ClickHouse学习
安装部署
1.下载rpm文件
下载地址:https://packages.clickhouse.com/rpm/stable/
txt
clickhouse-client-23.2.1.2537.x86_64.rpm
clickhouse-common-static-23.2.1.2537.x86_64.rpm
clickhouse-common-static-dbg-23.2.1.2537.x86_64.rpm
clickhouse-server-23.2.1.2537.x86_64.rpm2.上传rmp文件到Linux中
3.安装
shell
1、进入目录:
cd /usr/local/soft/jars/clickhouse_rpms
2、使用rpm命令安装
sudo rpm -ivh *.rpm
注意:安装过程需要输入密码,密码不要复杂,123456即可
Password for default user is saved in file /etc/clickhouse-server/users.d/default-password.xml.
3、启动服务
systemctl start clickhouse-server.service
4、状态查看
systemctl status clickhouse-server.service
5、停止服务
systemctl stop clickhouse-server.service
6、重启服务
systemctl restart clickhouse-server.service
7、进入客户端
clickhouse-client
8.安装后的数据根目录
/var/lib/clickhouse
4.远程连接clickhouse
shell
1、打开clickhouse配置文件
vim /etc/clickhouse-server/config.xml
2、搜索并放开下面配置的注释
<listen_host>0.0.0.0</listen_host>
<tcp_port>9001</tcp_port>
3、保存即可
:wq!
4、重启
systemctl restart clickhouse-server
查看端口号被哪个服务所占用
netstat -lnpt | grep 9001
使用命令行进入clickhouse客户端
clickhouse-client --port 9001 --password 1234565.使用datagrip连接clickhouse
Clickhouse概述
ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。
OLTP(联机事务处理系统)
例如mysql等关系型数据库,在对于存储小数据量的时候,查询数据并分析速度很快,OLTP本身其实是一个逻辑上的概念,指的是某个数据库,主要是针对增删改操作的。
里面的数据会经常的发生变化。
OLAP(联机分析处理系统)
指的是数据库中的数据长期不变,有着大量的历史数据,并且可以随时的做分析,而增删改操作很少。
OLAP 种类系统架构的的特点:
1、绝大多数是读请求
2、数据以相当大的批次(> 1000行)更新,而不是单行更新;或者根本没有更新。
3、已添加到数据库的数据不能修改。
4、对于读取,从数据库中提取相当多的行,但只提取列的一小部分。
5、宽表,即每个表包含着大量的列
6、查询相对较少(通常每台服务器每秒查询数百次或更少)
7、对于简单查询,允许延迟大约50毫秒
8、列中的数据相对较小:数字和短字符串(例如,每个URL 60个字节)
9、处理单个查询时需要高吞吐量(每台服务器每秒可达数十亿行)
10、事务不是必须的
11、对数据一致性要求低
12、每个查询有一个大表。除了他以外,其他的都很小。
13、查询结果明显小于源数据。换句话说,数据经过过滤或聚合,因此结果适合于单个服务器的RAM中
表操作
数据类型
注意事项:
1、建表写数据类型的时候,严格区分大小写Int32,不能写成int32
2、建表的时候,必须要指定表引擎(详细引擎的使用,后面介绍)
学习参考官方文档 (https://clickhouse.com/docs/zh)
- 整数类型
UInt8, UInt16, UInt32, UInt64, UInt128, UInt256, Int8, Int16, Int32, Int64, Int128, Int256
- 字符串类型
String:可变长字符串
FixedString(长度):固定长字符串,参数是字节数,执行效率比String要高
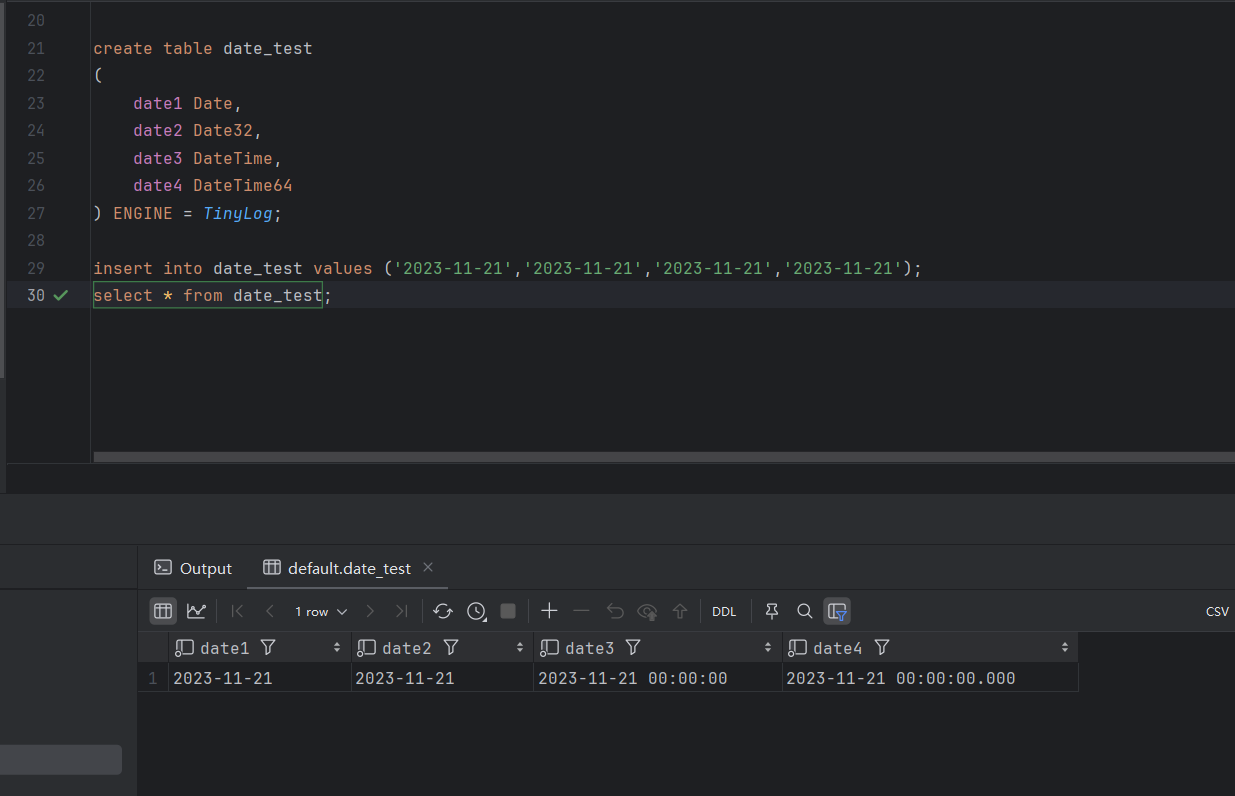
- 日期类型
Date 年-月-日
Date32 年-月-日
DateTime 年-月-日 时-分-秒
DateTime64 年-月-日 时-分-秒.毫秒
- UUID类型
clickhouse提供了一个函数:generateUUIDv4() 生成一个 00000000-0000-0000-0000-000000000000 的编号 编号的类型就是UUID类型
- 可为空 Nullable
例如建表的时候,有一个id字段类型时Int32,如果当id不确定的时候,我们应该使用null进行填充,而不应该用默认值0,所以,我们这里应该添加的是null
Nullable(Int32)
- 数组 Array(T)
字段类型是数组,对于同一个数组,在建表的时候指定数据类型,注意:在MergeTree表引擎中是不允许出现数组嵌套的
注意:需要使用array()函数,将元素组成数组,将来还可以使用toTypeName()查看某一列的数据类型
sql
create table bigdata30.t1 (col1 Array(Int8)) ENGINE = TinyLog;
insert into bigdata30.t1 values(array(11,12,13));
#得到是一个地址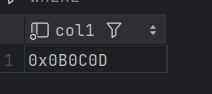
sql
create table bigdata30.t2 (col1 Array(String)) ENGINE = TinyLog;
insert into bigdata30.t2 values(array('java','hadoop'));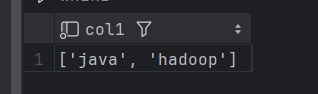
- 小数类型
Decimal(P,S),Decimal32(S),Decimal64(S),Decimal128(S)
有符号的定点数,可在加、减和乘法运算过程中保持精度。对于除法,最低有效数字会被丢弃(不舍入)
P - 精度。有效范围:1:38,决定可以有多少个十进制数字(包括分数)总共多少位
S - 规模。有效范围:0:P,决定数字的小数部分中包含的小数位数。 小数点后几位
Decimal(4,2)
举例:12.12234 Decimal(7,5)
P: 7
S: 5
建表
官方的建表语句模版:
sql
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [NULL|NOT NULL] [DEFAULT|MATERIALIZED|EPHEMERAL|ALIAS expr1] [COMMENT 'comment for column'] [compression_codec] [TTL expr1],
name2 [type2] [NULL|NOT NULL] [DEFAULT|MATERIALIZED|EPHEMERAL|ALIAS expr2] [COMMENT 'comment for column'] [compression_codec] [TTL expr2],
...
) ENGINE = engine
COMMENT 'comment for table'创建一张表:
数据准备:students.txt
建表语句:
sql
create table if not exists bigdata30.students_test1(
id Int16, --数据类型必须严格与官网保持一致,区分大小写
name String,
age Int8,
gender FixedString(3), --定长字符串
clazz String
) ENGINE = TinyLog -- 最简单的引擎
COMMENT '创建学生表'; -- 表描述信息引擎
数据库引擎
数据库引擎允许您处理数据表。
默认情况下,ClickHouse使用Atomic数据库引擎。它提供了可配置的table engines和SQL dialect
您还可以使用以下数据库引擎:
- MySQL
- MaterializeMySQL
- Lazy
- Atomic
- PostgreSQL
- MaterializedPostgreSQL
- Replicated
- SQLite
Atomic
clickhouse数据库建库默认指定的数据库引擎
它支持非阻塞的DROP TABLE和RENAME TABLE查询和原子的EXCHANGE TABLES t1 AND t2查询。默认情况下使用Atomic数据库引擎。
MySQL
MySQL引擎用于将远程的MySQL服务器中的表映射到ClickHouse中,并允许您对表进行
INSERT和SELECT查询,以方便您在ClickHouse与MySQL之间进行数据交换
MySQL数据库引擎会将对其的查询转换为MySQL语法并发送到MySQL服务器中,因此您可以执行诸如SHOW TABLES或SHOW CREATE TABLE之类的操作。但无法对其执行以下操作:
RENAMECREATE TABLEALTER
sql
CREATE DATABASE [IF NOT EXISTS] db_name [ON CLUSTER cluster]
ENGINE = MySQL('host:port', ['database' | database], 'user', 'password')
sql
create database if not exists master_mysql_Y1_db
ENGINE =MySQL('master','Y1','root','123456');两个数据库中的表相同
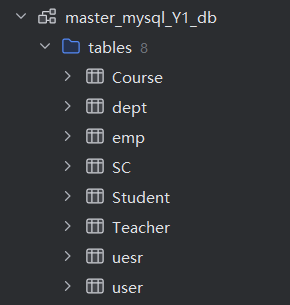
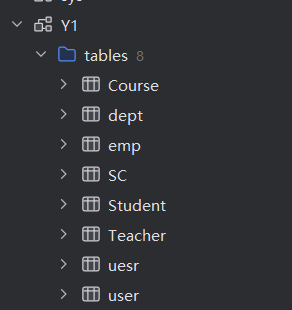 mysql的数据和ck中的数据库映射的数据几乎是同步的
mysql的数据和ck中的数据库映射的数据几乎是同步的
在任意一端添加数据,另一端都可以看到添加后的结果
删除数据: 只能在mysql端,不能在ck端删除
表引擎
表引擎(即表的类型)决定了:
- 数据的存储方式和位置,写到哪里以及从哪里读取数据
- 支持哪些查询以及如何支持。
- 并发数据访问。
- 索引的使用(如果存在)。
- 是否可以执行多线程请求。
- 数据复制参数。
日志引擎
这些引擎是为了需要写入许多小数据量(少于一百万行)的表的场景而开发的。
共同属性:
- 数据存储在磁盘上。
- 写入时将数据追加在文件末尾。
- 不支持突变操作。(不支持uodate和delete操作)
- 不支持索引。
- 非原子地写入数据
- TinyLog
最简单的表引擎,用于将数据存储在磁盘上。每列都存储在单独的压缩文件中。写入时,数据将附加到文件末尾。
并发数据访问不受任何限制:
- 如果同时从表中读取并在不同的查询中写入,则读取操作将抛出异常
- 如果同时写入多个查询中的表,则数据将被破坏。
这种表引擎的典型用法是 write-once:首先只写入一次数据,然后根据需要多次读取。查询在单个流中执行。换句话说,此引擎适用于相对较小的表(建议最多1,000,000行)。如果您有许多小表,则使用此表引擎是适合的,因为它比Log引擎更简单(需要打开的文件更少)。当您拥有大量小表时,可能会导致性能低下,但在可能已经在其它 DBMS 时使用过,则您可能会发现切换使用 TinyLog 类型的表更容易。不支持索引
存储数据情况:以创建的t2这张表为例

- Log
Log与TinyLog的不同之处在于,<<标记>> 的小文件与列文件存在一起。这些标记写在每个数据块上,并且包含偏移量,这些偏移量指示从哪里开始读取文件以便跳过指定的行数。这使得可以在多个线程中读取表数据。对于并发数据访问,可以同时执行读取操作,而写入操作则阻塞读取和其它写入。Log引擎不支持索引。同样,如果写入表失败,则该表将被破坏,并且从该表读取将返回错误。Log引擎适用于临时数据,write-once 表以及测试或演示目的。
sql
-- 使用log引擎建表
create table if not exists bigdata30.demo1(
id Int32,
name String,
age Int32
) ENGINE = Log;
insert into bigdata30.demo1 values (1001,'xiaohu',18),(1001,'xiaohu1',18),(1001,'xiaohu2',18);在根目录的数据中 与Tinylog不同 多了标记文件

- StripeLog
在你需要写入许多小数据量(小于一百万行)的表的场景下使用这个引擎。
写数据:
StripeLog引擎将所有列存储在一个文件中。对每一次Insert请求,ClickHouse 将数据块追加在表文件的末尾,逐列写入。ClickHouse 为每张表写入以下文件:
data.bin--- 数据文件。index.mrk--- 带标记的文件。标记包含了已插入的每个数据块中每列的偏移量。
StripeLog引擎不支持ALTER UPDATE和ALTER DELETE操作。读取数据:
带标记的文件使得 ClickHouse 可以并行的读取数据。这意味着
SELECT请求返回行的顺序是不可预测的。使用ORDER BY子句对行进行排序。
sql
-- 使用stripelog引擎建表
create table if not exists bigdata30.demo2(
id Int32,
name String,
age Int32
) ENGINE = StripeLog;
insert into bigdata30.demo2 values (1001,'xiaohu',18),(1001,'xiaohu1',18),(1001,'xiaohu2',18);数据存储情况:

合并树家族
MergeTree
Clickhouse 中最强大的表引擎当属
MergeTree(合并树)引擎及该系列(MergeTree)中的其他引擎。
MergeTree系列的引擎被设计用于插入极大量的数据到一张表当中。数据可以以数据片段的形式一个接着一个的快速写入,数据片段在后台按照一定的规则进行合并。相比在插入时不断修改(重写)已存储的数据,这种策略会高效很多。主要特点:
- 存储的数据按主键排序。
这使得您能够创建一个小型的稀疏索引来加快数据检索。
- 如果指定了 分区键的话,可以使用分区。
在相同数据集和相同结果集的情况下 ClickHouse 中某些带分区的操作会比普通操作更快。查询中指定了分区键时 ClickHouse 会自动截取分区数据。这也有效增加了查询性能。
- 支持数据副本。
ReplicatedMergeTree系列的表提供了数据副本功能。更多信息,请参阅 数据副本 一节。
- 支持数据采样。
需要的话,您可以给表设置一个采样方法
建表模版:
sql
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...]
[SETTINGS name=value, ...]
sql
# 案列
-- 使用合并树家族创建订单表
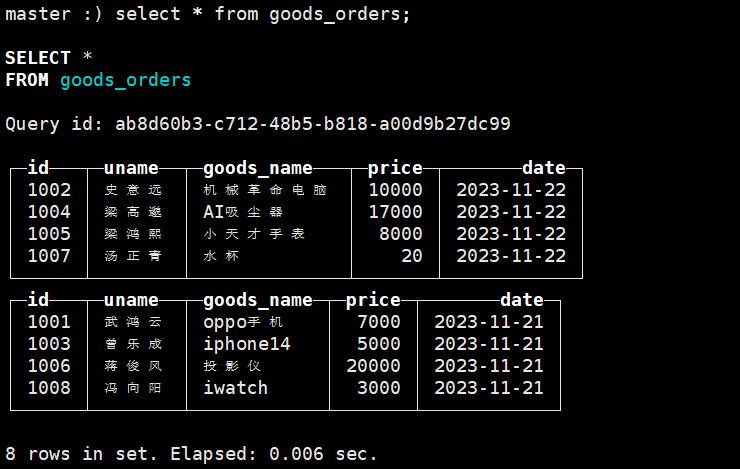
create table goods_orders
(
id String,
uname String,
goods_name String,
price Int64,
date Date32
) ENGINE = MergeTree() order by date PARTITION BY date;
# 插入数据
insert into goods_orders values ('1001','武鸿云','oppo手机',7000,'2023-11-21'),('1002','史意远','机械革命电脑',10000,'2023-11-22'),('1003','曾乐成','iphone14',5000,'2023-11-21'),('1004','梁高邈','AI吸尘器',17000,'2023-11-22');
insert into goods_orders values ('1005','梁鸿熙','小天才手表',8000,'2023-11-22'),('1006','蒋俊风','投影仪',20000,'2023-11-21'),('1007','汤正青','水杯',20,'2023-11-22'),('1008','冯向阳','iwatch',3000,'2023-11-21');先插入一部分数据,在ck客户端查看这张表
sh
# 启动服务
systemctl start clickhouse-server.service
#进入客户端
clickhouse-client --port 9001 --user default --password 123456
#查询数据
select * from goods_orders;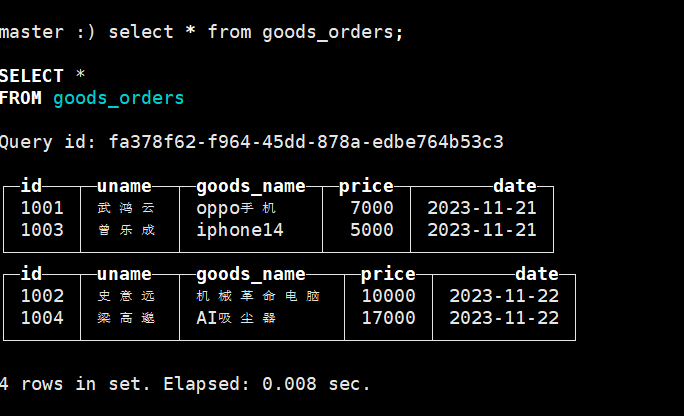
数据自动分区,默认是针对每一批数据按照分区字段的值进行分区,查看表数据结构:
sh
# 路径
/var/lib/clickhouse/data/default/goods_orders
再次添加数据:

根据上图所示,并不会立刻的将所有的相同的分区进行合并,如果想要很快的看到结果,可以手动的进行合并
sql
optimize table 表名 final;
optimize table goods_orders final;手动合并后结果/或者是过一段时间自动合并结果:
今后开发的时候,常用的表引擎:针对数据量小的表引擎用TinyLog, 数据量大表引擎就用MergeTree
常用函数
详细和更多函数 可以查看官网
算术函数
对于所有算术函数,结果类型为结果适合的最小数值类型(如果存在这样的类型)。最小数值类型是根据数值的位数,是否有符号以及是否是浮点类型而同时进行的。如果没有足够的位,则采用最高位类型。简单理解:会自动的根据我们的数值大小,来选用最适合的数据类型存储。
txt
# plus(a, b), a + b operator
计算数值的总和。 您还可以将Date或DateTime与整数进行相加。在Date的情况下,和整数相加整数意味着添加相应的天数。对于DateTime,这意味着添加相应的秒数。
# minus(a, b), a - b operator
计算数值之间的差,结果总是有符号的。
您还可以将Date或DateTime与整数进行相减。见上面的'plus'。
# multiply(a, b), a * b operator
计算数值的乘积。
# divide(a, b), a / b operator
计算数值的商。结果类型始终是浮点类型。 它不是整数除法。对于整数除法,请使用'intDiv'函数。 当除以零时,你得到'inf','- inf'或'nan'。
# intDiv(a,b) 相当于floor
计算数值的商,向下舍入取整(按绝对值)。 除以零或将最小负数除以-1时抛出异常。
# max2(a,b)
value1 --- 第一个值,类型为Int/UInt或Float。
value2 --- 第二个值,类型为Int/UInt或Float。
# max2(value1, value2)
value1 --- 第一个值,类型为Int/UInt or Float。
value2 --- 第二个值,类型为Int/UInt or Float。比较函数
可以比较以下类型:
- 数字
- String 和 FixedString
- date
- datetime
等于,a=b和a==b 运算符
不等于,a!=b和a<>b 运算符
少, < 运算符
大于, > 运算符
小于等于, <= 运算符
大于等于, >= 运算符
数据类型转换
当你把一个值从一个类型转换为另外一个类型的时候,你需要注意的是这是一个不安全的操作,可能导致数据的丢失。数据丢失一般发生在你将一个大的数据类型转换为小的数据类型的时候,或者你把两个不同的数据类型相互转换的时候。
txt
使用to...来进行转换
toInt
toFloat
toDateTime...
或者使用
CAST(x, T)
将'x'转换为't'数据类型。还支持语法CAST(x AS t)条件函数
txt
if
语法
SELECT if(cond, then, else)
三元运算符
与 if 函数相同。
语法: cond ? then : else
如果cond != 0则返回then,如果cond = 0则返回else。
cond必须是UInt8类型,then和else必须存在最低的共同类型。
then和else可以是NULL
multiIf
与case相同
multiIf(cond_1, then_1, cond_2, then_2, ..., else)
直接使用条件结果
--在同一个查询语句中,前一个列查询结果,可以被后续的查询语句或函数使用
select 2*2+20 as c1 ,10<20 as c2,10>20 as c3,c1>100 as c4;
c1 c2 c3 c4
24 1 0 0
条件中的NULL值
当条件中包含 NULL 值时,结果也将为 NULL。时间日期函数
date_add
date_diff
date_sub
等等
详细可见官网
字符串函数
txt
empty
对于空字符串返回1,对于非空字符串返回0。 结果类型是UInt8。 如果字符串包含至少一个字节,则该字符串被视为非空字符串,即使这是一个空格或空字符。 该函数也适用于数组。
notEmpty
对于空字符串返回0,对于非空字符串返回1。 结果类型是UInt8。 该函数也适用于数组。
length
返回字符串的字节长度。 结果类型是UInt64。 该函数也适用于数组。
reverse
反转字符串。
format(pattern, s0, s1, ...)
使用常量字符串pattern格式化其他参数。pattern字符串中包含由大括号{}包围的<<替换字段>>。 未被包含在大括号中的任何内容都被视为文本内容,它将原样保留在返回值中。 如果你需要在文本内容中包含一个大括号字符,它可以通过加倍来转义:{{ '{{' }}和{{ '{{' }} '}}' }}。 字段名称可以是数字(从零开始)或空(然后将它们视为连续数字)
concat(s1, s2, ...)
将参数中的多个字符串拼接,不带分隔符。
endsWith(s,后缀)
返回是否以指定的后缀结尾。如果字符串以指定的后缀结束,则返回1,否则返回0。
startsWith(s,前缀)
返回是否以指定的前缀开头。如果字符串以指定的前缀开头,则返回1,否则返回0。
...字符串替换函数
txt
replaceOne(haystack, pattern, replacement)
用'replacement'子串替换'haystack'中第一次出现的'pattern'子串(如果存在)。 'pattern'和'replacement'必须是常量。
等等开窗函数
clickhouse也支持开窗函数

clickhouse补充
使用客户端插入数据:
sh
$ echo -ne "1, 'some text', '2016-08-14 00:00:00'\n2, 'some more text', '2016-08-14 00:00:01'" | clickhouse-client --database=test --query="INSERT INTO test FORMAT CSV";
$ cat <<_EOF | clickhouse-client --database=test --query="INSERT INTO test FORMAT CSV";
3, 'some text', '2016-08-14 00:00:00'
4, 'some more text', '2016-08-14 00:00:01'
_EOF
$ cat file.csv | clickhouse-client --database=test --query="INSERT INTO test FORMAT CSV";eg:
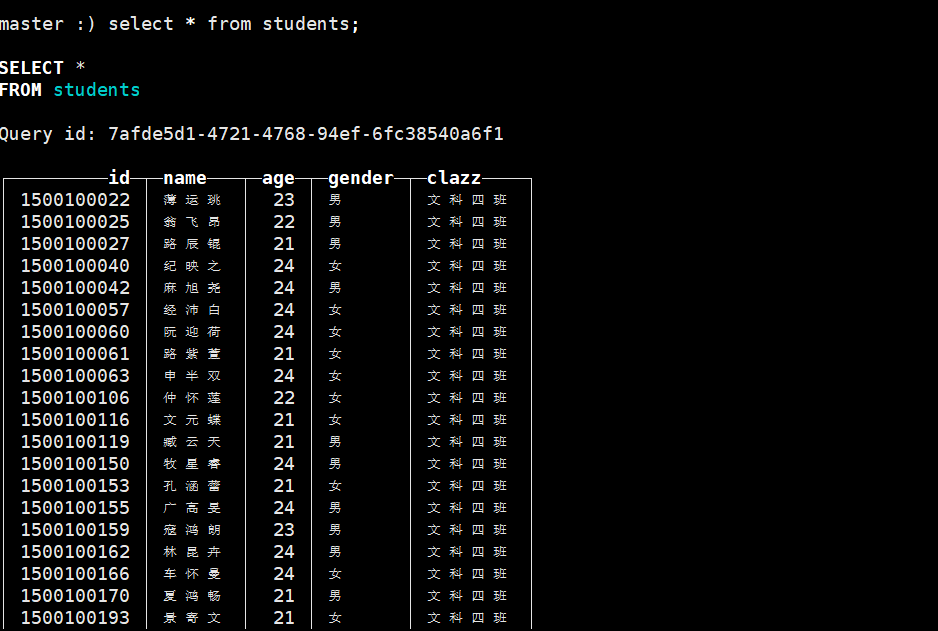
在ck中建一张表
sql
create table bigdata30.students
(
id Int32,
name String,
age Int32,
gender String,
clazz String
) ENGINE = MergeTree() order by id PARTITION BY clazz;使用命令将数据导入
sh
cat students.csv | clickhouse-client --port 9001 --user default --password 123456 --database=bigdata30 --query="INSERT INTO students FORMAT CSV"查询数据 按学号排序 相同的班级在一块
关联hive表数据
Hive引擎允许对HDFS Hive表执行
SELECT查询。目前它支持如下输入格式:-文本:只支持简单的标量列类型,除了
Binary
- ORC:支持简单的标量列类型,除了
char; 只支持array这样的复杂类型- Parquet:支持所有简单标量列类型;只支持
array这样的复杂类型
在hive中建表
sql
CREATE TABLE `bigdata30`.`test_text`(
`f_tinyint` tinyint,
`f_smallint` smallint,
`f_int` int,
`f_integer` int,
`f_bigint` bigint,
`f_float` float,
`f_double` double,
`f_decimal` decimal(10,0),
`f_timestamp` timestamp,
`f_date` date,
`f_string` string,
`f_varchar` varchar(100),
`f_char` char(100),
`f_bool` boolean,
`f_binary` binary,
`f_array_int` array<int>,
`f_array_string` array<string>,
`f_array_float` array<float>,
`f_array_array_int` array<array<int>>,
`f_array_array_string` array<array<string>>,
`f_array_array_float` array<array<float>>)
PARTITIONED BY (
`day` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://master:9000/user/hive/warehouse/bigdata30.db/test_text';
# 插入数据
insert into bigdata30.test_text partition(day='2024-06-26') select 1, 2, 3, 4, 5, 6.11, 7.22, 8.333, current_timestamp(), current_date(), 'hello world', 'hello world', 'hello world', true, 'hello world', array(1, 2, 3), array('hello world', 'hello world'), array(float(1.1), float(1.2)), array(array(1, 2), array(3, 4)), array(array('a', 'b'), array('c', 'd')), array(array(float(1.11), float(2.22)), array(float(3.33), float(4.44)));
#查询数据
select * from test.test_text;
在ck中建表
sql
CREATE TABLE bigdata30.test_text
(
`f_tinyint` Int8,
`f_smallint` Int16,
`f_int` Int32,
`f_integer` Int32,
`f_bigint` Int64,
`f_float` Float32,
`f_double` Float64,
`f_decimal` Float64,
`f_timestamp` DateTime,
`f_date` Date,
`f_string` String,
`f_varchar` String,
`f_char` String,
`f_bool` Bool,
`day` String
)
ENGINE = Hive('thrift://master:9083', 'bigdata30', 'test_text')
PARTITION BY day 发现在ck test_text表中出现于hive表中一样的数据
