GANDALF:主动学习 + 图注意力变换器 + 变分自编码器,改善多标签图像分类
提出背景
论文:GANDALF: Graph-based transformer and Data Augmentation Active Learning Framework with interpretable features for multi-label chest Xray classification
代码:https://github.com/mlcommons/GaNDLF
目的:GaNDLF旨在通过合成训练数据的方式,提高多标签医学图像分类任务的学习效率和分类性能。
解法拆解:
- 多标签信息样本的选择(因为标签间的相互影响) +
- 生成信息丰富且非冗余的合成样本(因为训练样本的多样性和信息量)
子解法1:多标签信息样本的选择
- 特征:在多标签学习场景中,不同疾病标签之间的相互影响可能会影响模型的判断和学习。
- 解法说明:通过构建一个图形模型,每个节点代表一个疾病标签的显著图,节点之间的边代表不同标签之间的相互关系。使用图转换器来评估和选择具有高度信息交互的样本,从而更有效地捕获多标签之间的复杂关系。
- 例子:在胸部X射线图像中,某些疾病(如肺炎和肺结核)可能表现出相似的影像特征。有效地识别和利用这些相互关系可以帮助模型区分这些相似的疾病,提高诊断的准确性。
子解法2:生成信息丰富且非冗余的合成样本
- 特征:仅靠原始的训练样本,可能不足以覆盖所有的特征变异,限制了模型的泛化能力。
- 解法说明:使用变分自编码器(VAE)从选定的信息丰富样本中生成新的合成图像。这些新图像不仅保持原有的类标签,还引入了新的变化,增加了数据的多样性,同时避免了信息的冗余。
- 例子:如果原始数据集中大部分图像展示的是早期肺炎,通过合成技术可以生成展示更多不同阶段和表现形式的肺炎图像,这样模型可以学习到肺炎在不同阶段的多样性,提高识别不同阶段肺炎的能力。
这两种子解法结合,通过在样本选择和数据增强中都注重信息的多样性和质量,为多标签分类任务提供了一种更有效的学习策略。
例子:胸部X射线图像分析
医疗研究人员需要对胸部X射线图像进行分类,识别图中可能存在的多种疾病(如肺炎、肺结核、肺癌等)。
传统方法的操作和局限
- 数据集:使用一个固定的、预先标注的数据集,其中可能缺乏某些疾病的表现形式多样性。
- 数据增强:应用基本的图像处理技术(如翻转、旋转),这些技术虽然增加了图像数量,但并未实质增加关于疾病特征的新信息。
- 样本选择:随机或基于简单规则选择样本,这可能导致关键信息样本被忽略,从而影响模型的准确性和泛化能力。
GaNDLF方法的优势
- 动态样本选择 :
- 使用图注意力变换器(GAT)分析未标记的胸部X射线图像,根据疾病标签间的相互影响动态选择信息量最大的样本。例如,如果系统发现某些图像中肺炎和肺结核的特征同时显著,它会优先选择这些样本进行训练,因为这样的样本能帮助模型更好地学习区分具有相似表现的不同疾病。
- 高级数据增强 :
- 利用变分自编码器(VAE)根据选定的高信息量样本生成新的图像。这些合成图像在保留原有疾病标签的同时,引入了新的变体(如不同阶段的病变),从而丰富了模型的训练数据。例如,对于初始阶段肺炎的图像,VAE可以生成显示肺炎后期更严重病变的图像,这有助于模型学习识别疾病的不同阶段。
- 减少冗余,确保新增样本的质量 :
- 通过结合标签保持评分和避免冗余评分,确保生成的样本在增加新信息的同时,避免与已有训练样本重复。这一策略确保了每一个新增样本都能为模型训练提供真正的价值。
结果比较:
- 传统方法可能导致模型在遇到未包含在初始数据集中的疾病变异时性能下降。
- GaNDLF方法通过提供更广泛的病变样本和更精确的样本选择,显著提高了模型的诊断准确性和泛化能力。
通过这个例子,我们可以看到GaNDLF方法不仅使模型训练更为有效,还增强了模型在实际应用中的可靠性和准确性。
工作流程
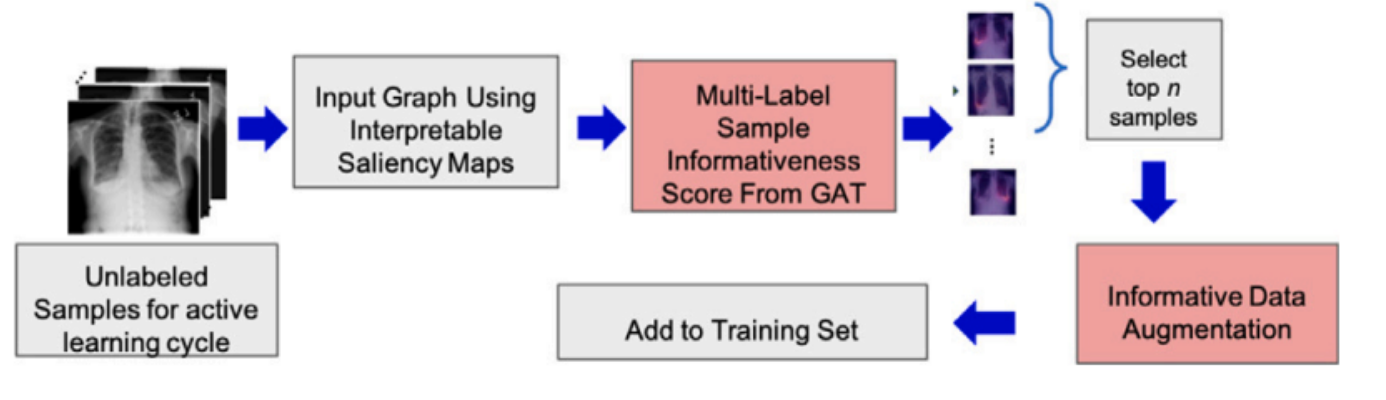
此图展示了GANDALF方法的整体工作流程:
- 未标记样本:从一个可用于主动学习周期的未标记样本池开始。
- 使用可解释显著图创建输入图:显著图用于创建输入图。这些图突出显示图像中对分类最关键的区域。
- 来自GAT(图注意力变换器)的多标签样本信息评分:然后使用图注意力变换器处理图,根据图中表示的标签间互动评估每个样本的信息量。
- 选择顶尖n个样本:选择最具信息量的样本。
- 信息数据增强:选定的样本用于生成合成且具有信息量的样本,这些样本对训练数据进行了非冗余的增强。
- 添加到训练集:原始样本和新生成的合成样本都被添加到训练集中,用于下一个主动学习周期。
一个医疗研究中心希望通过机器学习模型提高其对胸部X射线图像中多种疾病(如肺炎、肺结核和肺癌)的自动诊断能力。
GANDALF方法的操作步骤:
-
未标记样本:
- 医院收集了大量的胸部X射线图像,这些图像尚未进行疾病标记。这些未标记的样本构成了主动学习周期的样本池。
-
使用可解释显著图创建输入图:
- 研究人员使用计算机视觉技术分析每张X射线图像,创建显著图。这些显著图突出显示了图像中对于诊断最为关键的区域,如异常阴影或肺部结构变化。
-
来自GAT的多标签样本信息评分:
- 利用图注意力变换器(GAT),分析由显著图构建的图形数据。GAT评估不同疾病标签在显著区域间的互动和联系,识别出潜在的复合疾病特征,计算每个样本的信息量。
-
选择顶尖n个样本:
- 系统根据信息评分选择信息量最大的前n个样本,这些样本表现出高度的疾病特征复杂性和诊断价值。
-
信息数据增强:
- 选定的信息丰富样本被用于生成新的合成样本。使用变分自编码器(VAE)在保持原有疾病标签的同时引入图像变体,如模拟疾病的不同发展阶段或轻微的解剖差异。
-
添加到训练集:
- 原始的信息丰富样本及其合成的衍生样本都被添加到训练集中。这些数据将用于训练和优化机器学习模型,模型随后在下一个主动学习周期中更精准地诊断和识别复杂的疾病模式。
通过GANDALF方法,该医疗中心的机器学习模型能够更有效地识别和分类胸部X射线图像中的多种疾病。
模型不仅学习从单一病变中识别疾病,还能识别多疾病共存的复杂情况,大大提高了诊断的准确性和效率。
图多集合变换器
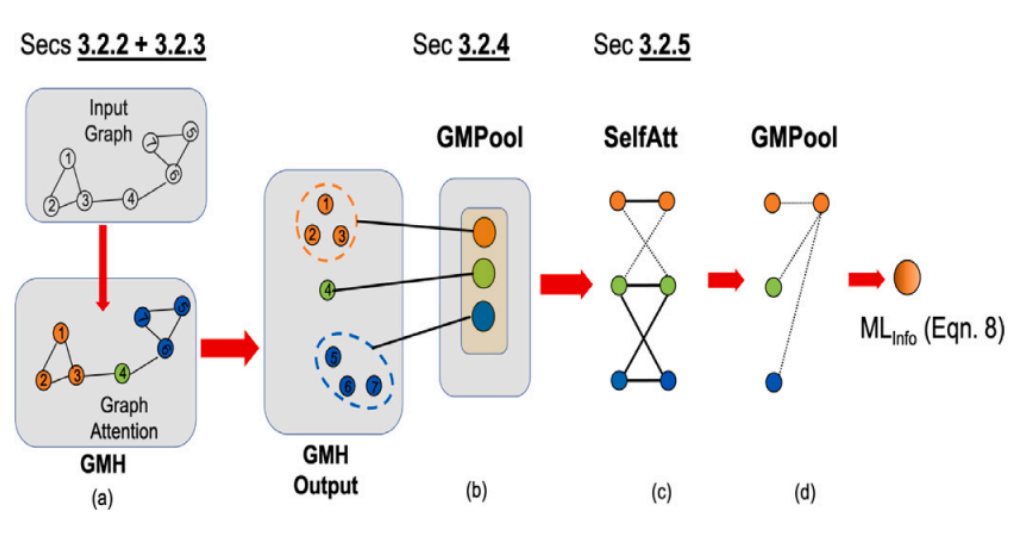
此图详细说明了GANDALF方法中使用的图多集合变换器的过程和组件:
- 输入图:显示基于样本的多标签信息的显著图创建的初始图。
- 图注意力(GMH):利用基于图的注意力机制来关注图中的重要特征和关系。
- GMH输出:图注意力阶段的输出。
- 图池化(GMPool):通过基于节点的连通性和相似性合并节点,将图简化为更简单的形式,有效地总结图的信息。
- 自注意力(SelfAtt):应用自注意力机制进一步细化节点特征,考虑其中的相互作用。
- 最终池化到ML_Info:最终的图表示被汇总为单一分数(ML_Info),量化样本的总体信息量。
假设一家医院希望利用深度学习模型识别和分类患者的胸部X射线图像,特别是能够同时识别多种肺部疾病的共存,如肺炎和肺癌。
-
输入图:
- 医生收集了一系列胸部X射线图像,这些图像未经标记且疑似包含多种肺部疾病。使用计算机视觉技术对这些图像生成显著图,突出显示对诊断至关重要的区域。例如,图中可能突出显示了肺部的异常阴影区域和肿块。
-
图注意力(GMH):
- 利用图注意力机制,模型分析这些显著图构建的输入图。图中的每个节点代表一个特定区域的显著特征,而边则表示这些区域之间的相互关系。这一步骤帮助模型聚焦于那些可能指示多种疾病共存的关键特征。
-
GMH输出:
- 注意力机制处理后的输出图,其中包括了经过优化的节点和边,这些信息代表了图像中最关键的相互作用和特征关系。
-
图池化(GMPool):
- 通过图池化技术,进一步简化图结构,合并那些具有高度相似性或连通性的节点。例如,如果多个节点都指向同一区域的疾病特征,这些节点可以合并为一个,从而简化模型的复杂性并增强信息的清晰度。
-
自注意力(SelfAtt):
- 自注意力机制用于加强模型对各节点特征的理解,它通过比较各节点间的相互作用强化了模型对图中信息的总体把握。这有助于模型更好地理解不同疾病标签之间的复杂关系。
-
最终池化到ML_Info:
- 将所有处理过的图信息汇总为一个单一的分数(ML_Info),这个分数量化了整个样本图的总体信息量。这个分数可以直接用于训练模型,帮助预测胸部X射线图像中的疾病类型。
这种方法使模型能够准确识别并分类图像中的多种疾病,如正确区分并同时识别存在于同一患者图像中的肺炎和肺癌。
这对于提早诊断和治疗计划的制定极为关键,特别是在复合疾病的情况下。
数据增强的采样与评分
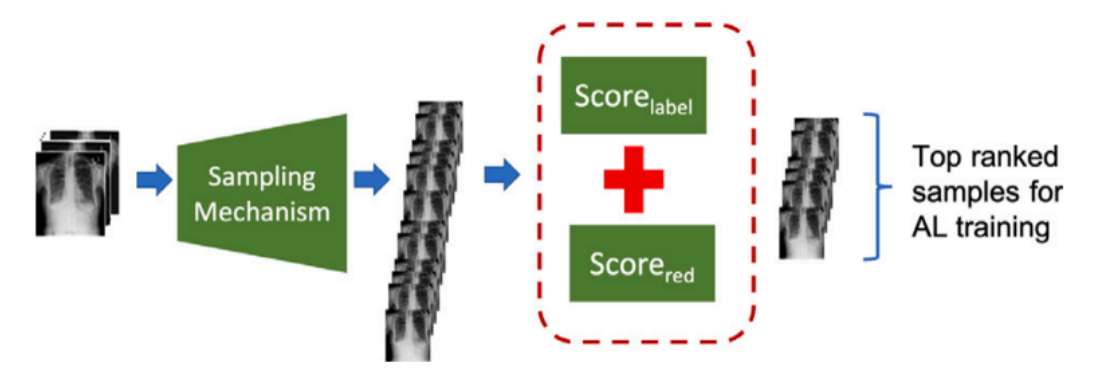
此图解释了增强和选择信息样本所涉及的步骤:
- 采样机制:使用变分自编码器(VAE)生成有信息量的基础样本的变体。VAE在当前数据集上训练,以确保它产生相关的变体。
- 评分系统 :生成的样本根据两个标准进行评分:
- 标签评分(Score_label):评估生成样本在保留原始样本的类标签方面的表现。
- 避免冗余评分(Score_red):评估生成的样本与原始样本的差异,确保它们在不复制现有数据的情况下添加新信息。
- 选择顶尖样本:得分最高的样本,表明它们既有信息量又具多样性,被选中添加到下一个主动学习周期的训练集中。
假设一家医院正在研究一个新的机器学习模型,用以分析心脏超声图像,以诊断心脏瓣膜病变、心肌病变以及心包积液等多种心脏疾病。
-
采样机制:
- 医疗研究团队使用变分自编码器(VAE)处理一组心脏超声图像。VAE模型在包含各种心脏病状的广泛数据集上训练,使其能够生成包含不同心脏状况的合成图像。例如,VAE可能生成一些展示不同程度心肌肥厚或瓣膜泄漏的图像,这些都是原始数据集中可能未充分代表的病变。
-
评分系统:
- 标签评分(Score_label):每个生成的图像会被评估其在保留心脏病变特征(如瓣膜泄漏的特定标记)方面的准确性。如果合成图像能准确地保持原始图像的病理标签,则获得高标签评分。
- 避免冗余评分(Score_red):此外,还会评估合成图像与原始图像的差异性,确保新增的图像为模型训练提供新的信息。例如,如果生成的图像展示了与原始数据集不同阶段的病变,而且这种差异足够大以避免简单的重复,则获得高避免冗余评分。
-
选择顶尖样本:
- 基于上述两种评分,选择得分最高的样本以添加到模型的训练集中。这确保了选中的图像不仅在医学上具有高度的相关性和准确性,而且能够增加训练集的多样性和信息量。这对于提升模型在实际诊断中的准确性和泛化能力至关重要。
通过这种方法,新的心脏疾病诊断模型能够接触到更广泛的心脏病变表现,包括那些在原始数据集中未充分代表的病变阶段和类型。
这使得模型在现实世界应用中能更准确地识别和分类心脏疾病,特别是在处理罕见或复杂病例时表现出更高的效率和准确性。