用来实现数据的恢复,数据被更新到缓冲区但没刷磁盘,然后MySQL宕机了,MySQL会通过日志恢复数据。
1.为什么需要Redo-log日志?
MySQL绝大部分引擎都是基于磁盘存储数据的,每次读写数据都走磁盘,效率十分低下,InnoDB引擎在设计时,当MySQL启动后就会在内存中创建一个BufferPool,运行过程中会将大量操作汇集在内存中进行,比如写入数据时,先写到内存中,然后由后台线程再刷写到磁盘。
使用BufferPool提升了MySQL整体的读写性能,但它是基于内存的,意味着随着机器的宕机、重启,其中保存的数据会消失,那当一个事务向内存中写入数据后,突然宕机了未刷写到磁盘的数据就会丢失,这违背了事务ACID原则中的持久性,所以Redo-log的出现就是为了解决该问题,
Redo-log是一种预写式日志,即在向内存写入数据前,会先写日志,当后续数据未被刷写到磁盘、MySQL崩溃时,就可以通过日志来恢复数据,确保所有提交的事务都会被持久化。
2. Redo-log的刷盘策略
刷盘的时机由 innodb_flush_log_at_trx_commit 参数来控制,默认是处于第二个级别,也就是每次提交事务时都会刷盘,这也就意味着一个事务执行成功后,相应的Redo-log日志绝对会被刷写到磁盘中,因此无需担心会出现丢失风险。
3. Redo-log 为什么多此一举
先刷写一次Redo-log日志到磁盘,后台线程再根据Redo-log日志把数据落盘,这样做好处很大:
- 日志比数据先落入磁盘,就算MySQL崩溃也可以通过日志恢复数据。
- 写日志时是以追加形式写到末尾,而写数据时则是计算数据位置,随机插入。
写日志的时候,只需要将记录追加到日志文件的尾部即可,这是按顺序写入,但写入表数据时,还需要先先计算数据的位置,比如修改一条数据时,需要先判断这条数据在磁盘文件中的那个位置,找到了位置再写入,这是随机写入,顺序写入的速度会比随机写入快很多很多。
所以写日志会比写数据落盘快,因此日志落盘后返回,比数据落盘后返回要快,对于客户端而言,响应时间会更短。
4. Redo-log相关的参数
Redo-log日志中,较为重要的系统参数:
- innodb_flush_log_at_trx_commit:设置redo_log_buffer的刷盘策略,默认每次提交事务都刷盘。
- innodb_log_group_home_dir:指定redo-log日志文件的保存路径,默认为./。
- innodb_log_buffer_size:指定redo_log_buffer缓冲区的大小,默认为16MB。
- innodb_log_files_in_group:指定redo日志的磁盘文件个数,默认为2个。
- innodb_log_file_size:指定redo日志的每个磁盘文件的大小限制,默认为48MB。
Redo-log的本地磁盘文件个数是两个,MySQL通过来回写这两个文件的形式记录Redo-log日志,用两个日志文件组成一个"环形",如下:
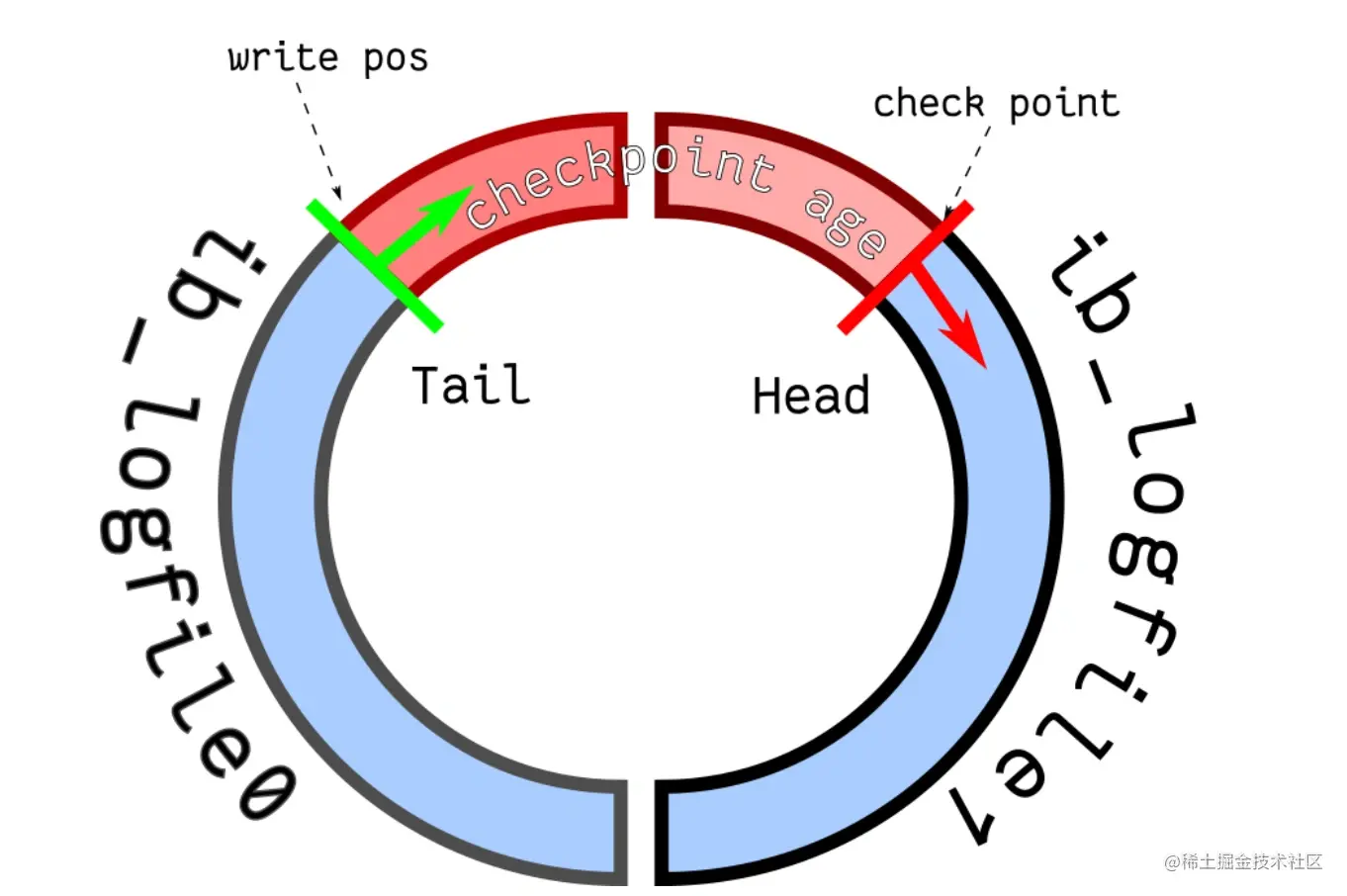
- write pos:这根指针用来表示当前Redo-log文件写到了哪个位置。
- check point:这根指针表示目前哪些Redo-log记录已经失效且可以被擦除(覆盖)。
当一个事务写了redo-log日志、并将数据写入缓冲区后,但数据还未写到本地的表数据文件中,此时这个事务对应的redo-log记录就为上图中的蓝色,而当一个事务所写的数据也落盘后,对应的redo-log记录就会变为红色。
当write pos指针追上check point指针时,红色区域就会消失,也就代表Redo-log文件满了,再当MySQL执行写操作时就会被阻塞,因为无法再写入redo-log日志了,所以会触发checkpoint刷盘机制,将redo-log记录对应的事务数据,全部刷写到磁盘中的表数据文件后,阻塞的写事务才能继续执行。
关于checkpoint机制的系统参数:
- innodb_log_write_ahead_size:设置checkpoint刷盘机制每次落盘动作的大小,默认为8K,如果要设置,必须要为4k的整数倍,这跟read-on-write问题有关。
- innodb_log_compressed_pages:是否对Redo日志开启页压缩机制,默认ON,这跟InnoDB的页压缩技术有关。
- innodb_log_checksums:Redo日志完整性效验机制,默认开启,必须要开启,否则有可能刷写数据时,只刷一半,出现类似于"网络粘包"的问题。