python期考复习题
目录
[1. 判断n**2的值每一位互不相同编辑](#1. 判断n**2的值每一位互不相同编辑)
[2. 密码](#2. 密码)
[3. 图书版号](#3. 图书版号)
[4. 情感分类矩阵](#4. 情感分类矩阵)
[5. 计算数对个数](#5. 计算数对个数)
1. 判断n**2的值每一位互不相同
pythondef isdiff(n): s=str(n) for i in range(len(s)): for j in range(len(s)): if i!=j: if s[i]==s[j]: return False return True low=eval(input()) high=eval(input()) for i in range(low,high+1): if isdiff(i*i): print(i,end=" ") print(i*i)该题难点主要在于如何构建函数判断数字内部每一位互不相同,可以将数字转换为字符串,使用for循环的嵌套遍历该字符串(如上),也可以使用count函数(如下):
pythondef isdiff(n): s=str(n) for c in s: if s.count(c)>1: return False else: return True low=eval(input()) high=eval(input()) for i in range(low,high+1): if isdiff(i*i): print(i,end=" ") print(i*i)
2. 密码


pythons='abcdefghijklmnopqrstuvwxyz' # 定义一个包含所有小写字母的字符串 dic={} # 定义一个空字典,用于存储每个字母的加密映射 for k in s: i=s.index(k) dic[k]=s[i:]+s[:i] # 为每个字母生成加密映射,将字母表分为两部分,并按顺序拼接 K=input().lower() # 获取密钥,并将其转换为小写 len_k=len(K) # 获取密钥的长度 C=input() # 获取需要加密的文本 M='' # 定义一个空字符串,用于存储解密后的文本 for i in range(len(C)): # 遍历需要加密的文本的每个字符 k = K[i % len_k] # 获取当前字符对应的密钥字母 c = C[i] # 获取需要加密的文本的当前字符 idx = dic[k].index(c.lower()) # 计算当前字符在加密映射中的索引 m = s[idx] # 根据索引获取解密后的字符 if c.isupper(): # 如果原始字符是大写 m = m.upper() # 将解密后的字符也转换为大写 M += m # 将解密后的字符添加到解密文本中 print(M) #输出结果难点:题目很长,而且较难理解,我也不是很懂,备注里是GPT的解释
3. 图书版号

pythons=input() key=int(s[-1]) #获取验证码 s=s[:-2] #获取删除验证码后的字符串,不然会很难做替换那一步 s1=s.replace('-','') ls=[int(s1[i])*(i+1) for i in range(len(s))] sum1=sum(ls) x=sum1%11 #x是计算出来的验证码 if x==10: x='X' #记得加引号,不然会报错,别问我怎么知道的 if x==key: print('Right') else: print('{}-{}'.format(s,x))这题我认为难点主要是数据类型要保持一致,在计算途中要记得使用int(),str()等强制转换数据类型,不然很容易报错
4. 情感分类矩阵
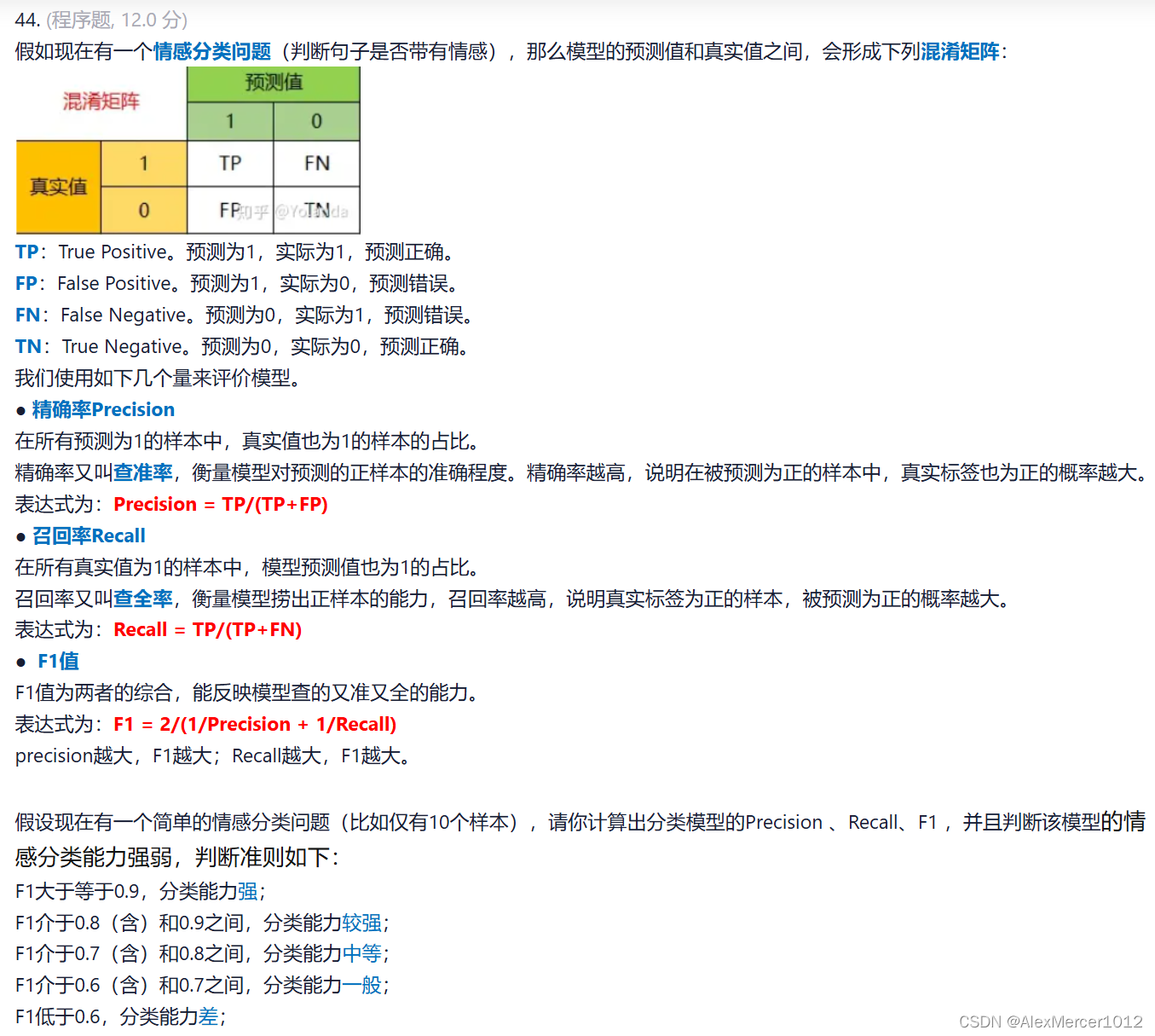

pythonls2=eval(input()) ls1=eval(input()) '''注意先输入的是真实值,后输入的是预测值,但是在描述计算方法时,先讲的是预测值, 后讲的是真实值.这里为了方便边写程序,是按照计算方法的描述顺序写的下面的for循环, 所以先输入ls2后输入ls1 ''' TP=FP=FN=TN=0 #使用连续初始化更加简洁 for i in range(10): if ls1[i]==1 and ls2[i]==1: TP+=1 elif ls1[i]==1 and ls2[i]==0: FP+=1 elif ls1[i]==0 and ls2[i]==1: FN+=1 elif ls1[i]==0 and ls2[i]==0: #用else也一样,elif会更严谨,如果输入错了也会报错 TN+=1 #print(TP,FP,FN,TN) 在编写程序时可以让其输出看看值 P=round(TP/(TP+FP),2) R=round(TP/(TP+FN),2) F1=round(2/(1/P+1/R),2) if F1>=0.9: J='强' elif 0.9>F1>=0.8: J='较强' elif 0.8>F1>=0.7: J='中等' elif 0.7>F1>=0.6: J='一般' elif F1<0.6: J='差' print(P,R,F1,J)这题的难点我认为不在于编写,在于输入时是先真实后预测,但在如何计算的描述中是先预测后真实,输入语句容易写反,具体在注释中已经说明。
5. 计算数对个数

pythonlst=eval(input()) C=eval(input()) cnt=0 for i in range(len(lst)): for j in range(len(lst)): if i!=j: #注意判断不能是同一个位置的值 if lst[i]-lst[j]==C: cnt+=1 print(cnt)本题较为简单,直接遍历列表然后输出即可,注意最后一行不用输出,如果需要输出:
pythonlst=eval(input()) C=eval(input()) lst1=[] #初始化一个列表用于存储结果 cnt=0 for i in range(len(lst)): for j in range(len(lst)): if i!=j: if lst[i]-lst[j]==C: lst1.append((i,j)) cnt+=1 print(cnt) print("上例中包含{}个数对,分别为:"。format(cnt),end='') for i in range(cnt): print(lst1[i],end='') #引号内为空 if i==cnt-1: break print("、",end='') #引号内为空 '''如果直接输出整句话: print("上例中包含{}个数对,分别为:"。format(cnt),end='') for i in lst1: print(i,end="、") 句末会多出一个顿号'''