上一章讲到了RAG的基本流程,但是如果只是完成一个基本流程,想要在商业上使用还是不行,因为正常商业上的使用其准确度至少有个90%甚至更高。那么如何提高RAG的准确度,那么需要看看RAG有哪些关键点。
目录
- [1 RAG结构图](#1 RAG结构图)
- [2 文档处理](#2 文档处理)
- [3 问题优化](#3 问题优化)
- [4 总结](#4 总结)
1 RAG结构图
在上一章中展现了一个最基本的RAG流程图,其实主要是想让你了解RAG的工作模式以及最基本包含的组件,下面的图让你更为细节的了解一个RAG架构的可能性:
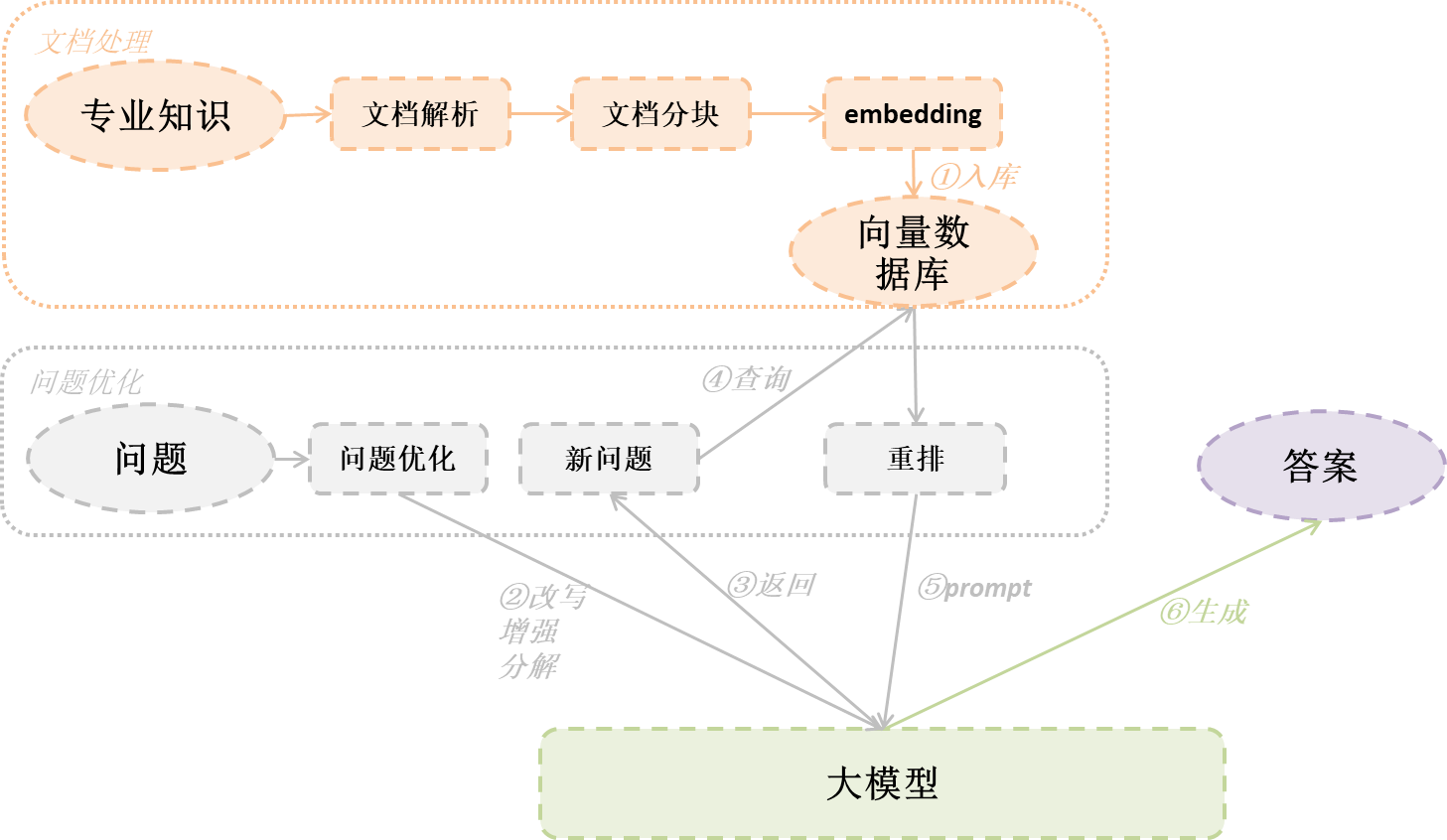
从上图可以看出更为详细的RAG过程中的步骤,我们可以总结为2个大方面对RAG的准确性提高有着举足轻重的影响,后续也会根据这2个大的方面改进做一些详细代码实现,本章先通过简单介绍每个模块作用和如何对RAG产生影响的。
- 文档处理:包括文档解析、文档分块、文档embedding、向量数据库等
- 问题优化:通过改写问题、增强问题、分解问题、重排等手段,使得问题更匹配知识库
下面就通过这2个大方面来分别说明为什么这些内容是提高RAG准确度的关键点。
2 文档处理
我们能够从上图看到,文档处理包括很重要的3个部分:文档解析、文档分块、文档embedding。
- 文档解析:我们需要查询的文档可能包括pdf、Excel、图片等等各种各样的内容,而这些内容中包括很多不同的格式,比如pdf中可能还包括表格和图片,因此选择哪些文档解析工具非常重要。目前市面上有很多工具,如PyPDF、LlamaParse、Firecrawl等等。关于使用哪些解析工具解析哪些文档,这方面在系列3中详细讲解。
- 文档分块:之所以要分块是因为2个原因,第一个是因为大模型有token长度限制,第二是过长的token其实对于大模型的理解和推理会变慢或者不准确。因此需要适当的对文档进行分块,有可能分块会将原先有关联的一句话给分隔开了,这样对RAG的检索结果就会不准确甚至找不到答案。因此如何分块或者该分块多大才是最优解,这些也在系列3中详细讲解,这里只是说明文档的分块对于RAG的准确度也是影响较大的。
- 文档embedding:文档最终是向量化后存入向量数据库,然后通过query方式查询问题与答案的相似度来获取top_n的数据,再交于大模型去返回最终答案。这里要注意的是embedding也是一个可训练的模型或者已经训练完成的模型。那么有可能embedding模型做得不好,导致查询的结果与答案不一致。那么如何选对一个embedding模型也是对于RAG的准确度至关重要,这些也在系列3中详细讲解。
- 向量数据库:向量数据库需要存储向量化后的数据,然后通过问题查询相似度,得到最终相关的几个答案,扔给大模型进行回答。那么向量数据库的存储和相似度查询就可能会影响RAG最终的结果,因此,我们选择哪一种向量数据库,对于我们来说还是比较重要的。
3 问题优化
我们能够从上图看到,问题优化包括改写、增强、分解等措施。那么先说一下为什么要对问题优化。其实很好理解,你在使用大模型的时候,经常使用优化prompt的方式让大模型能够返回你想要的答案,那么对于问题优化也是同样的道理,可能造成的原因是用户表达不准确、问题和文档不在一个语义空间或者可能问题需要拆解多步等等。那么对于RAG来说,对于问题优化包括以下内容:
- 问题改写:可能提问的不是很准确,让大模型或者其它技术给你的问题进行改写,这样能够提高问题的准确性,使得查询结果相关性更高
- 问题增强:增强可能比较难以理解,其实就是通过某些技术让模型更能理解你这句话,比如使用假设性回答去找答案或者通过抽象问题去检索等等
- 问题分解:很明显是对于需要针对多步解决的问题,这时候对问题进行分解有利于得到更准确的答案,比如将问题分解为更小更简单的问题或者利用生成和检索不断交替等方法去优化问题
- 重排:前面提到过可能根据改写、增强等方式对问题进行优化,有可能是生成多个不同角度问题,再做多次查询,获得最终查询结果。但是最终的查询结果需要进行一个相关性的排序,因为有可能数据过多,需要过滤掉一些,也有可能获取的数据相关性不一。因此对于返回结果进行重排也是能够提高RAG的准确度
以上是对于问题优化为什么能够提高RAG的准确度进行简单的概述,优化手段将在本系列4中详细讲解。
4 总结
本章中我们通过更为详细的描述RAG整体架构流程图,并一一分析了里面对于RAG准确度的影响。其实主要包括2部分:文档处理 和问题优化。接下来几章可能真的这些部分做出详细的一些优化策略的解决方案,同时也会总结一些实战经验。