文章目录
数据
python
from datasets import load_dataset
# 准备数据和分割
tomatoes = load_dataset("/workspace/huggingface_cache/datasets/rotten_tomatoes")
train_data, test_data = tomatoes["train"], tomatoes["test"]这里我们加载了"rotten_tomatoes"数据集,该数据集用于电影评论情感分类,包含正面和负面评论。
监督分类
HuggingFace Trainer
python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# 加载模型和分词器
model_id = "/workspace/huggingface_cache/models/bert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_id, num_labels=2)
tokenizer = AutoTokenizer.from_pretrained(model_id)使用BERT-base-uncased模型进行序列分类任务(二分类)。num_labels=2表示这是一个二分类任务。
模型警告解释:由于我们在预训练模型上添加了新的分类头(classifier层),这些新层的权重是随机初始化的,需要在下游任务上进行训练才能获得良好的预测性能。
数据预处理
python
from transformers import DataCollatorWithPadding
# 按批次中最长序列进行填充
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
def preprocess_function(examples):
"""对输入数据进行分词处理"""
return tokenizer(examples["text"], truncation=True)
# 对训练/测试数据进行分词
tokenized_train = train_data.map(preprocess_function, batched=True)
tokenized_test = test_data.map(preprocess_function, batched=True)DataCollatorWithPadding确保每个批次的序列长度一致,通过填充较短的序列来实现。truncation=True确保过长的序列被截断到模型的最大输入长度。
编写f1评价函数
由于网络的原因直接使用transformers里面的f1函数可能会报错,这里我们自己编写f1评价函数
python
import numpy as np
import evaluate
def compute_metrics(eval_pred):
"""计算F1分数"""
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
load_f1 = evaluate.load("f1")
f1 = load_f1.compute(predictions=predictions, references=labels)["f1"]
return {"f1": f1}使用F1分数作为评估指标,这对于不平衡的数据集特别有用。np.argmax(logits, axis=-1)从模型输出的logits中选择概率最高的类别。
训练模型
python
from transformers import TrainingArguments, Trainer
# 训练参数设置
training_args = TrainingArguments(
"model",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=1,
weight_decay=0.01,
save_strategy="epoch",
report_to="none"
)
# 创建训练器
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_train,
eval_dataset=tokenized_test,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
trainer.train()训练参数说明:
learning_rate=2e-5:典型的小学习率,适合微调weight_decay=0.01:L2正则化,防止过拟合save_strategy="epoch":每个epoch保存一次模型
输出

评估结果
python
trainer.evaluate(){'eval_loss': 0.3693001866340637, 'eval_f1': 0.8472998137802606, 'eval_runtime': 1.6898, 'eval_samples_per_second': 630.847, 'eval_steps_per_second': 39.65, 'epoch': 1.0}
获得了0.847的F1分数,表明模型在情感分类任务上表现良好。
冻结层
仅训练分类头
python
# 重新加载模型
model = AutoModelForSequenceClassification.from_pretrained(model_id, num_labels=2)
tokenizer = AutoTokenizer.from_pretrained(model_id)查看模型
python
for name, param in model.named_parameters():
print(name)输出
bash
bert.embeddings.word_embeddings.weight
bert.embeddings.position_embeddings.weight
bert.embeddings.token_type_embeddings.weight
bert.embeddings.LayerNorm.weight
bert.embeddings.LayerNorm.bias
bert.encoder.layer.0.attention.self.query.weight
bert.encoder.layer.0.attention.self.query.bias
bert.encoder.layer.0.attention.self.key.weight
bert.encoder.layer.0.attention.self.key.bias
bert.encoder.layer.0.attention.self.value.weight
bert.encoder.layer.0.attention.self.value.bias
bert.encoder.layer.0.attention.output.dense.weight
bert.encoder.layer.0.attention.output.dense.bias
bert.encoder.layer.0.attention.output.LayerNorm.weight
bert.encoder.layer.0.attention.output.LayerNorm.bias
bert.encoder.layer.0.intermediate.dense.weight
bert.encoder.layer.0.intermediate.dense.bias
bert.encoder.layer.0.output.dense.weight
bert.encoder.layer.0.output.dense.bias
bert.encoder.layer.0.output.LayerNorm.weight
bert.encoder.layer.0.output.LayerNorm.bias
bert.encoder.layer.1.attention.self.query.weight
bert.encoder.layer.1.attention.self.query.bias
bert.encoder.layer.1.attention.self.key.weight
bert.encoder.layer.1.attention.self.key.bias
bert.encoder.layer.1.attention.self.value.weight
bert.encoder.layer.1.attention.self.value.bias
bert.encoder.layer.1.attention.output.dense.weight
bert.encoder.layer.1.attention.output.dense.bias
bert.encoder.layer.1.attention.output.LayerNorm.weight
bert.encoder.layer.1.attention.output.LayerNorm.bias
bert.encoder.layer.1.intermediate.dense.weight
bert.encoder.layer.1.intermediate.dense.bias
bert.encoder.layer.1.output.dense.weight
bert.encoder.layer.1.output.dense.bias
bert.encoder.layer.1.output.LayerNorm.weight
bert.encoder.layer.1.output.LayerNorm.bias
bert.encoder.layer.2.attention.self.query.weight
bert.encoder.layer.2.attention.self.query.bias
bert.encoder.layer.2.attention.self.key.weight
bert.encoder.layer.2.attention.self.key.bias
bert.encoder.layer.2.attention.self.value.weight
bert.encoder.layer.2.attention.self.value.bias
bert.encoder.layer.2.attention.output.dense.weight
bert.encoder.layer.2.attention.output.dense.bias
bert.encoder.layer.2.attention.output.LayerNorm.weight
bert.encoder.layer.2.attention.output.LayerNorm.bias
bert.encoder.layer.2.intermediate.dense.weight
bert.encoder.layer.2.intermediate.dense.bias
bert.encoder.layer.2.output.dense.weight
bert.encoder.layer.2.output.dense.bias
bert.encoder.layer.2.output.LayerNorm.weight
bert.encoder.layer.2.output.LayerNorm.bias
bert.encoder.layer.3.attention.self.query.weight
bert.encoder.layer.3.attention.self.query.bias
bert.encoder.layer.3.attention.self.key.weight
bert.encoder.layer.3.attention.self.key.bias
bert.encoder.layer.3.attention.self.value.weight
bert.encoder.layer.3.attention.self.value.bias
bert.encoder.layer.3.attention.output.dense.weight
bert.encoder.layer.3.attention.output.dense.bias
bert.encoder.layer.3.attention.output.LayerNorm.weight
bert.encoder.layer.3.attention.output.LayerNorm.bias
bert.encoder.layer.3.intermediate.dense.weight
bert.encoder.layer.3.intermediate.dense.bias
bert.encoder.layer.3.output.dense.weight
bert.encoder.layer.3.output.dense.bias
bert.encoder.layer.3.output.LayerNorm.weight
bert.encoder.layer.3.output.LayerNorm.bias
bert.encoder.layer.4.attention.self.query.weight
bert.encoder.layer.4.attention.self.query.bias
bert.encoder.layer.4.attention.self.key.weight
bert.encoder.layer.4.attention.self.key.bias
bert.encoder.layer.4.attention.self.value.weight
bert.encoder.layer.4.attention.self.value.bias
bert.encoder.layer.4.attention.output.dense.weight
bert.encoder.layer.4.attention.output.dense.bias
bert.encoder.layer.4.attention.output.LayerNorm.weight
bert.encoder.layer.4.attention.output.LayerNorm.bias
bert.encoder.layer.4.intermediate.dense.weight
bert.encoder.layer.4.intermediate.dense.bias
bert.encoder.layer.4.output.dense.weight
bert.encoder.layer.4.output.dense.bias
bert.encoder.layer.4.output.LayerNorm.weight
bert.encoder.layer.4.output.LayerNorm.bias
bert.encoder.layer.5.attention.self.query.weight
bert.encoder.layer.5.attention.self.query.bias
bert.encoder.layer.5.attention.self.key.weight
bert.encoder.layer.5.attention.self.key.bias
bert.encoder.layer.5.attention.self.value.weight
bert.encoder.layer.5.attention.self.value.bias
bert.encoder.layer.5.attention.output.dense.weight
bert.encoder.layer.5.attention.output.dense.bias
bert.encoder.layer.5.attention.output.LayerNorm.weight
bert.encoder.layer.5.attention.output.LayerNorm.bias
bert.encoder.layer.5.intermediate.dense.weight
bert.encoder.layer.5.intermediate.dense.bias
bert.encoder.layer.5.output.dense.weight
bert.encoder.layer.5.output.dense.bias
bert.encoder.layer.5.output.LayerNorm.weight
bert.encoder.layer.5.output.LayerNorm.bias
bert.encoder.layer.6.attention.self.query.weight
bert.encoder.layer.6.attention.self.query.bias
bert.encoder.layer.6.attention.self.key.weight
bert.encoder.layer.6.attention.self.key.bias
bert.encoder.layer.6.attention.self.value.weight
bert.encoder.layer.6.attention.self.value.bias
bert.encoder.layer.6.attention.output.dense.weight
bert.encoder.layer.6.attention.output.dense.bias
bert.encoder.layer.6.attention.output.LayerNorm.weight
bert.encoder.layer.6.attention.output.LayerNorm.bias
bert.encoder.layer.6.intermediate.dense.weight
bert.encoder.layer.6.intermediate.dense.bias
bert.encoder.layer.6.output.dense.weight
bert.encoder.layer.6.output.dense.bias
bert.encoder.layer.6.output.LayerNorm.weight
bert.encoder.layer.6.output.LayerNorm.bias
bert.encoder.layer.7.attention.self.query.weight
bert.encoder.layer.7.attention.self.query.bias
bert.encoder.layer.7.attention.self.key.weight
bert.encoder.layer.7.attention.self.key.bias
bert.encoder.layer.7.attention.self.value.weight
bert.encoder.layer.7.attention.self.value.bias
bert.encoder.layer.7.attention.output.dense.weight
bert.encoder.layer.7.attention.output.dense.bias
bert.encoder.layer.7.attention.output.LayerNorm.weight
bert.encoder.layer.7.attention.output.LayerNorm.bias
bert.encoder.layer.7.intermediate.dense.weight
bert.encoder.layer.7.intermediate.dense.bias
bert.encoder.layer.7.output.dense.weight
bert.encoder.layer.7.output.dense.bias
bert.encoder.layer.7.output.LayerNorm.weight
bert.encoder.layer.7.output.LayerNorm.bias
bert.encoder.layer.8.attention.self.query.weight
bert.encoder.layer.8.attention.self.query.bias
bert.encoder.layer.8.attention.self.key.weight
bert.encoder.layer.8.attention.self.key.bias
bert.encoder.layer.8.attention.self.value.weight
bert.encoder.layer.8.attention.self.value.bias
bert.encoder.layer.8.attention.output.dense.weight
bert.encoder.layer.8.attention.output.dense.bias
bert.encoder.layer.8.attention.output.LayerNorm.weight
bert.encoder.layer.8.attention.output.LayerNorm.bias
bert.encoder.layer.8.intermediate.dense.weight
bert.encoder.layer.8.intermediate.dense.bias
bert.encoder.layer.8.output.dense.weight
bert.encoder.layer.8.output.dense.bias
bert.encoder.layer.8.output.LayerNorm.weight
bert.encoder.layer.8.output.LayerNorm.bias
bert.encoder.layer.9.attention.self.query.weight
bert.encoder.layer.9.attention.self.query.bias
bert.encoder.layer.9.attention.self.key.weight
bert.encoder.layer.9.attention.self.key.bias
bert.encoder.layer.9.attention.self.value.weight
bert.encoder.layer.9.attention.self.value.bias
bert.encoder.layer.9.attention.output.dense.weight
bert.encoder.layer.9.attention.output.dense.bias
bert.encoder.layer.9.attention.output.LayerNorm.weight
bert.encoder.layer.9.attention.output.LayerNorm.bias
bert.encoder.layer.9.intermediate.dense.weight
bert.encoder.layer.9.intermediate.dense.bias
bert.encoder.layer.9.output.dense.weight
bert.encoder.layer.9.output.dense.bias
bert.encoder.layer.9.output.LayerNorm.weight
bert.encoder.layer.9.output.LayerNorm.bias
bert.encoder.layer.10.attention.self.query.weight
bert.encoder.layer.10.attention.self.query.bias
bert.encoder.layer.10.attention.self.key.weight
bert.encoder.layer.10.attention.self.key.bias
bert.encoder.layer.10.attention.self.value.weight
bert.encoder.layer.10.attention.self.value.bias
bert.encoder.layer.10.attention.output.dense.weight
bert.encoder.layer.10.attention.output.dense.bias
bert.encoder.layer.10.attention.output.LayerNorm.weight
bert.encoder.layer.10.attention.output.LayerNorm.bias
bert.encoder.layer.10.intermediate.dense.weight
bert.encoder.layer.10.intermediate.dense.bias
bert.encoder.layer.10.output.dense.weight
bert.encoder.layer.10.output.dense.bias
bert.encoder.layer.10.output.LayerNorm.weight
bert.encoder.layer.10.output.LayerNorm.bias
bert.encoder.layer.11.attention.self.query.weight
bert.encoder.layer.11.attention.self.query.bias
bert.encoder.layer.11.attention.self.key.weight
bert.encoder.layer.11.attention.self.key.bias
bert.encoder.layer.11.attention.self.value.weight
bert.encoder.layer.11.attention.self.value.bias
bert.encoder.layer.11.attention.output.dense.weight
bert.encoder.layer.11.attention.output.dense.bias
bert.encoder.layer.11.attention.output.LayerNorm.weight
bert.encoder.layer.11.attention.output.LayerNorm.bias
bert.encoder.layer.11.intermediate.dense.weight
bert.encoder.layer.11.intermediate.dense.bias
bert.encoder.layer.11.output.dense.weight
bert.encoder.layer.11.output.dense.bias
bert.encoder.layer.11.output.LayerNorm.weight
bert.encoder.layer.11.output.LayerNorm.bias
bert.pooler.dense.weight
bert.pooler.dense.bias
classifier.weight
classifier.bias从上面的输出可以看出该模型由 12 个(编号为 0~11)编码器块构成,每个块均包含注意力头、前馈神经网络以及层归一化组件。
python
# 冻结所有层,只训练分类头
for name, param in model.named_parameters():
# 可训练的分类头
if name.startswith("classifier"):
param.requires_grad = True
# 冻结其他所有层
else:
param.requires_grad = Falserequires_grad=False表示在训练过程中不更新这些参数的梯度,从而"冻结"这些层。这种方法:
- 大大减少训练时间
- 减少内存消耗
- 但可能影响模型性能
训练模型
python
from transformers import TrainingArguments, Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_train,
eval_dataset=tokenized_test,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
trainer.train()输出

评估结果
python
trainer.evaluate(){'eval_loss': 0.6911734938621521, 'eval_f1': 0.6326681448632668, 'eval_runtime': 1.7076, 'eval_samples_per_second': 624.256, 'eval_steps_per_second': 39.236, 'epoch': 1.0}
结果分析:仅训练分类头时,F1分数从0.84下降到0.6327,表明预训练模型的中间层表示对于此任务很重要。
冻结前10个编码器块
python
# 重新加载模型
model_id = "bert-base-cased"
model = AutoModelForSequenceClassification.from_pretrained(model_id, num_labels=2)
tokenizer = AutoTokenizer.from_pretrained(model_id)
# 编码器块10从索引165开始
# 我们冻结该块之前的所有层
for index, (name, param) in enumerate(model.named_parameters()):
if index < 165:
param.requires_grad = False这种方法:
- 冻结前10个编码器块(共12个)
- 只训练最后2个编码器块和分类头
- 平衡了训练效率和模型性能
查看模型情况
bash
# # We can check whether the model was correctly updated
for index, (name, param) in enumerate(model.named_parameters()):
print(f"Parameter: {index}{name} ----- {param.requires_grad}")输出
bash
Parameter: 0bert.embeddings.word_embeddings.weight ----- False
Parameter: 1bert.embeddings.position_embeddings.weight ----- False
Parameter: 2bert.embeddings.token_type_embeddings.weight ----- False
Parameter: 3bert.embeddings.LayerNorm.weight ----- False
Parameter: 4bert.embeddings.LayerNorm.bias ----- False
Parameter: 5bert.encoder.layer.0.attention.self.query.weight ----- False
Parameter: 6bert.encoder.layer.0.attention.self.query.bias ----- False
Parameter: 7bert.encoder.layer.0.attention.self.key.weight ----- False
Parameter: 8bert.encoder.layer.0.attention.self.key.bias ----- False
Parameter: 9bert.encoder.layer.0.attention.self.value.weight ----- False
Parameter: 10bert.encoder.layer.0.attention.self.value.bias ----- False
Parameter: 11bert.encoder.layer.0.attention.output.dense.weight ----- False
Parameter: 12bert.encoder.layer.0.attention.output.dense.bias ----- False
Parameter: 13bert.encoder.layer.0.attention.output.LayerNorm.weight ----- False
Parameter: 14bert.encoder.layer.0.attention.output.LayerNorm.bias ----- False
Parameter: 15bert.encoder.layer.0.intermediate.dense.weight ----- False
Parameter: 16bert.encoder.layer.0.intermediate.dense.bias ----- False
Parameter: 17bert.encoder.layer.0.output.dense.weight ----- False
Parameter: 18bert.encoder.layer.0.output.dense.bias ----- False
Parameter: 19bert.encoder.layer.0.output.LayerNorm.weight ----- False
Parameter: 20bert.encoder.layer.0.output.LayerNorm.bias ----- False
Parameter: 21bert.encoder.layer.1.attention.self.query.weight ----- False
Parameter: 22bert.encoder.layer.1.attention.self.query.bias ----- False
Parameter: 23bert.encoder.layer.1.attention.self.key.weight ----- False
Parameter: 24bert.encoder.layer.1.attention.self.key.bias ----- False
Parameter: 25bert.encoder.layer.1.attention.self.value.weight ----- False
Parameter: 26bert.encoder.layer.1.attention.self.value.bias ----- False
Parameter: 27bert.encoder.layer.1.attention.output.dense.weight ----- False
Parameter: 28bert.encoder.layer.1.attention.output.dense.bias ----- False
Parameter: 29bert.encoder.layer.1.attention.output.LayerNorm.weight ----- False
Parameter: 30bert.encoder.layer.1.attention.output.LayerNorm.bias ----- False
Parameter: 31bert.encoder.layer.1.intermediate.dense.weight ----- False
Parameter: 32bert.encoder.layer.1.intermediate.dense.bias ----- False
Parameter: 33bert.encoder.layer.1.output.dense.weight ----- False
Parameter: 34bert.encoder.layer.1.output.dense.bias ----- False
Parameter: 35bert.encoder.layer.1.output.LayerNorm.weight ----- False
Parameter: 36bert.encoder.layer.1.output.LayerNorm.bias ----- False
Parameter: 37bert.encoder.layer.2.attention.self.query.weight ----- False
Parameter: 38bert.encoder.layer.2.attention.self.query.bias ----- False
Parameter: 39bert.encoder.layer.2.attention.self.key.weight ----- False
Parameter: 40bert.encoder.layer.2.attention.self.key.bias ----- False
Parameter: 41bert.encoder.layer.2.attention.self.value.weight ----- False
Parameter: 42bert.encoder.layer.2.attention.self.value.bias ----- False
Parameter: 43bert.encoder.layer.2.attention.output.dense.weight ----- False
Parameter: 44bert.encoder.layer.2.attention.output.dense.bias ----- False
Parameter: 45bert.encoder.layer.2.attention.output.LayerNorm.weight ----- False
Parameter: 46bert.encoder.layer.2.attention.output.LayerNorm.bias ----- False
Parameter: 47bert.encoder.layer.2.intermediate.dense.weight ----- False
Parameter: 48bert.encoder.layer.2.intermediate.dense.bias ----- False
Parameter: 49bert.encoder.layer.2.output.dense.weight ----- False
Parameter: 50bert.encoder.layer.2.output.dense.bias ----- False
Parameter: 51bert.encoder.layer.2.output.LayerNorm.weight ----- False
Parameter: 52bert.encoder.layer.2.output.LayerNorm.bias ----- False
Parameter: 53bert.encoder.layer.3.attention.self.query.weight ----- False
Parameter: 54bert.encoder.layer.3.attention.self.query.bias ----- False
Parameter: 55bert.encoder.layer.3.attention.self.key.weight ----- False
Parameter: 56bert.encoder.layer.3.attention.self.key.bias ----- False
Parameter: 57bert.encoder.layer.3.attention.self.value.weight ----- False
Parameter: 58bert.encoder.layer.3.attention.self.value.bias ----- False
Parameter: 59bert.encoder.layer.3.attention.output.dense.weight ----- False
Parameter: 60bert.encoder.layer.3.attention.output.dense.bias ----- False
Parameter: 61bert.encoder.layer.3.attention.output.LayerNorm.weight ----- False
Parameter: 62bert.encoder.layer.3.attention.output.LayerNorm.bias ----- False
Parameter: 63bert.encoder.layer.3.intermediate.dense.weight ----- False
Parameter: 64bert.encoder.layer.3.intermediate.dense.bias ----- False
Parameter: 65bert.encoder.layer.3.output.dense.weight ----- False
Parameter: 66bert.encoder.layer.3.output.dense.bias ----- False
Parameter: 67bert.encoder.layer.3.output.LayerNorm.weight ----- False
Parameter: 68bert.encoder.layer.3.output.LayerNorm.bias ----- False
Parameter: 69bert.encoder.layer.4.attention.self.query.weight ----- False
Parameter: 70bert.encoder.layer.4.attention.self.query.bias ----- False
Parameter: 71bert.encoder.layer.4.attention.self.key.weight ----- False
Parameter: 72bert.encoder.layer.4.attention.self.key.bias ----- False
Parameter: 73bert.encoder.layer.4.attention.self.value.weight ----- False
Parameter: 74bert.encoder.layer.4.attention.self.value.bias ----- False
Parameter: 75bert.encoder.layer.4.attention.output.dense.weight ----- False
Parameter: 76bert.encoder.layer.4.attention.output.dense.bias ----- False
Parameter: 77bert.encoder.layer.4.attention.output.LayerNorm.weight ----- False
Parameter: 78bert.encoder.layer.4.attention.output.LayerNorm.bias ----- False
Parameter: 79bert.encoder.layer.4.intermediate.dense.weight ----- False
Parameter: 80bert.encoder.layer.4.intermediate.dense.bias ----- False
Parameter: 81bert.encoder.layer.4.output.dense.weight ----- False
Parameter: 82bert.encoder.layer.4.output.dense.bias ----- False
Parameter: 83bert.encoder.layer.4.output.LayerNorm.weight ----- False
Parameter: 84bert.encoder.layer.4.output.LayerNorm.bias ----- False
Parameter: 85bert.encoder.layer.5.attention.self.query.weight ----- False
Parameter: 86bert.encoder.layer.5.attention.self.query.bias ----- False
Parameter: 87bert.encoder.layer.5.attention.self.key.weight ----- False
Parameter: 88bert.encoder.layer.5.attention.self.key.bias ----- False
Parameter: 89bert.encoder.layer.5.attention.self.value.weight ----- False
Parameter: 90bert.encoder.layer.5.attention.self.value.bias ----- False
Parameter: 91bert.encoder.layer.5.attention.output.dense.weight ----- False
Parameter: 92bert.encoder.layer.5.attention.output.dense.bias ----- False
Parameter: 93bert.encoder.layer.5.attention.output.LayerNorm.weight ----- False
Parameter: 94bert.encoder.layer.5.attention.output.LayerNorm.bias ----- False
Parameter: 95bert.encoder.layer.5.intermediate.dense.weight ----- False
Parameter: 96bert.encoder.layer.5.intermediate.dense.bias ----- False
Parameter: 97bert.encoder.layer.5.output.dense.weight ----- False
Parameter: 98bert.encoder.layer.5.output.dense.bias ----- False
Parameter: 99bert.encoder.layer.5.output.LayerNorm.weight ----- False
Parameter: 100bert.encoder.layer.5.output.LayerNorm.bias ----- False
Parameter: 101bert.encoder.layer.6.attention.self.query.weight ----- False
Parameter: 102bert.encoder.layer.6.attention.self.query.bias ----- False
Parameter: 103bert.encoder.layer.6.attention.self.key.weight ----- False
Parameter: 104bert.encoder.layer.6.attention.self.key.bias ----- False
Parameter: 105bert.encoder.layer.6.attention.self.value.weight ----- False
Parameter: 106bert.encoder.layer.6.attention.self.value.bias ----- False
Parameter: 107bert.encoder.layer.6.attention.output.dense.weight ----- False
Parameter: 108bert.encoder.layer.6.attention.output.dense.bias ----- False
Parameter: 109bert.encoder.layer.6.attention.output.LayerNorm.weight ----- False
Parameter: 110bert.encoder.layer.6.attention.output.LayerNorm.bias ----- False
Parameter: 111bert.encoder.layer.6.intermediate.dense.weight ----- False
Parameter: 112bert.encoder.layer.6.intermediate.dense.bias ----- False
Parameter: 113bert.encoder.layer.6.output.dense.weight ----- False
Parameter: 114bert.encoder.layer.6.output.dense.bias ----- False
Parameter: 115bert.encoder.layer.6.output.LayerNorm.weight ----- False
Parameter: 116bert.encoder.layer.6.output.LayerNorm.bias ----- False
Parameter: 117bert.encoder.layer.7.attention.self.query.weight ----- False
Parameter: 118bert.encoder.layer.7.attention.self.query.bias ----- False
Parameter: 119bert.encoder.layer.7.attention.self.key.weight ----- False
Parameter: 120bert.encoder.layer.7.attention.self.key.bias ----- False
Parameter: 121bert.encoder.layer.7.attention.self.value.weight ----- False
Parameter: 122bert.encoder.layer.7.attention.self.value.bias ----- False
Parameter: 123bert.encoder.layer.7.attention.output.dense.weight ----- False
Parameter: 124bert.encoder.layer.7.attention.output.dense.bias ----- False
Parameter: 125bert.encoder.layer.7.attention.output.LayerNorm.weight ----- False
Parameter: 126bert.encoder.layer.7.attention.output.LayerNorm.bias ----- False
Parameter: 127bert.encoder.layer.7.intermediate.dense.weight ----- False
Parameter: 128bert.encoder.layer.7.intermediate.dense.bias ----- False
Parameter: 129bert.encoder.layer.7.output.dense.weight ----- False
Parameter: 130bert.encoder.layer.7.output.dense.bias ----- False
Parameter: 131bert.encoder.layer.7.output.LayerNorm.weight ----- False
Parameter: 132bert.encoder.layer.7.output.LayerNorm.bias ----- False
Parameter: 133bert.encoder.layer.8.attention.self.query.weight ----- False
Parameter: 134bert.encoder.layer.8.attention.self.query.bias ----- False
Parameter: 135bert.encoder.layer.8.attention.self.key.weight ----- False
Parameter: 136bert.encoder.layer.8.attention.self.key.bias ----- False
Parameter: 137bert.encoder.layer.8.attention.self.value.weight ----- False
Parameter: 138bert.encoder.layer.8.attention.self.value.bias ----- False
Parameter: 139bert.encoder.layer.8.attention.output.dense.weight ----- False
Parameter: 140bert.encoder.layer.8.attention.output.dense.bias ----- False
Parameter: 141bert.encoder.layer.8.attention.output.LayerNorm.weight ----- False
Parameter: 142bert.encoder.layer.8.attention.output.LayerNorm.bias ----- False
Parameter: 143bert.encoder.layer.8.intermediate.dense.weight ----- False
Parameter: 144bert.encoder.layer.8.intermediate.dense.bias ----- False
Parameter: 145bert.encoder.layer.8.output.dense.weight ----- False
Parameter: 146bert.encoder.layer.8.output.dense.bias ----- False
Parameter: 147bert.encoder.layer.8.output.LayerNorm.weight ----- False
Parameter: 148bert.encoder.layer.8.output.LayerNorm.bias ----- False
Parameter: 149bert.encoder.layer.9.attention.self.query.weight ----- False
Parameter: 150bert.encoder.layer.9.attention.self.query.bias ----- False
Parameter: 151bert.encoder.layer.9.attention.self.key.weight ----- False
Parameter: 152bert.encoder.layer.9.attention.self.key.bias ----- False
Parameter: 153bert.encoder.layer.9.attention.self.value.weight ----- False
Parameter: 154bert.encoder.layer.9.attention.self.value.bias ----- False
Parameter: 155bert.encoder.layer.9.attention.output.dense.weight ----- False
Parameter: 156bert.encoder.layer.9.attention.output.dense.bias ----- False
Parameter: 157bert.encoder.layer.9.attention.output.LayerNorm.weight ----- False
Parameter: 158bert.encoder.layer.9.attention.output.LayerNorm.bias ----- False
Parameter: 159bert.encoder.layer.9.intermediate.dense.weight ----- False
Parameter: 160bert.encoder.layer.9.intermediate.dense.bias ----- False
Parameter: 161bert.encoder.layer.9.output.dense.weight ----- False
Parameter: 162bert.encoder.layer.9.output.dense.bias ----- False
Parameter: 163bert.encoder.layer.9.output.LayerNorm.weight ----- False
Parameter: 164bert.encoder.layer.9.output.LayerNorm.bias ----- False
Parameter: 165bert.encoder.layer.10.attention.self.query.weight ----- True
Parameter: 166bert.encoder.layer.10.attention.self.query.bias ----- True
Parameter: 167bert.encoder.layer.10.attention.self.key.weight ----- True
Parameter: 168bert.encoder.layer.10.attention.self.key.bias ----- True
Parameter: 169bert.encoder.layer.10.attention.self.value.weight ----- True
Parameter: 170bert.encoder.layer.10.attention.self.value.bias ----- True
Parameter: 171bert.encoder.layer.10.attention.output.dense.weight ----- True
Parameter: 172bert.encoder.layer.10.attention.output.dense.bias ----- True
Parameter: 173bert.encoder.layer.10.attention.output.LayerNorm.weight ----- True
Parameter: 174bert.encoder.layer.10.attention.output.LayerNorm.bias ----- True
Parameter: 175bert.encoder.layer.10.intermediate.dense.weight ----- True
Parameter: 176bert.encoder.layer.10.intermediate.dense.bias ----- True
Parameter: 177bert.encoder.layer.10.output.dense.weight ----- True
Parameter: 178bert.encoder.layer.10.output.dense.bias ----- True
Parameter: 179bert.encoder.layer.10.output.LayerNorm.weight ----- True
Parameter: 180bert.encoder.layer.10.output.LayerNorm.bias ----- True
Parameter: 181bert.encoder.layer.11.attention.self.query.weight ----- True
Parameter: 182bert.encoder.layer.11.attention.self.query.bias ----- True
Parameter: 183bert.encoder.layer.11.attention.self.key.weight ----- True
Parameter: 184bert.encoder.layer.11.attention.self.key.bias ----- True
Parameter: 185bert.encoder.layer.11.attention.self.value.weight ----- True
Parameter: 186bert.encoder.layer.11.attention.self.value.bias ----- True
Parameter: 187bert.encoder.layer.11.attention.output.dense.weight ----- True
Parameter: 188bert.encoder.layer.11.attention.output.dense.bias ----- True
Parameter: 189bert.encoder.layer.11.attention.output.LayerNorm.weight ----- True
Parameter: 190bert.encoder.layer.11.attention.output.LayerNorm.bias ----- True
Parameter: 191bert.encoder.layer.11.intermediate.dense.weight ----- True
Parameter: 192bert.encoder.layer.11.intermediate.dense.bias ----- True
Parameter: 193bert.encoder.layer.11.output.dense.weight ----- True
Parameter: 194bert.encoder.layer.11.output.dense.bias ----- True
Parameter: 195bert.encoder.layer.11.output.LayerNorm.weight ----- True
Parameter: 196bert.encoder.layer.11.output.LayerNorm.bias ----- True
Parameter: 197bert.pooler.dense.weight ----- True
Parameter: 198bert.pooler.dense.bias ----- True
Parameter: 199classifier.weight ----- True
Parameter: 200classifier.bias ----- True训练与评估
python
# Trainer which executes the training process
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_train,
eval_dataset=tokenized_test,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
trainer.train()
trainer.evaluate()输出
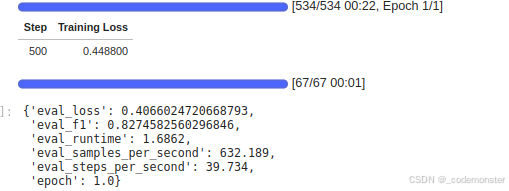
结果:F1分数为0.82,比仅训练分类头好,但比全模型微调稍差。
不同冻结策略的比较
通过实验不同数量的冻结层,还可以发现:
- 冻结前4个块对性能影响不大
- 冻结更多块会导致性能下降
- 完全冻结所有层(只训练分类头)性能最差