Kubernetes是一种非常流行的容器编排平台,旨在大规模管理分布式应用程序。它具有许多用于部署、扩展和管理容器的高级功能,使软件工程师能够构建高度灵活且具有弹性的基础设施。
此外,值得注意的是,它是一款开源软件,提供声明式应用程序部署方法,并支持跨多个节点的无缝扩展和负载平衡。 Kubernetes 具有内置的容错和自我修复功能,可确保您的应用程序具有高可用性和弹性。
Kubernetes 的关键优势之一是它能够自动执行许多操作任务,抽象基础设施的底层复杂性,使开发人员能够专注于应用程序逻辑,并优化解决方案的性能。
什么是 ChatGPT?
您可能听说过很多关于ChatGPT 的事情,它是一种著名的语言模型,彻底改变了自然语言处理(NLP)领域。ChatGPT 由OpenAI构建,由先进的人工智能算法提供支持,并针对大量文本数据进行训练。
ChatGPT 的多功能性不仅限于虚拟助手和聊天机器人,因为它可以应用于各种自然语言处理应用程序。它能够理解和生成类似人类的文本,这使它成为自动执行涉及理解和处理书面语言的任务的宝贵工具。
ChatGPT 背后的底层技术基于深度学习和转换模型。ChatGPT 训练过程涉及将模型暴露于来自各种来源的大量文本数据。
这种广泛的训练有助于它学习语言的复杂性,包括语法、语义和常见模式。此外,使用特定数据调整模型的能力意味着它可以定制以在特定领域或专门任务中表现出色。
将 ChatGPT (OpenAI) 与 Kubernetes 集成:概述
将 Kubernetes 与 ChatGPT 集成,可以自动执行与 Kubernetes 集群中部署的应用程序的操作和管理相关的任务。因此,利用 ChatGPT,您可以使用文本或语音命令与 Kubernetes 无缝交互,从而更高效地执行复杂操作。
本质上,通过这种集成,您可以简化各种任务,例如;
- 部署应用程序
- 扩展资源
- 监控集群健康
通过集成,您可以利用 ChatGPT 的上下文语言生成功能以自然直观的方式与 Kubernetes 进行通信。
无论您是开发人员、系统管理员还是 DevOps 专业人员,此集成都可以彻底改变您的运营方式并简化您的工作流程。结果是您可以有更多空间专注于更高级别的战略计划并提高整体生产力。
将 ChatGPT (OpenAI) 与 Kubernetes 集成的好处
- **自动化:**这种集成简化并自动化了操作流程,减少了人工干预的需要。
- **效率:**可以快速、更准确地执行操作,从而优化时间和资源。
- 可扩展性: Kubernetes 提供自动扩展功能,使 ChatGPT 无需额外努力即可扩展应用程序。
- 监控: ChatGPT 可以提供有关 Kubernetes 集群和应用程序状态的实时信息,促进问题检测和解决。
如何将 ChatGPT (OpenAI) 与 Kubernetes 集成:分步指南
至此,我们了解您已经拥有适合集成的环境,包括Kubernetes的安装和用于 ChatGPT 呼叫的 OpenAI 帐户。
让我们继续向您展示如何配置 ChatGPT 访问 Kubernetes 的凭据,并使用`kubernetes-client`自动化脚本中的库与 Kubernetes 进行交互。
首先,在 OpenAI 平台上创建你的Token :
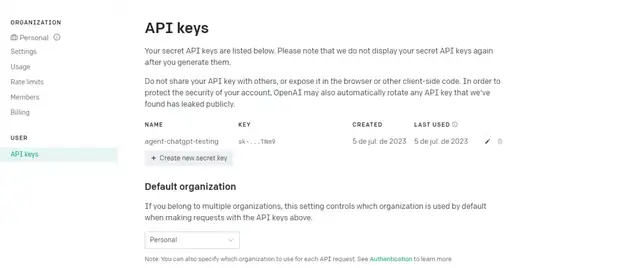
我们会将有关状态的消息转发到Slack,如果 Kubernetes 出现问题,ChatGPT 会提出可能的解决方案。
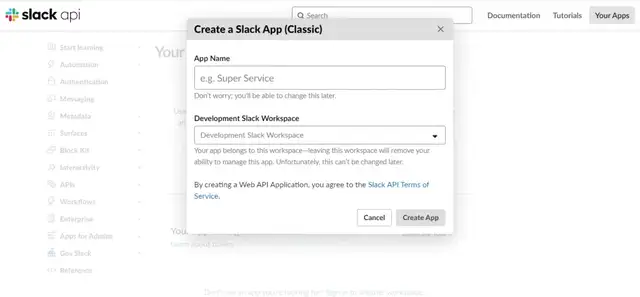
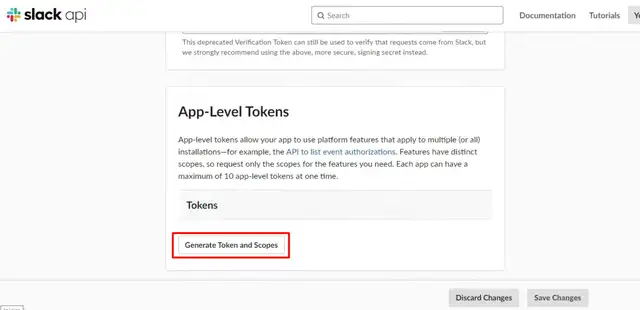
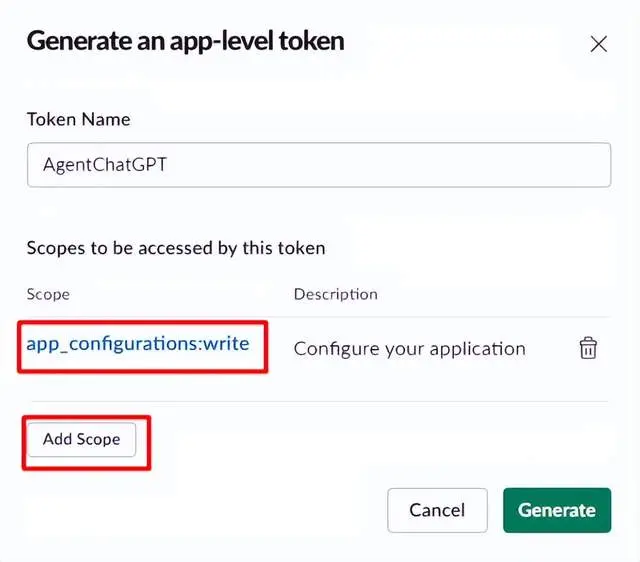
太好了,现在让我们配置 AgentChatGPT 脚本,记得更改这一点:
- Bearer <你的令牌>
- 客户端 = WebClient(token="<你的令牌>"
- channel_id = "<你的频道 ID>"
Python
导入 请求 br
从 slack_sdk 导入 WebClient br
从 kubernetes 导入 客户端,配置 br
br
# 与 GPT 模型交互的函数br
def interagir_chatgpt(消息): br
端点= "https://api.openai.com/v1/chat/completions" br
提示= "用户:" + 消息 br
br
响应=请求.post ( br
终点, br
标题={ br
"授权":"持有人", br
"内容类型":"application/json", br
}, br
json ={ br
"模型":"GPT-3.5-Turbo", br
"消息":[{ "角色":"系统","内容":提示}], br
}, br
)br
br
响应数据=响应.json ( ) br
chatgpt_response = response_data [ "选择" ][ 0 ][ "消息" ][ "内容" ] br
br
返回 chatgpt_response br
br
# 向 Slack 发送通知的函数br
def send_notification_slack(消息): br
客户端= WebClient(令牌= "") br
频道ID = ""br
br
响应=客户端.chat_postMessage (频道= channel_id,文本=消息)br
br
返回 响应 br
br
# Kubernetes 配置br
配置. load_kube_config ()br
v1 =客户端.CoreV1Api ( )br
br
# Kubernetes 集群监控br
def surveillance_cluster_kubernetes(): br
而 True:br
# 收集 Kubernetes 集群指标、日志和事件br
def get_information_cluster(): br
# 收集 Kubernetes 集群指标的逻辑 br
指标= v1.list_node () br
br
# 收集 Kubernetes 集群日志的逻辑 br
日志= v1 . read_namespaced_pod_log ( "POD_NAME" , "NAMESPACE" ) br
br
# 收集 Kubernetes 集群事件的逻辑 br
事件= v1.list_event_for_all_namespaces ()br
br
返回 指标、日志、事件 br
br
# 根据收集到的信息进行故障排除br
def determine_problems(指标,日志,事件): br
问题= [] br
br
# 分析指标和识别问题的逻辑 br
对于 指标中的指标 .项目: br
如果 metric.status.conditions为None或metric.status.conditions [ - 1 ] .type ! = " Ready " : br
问题.附加( f"节点 {metric.metadata.name} 未准备好。" ) br
br
# 分析日志并识别问题的逻辑 br
如果 日志中出现"ERROR" : br
problems.append ( "在pod 日志中发现错误。" ) br
br
# 分析事件和识别问题的逻辑 br
对于 events中的eveno 。项目: br
如果 evento.type == "警告" :br
问题.附加( f "已记录警告事件:{event.message}" ) br
br
退货 问题br
# Kubernetes 集群监控br
def surveillance_cluster_kubernetes(): br
而 True: br
指标,日志,事件= get_information_cluster() br
问题=识别问题(指标、日志、事件) br
br
如果 出现问题: br
# 处理已发现问题的逻辑 br
对于 问题中的问题 : br
# 单独处理每个问题的逻辑 br
# 可能包括纠正措施、附加通知等。 br
打印(f"已识别问题:{problem}") br
br
# 在检查之间等待时间间隔的逻辑 br
time.sleep ( 60 ) # 等待1分钟后再进行下一个检查br
br
# 运行 ChatGPT 代理并监控 Kubernetes 集群br
如果 __name__ == "__main__": br
监控_集群_kubernetes()br
br
如果 检测到问题: br
# 使用 ChatGPT 生成故障排除建议的逻辑 br
resposta_chatgpt = interact_chatgpt (描述问题) br
br
# 向 Slack 发送问题描述通知,br
推荐 br
br
message_slack = f"已识别问题:br
{ description_problem } \ n建议:{ response_chatgpt } "br
br
发送通知延迟(消息延迟)br
br
# 运行 ChatGPT 代理并监控 Kubernetes 集群br
如果 __name__ == "__main__": br
monitorar_cluster_kubernetes()现在使用 Dockerfile 示例通过 ChatGPT Agent 构建您的容器,记住需要使用您的 Kube 配置创建卷:
Dockerfile
# 定义基础镜像br
来自 python:3.9-slimbr
br
# 将 Python 脚本复制到图像的工作目录br
复制 agent-chatgpt.py /app/agent-chatgpt.pybr
br
# 定义图像的工作目录br
工作目录 /appbr
br
# 安装所需的依赖项br
运行 pip 安装请求 slack_sdk kubernetesbr
br
# 镜像启动时运行 Python 脚本br
CMD ["python","agent-chatgpt.py"]如果一切配置正确,那么恭喜你。在监控的某个时刻运行脚本,你可能会收到类似这样的消息:

使用 Kubernetes 与 ChatGPT (OpenAI) 的最佳实践
安全
实施适当的安全措施来保护 ChatGPT 对 Kubernetes 的访问。
日志记录和监控
在 Kubernetes 集群中实施强大的日志记录和监控实践。使用Prometheus、Grafana或Elasticsearch等工具收集和分析来自 Kubernetes 集群和 ChatGPT 代理的日志和指标。
这将为您的集成系统的性能、健康和使用模式提供宝贵的见解。
错误处理和警报
建立全面的错误处理和警报系统,以便及时识别和应对集成过程中的任何问题或故障。本质上,为关键事件设置警报和通知,例如与 Kubernetes API 通信失败或 ChatGPT 代理中的意外错误。
这将帮助您主动解决问题并确保顺利运行。
可扩展性和负载平衡
在集成设置中规划可扩展性和负载平衡。考虑利用 Kubernetes 功能(如水平 Pod 自动扩展和负载平衡)来有效处理不同的工作负载和用户需求。
这将确保您的 ChatGPT 代理的最佳性能和响应能力,同时保持所需的可扩展性水平。
备份和灾难恢复
实施备份和灾难恢复机制以保护您的集成环境。定期备份 ChatGPT 代理使用的关键数据、配置和模型。
此外,创建并测试灾难恢复程序,以在系统故障或灾难发生时最大限度地减少停机时间和数据丢失。
持续集成和部署
实施强大的 CI/CD(持续集成/持续部署)管道,以简化集成系统的部署和更新。
此外,自动化 Kubernetes 基础设施和 ChatGPT 代理的构建、测试和部署流程,以确保可靠、高效的发布周期。
文档与协作
维护集成设置的详细文档,包括配置、部署步骤和故障排除指南。此外,鼓励从事集成工作的团队成员之间的协作和知识共享。
这将促进未来更好的协作、更顺畅的入职和有效的故障排除。
通过将这些额外的建议纳入您的集成方法中,您可以进一步增强 Kubernetes 和 ChatGPT 集成的可靠性、可扩展性和可维护性。
结论
将 Kubernetes 与 ChatGPT (OpenAI) 集成可为管理 Kubernetes 集群内的操作和应用程序带来诸多好处。通过遵循最佳实践并遵循本资源中提供的分步指南,您将能够充分利用 ChatGPT 的功能来自动执行任务并优化您的 Kubernetes 环境。
Kubernetes 先进的容器编排功能与 ChatGPT 的上下文语言生成相结合,使您能够简化操作、提高效率、实现可扩展性并促进实时监控。
无论是自动化部署、扩展应用程序还是解决问题,Kubernetes 和 ChatGPT 的集成都可以显著改善 Kubernetes 基础设施的管理和性能。
当您踏上这一集成之旅时,请记住优先考虑安全措施,确保持续监控,并考虑使用 Kubernetes 特定数据定制 ChatGPT 模型以获得更精确的结果。
维护版本控制和跟踪 Kubernetes 配置对于故障排除和未来更新也非常有价值。