WorkQueues模型
Work queues,任务模型。简单来说就是让多个消费者绑定到一个队列,共同消费队列中的消息 。
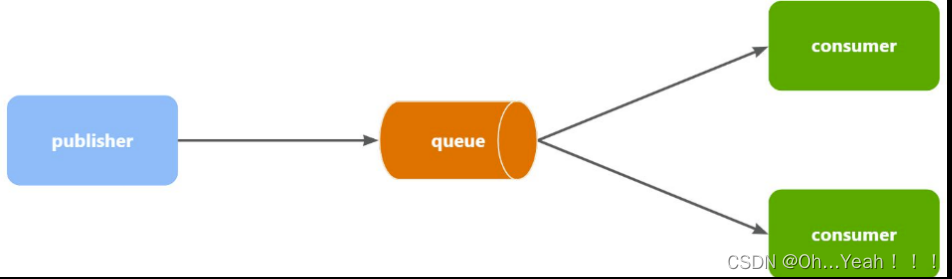
当消息处理比较耗时的时候,可能生产消息的速度会远远大于消息的消费速度。长此以往,消息就会堆积越来越多,无法及时处理。
此时就可以使用work 模型,多个消费者共同处理消息处理,消息处理的速度就能大大提高了。
接下来,我们就来模拟这样的场景。

首先,我们在控制台创建一个新的队列,命名为work.queue:
3.3.1.消息发送
这次我们循环发送,模拟大量消息堆积现象。
在publisher服务中的SpringAmqpTest类中添加一个测试方法:
java
/**
* workQueue
* 向队列中不停发送消息,模拟消息堆积。
*/
@Test
public void testWorkQueue() throws InterruptedException {
// 队列名称
String queueName = "work.queue";
// 消息
String message = "hello, message_";
for (int i = 0; i < 50; i++) {
// 发送消息,每20毫秒发送一次,相当于每秒发送50条消息
rabbitTemplate.convertAndSend(queueName, message + i);
Thread.sleep(20);
}
}3.3.2.消息接收
要模拟多个消费者绑定同一个队列,我们在consumer服务的SpringRabbitListener中添加2个新的方法:
java
@RabbitListener(queues = "work.queue")
public void listenWorkQueue1(String msg) throws InterruptedException {
System.out.println("消费者1接收到消息:【" + msg + "】" + LocalTime.now());
Thread.sleep(20);
}
@RabbitListener(queues = "work.queue")
public void listenWorkQueue2(String msg) throws InterruptedException {
System.err.println("消费者2........接收到消息:【" + msg + "】" + LocalTime.now());
Thread.sleep(200);
}注意到这两消费者,都设置了Thead.sleep,模拟任务耗时:
- 消费者1 sleep了20毫秒,相当于每秒钟处理50个消息
- 消费者2 sleep了200毫秒,相当于每秒处理5个消息
3.3.3.测试
启动ConsumerApplication后,在执行publisher服务中刚刚编写的发送测试方法testWorkQueue。
最终结果如下:
java
消费者1接收到消息:【hello, message_0】21:06:00.869555300
消费者2........接收到消息:【hello, message_1】21:06:00.884518
消费者1接收到消息:【hello, message_2】21:06:00.907454400
消费者1接收到消息:【hello, message_4】21:06:00.953332100
消费者1接收到消息:【hello, message_6】21:06:00.997867300
消费者1接收到消息:【hello, message_8】21:06:01.042178700
消费者2........接收到消息:【hello, message_3】21:06:01.086478800
消费者1接收到消息:【hello, message_10】21:06:01.087476600
消费者1接收到消息:【hello, message_12】21:06:01.132578300
消费者1接收到消息:【hello, message_14】21:06:01.175851200
消费者1接收到消息:【hello, message_16】21:06:01.218533400
消费者1接收到消息:【hello, message_18】21:06:01.261322900
消费者2........接收到消息:【hello, message_5】21:06:01.287003700
消费者1接收到消息:【hello, message_20】21:06:01.304412400
消费者1接收到消息:【hello, message_22】21:06:01.349950100
消费者1接收到消息:【hello, message_24】21:06:01.394533900
消费者1接收到消息:【hello, message_26】21:06:01.439876500
消费者1接收到消息:【hello, message_28】21:06:01.482937800
消费者2........接收到消息:【hello, message_7】21:06:01.488977100
消费者1接收到消息:【hello, message_30】21:06:01.526409300
消费者1接收到消息:【hello, message_32】21:06:01.572148
消费者1接收到消息:【hello, message_34】21:06:01.618264800
消费者1接收到消息:【hello, message_36】21:06:01.660780600
消费者2........接收到消息:【hello, message_9】21:06:01.689189300
消费者1接收到消息:【hello, message_38】21:06:01.705261
消费者1接收到消息:【hello, message_40】21:06:01.746927300
消费者1接收到消息:【hello, message_42】21:06:01.789835
消费者1接收到消息:【hello, message_44】21:06:01.834393100
消费者1接收到消息:【hello, message_46】21:06:01.875312100
消费者2........接收到消息:【hello, message_11】21:06:01.889969500
消费者1接收到消息:【hello, message_48】21:06:01.920702500
消费者2........接收到消息:【hello, message_13】21:06:02.090725900
消费者2........接收到消息:【hello, message_15】21:06:02.293060600
消费者2........接收到消息:【hello, message_17】21:06:02.493748
消费者2........接收到消息:【hello, message_19】21:06:02.696635100
消费者2........接收到消息:【hello, message_21】21:06:02.896809700
消费者2........接收到消息:【hello, message_23】21:06:03.099533400
消费者2........接收到消息:【hello, message_25】21:06:03.301446400
消费者2........接收到消息:【hello, message_27】21:06:03.504999100
消费者2........接收到消息:【hello, message_29】21:06:03.705702500
消费者2........接收到消息:【hello, message_31】21:06:03.906601200
消费者2........接收到消息:【hello, message_33】21:06:04.108118500
消费者2........接收到消息:【hello, message_35】21:06:04.308945400
消费者2........接收到消息:【hello, message_37】21:06:04.511547700
消费者2........接收到消息:【hello, message_39】21:06:04.714038400
消费者2........接收到消息:【hello, message_41】21:06:04.916192700
消费者2........接收到消息:【hello, message_43】21:06:05.116286400
消费者2........接收到消息:【hello, message_45】21:06:05.318055100
消费者2........接收到消息:【hello, message_47】21:06:05.520656400
消费者2........接收到消息:【hello, message_49】21:06:05.723106700可以看到消费者1和消费者2竟然每人消费了25条消息:
- 消费者1很快完成了自己的25条消息
- 消费者2却在缓慢的处理自己的25条消息。
也就是说消息是平均分配给每个消费者,并没有考虑到消费者的处理能力。导致1个消费者空闲,另一个消费者忙的不可开交。没有充分利用每一个消费者的能力,最终消息处理的耗时远远超过了1秒。这样显然是有问题的。
3.3.4.能者多劳(prefetch)
在spring中有一个简单的配置,可以解决这个问题。我们修改consumer服务的application.yml文件,添加配置:
yaml
spring:
rabbitmq:
listener:
simple:
prefetch: 1 # 每次只能获取一条消息,处理完成才能获取下一个消息再次测试,发现结果如下:
java
消费者1接收到消息:【hello, message_0】21:12:51.659664200
消费者2........接收到消息:【hello, message_1】21:12:51.680610
消费者1接收到消息:【hello, message_2】21:12:51.703625
消费者1接收到消息:【hello, message_3】21:12:51.724330100
消费者1接收到消息:【hello, message_4】21:12:51.746651100
消费者1接收到消息:【hello, message_5】21:12:51.768401400
消费者1接收到消息:【hello, message_6】21:12:51.790511400
消费者1接收到消息:【hello, message_7】21:12:51.812559800
消费者1接收到消息:【hello, message_8】21:12:51.834500600
消费者1接收到消息:【hello, message_9】21:12:51.857438800
消费者1接收到消息:【hello, message_10】21:12:51.880379600
消费者2........接收到消息:【hello, message_11】21:12:51.899327100
消费者1接收到消息:【hello, message_12】21:12:51.922828400
消费者1接收到消息:【hello, message_13】21:12:51.945617400
消费者1接收到消息:【hello, message_14】21:12:51.968942500
消费者1接收到消息:【hello, message_15】21:12:51.992215400
消费者1接收到消息:【hello, message_16】21:12:52.013325600
消费者1接收到消息:【hello, message_17】21:12:52.035687100
消费者1接收到消息:【hello, message_18】21:12:52.058188
消费者1接收到消息:【hello, message_19】21:12:52.081208400
消费者2........接收到消息:【hello, message_20】21:12:52.103406200
消费者1接收到消息:【hello, message_21】21:12:52.123827300
消费者1接收到消息:【hello, message_22】21:12:52.146165100
消费者1接收到消息:【hello, message_23】21:12:52.168828300
消费者1接收到消息:【hello, message_24】21:12:52.191769500
消费者1接收到消息:【hello, message_25】21:12:52.214839100
消费者1接收到消息:【hello, message_26】21:12:52.238998700
消费者1接收到消息:【hello, message_27】21:12:52.259772600
消费者1接收到消息:【hello, message_28】21:12:52.284131800
消费者2........接收到消息:【hello, message_29】21:12:52.306190600
消费者1接收到消息:【hello, message_30】21:12:52.325315800
消费者1接收到消息:【hello, message_31】21:12:52.347012500
消费者1接收到消息:【hello, message_32】21:12:52.368508600
消费者1接收到消息:【hello, message_33】21:12:52.391785100
消费者1接收到消息:【hello, message_34】21:12:52.416383800
消费者1接收到消息:【hello, message_35】21:12:52.439019
消费者1接收到消息:【hello, message_36】21:12:52.461733900
消费者1接收到消息:【hello, message_37】21:12:52.485990
消费者1接收到消息:【hello, message_38】21:12:52.509219900
消费者2........接收到消息:【hello, message_39】21:12:52.523683400
消费者1接收到消息:【hello, message_40】21:12:52.547412100
消费者1接收到消息:【hello, message_41】21:12:52.571191800
消费者1接收到消息:【hello, message_42】21:12:52.593024600
消费者1接收到消息:【hello, message_43】21:12:52.616731800
消费者1接收到消息:【hello, message_44】21:12:52.640317
消费者1接收到消息:【hello, message_45】21:12:52.663111100
消费者1接收到消息:【hello, message_46】21:12:52.686727
消费者1接收到消息:【hello, message_47】21:12:52.709266500
消费者2........接收到消息:【hello, message_48】21:12:52.725884900
消费者1接收到消息:【hello, message_49】21:12:52.746299900可以发现,由于消费者1处理速度较快,所以处理了更多的消息;消费者2处理速度较慢,只处理了6条消息。而最终总的执行耗时也在1秒左右,大大提升。
正所谓能者多劳,这样充分利用了每一个消费者的处理能力,可以有效避免消息积压问题。
3.3.5.总结(如何解决消息堆积的问题?)
Work模型的使用:
- 多个消费者绑定到一个队列,同一条消息只会被一个消费者处理
- 通过设置prefetch来控制消费者预取的消息数量
