目录标题
- 完整可运行项目(生产级最小实现,自动选模型)
-
- [pip install dotenv](#pip install dotenv)
- 一、项目结构
- [二、`.env`(不要放真实 Key)](#二、
.env(不要放真实 Key)) - 三、`requirements.txt`
- [四、`env_utils.py`(**绝对路径加载 .env**)](#四、
env_utils.py(绝对路径加载 .env)) - [五、`my_llm.py`(**自动选择可用模型**,不再手写 `gemini-pro`)](#五、
my_llm.py(自动选择可用模型,不再手写gemini-pro)) - [六、`my_custom_llm.py`(带前缀 / 系统提示词--带角色的 AI)](#六、
my_custom_llm.py(带前缀 / 系统提示词--带角色的 AI)) - 七、`list_models.py`(排查账号权限必备)
- 八、`test_llm/init.py`(主入口)
- 九、运行步骤(一次成功)
- [下面给出**"逐行解释 + 行内注释版"**](#下面给出**“逐行解释 + 行内注释版”**)
- 1) `requirements.txt`(不是 Python 代码,但也解释一下)
requirements.txt(不是 Python 代码,但也解释一下)) - 2) `.env`
.env) - 3) `env_utils.py`(逐行解释 + 注释版)
env_utils.py(逐行解释 + 注释版)) - 4) `my_llm.py`(逐行解释 + 注释版)
my_llm.py(逐行解释 + 注释版)) - 5) `my_custom_llm.py`(逐行解释 + 注释版)
my_custom_llm.py(逐行解释 + 注释版)) - 6) `list_models.py`(逐行解释 + 注释版)
list_models.py(逐行解释 + 注释版)) - 7) `test_llm/init.py`(逐行解释 + 注释版)
test_llm/__init__.py(逐行解释 + 注释版)) - [最后,写个前端页面,用 FastAPI调 Gemini 后端](#最后,写个前端页面,用 FastAPI调 Gemini 后端)
完整可运行项目(生产级最小实现,自动选模型)
目标
不手写模型名(避免 404)
自动选择支持 generateContent 的模型
支持单轮 & 带前缀
结构清晰、可维护
完整可运行项目(生产级最小实现,自动选模型)
目标
- 不手写模型名(避免 404)
- 自动选择支持
generateContent的模型- 支持单轮 & 带前缀
- 结构清晰、可维护
必要的依赖包下载
python
pip install -U langchain
pip install -U langchain-openai
pip install -U langchain-anthropicpip install dotenv
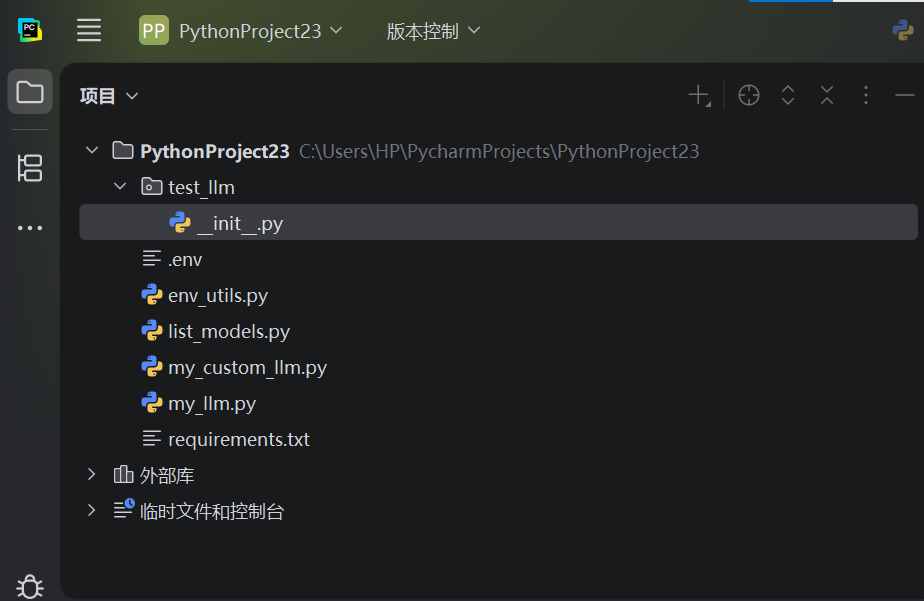
一、项目结构
本项目可以:
读取 API Key
自动选择一个 可用的 Gemini 模型
向模型提问
打印模型回答
支持"普通问答"和"带角色设定的问答"
text
PythonProject23/
├── .env # 存放"秘密信息"(API Key)
├── requirements.txt # 告诉 Python:这个项目需要哪些库
├── env_utils.py # 负责读取 .env 的工具代码
├── my_llm.py # 核心:和 Gemini 对话的代码
├── my_custom_llm.py # 在 my_llm 基础上加"前缀/角色"
├── list_models.py # 查看你账号能用哪些 Gemini 模型
└── test_llm/ # 测试代码文件夹
└── __init__.py # 程序入口(真正开始执行的地方)二、.env(不要放真实 Key)
代码只负责"去拿",不负责"写死"
dotenv
# 复制为 .env 后填写你【自己新生成】的 Google API Key
GOOGLE_API_KEY=YOUR_GOOGLE_API_KEY_HERE三、requirements.txt
告诉 Python:这个项目需要安装哪些"第三方工具"
txt
google-generativeai>=0.5.0
python-dotenv>=1.0.0安装:
bash
pip install -r requirements.txt四、env_utils.py(绝对路径加载 .env)
专门负责 从 .env 里把 API Key 读出来
为什么单独一个文件?
因为:
很多地方都会用到 API Key
不想每个文件都写一遍读取逻辑
env_utils.py = 公共工具
谁要 Key,就找它
你可以把它理解成:
"钥匙管理员"
python
import os
from dotenv import load_dotenv
def load_google_api_key() -> str:
"""
从项目根目录加载 .env 中的 GOOGLE_API_KEY
"""
base_dir = os.path.dirname(os.path.abspath(__file__))
env_path = os.path.join(base_dir, ".env")
load_dotenv(env_path)
api_key = os.getenv("GOOGLE_API_KEY")
if not api_key or not api_key.strip():
raise RuntimeError(
f"未读取到 GOOGLE_API_KEY。\n"
f"请确认已在 {env_path} 中填写。"
)
return api_key.strip()五、my_llm.py(自动选择可用模型 ,不再手写 gemini-pro)
这是整个项目最重要的文件
封装了"如何使用 Gemini 回答问题"的全部逻辑
它做了这些事:
读取 API Key
连接 Google Gemini
自动选择你账号能用的模型
提供一个方法:
generate("用户的问题")
MyGeminiLLM.generate() = 向 AI 提问
python
from dataclasses import dataclass
from typing import Optional, Dict, Any, List
import google.generativeai as genai
from env_utils import load_google_api_key
@dataclass
class GeminiConfig:
temperature: float = 0.7
max_output_tokens: int = 1024
top_p: float = 1.0
top_k: int = 1
class MyGeminiLLM:
"""
Gemini LLM 封装(自动选择支持 generateContent 的模型)
"""
def __init__(self, config: Optional[GeminiConfig] = None):
self.config = config or GeminiConfig()
api_key = load_google_api_key()
genai.configure(api_key=api_key)
self.model_name = self._select_available_model()
self.model = genai.GenerativeModel(self.model_name)
def _select_available_model(self) -> str:
"""
从账号可用模型中,选择支持 generateContent 的模型
优先顺序:1.5-flash > 1.5-pro > 其他
"""
candidates: List[str] = []
for m in genai.list_models():
methods = getattr(m, "supported_generation_methods", []) or []
if "generateContent" in methods:
candidates.append(m.name)
if not candidates:
raise RuntimeError("当前账号没有任何支持 generateContent 的模型。")
# 优先级选择
for prefer in ("gemini-1.5-flash", "gemini-1.5-pro"):
for name in candidates:
if prefer in name:
return name
return candidates[0]
def generate(self, prompt: str, **kwargs: Any) -> str:
generation_config: Dict[str, Any] = {
"temperature": kwargs.get("temperature", self.config.temperature),
"max_output_tokens": kwargs.get(
"max_output_tokens", self.config.max_output_tokens
),
"top_p": kwargs.get("top_p", self.config.top_p),
"top_k": kwargs.get("top_k", self.config.top_k),
}
resp = self.model.generate_content(
prompt,
generation_config=generation_config
)
return resp.text or ""六、my_custom_llm.py(带前缀 / 系统提示词--带角色的 AI)
my_custom_llm.py ------「带角色的 AI」
在 my_llm.py 的基础上,加一句"固定说明"
比如我们想要:
"你是一名资深后端工程师,用结构化方式回答"
那就用这个文件。
它的作用不是"更强",而是:
更可控
更像真实工作中用 LLM 的方式
python
from typing import Optional, Any
from my_llm import MyGeminiLLM, GeminiConfig
class MyCustomGeminiLLM(MyGeminiLLM):
"""
增加固定前缀(系统提示词)
"""
def __init__(self, prefix: str, config: Optional[GeminiConfig] = None):
self.prefix = prefix.strip()
super().__init__(config=config)
def generate(self, prompt: str, **kwargs: Any) -> str:
final_prompt = (
f"{self.prefix}\n\n用户:{prompt}\n助手:"
if self.prefix else prompt
)
return super().generate(final_prompt, **kwargs)七、list_models.py(排查账号权限必备)
看看这个账号,到底能用哪些 Gemini 模型
这个文件能帮我们看:
快速确认是不是"账号问题"
判断是代码错,还是模型不可用
python
import google.generativeai as genai
from env_utils import load_google_api_key
def main() -> None:
genai.configure(api_key=load_google_api_key())
print("==== 可用模型 ====")
for m in genai.list_models():
print(
f"{m.name} | "
f"methods={getattr(m, 'supported_generation_methods', None)}"
)
if __name__ == "__main__":
main()八、test_llm/__init__.py(主入口)
python -m test_llm
这里通常做什么?
创建 LLM 对象
提问
打印结果
这是"演示 & 测试入口"
python
from my_llm import MyGeminiLLM, GeminiConfig
from my_custom_llm import MyCustomGeminiLLM
def test_basic_llm():
print("===== 测试:基础 LLM =====")
llm = MyGeminiLLM(
config=GeminiConfig(
temperature=0.7,
max_output_tokens=512
)
)
print(llm.generate("用中文解释什么是 REST API,并给一个简单例子。"))
def test_prefix_llm():
print("\n===== 测试:带前缀 LLM =====")
prefix = (
"你是一名资深后端工程师。\n"
"回答要求:结构化、简洁、示例清晰。"
)
llm = MyCustomGeminiLLM(prefix=prefix)
print(llm.generate("解释 DTO 和 Map 互转的常见方式及优缺点。"))
def main():
test_basic_llm()
test_prefix_llm()
if __name__ == "__main__":
main()九、运行步骤(一次成功)
bash
# 1. 复制并填写你【新生成】的 Key
# 2. 安装依赖
pip install -r requirements.txt
# 3.(可选)查看可用模型
python list_models.py
# 4. 运行测试
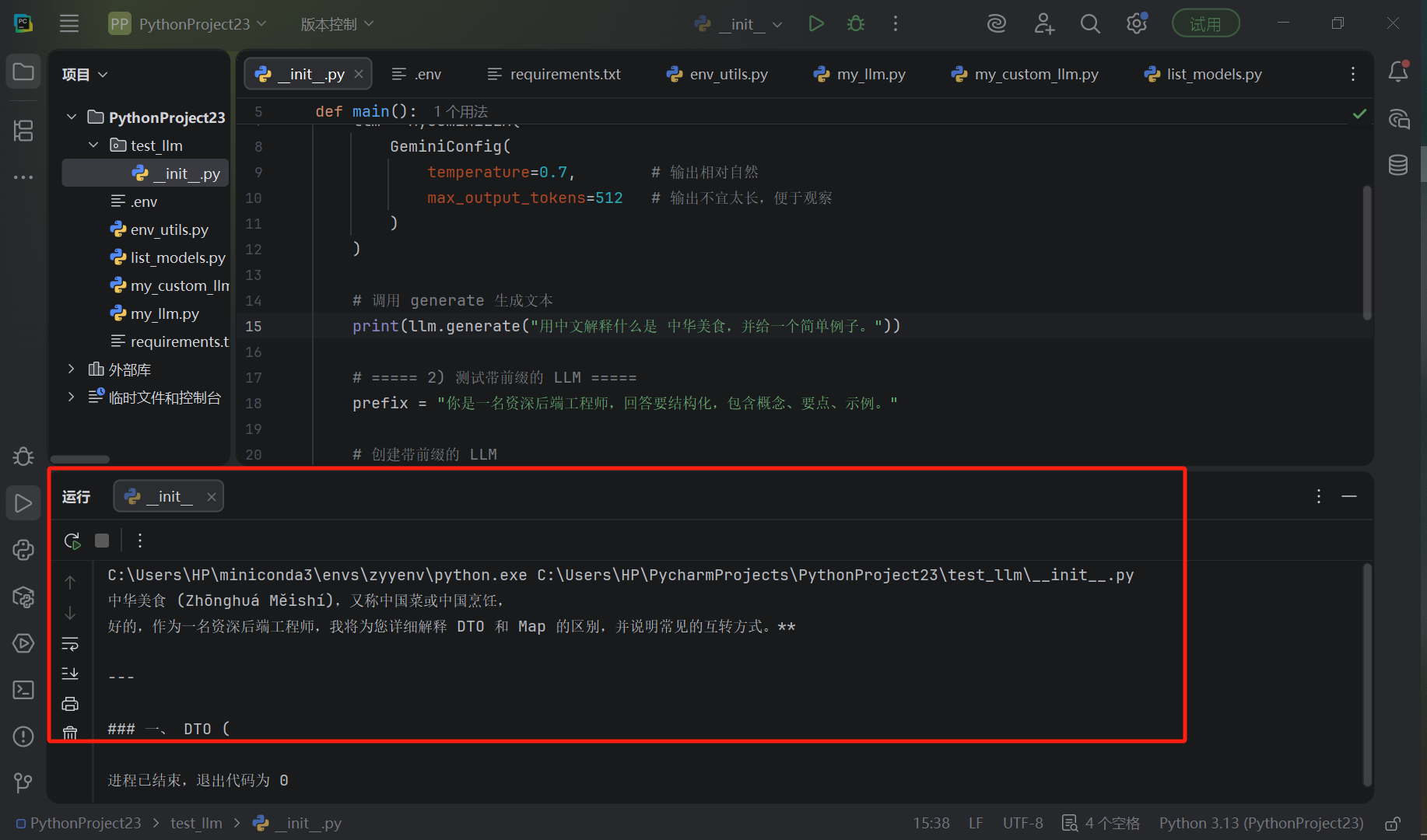
python -m test_llm现在这一步,已经是标准工程级起点了。
运行结果:
下面给出**"逐行解释 + 行内注释版"**
1) requirements.txt(不是 Python 代码,但也解释一下)
txt
google-generativeai>=0.5.0
# Gemini 官方 Python SDK(提供 genai.configure / GenerativeModel / list_models 等)
python-dotenv>=1.0.0 # 读取 .env 文件,把里面的键值对加载到系统环境变量中2) .env
dotenv
GOOGLE_API_KEY=YOUR_GOOGLE_API_KEY_HERE # 这里放你自己的 Google API Key(示例文件不要写真实 key)3) env_utils.py(逐行解释 + 注释版)
python
import os # os:用于获取文件路径、读取环境变量等(操作系统相关功能)
from dotenv import load_dotenv # load_dotenv:从 .env 文件读取变量并注入到环境变量中
def load_google_api_key() -> str:
"""
从项目根目录加载 .env 中的 GOOGLE_API_KEY,并返回该 Key。
返回 str 表示这个函数一定会返回字符串。
"""
# os.path.abspath(__file__):得到当前文件 env_utils.py 的绝对路径(【注意:带文件名)】
# 例:C:\Users\HP\PycharmProjects\PythonProject23\env_utils.py
current_file_abs_path = os.path.abspath(__file__)
# os.path.dirname(...):取目录部分,得到 env_utils.py 所在文件夹(也就是项目根目录)
# 例:C:\Users\HP\PycharmProjects\PythonProject23
base_dir = os.path.dirname(current_file_abs_path)
# 拼出 .env 的绝对路径(确保无论工作目录在哪,都能找到项目根目录下的 .env)
# 例:C:\Users\HP\PycharmProjects\PythonProject23\.env
env_path = os.path.join(base_dir, ".env")
# 读取 env_path 指向的 .env 文件,把里面的键值对加载到进程环境变量中
# load_dotenv 不会"返回变量",它只是把变量写进 os.environ
load_dotenv(env_path)
# os.getenv("GOOGLE_API_KEY"):从环境变量里取 GOOGLE_API_KEY
# 如果没找到会返回 None
api_key = os.getenv("GOOGLE_API_KEY")
# 校验:如果 api_key 不存在,或者全部是空格,就抛异常
# 这样能尽早告诉你"没配置 .env",避免后续调用 API 时才报更难懂的错
if not api_key or not api_key.strip():
raise RuntimeError(f"未读取到 GOOGLE_API_KEY,请检查 {env_path}")
# strip():去掉前后空白(防止复制粘贴带空格导致认证失败)
return api_key.strip()4) my_llm.py(逐行解释 + 注释版)
python
from dataclasses import dataclass # dataclass:快速定义"配置类",自动生成 __init__ 等
from typing import Optional, Dict, Any, List # 类型提示:让代码更清晰(运行不依赖它们)
import google.generativeai as genai # Google Gemini SDK(官方库)
from env_utils import load_google_api_key # 导入我们写的函数:读取 API Key
@dataclass
class GeminiConfig:
"""
Gemini 生成参数的配置类:
dataclass 会自动生成 __init__(temperature=..., max_output_tokens=..., ...)
"""
temperature: float = 0.7 # 温度:越大越发散/有创意,越小越稳定/保守
max_output_tokens: int = 1024 # 最大输出 token 数(输出越长越大)
top_p: float = 1.0 # nucleus sampling(控制输出分布)
top_k: int = 1 # top-k sampling(控制候选词范围)
class MyGeminiLLM:
"""
对 Gemini SDK 做一个"业务友好"的封装:
- 自动读取 API Key
- 自动选择可用模型(避免 gemini-pro 404)
- 提供统一的 generate(prompt) 方法
"""
def __init__(self, config: Optional[GeminiConfig] = None):
# 如果外部传了 config,就用外部的;否则使用默认 GeminiConfig()
self.config = config or GeminiConfig()
# 配置 SDK:把 API Key 告诉 genai(内部会用于请求鉴权)
# load_google_api_key() 会去项目根目录的 .env 读取 GOOGLE_API_KEY
genai.configure(api_key=load_google_api_key())
# 自动选择一个当前账号可用且支持 generateContent 的模型名
self.model_name = self._select_available_model()
# 用选择到的模型名创建模型对象
self.model = genai.GenerativeModel(self.model_name)
def _select_available_model(self) -> str:
"""
从账号可用模型中选择一个支持 generateContent 的模型。
返回值是模型名字符串(例如:models/gemini-1.5-flash)
"""
candidates: List[str] = [] # 存放候选模型名
# genai.list_models():向 Google 请求"当前 API Key 可用的模型列表"
for m in genai.list_models():
# 每个模型对象通常有 supported_generation_methods 属性
# 可能是 ['generateContent', ...]
methods = getattr(m, "supported_generation_methods", []) or []
# 只保留支持 generateContent 的模型(因为我们要用 generate_content)
if "generateContent" in methods:
candidates.append(m.name)
# 如果一个都没有,说明账号权限/计费/地区限制等有问题
if not candidates:
raise RuntimeError("当前账号没有任何支持 generateContent 的模型。")
# 优先选择更常用/性价比高的模型:
# 1) gemini-1.5-flash(快、便宜)
# 2) gemini-1.5-pro(更强)
for prefer in ("gemini-1.5-flash", "gemini-1.5-pro"):
for name in candidates:
if prefer in name:
return name
# 如果都不匹配,就返回列表第一个(兜底)
return candidates[0]
def generate(self, prompt: str, **kwargs: Any) -> str:
"""
生成文本的统一入口。
:param prompt: 用户输入文本
:param kwargs: 允许调用者覆盖生成参数,例如 temperature=0.2
:return: Gemini 返回的文本
"""
# generation_config:本次生成的参数
# kwargs 优先级更高:外部传了就覆盖默认 config
generation_config: Dict[str, Any] = {
"temperature": kwargs.get("temperature", self.config.temperature),
"max_output_tokens": kwargs.get("max_output_tokens", self.config.max_output_tokens),
"top_p": kwargs.get("top_p", self.config.top_p),
"top_k": kwargs.get("top_k", self.config.top_k),
}
# 调用 Gemini 的生成接口:
# - prompt:你要问的问题
# - generation_config:控制输出风格/长度
resp = self.model.generate_content(
prompt,
generation_config=generation_config
)
# resp.text:SDK 帮你拼好的纯文本输出(若为空则返回空字符串)
return resp.text or ""关键理解点
- 你之前的 404 本质是模型名不可用
- 我们用
list_models()自动选一个支持generateContent的模型 → 彻底规避
5) my_custom_llm.py(逐行解释 + 注释版)
python
from typing import Optional, Any # 类型提示
from my_llm import MyGeminiLLM, GeminiConfig # 复用基础封装和配置类
class MyCustomGeminiLLM(MyGeminiLLM):
"""
自定义 LLM:在基础 LLM 上增加"固定前缀"
这个前缀相当于:系统提示词 / 角色设定 / 固定上下文
"""
def __init__(self, prefix: str, config: Optional[GeminiConfig] = None):
# 把 prefix 存起来,strip 去掉首尾空白
self.prefix = prefix.strip()
# 调用父类初始化:加载 key、选模型、创建 model
super().__init__(config=config)
def generate(self, prompt: str, **kwargs: Any) -> str:
# 如果 prefix 非空,把 prefix + 用户输入拼成最终 prompt
if self.prefix:
final_prompt = f"{self.prefix}\n\n用户:{prompt}\n助手:"
else:
final_prompt = prompt
# 调用父类 generate 实际请求 Gemini
return super().generate(final_prompt, **kwargs)为什么这种"拼前缀"有效?
LLM 的输入本质是文本。
你给它一段"角色设定/约束",再给问题,它就会倾向遵守这些规则。
6) list_models.py(逐行解释 + 注释版)
python
import google.generativeai as genai # Gemini SDK
from env_utils import load_google_api_key # 读取 API Key
def main():
# 配置 SDK 鉴权
genai.configure(api_key=load_google_api_key())
# list_models():打印当前账号可用模型
for m in genai.list_models():
# m.name:模型名(例如 models/gemini-1.5-flash)
# supported_generation_methods:支持的方法列表
print(m.name, getattr(m, "supported_generation_methods", None))
if __name__ == "__main__":
# 只有当你直接运行 python list_models.py 时,才会执行 main()
main()7) test_llm/__init__.py(逐行解释 + 注释版)
python
from my_llm import MyGeminiLLM, GeminiConfig # 基础 LLM 和配置
from my_custom_llm import MyCustomGeminiLLM # 带前缀的 LLM
def main():
# ===== 1) 测试基础 LLM =====
llm = MyGeminiLLM(
GeminiConfig(
temperature=0.7, # 输出相对自然
max_output_tokens=512 # 输出不宜太长,便于观察
)
)
# 调用 generate 生成文本
print(llm.generate("用中文解释什么是 REST API,并给一个简单例子。"))
# ===== 2) 测试带前缀的 LLM =====
prefix = "你是一名资深后端工程师,回答要结构化,包含概念、要点、示例。"
# 创建带前缀的 LLM
llm2 = MyCustomGeminiLLM(prefix)
# 生成文本:会自动把 prefix 拼到 prompt 前面
print(llm2.generate("解释 DTO 和 Map 的区别,并说明常见互转方式。"))
if __name__ == "__main__":
# python -m test_llm 或直接运行本文件时,会从这里开始
main()最后,写个前端页面,用 FastAPI调 Gemini 后端
目标很明确:
后端:Python(FastAPI + 现在的 LLM 代码)
前端:一个最简单的 HTML 页面
功能:
在网页输入问题 → 点按钮 → 后端调用 Gemini → 返回答案 → 页面显示
新增 2 个文件即可:
PythonProject23/
├── app.py ← FastAPI 后端
├── templates/
│ └── index.html ← 前端页面

index.html
html
<!DOCTYPE html>
<html lang="zh">
<head>
<meta charset="UTF-8">
<title>Gemini 问答</title>
</head>
<body>
<h2>Gemini 问答测试</h2>
<textarea id="question" rows="5" cols="60" placeholder="请输入你的问题"></textarea>
<br><br>
<button onclick="ask()">提交</button>
<h3>回答:</h3>
<pre id="answer"></pre>
<script>
function ask() {
const question = document.getElementById("question").value;
fetch("/ask", {
method: "POST",
headers: {
"Content-Type": "application/json"
},
body: JSON.stringify({
question: question
})
})
.then(response => response.json())
.then(data => {
document.getElementById("answer").innerText = data.answer;
})
.catch(err => {
alert("请求失败:" + err);
});
}
</script>
</body>
</html>
python
from fastapi import FastAPI
from fastapi.responses import HTMLResponse, JSONResponse
from pydantic import BaseModel
# 引入你已经写好的 LLM
from my_llm import MyGeminiLLM
# 1️⃣ 创建 FastAPI 应用
app = FastAPI()
# 2️⃣ 创建一个 LLM 实例(整个程序共用一个)
llm = MyGeminiLLM()
# 3️⃣ 定义"前端传过来的数据格式"
class QuestionRequest(BaseModel):
question: str
# 4️⃣ 首页接口:返回 HTML 页面
@app.get("/", response_class=HTMLResponse)
def index():
# 直接返回一个 HTML 文件内容
with open("templates/index.html", "r", encoding="utf-8") as f:
return f.read()
# 5️⃣ 给前端用的 API 接口
@app.post("/ask")
def ask_question(req: QuestionRequest):
"""
前端会 POST 一个 JSON:
{
"question": "你好"
}
"""
answer = llm.generate(req.question)
# 返回 JSON 给前端
return JSONResponse({
"answer": answer
})执行效果:

前端效果 大道至简 : 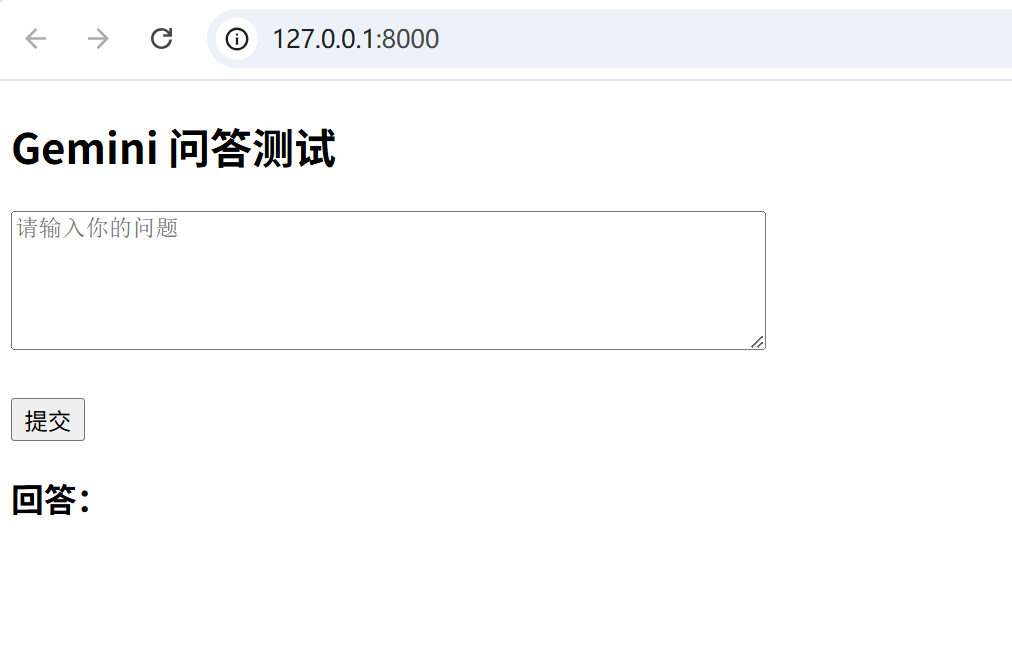
前后端能跑通:
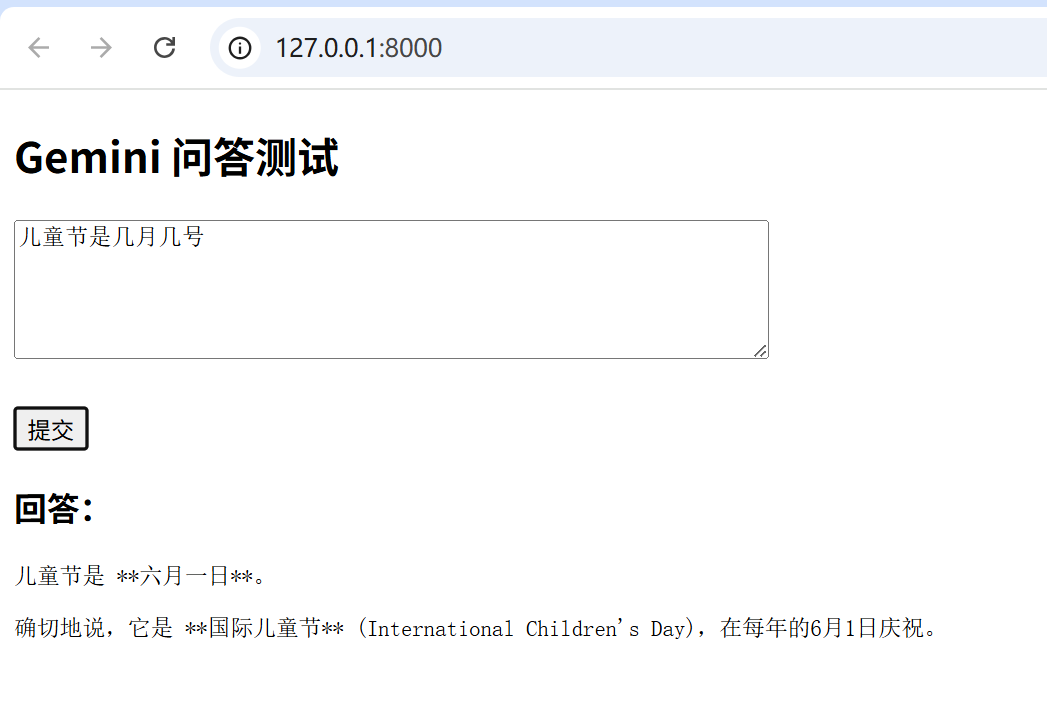
家人们,赶快在你的简历上,吹起来吧。