}
// 将输出的str转化成stringStruct结构
// 并且赋值
stringStructOf(&str).str = p
stringStructOf(&str).len = len(b)
// 将[]byte中的内容,复制到内存空间p中
memmove(p, (*(*slice)(unsafe.Pointer(&b))).array, uintptr(len(b)))
return
}
// 转换成
func stringStructOf(sp *string) *stringStruct {
return (*stringStruct)(unsafe.Pointer(sp))
}JAVA与GOLANG转换区别的对比
基本存储逻辑的区别:
- Java :
String是用 UTF-16 编码存储的字符序列,设计上是用于表示文本数据的类。byte[]是原始的字节数据,通常与String之间的转换涉及字符编码。 - Go :
string总是 UTF-8 (不代表一定)编码的字节序列视图,表示不可变的字节数据。它更接近于一个只读的[]byte,在内部没有进行复杂的编码处理。
对无效编码的处理:
- Java : 在将
byte[]转换为String时,如果字节序列不符合字符集(例如 UTF-8)的要求,Java 会用替代字符'\uFFFD'来表示解码失败的字节。这是为了保证转换结果在文本上是合理的。 - Go : 将
[]byte转换为string时,不会检查字节序列的有效性。无论字节是否符合 UTF-8 规范,转换后的string都会直接包含这些原始字节,不会进行替换。
设计上的考虑:
- Java : 强调国际化和多语言支持,
String是表示人类可读文本的类,必须处理和转换字符集。Java 期望转换过程中得到有效的字符,因此必须处理无效字节序列(替换或者抛出异常)。 - Go : 设计上强调简单和直接,
string只是字节序列的不可变视图,不做额外的编码检查和处理。这使得处理二进制数据和文本时更灵活,但要求开发者自己确保字节序列的有效性。 - 总结
- Java : 强调对字符集和编码的处理,
String是用来表示文本的类,在转换时需要处理不合法的字节。 - Go :
string是不可变的字节序列视图,直接允许[]byte转换为string,无论字节是否构成有效的 UTF-8 字符。
- Java : 强调对字符集和编码的处理,
想看更加详细对比,请参考另外一篇文章**:** Java 和 Go 中的 byte 和 String 转换-CSDN博客
最终结论
java底层存储string,使用byte字节序列,严格限制合法的UTF-16编码,所以为了强调String的有效性,做了严格限制,比如不合法的byte会被替换掉。
golang底层存储string,使用byte字节序列,默认总表示UTF-8编码的字符,也可以不是,不做额外的字符合法性校验。
所以,Java里使用new String(new byte\[\]{new byte\[\] {(byte) 0xef, (byte) 0x8f, (byte) 0xff}})会导致数据被篡改。golang里使用string(\[\]byte{0xef, 0x8f, 0xff})不会导致数据被篡改,所以golang不存在该问题。
7.JAVA和Golang String分析过程中的细节补充
(1)UTF-8和UTF-16什么区别
- UTF-8: 以可变长度编码字符,具有较好的 ASCII 兼容性和网络传输效率,非常适合以英语为主的文本处理和互联网应用。
- UTF-16 : 适合需要处理大量非 ASCII 字符的场景,虽然占用存储空间较大,但在处理字符时较为高效,适合在内存中存储文本和内部字符处理。UTF16详细设计信息,参考:https://zh.wikipedia.org/wiki/UTF-16
更多对比参考文章:编码规则UTF-8 和 UTF-16的区别-CSDN博客
(2)为什么Java默认使用UTF-16,Golang默认使用UTF-8呢?
Java 选择 UTF-16:
历史背景 : Java 诞生时 Unicode 设计目标主要是 16 位编码,UTF-16 是当时处理多语言的最佳选择。
效率考虑 : 固定长度的 2 字节编码简化了字符处理逻辑,特别是在需要高效定位和操作字符时。
兼容性需求: 与 Windows 系统的兼容性需求,使得 UTF-16 在跨平台应用中具有优势。
Go 选择 UTF-8:
创始人背景:Go 语言的3位创始人,其中有2位同时也是UTF-8 字元编码的创始人。
互联网标准 : Go 语言诞生在互联网时代,UTF-8 已成为网络传输和文件存储的标准。
简单高效 : Go 的设计强调简单和高效,UTF-8 作为默认编码简化了字符串处理,特别是在处理 ASCII 兼容文本时。
全球化支持: UTF-8 能够支持全球所有字符,适应了现代互联网应用的需求。
总结
Java 和 Go 在处理字符编码方面的选择,反映了它们各自的历史背景和设计哲学。Java 的 UTF-16 选择了稳定和兼容,而 Go 的 UTF-8 则倾向于现代互联网应用的灵活性和效率。
更多原因,参考另外一篇文章:为什么Java默认使用UTF-16,Golang默认使用UTF-8呢?-CSDN博客
8.Golang中String与Byte、Rune的关系
(1)有必要重温一下,最基本的字符编码概念(上面已经讲过了)
字符串:字符串是由一个或多个字符组成的序列。它可以包含字母、数字、符号和其他特殊字符。
Unicode:Unicode 是一个字符集,它为世界上几乎所有的字符都分配了一个唯一的标识符(码点)。每个字符都有一个对应的 Unicode 码点,用 U+ 加上一个十六进制数字表示,例如 U+0041 表示字符 'A'。
UTF-8:UTF-8 是一种变长编码方案,用于在计算机中表示 Unicode 字符。它使用 8 位字节来编码字符,根据字符的码点范围,使用不同长度的字节序列来表示字符。UTF-8 可以准确地表示各种语言字符、符号和表情等,它是最常用的字符编码方案之一。
Unicode 和 UTF-8 的关系是,Unicode 定义了字符集和字符的标识符(码点),而 UTF-8 是一种编码方案,用于在计算机中表示 Unicode 字符。UTF-8 编码将 Unicode 码点转换为字节序列,并且可以通过解码将字节序列转换回字符。
|-----|------------|--------------|--------------------------------|
| 字符 | Unicode 码点 | UTF-8 编码十六进制 | UTF-8 编码二进制 |
| '爱' | U+7231 | E788B1 | 11100111 10001000 10110001 |
| 'A' | U+0041 | 41 | 01000001 |
| '9' | U+0039 | 39 | 00111001 |
讲解可变长字符,三字节的'爱'字的转换过程:
- 查询Unicode表,找到Unicode 码点: U+7231 十六进制数
- 十六进制数转换为二进制: 0111 0010 0011 0001

- 根据 UTF-8 编码规则,U+7231 需要 3 字节。
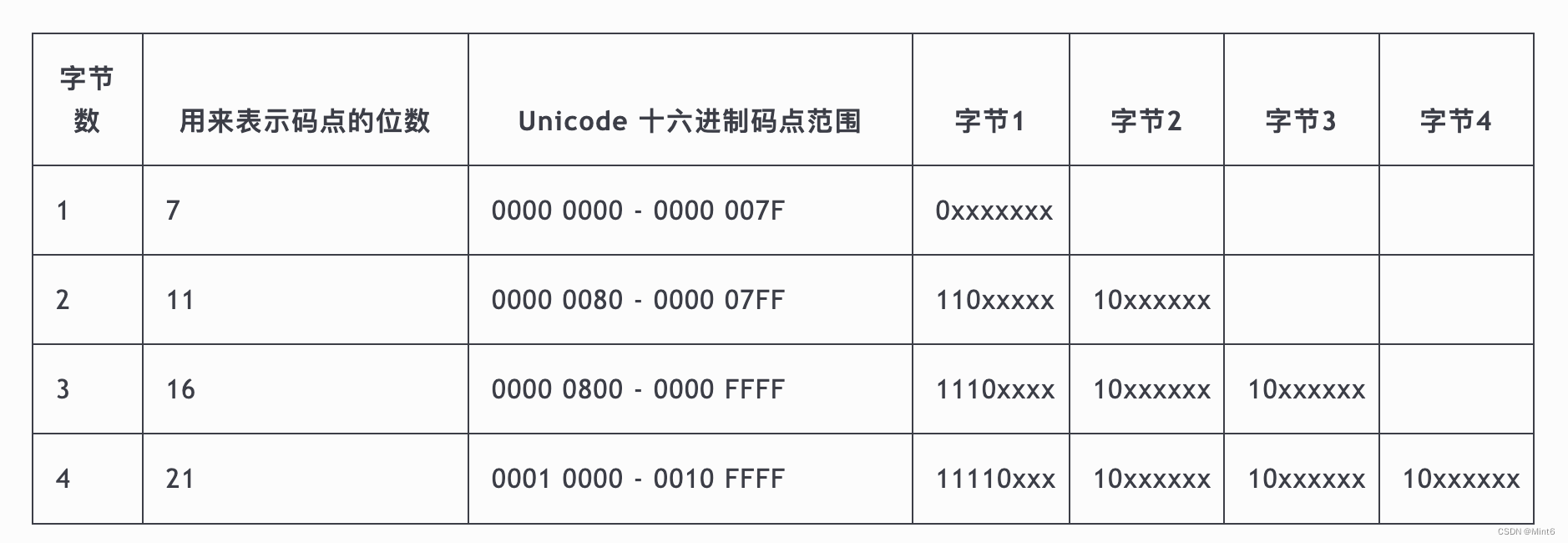
- UTF-8 编码格式:
1110xxxx 10xxxxxx 10xxxxxx - 将二进制数字按位插入格式,按从右向左依次填充这个格式中的 x,多出的 x 用 0 补上:
- 1110xxxx => 11100111
- 10xxxxxx => 10001000
- 10xxxxxx => 10110001
- 二进制每4位一组,根据下面的对照表,转十六进制,最终得到:E7 88 B1
需要进一步详细重温原理,可以看本文的第2个章节:【2.首先熟悉相关字符、字符集、字符编码与字符概念】。
(2)String、Byte和Rune代码中的基本概念
详细讲解版本
String:Go 语言中的字符串是一个只读的字节切片。默认为UTF-8的字节序列,所以string底层转字节时,是默认按照UTF-8编码转换。字节转string时,也默认按照UTF-8解码,如果这组字节不是UTF-8个格式,显示string的时候则会乱码。
[]rune:可以把字符串转换为一个rune数组(即unicode数组)
- 一个rune 4个字节,32 bit
- 一个rune就表示一个Unicode字符
- 每个
Unicode字符,在内存中是以utf-8的形式存储 Unicode字符,输出\[\]rune,会把每个UTF-8转换为Unicode后再输出
[]byte:可以把字符串转换为一个byte数组
- 一个byte 1个字节,8 bit(为了对比rune,所以这句话看起来有点废话)
- 输出
[]byte, 会按字符串在内存中实际存储形式(UTF-8)输出 Unicode字符,按[]byte输出,就会把UTF-8的每个字节单个输出
ASCII(American Standard Code for Information Interchange)****: 是一种字符编码标准,用于表示英文字符及一些控制字符。
- 7 位编码:标准 ASCII 使用 7 位来编码字符,可以表示 128 个字符(从 0 到 127)。
- 8 位扩展:扩展 ASCII 使用 8 位,可以表示 256 个字符(从 0 到 255),包括标准 ASCII 和额外的字符。
- 标准 ASCII 字符的Unicode范围是
U+0000到U+007F,使用单个字节表示 - 256个字符,正好可以使用1个字节表示(8bit,也就是2的8次方256个字符)全部可以存下。
非ASCII:非 ASCII 字符指的是那些超出了标准 ASCII 范围的字符。非 ASCII 字符的编码值通常在 128 以上,要更多的比特来编码,以表示更广泛的字符集。
- 截至 Unicode 15.0(最新版本),已定义的字符总数为 149,186 个 。
- 其中,128 个是标准 ASCII 字符(不包括拓展)。因此,非 ASCII 字符的数量是 149,186 - 128 = 149,058 个。
- 非 ASCII 字符的Unicode范围是
U+0080到U+10FFFF,最大的Unicode为U+10FFFF,二进制需要4个字节才能表示。需要使用可变的多字节表示(从 2 到 4 个字节) - 所以
查看Go源码,byte和rune的定义分别是:type byte = uint8和type rune = int32。
Go
// string is the set of all strings of 8-bit bytes, conventionally but not
// necessarily representing UTF-8-encoded text. A string may be empty, but
// not nil. Values of string type are immutable.
type string string
// byte is an alias for uint8 and is equivalent to uint8 in all ways. It is
// used, by convention, to distinguish byte values from 8-bit unsigned
// integer values.
type byte = uint8
// rune is an alias for int32 and is equivalent to int32 in all ways. It is
// used, by convention, to distinguish character values from integer values.
type rune = int32byte uint8范围是0-255(2的8次方,1字节),只能够表示ASCII Unicode。
Rune int32,4字节的rune完全兼容所有的unicode,包括最大的Unicode U+10FFFF。
区别总结
| 特性 | string |
byte[] |
rune |
|---|---|---|---|
| 数据类型 | 不可变的字符串 | 可变的字节切片 | 可变的 rune(字符)切片 |
| 单位 | UTF-8 字符串 | 单个字节 | Unicode 码点(字符) |
| 主要用途 | 存储和操作文本数据 | 操作原始二进制数据或单字节字符 | 处理和操作 Unicode 字符 |
| 可变性 | 不可变 | 可变 | 可变 |
| 访问方式 | 按字节或字符(rune)访问 | 按字节访问 | 按字符(rune)访问 |
| 示例 | "Hello, 世界" |
[]byte{'H', 'e', 'l', 'l', 'o'} |
[]rune{'H', '世'} |
简单总结版本
-
string
- 定义 :
string类型表示一个不可变的字节序列(文本字符串)。 - 特点 :
- 每个字符可能是一个或多个字节。
- 在 Go 中,
string是 UTF-8 编码的字节序列,这意味着它可以包含多字节字符。
- 操作 :
string可以使用内置的字符串操作函数,如len、+等。
- 定义 :
-
byte
- 定义 :
byte是一个 8 位无符号整数类型,本质上等同于uint8。 - 特点 :
byte类型通常用于表示原始的字节数据。- 处理单字节字符(如 ASCII 字符)或原始的二进制数据时非常有用。
- 操作 :
byte数组([]byte)可以进行字节级别的操作,如读取、写入和修改。
- 定义 :
-
rune
- 定义 :
rune是一个 32 位有符号整数类型,本质上等同于int32。 - 特点 :
rune表示一个 Unicode 码点,可以表示世界上所有的字符。- 使用
rune处理多字节字符和非 ASCII 字符时更方便。
- 操作 :
rune切片([]rune)可以方便地处理字符串中的 Unicode 字符。
- 定义 :
存储同一个字符串时,byte和rune的代码表现
包含非ascii码的字符串
Go
package main
import (
"fmt"
"unicode/utf8"
"unsafe"
)
func main() {
c := "go语言"
s_rune_c := []rune(c)
s_byte_c := []byte(c)
fmt.Println(s_rune_c) // [103 111 35821 35328]
fmt.Println(s_byte_c) // [103 111 232 175 173 232 168 128]
fmt.Println(utf8.RuneCountInString(c)) //4
fmt.Println(len(c)) //8
fmt.Println(len(s_rune_c)) //4
}- 汉字占3个字节(可变长字节存储unicode),所以转换的
[]byte长度为8 - 由于已经转换为
[]rune,所以长度为4 utf8.RuneCountInString()获取UTF-8编码字符串的长度,所以跟[]rune一致
想了解更多它们的区别,可以参考另外一篇文章:golang string、byte\[\]以及rune的基本概念,用法以及区别-CSDN博客
(3)String、Byte和Rune代码的用法示例和转换注意事项
示例与转换
1. string 与 []byte 的转换
string转[]byte:将字符串转换为字节数组,可以用于对原始数据进行处理或传输。[]byte转string:将字节数组转换回字符串,用于将处理后的数据重新组装为字符串。
Go
package main
import (
"fmt"
)
func main() {
// string 转换为 []byte
str := "Hello, 世界"
byteArray := []byte(str)
fmt.Printf("string to []byte: %v\n", byteArray)
fmt.Printf("string to []byte: % X\n", byteArray) // 用 16 进制显示字节
// []byte 转换为 string
newStr := string(byteArray)
fmt.Printf("[]byte to string: %s\n", newStr)
}输出:
Go
string to []byte: [72 101 108 108 111 44 32 228 184 150 231 149 140]
string to []byte: 48 65 6C 6C 6F 2C 20 E4 B8 96 E7 95 8C
[]byte to string: Hello, 世界注意事项:
- 在
string转[]byte时,字符可能会被分割成多个字节。 - 在
[]byte转string时,确保字节数组是合法的 UTF-8 编码,否则会出现乱码或非法字符。
2. string 与 []rune 的转换
string转[]rune:将字符串转换为rune数组,方便逐字符处理,特别是对于非 ASCII 字符。[]rune转string:将rune数组转换回字符串,用于重新组合字符。
Go
package main
import (
"fmt"
)
func main() {
// string 转换为 []rune
str := "Hello, 世界"
runeArray := []rune(str)
fmt.Printf("string to []rune: %v\n", runeArray)
fmt.Printf("string to []rune: %c\n", runeArray) // 用字符显示每个 rune
// []rune 转换为 string
newStr := string(runeArray)
fmt.Printf("[]rune to string: %s\n", newStr)
}输出:
Go
string to []rune: [72 101 108 108 111 44 32 19990 30028]
string to []rune: [H e l l o , 世 界]
[]rune to string: Hello, 世界注意事项:
rune表示的是 Unicode 码点,一个rune可以表示一个完整的字符。string转[]rune时,每个字符都转换为对应的 Unicode 码点,即使是多字节字符。[]rune转string时,字符会被正确地重新组装为字符串。
3. []byte 与 []rune 的转换
[]byte转[]rune:首先需要将[]byte转换为string,然后再将string转换为[]rune。[]rune转[]byte:将[]rune转换为string,然后再将string转换为[]byte。
Go
package main
import (
"fmt"
)
func main() {
// []byte 转换为 []rune
byteArray := []byte("Hello, 世界")
str := string(byteArray) // 中间转换为 string
runeArray := []rune(str) // 再转换为 []rune
fmt.Printf("[]byte to []rune: %v\n", runeArray)
fmt.Printf("[]byte to []rune: %c\n", runeArray)
// []rune 转换为 []byte
newStr := string(runeArray) // 中间转换为 string
newByteArray := []byte(newStr) // 再转换为 []byte
fmt.Printf("[]rune to []byte: %v\n", newByteArray)
fmt.Printf("[]rune to []byte: % X\n", newByteArray) // 用 16 进制显示字节
}输出:
Go
[]byte to []rune: [72 101 108 108 111 44 32 19990 30028]
[]byte to []rune: [H e l l o , 世 界]
[]rune to []byte: [72 101 108 108 111 44 32 228 184 150 231 149 140]
[]rune to []byte: 48 65 6C 6C 6F 2C 20 E4 B8 96 E7 95 8C注意事项:
- 由于
byte只表示单个字节,因此在转换到rune之前,需要经过string以处理多字节字符。 - 直接将
[]rune转换为[]byte是不可行的,因为rune是 32 位,而byte是 8 位,需要中间通过string处理字符的编码。
总结与注意事项
string是 UTF-8 编码的字节序列,适合用于表示和处理常规的文本数据。byte类型用于处理原始字节数据,适合低级别的数据操作和处理单字节字符。rune类型用于处理 Unicode 码点,适合表示和操作多字节的字符,特别是非 ASCII 字符。- 转换时需要注意字符编码,确保在从一种表示形式转换到另一种时不会丢失数据或出现乱码,尤其是在处理非 ASCII 字符时。
9.不符合UTF-8的Byte转换示例
Java
代码
java
package com.xxx;
import java.nio.charset.Charset;
import java.nio.charset.StandardCharsets;
import java.util.Arrays;
public class StringConversionExample {
public static void main(String[] args) {
byte[] original2 = new byte[] {(byte) 0xef, (byte) 0x8f, (byte) 0xff};
// 解决办法,使用单字节
// byte[] transformed2 =
new String(original2, StandardCharsets.ISO_8859_1).getBytes(StandardCharsets.ISO_8859_1);
byte[] transformed2 = new String(original2).getBytes();
System.out.println(Arrays.toString(original2));
System.out.println(Arrays.toString(transformed2));
System.out.println(Arrays.equals(original2, transformed2));
String unicodeString = "\uFFFD";
Charset charset = Charset.forName("UTF-8");
byte[] byteArr = unicodeString.getBytes(charset);
System.out.println(Arrays.toString(byteArr));
}
}输出
java
[-17, -113, -1]
[-17, -65, -67, -17, -65, -67]
false
[-17, -65, -67]Golang
代码
Go
package main
import (
"fmt"
"reflect"
"unicode/utf8"
)
func main() {
original2 := []byte{0xef, 0x8f, 0xff}
transformed2 := []byte(string(original2))
fmt.Println()
fmt.Println("byte byte demo")
fmt.Println("Original byte:", original2)
fmt.Println("Transformed byte:", transformed2)
fmt.Println("Byte are equal:", reflect.DeepEqual(original2, transformed2))
fmt.Println("Original byte string:", string(original2))
fmt.Println("Transformed byte string:", string(transformed2))
if utf8.Valid(original2) {
fmt.Println("Original is valid UTF-8")
} else {
fmt.Println("Original is not valid UTF-8")
}
fmt.Println()
fmt.Println("rune rune demo")
originalRune := []rune{0xef, 0x8f, 0xff}
transformedRune := []rune(string(originalRune))
fmt.Println("Original rune:", originalRune)
fmt.Println("Transformed rune:", transformedRune)
fmt.Println("Rune are equal:", reflect.DeepEqual(originalRune, transformedRune))
fmt.Println("Original rune string:", string(originalRune))
fmt.Println("Transformed rune string:", string(transformedRune))
fmt.Println()
fmt.Println("next rune to byte demo")
originalRune2 := []rune{0xef, 0x8f, 0xff}
transformedRune2 := []byte(string(originalRune2))
fmt.Println("Original rune:", originalRune2)
fmt.Println("Transformed byte:", transformedRune2)
fmt.Println("Rune byte are equal:", reflect.DeepEqual(originalRune2, transformedRune2))
fmt.Println("Original rune string:", string(originalRune2))
fmt.Println("Transformed byte string:", string(transformedRune2))
fmt.Println()
fmt.Println("next byte to rune demo")
originalRune3 := []byte{0xef, 0x8f, 0xff}
transformedRune3 := []rune(string(originalRune3))
fmt.Println("Original byte:", originalRune3)
fmt.Println("Transformed rune:", transformedRune3)
fmt.Println("Byte Rune are equal:", reflect.DeepEqual(originalRune3, transformedRune3))
fmt.Println("Original byte string:", string(originalRune3))
fmt.Println("Transformed rune string:", string(transformedRune3))
fmt.Println()
fmt.Println("打印替换字符的byte和rune二进制格式")
fmt.Println([]byte(string("\uFFFD")))
fmt.Println([]rune(string("\uFFFD")))
}输出
Go
byte byte demo
Original byte: [239 143 255]
Transformed byte: [239 143 255]
Byte are equal: true
Original byte string: ��
Transformed byte string: ��
Original is not valid UTF-8
rune rune demo
Original rune: [239 143 255]
Transformed rune: [239 143 255]
Rune are equal: true
Original rune string: ïÿ
Transformed rune string: ïÿ
next rune to byte demo
Original rune: [239 143 255]
Transformed byte: [195 175 194 143 195 191]
Rune byte are equal: false
Original rune string: ïÿ
Transformed byte string: ïÿ
next byte to rune demo
Original byte: [239 143 255]
Transformed rune: [65533 65533 65533]
Byte Rune are equal: false
Original byte string: ��
Transformed rune string: ���
打印替换字符的byte和rune二进制格式
[239 191 189]
[65533]这里的代码中,输入都是byte\[\]:0xef, 0x8f, 0xff,非标准的UTF-8变长字节,转换过程会出现字符串显示乱码。
相关链接
(1)本文原理参考文档
深入剖析go中字符串的编码问题------特殊字符的string怎么转byte?
【Golang】深究字符串------从byte rune string到Unicode与UTF-8
(2)容易忽视的类似问题,与本文的问题相似但有些区别,也很有趣
Redis数据迁移过程,使用jedis客户端,需要注意区分string和byte命令转换字符编码不一致的问题,使用不当会导致丢数据_redis数据转编议-CSDN博客