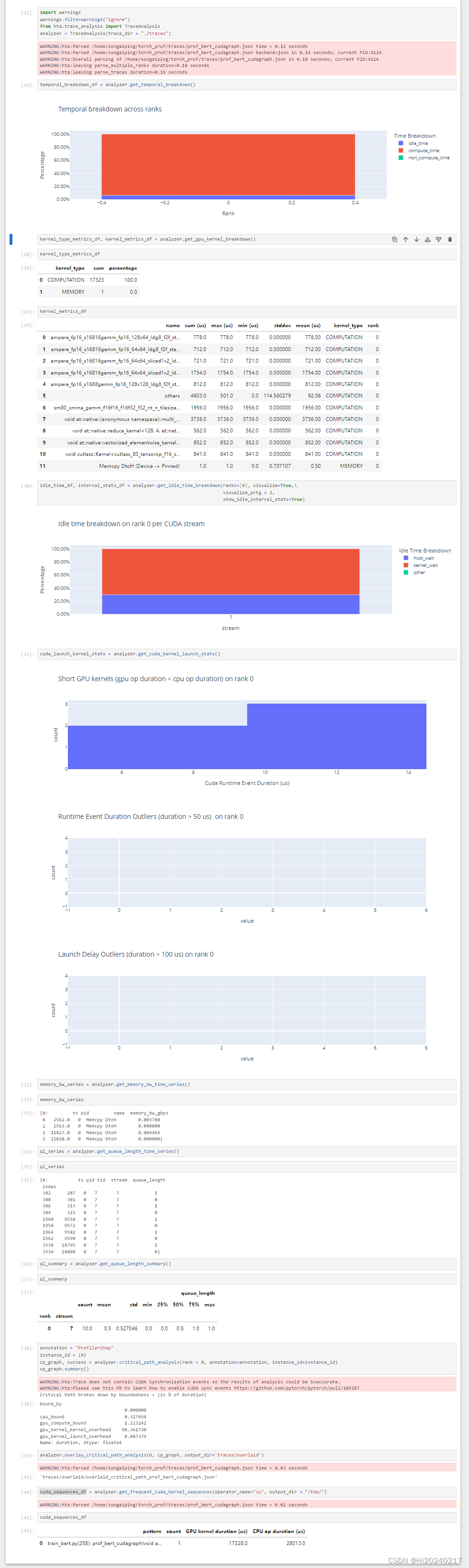
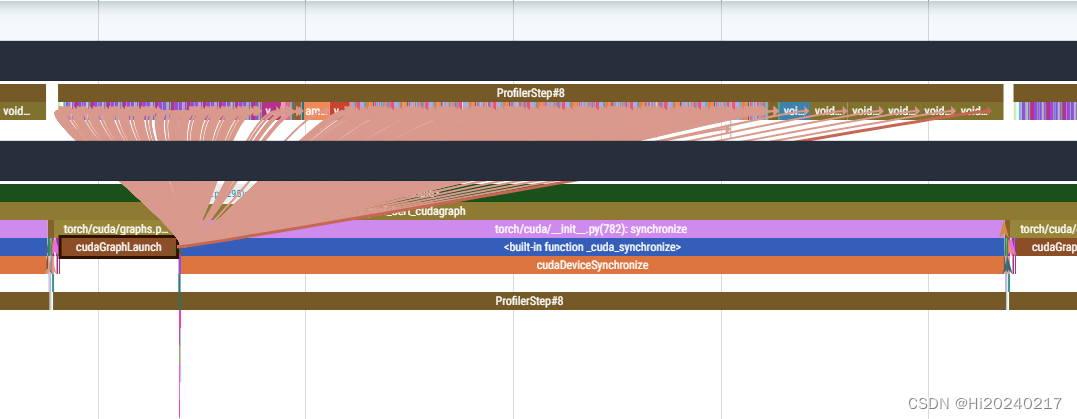
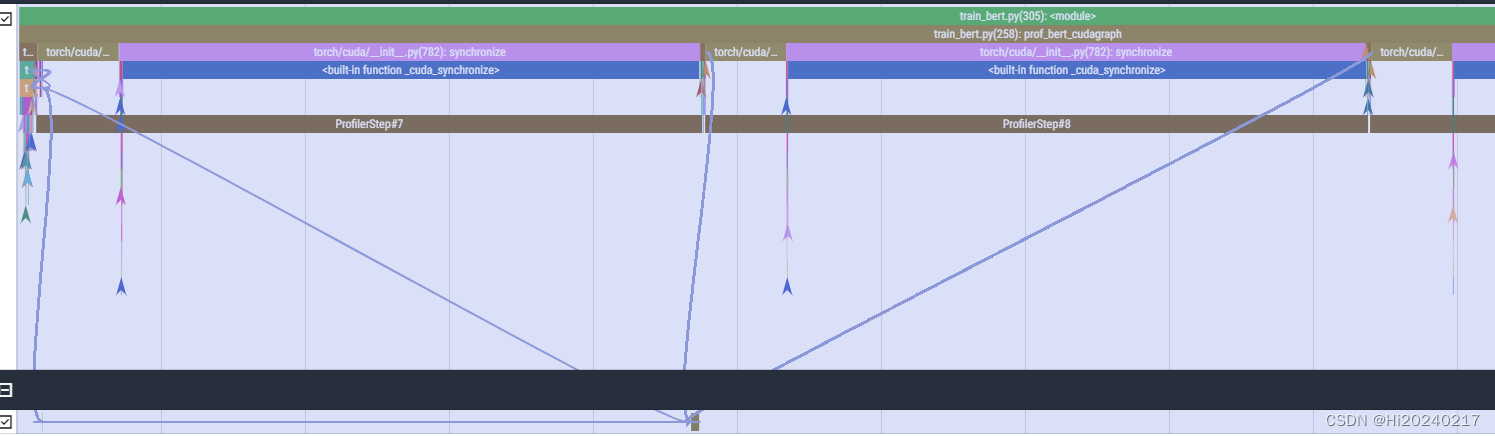
以Bert训练为例,测试torch不同的运行方式,并用torch.profile+HolisticTraceAnalysis分析性能瓶颈
以Bert训练为例,测试torch不同的运行方式,并用torch.profile+HolisticTraceAnalysis分析性能瓶颈
1.参考链接:
2.性能对比
| 序号 | 运行方式 | build耗时(s) | warmup耗时(s) | 运行耗时(w) | 备注 |
|---|---|---|---|---|---|
| 1 | 普通模式 | 0.70 | max:0.0791 min:0.0358 std:0.0126 mean:0.0586 | CPU Bound | |
| 2 | torch.cuda.CUDAGraph() | 0.01 | max:0.0109 min:0.0090 std:0.0006 mean:0.0094 | Kernel Bound | |
| 3 | torch.compile("cudagraphs") | 0.7126 | 10.7256 | max:3.9467 min:0.0197 std:1.1683 mean:0.4590 | |
| 4 | torch.compile("inductor") | 0.0005 | 45.1444 | max:5.9465 min:0.0389 std:1.7684 mean:0.6415 |
3.相关依赖或命令
bash
# 安装pytorch
pip install torch==2.3.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
# 安装HTA
git clone https://github.com/facebookresearch/HolisticTraceAnalysis.git
cd HolisticTraceAnalysis
git submodule update --init
pip install -r requirements.txt
pip install -e .
# 运行jupyter
pip install jupyter
jupyter notebook --allow-root --no-browser --ip=192.168.1.100 --port 80804.测试代码
python
import os
import warnings
warnings.filterwarnings("ignore")
import copy
import sys
import torch
from tqdm import tqdm
from torch.profiler import profile
import time
from typing import Final, Any, Callable
import random
import numpy as np
import os
import requests
import importlib.util
import sys
import json
def download_module(url, destination_path):
response = requests.get(url)
response.raise_for_status()
with open(destination_path, 'wb') as f:
f.write(response.content)
def module_from_path(module_name, file_path):
spec = importlib.util.spec_from_file_location(module_name, file_path)
module = importlib.util.module_from_spec(spec)
sys.modules[module_name] = module
spec.loader.exec_module(module)
return module
def load_or_download_module(module_url, module_name, cache_dir=".cache"):
if not os.path.exists(cache_dir):
os.makedirs(cache_dir)
destination_path = os.path.join(cache_dir, module_name + ".py")
if not os.path.isfile(destination_path):
download_module(module_url, destination_path)
module = module_from_path(module_name, destination_path)
return module
import sys
sys.path.append(".cache/")
module_url = "https://raw.githubusercontent.com/NVIDIA/DeepLearningExamples/master/PyTorch/LanguageModeling/BERT/file_utils.py"
module_name = "file_utils"
load_or_download_module(module_url, module_name)
module_url = "https://raw.githubusercontent.com/NVIDIA/DeepLearningExamples/master/PyTorch/LanguageModeling/BERT/modeling.py"
module_name = "modeling"
modeling = load_or_download_module(module_url, module_name)
def fix_gelu_bug(fn):
def wrapper(tensor, *args, **kwargs):
return fn(tensor)
return wrapper
torch.nn.functional.gelu=fix_gelu_bug(torch.nn.functional.gelu)
class SyncFreeStats :
def __init__(self) :
self.host_stats = {}
self.device_stats = {}
self.device_funcs = {}
def add_stat(self, name, dtype=torch.int32, device_tensor=None, device_func=None) :
if device_tensor is not None :
assert dtype == device_tensor.dtype, "Error: dtype do not match: {} {}".format(dtype, device_tensor.dtype)
self.host_stats[name] = torch.zeros(1, dtype=dtype).pin_memory()
self.device_stats[name] = device_tensor
self.device_funcs[name] = device_func
def copy_from_device(self) :
for name in self.host_stats.keys() :
# Apply device function to device stat
if self.device_stats[name] is not None and self.device_funcs[name] is not None:
self.host_stats[name].copy_(self.device_funcs[name](self.device_stats[name]), non_blocking=True)
elif self.device_stats[name] is not None :
self.host_stats[name].copy_(self.device_stats[name], non_blocking=True)
elif self.device_funcs[name] is not None :
self.host_stats[name].copy_(self.device_funcs[name](), non_blocking=True)
def host_stat(self, name) :
assert name in self.host_stats
return self.host_stats[name]
def host_stat_value(self, name) :
assert name in self.host_stats
return self.host_stats[name].item()
def update_host_stat(self, name, tensor) :
self.host_stats[name] = tensor
def device_stat(self, name) :
assert self.device_stats[name] is not None
return self.device_stats[name]
def update_device_stat(self, name, tensor) :
self.device_stats[name] = tensor
class BertPretrainingCriterion(torch.nn.Module):
sequence_output_is_dense: Final[bool]
def __init__(self, vocab_size, sequence_output_is_dense=False):
super(BertPretrainingCriterion, self).__init__()
self.loss_fn = torch.nn.CrossEntropyLoss(ignore_index=-1)
self.vocab_size = vocab_size
self.sequence_output_is_dense = sequence_output_is_dense
def forward(self, prediction_scores, seq_relationship_score, masked_lm_labels, next_sentence_labels):
if self.sequence_output_is_dense:
# prediction_scores are already dense
masked_lm_labels_flat = masked_lm_labels.view(-1)
mlm_labels = masked_lm_labels_flat[masked_lm_labels_flat != -1]
masked_lm_loss = self.loss_fn(prediction_scores.view(-1, self.vocab_size), mlm_labels.view(-1))
else:
masked_lm_loss = self.loss_fn(prediction_scores.view(-1, self.vocab_size), masked_lm_labels.view(-1))
next_sentence_loss = self.loss_fn(seq_relationship_score.view(-1, 2), next_sentence_labels.view(-1))
total_loss = masked_lm_loss + next_sentence_loss
return total_loss
def setup_model_optimizer_data(device="cuda"):
train_batch_size=1
max_seq_length=128
config=modeling.BertConfig(21128)
sequence_output_is_dense=False
model = modeling.BertForPreTraining(config, sequence_output_is_dense=sequence_output_is_dense)
model=model.half()
model.train().to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
criterion = BertPretrainingCriterion(config.vocab_size, sequence_output_is_dense=sequence_output_is_dense).to(device)
batch = {
'input_ids': torch.ones(train_batch_size, max_seq_length, dtype=torch.int64, device=device),
'token_type_ids': torch.ones(train_batch_size, max_seq_length, dtype=torch.int64, device=device),
'attention_mask': torch.ones(train_batch_size, max_seq_length, dtype=torch.int64, device=device),
'labels': torch.ones(train_batch_size, max_seq_length, dtype=torch.int64, device=device),
'next_sentence_labels': torch.ones(train_batch_size, dtype=torch.int64, device=device),
}
stats = SyncFreeStats()
stats.add_stat('average_loss', dtype=torch.float32, device_tensor=torch.zeros(1, dtype=torch.float32, device=device))
return model,optimizer,criterion,batch,stats
def train_step(model,optimizer,criterion,batch,stats):
optimizer.zero_grad(set_to_none=True)
prediction_scores,seq_relationship_score=model(input_ids=batch['input_ids'],
token_type_ids=batch['token_type_ids'],
attention_mask=batch['attention_mask'],
masked_lm_labels=batch['labels'])
loss = criterion(prediction_scores, seq_relationship_score, batch['labels'], batch['next_sentence_labels'])
stats.device_stat('average_loss').add_(loss.detach())
loss.backward()
optimizer.step()
def reset_seed():
random.seed(0)
np.random.seed(0)
torch.manual_seed(0)
torch.cuda.manual_seed(0)
def stat(data):
return f"max:{np.max(data):.4f} min:{np.min(data):.4f} std:{np.std(data):.4f} mean:{np.mean(data):.4f}"
def prof_bert_native():
reset_seed()
activities=[torch.profiler.ProfilerActivity.CPU]
activities.append(torch.profiler.ProfilerActivity.CUDA)
model,optimizer,criterion,batch,stats=setup_model_optimizer_data()
t0=time.time()
train_step(model,optimizer,criterion,batch,stats)
torch.cuda.synchronize()
t1=time.time()
print(f"warmup:{t1-t0:.2f}")
latency=[]
with profile(activities=activities,record_shapes=True,
with_stack=True,with_modules=True,
schedule=torch.profiler.schedule(wait=1,warmup=1,active=3,repeat=0),
with_flops=True,profile_memory=True) as prof:
for i in range(10):
t0=time.time()
train_step(model,optimizer,criterion,batch,stats)
torch.cuda.synchronize()
t1=time.time()
latency.append(t1-t0)
prof.step()
stats.copy_from_device()
print(f"native average_loss:{stats.host_stat_value('average_loss'):.4f} {stat(latency)}")
prof.export_chrome_trace("prof_bert_native.json")
def prof_bert_cudagraph():
reset_seed()
activities=[torch.profiler.ProfilerActivity.CPU]
activities.append(torch.profiler.ProfilerActivity.CUDA)
model,optimizer,criterion,batch,stats=setup_model_optimizer_data()
# Warmup Steps - includes jitting fusions
side_stream = torch.cuda.Stream()
side_stream.wait_stream(torch.cuda.current_stream())
with torch.cuda.stream(side_stream):
for _ in range(11):
train_step(model,optimizer,criterion,batch,stats)
torch.cuda.current_stream().wait_stream(side_stream)
# Capture Graph
full_cudagraph = torch.cuda.CUDAGraph()
with torch.cuda.graph(full_cudagraph):
train_step(model,optimizer,criterion,batch,stats)
print("build done")
t0=time.time()
full_cudagraph.replay()
torch.cuda.synchronize()
t1=time.time()
print(f"warmup:{t1-t0:.2f}")
latency=[]
with profile(activities=activities,record_shapes=True,
with_stack=True,with_modules=True,
schedule=torch.profiler.schedule(wait=1,warmup=1,active=3,repeat=0),
with_flops=True,profile_memory=True) as prof:
for i in range(10):
t0=time.time()
full_cudagraph.replay()
torch.cuda.synchronize()
t1=time.time()
latency.append(t1-t0)
prof.step()
stats.copy_from_device()
print(f"cudagraph average_loss:{stats.host_stat_value('average_loss'):.4f} {stat(latency)}")
prof.export_chrome_trace("prof_bert_cudagraph.json")
def prof_bert_torchcompiler(backend):
reset_seed()
activities=[torch.profiler.ProfilerActivity.CPU]
activities.append(torch.profiler.ProfilerActivity.CUDA)
model,optimizer,criterion,batch,stats=setup_model_optimizer_data()
latency=[]
t0=time.time()
new_fn = torch.compile(train_step, backend=backend)
t1=time.time()
print(f"torchcompiler_{backend} build:{t1-t0:.4f}s")
new_fn(model,optimizer,criterion,batch,stats)
torch.cuda.synchronize()
t2=time.time()
print(f"torchcompiler_{backend} warmup:{t2-t1:.4f}s")
with profile(activities=activities,record_shapes=True,
with_stack=True,with_modules=True,
schedule=torch.profiler.schedule(wait=1,warmup=1,active=3,repeat=0),
with_flops=True,profile_memory=True) as prof:
for i in range(10):
t0=time.time()
new_fn(model,optimizer,criterion,batch,stats)
torch.cuda.synchronize()
t1=time.time()
latency.append(t1-t0)
prof.step()
stats.copy_from_device()
print(f"torchcompiler_{backend} average_loss:{stats.host_stat_value('average_loss'):.4f} {stat(latency)}")
prof.export_chrome_trace(f"prof_bert_torchcompiler_{backend}.json")
os.environ['LOCAL_RANK']="0"
os.environ['RANK']="0"
os.environ['WORLD_SIZE']="1"
os.environ['MASTER_ADDR']="localhost"
os.environ['MASTER_PORT']="6006"
import torch.distributed as dist
dist.init_process_group(backend='nccl')
rank=torch.distributed.get_rank()
prof_bert_native()
prof_bert_cudagraph()
prof_bert_torchcompiler("cudagraphs")
prof_bert_torchcompiler("inductor")5.HolisticTraceAnalysis代码
python
#!/usr/bin/env python
# coding: utf-8
# In[25]:
import warnings
warnings.filterwarnings("ignore")
from hta.trace_analysis import TraceAnalysis
analyzer = TraceAnalysis(trace_dir = "./traces")
# In[26]:
temporal_breakdown_df = analyzer.get_temporal_breakdown()
# kernel_type_metrics_df, kernel_metrics_df = analyzer.get_gpu_kernel_breakdown()
# In[28]:
kernel_type_metrics_df
# In[29]:
kernel_metrics_df
# In[30]:
idle_time_df, interval_stats_df = analyzer.get_idle_time_breakdown(ranks=[0], visualize=True,\
visualize_pctg = 1,
show_idle_interval_stats=True)
# In[31]:
cuda_launch_kernel_stats = analyzer.get_cuda_kernel_launch_stats()
# In[32]:
memory_bw_series = analyzer.get_memory_bw_time_series()
# In[33]:
memory_bw_series
# In[34]:
ql_series = analyzer.get_queue_length_time_series()
# In[35]:
ql_series
# In[36]:
ql_summary = analyzer.get_queue_length_summary()
# In[37]:
ql_summary
# In[38]:
annotation = "ProfilerStep"
instance_id = (0)
cp_graph, success = analyzer.critical_path_analysis(rank = 0, annotation=annotation, instance_id=instance_id)
cp_graph.summary()
# In[39]:
analyzer.overlay_critical_path_analysis(0, cp_graph, output_dir='traces/overlaid')
# In[40]:
cuda_sequences_df = analyzer.get_frequent_cuda_kernel_sequences(operator_name="cu", output_dir = "/tmp/")
# In[42]:
cuda_sequences_df6.可视化
A.优化前
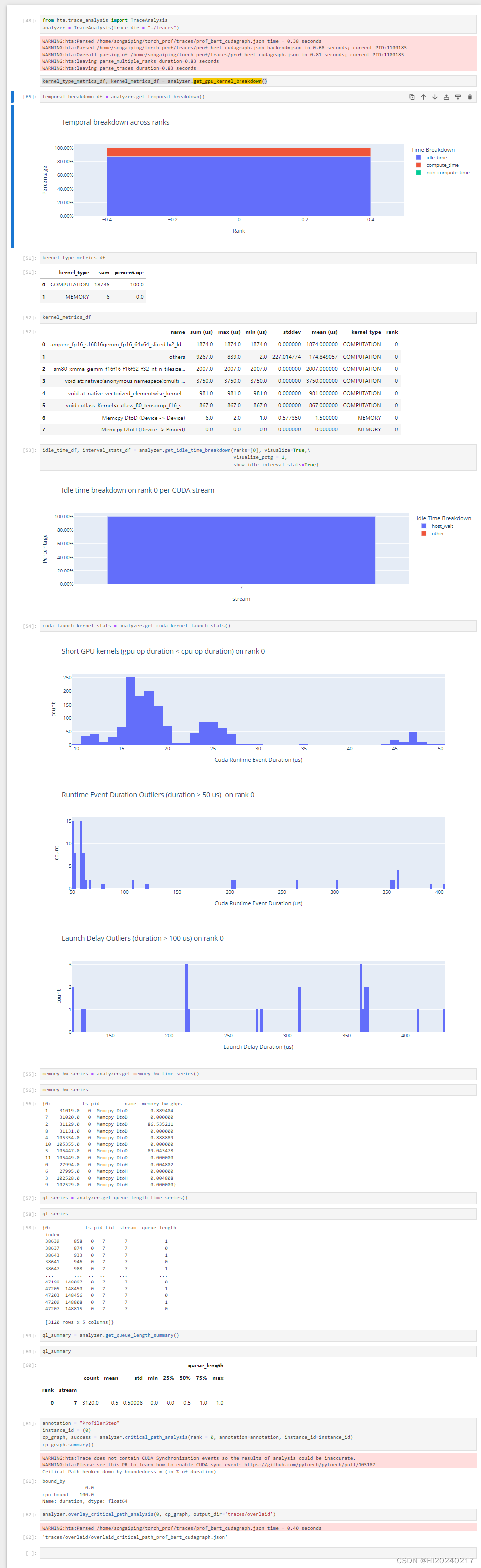
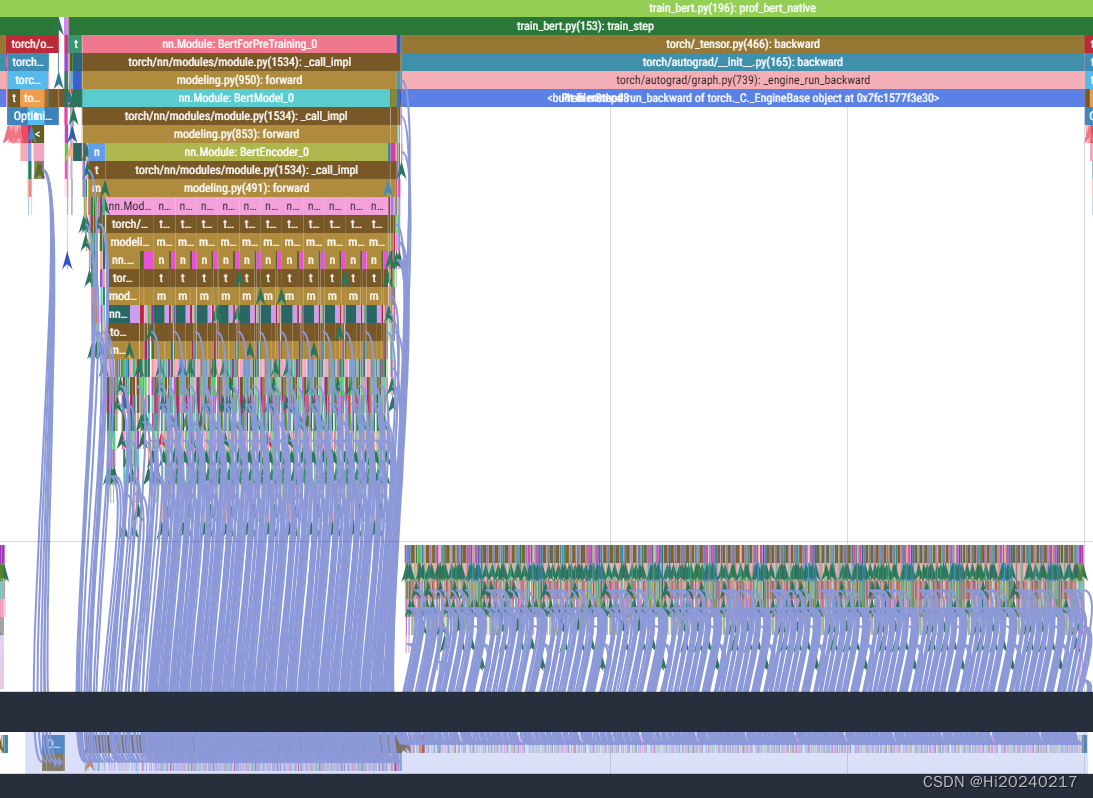
B.优化后