小白上手AIGC-基于PAI-DSW部署Stable Diffusion文生图Lora模型
前言
在上一篇博文小白上手AIGC-基于FC部署stable-diffusion 中,说到基于函数计算应用模板部署AIGC文生图应用,部署后实验的参数比较局限,可选参数不多,因此不太能更好的深入体验AIGC,这一篇博文我们部署一款基于PAI-DSW部署Stable Diffusion文生图Lora模型,希望可以达到我们想要的效果。拭目以待...
资源准备
开启体验服务
再开始实验之前,我们需要先开通交互式建模PAI-DSW 的服务,趁着阿里云推出的免费试用的机会,赶快来体验吧,试用中心地址:阿里云免费试用 找到机器学习平台PAI的类别,点击【立即试用】

开通交互式建模PAI-DSW服务之后,需要创建默认工作空间,
创建工作空间
创建默认工作空间,官方文档地址:开通并创建默认工作空间,比如选择地域杭州
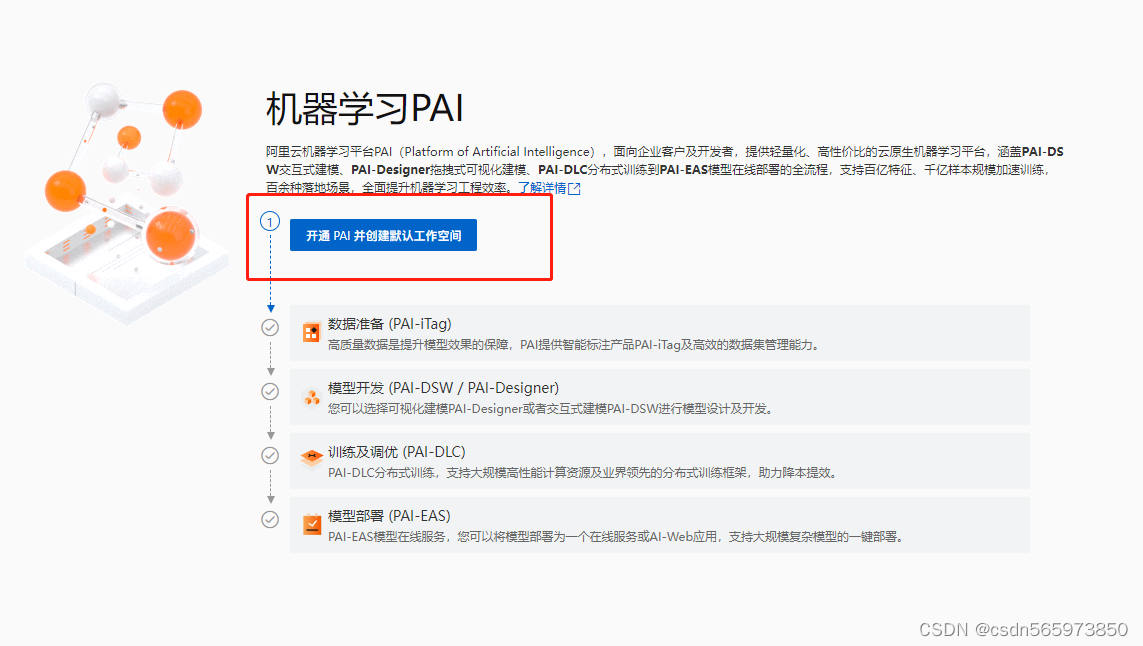
点击【开通PAI并创建默认工作空间】,完成授权及勾选操作
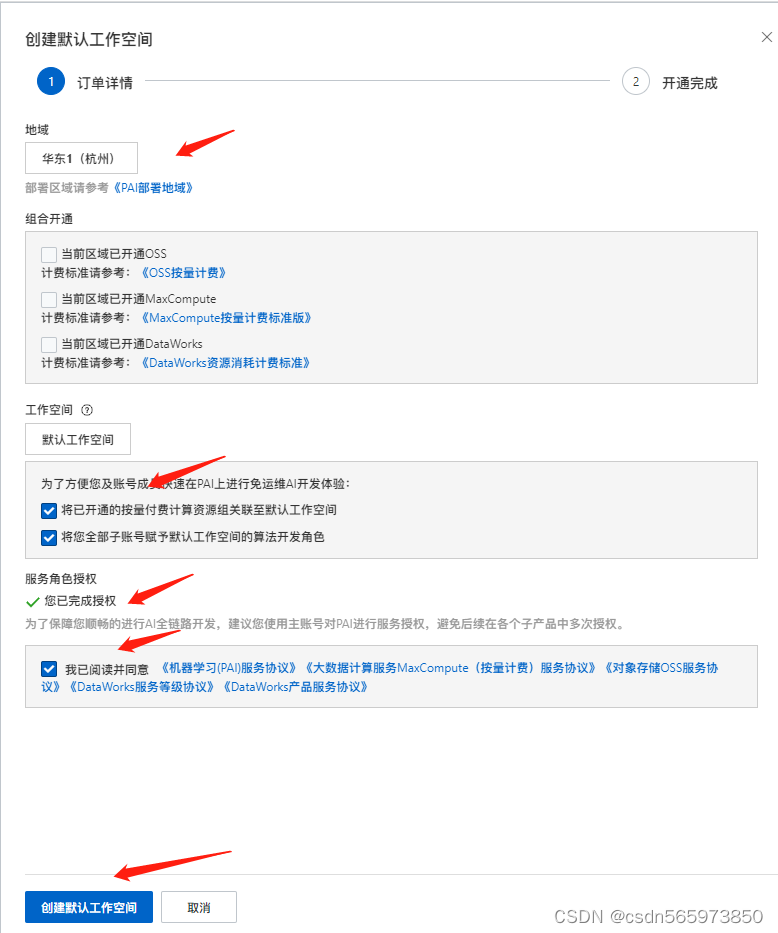
点击【确认开通并创建默认工作空间】完成默认工作空间的创建。
部署服务
回到PAI控制台首页,可以在工作空间列表中看到我们刚才创建的默认工作空间信息,
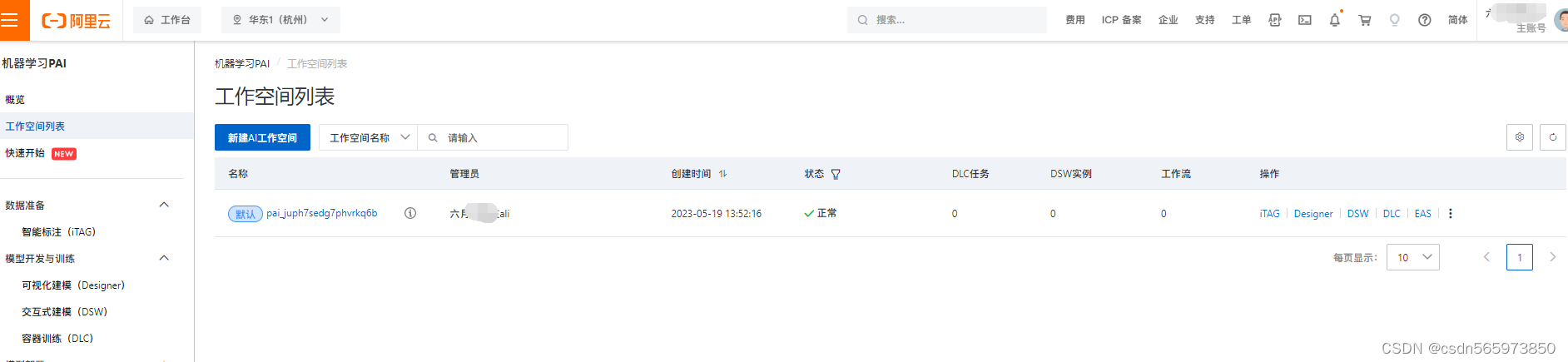
在控制台选择菜单【交互式建模(DSW)】
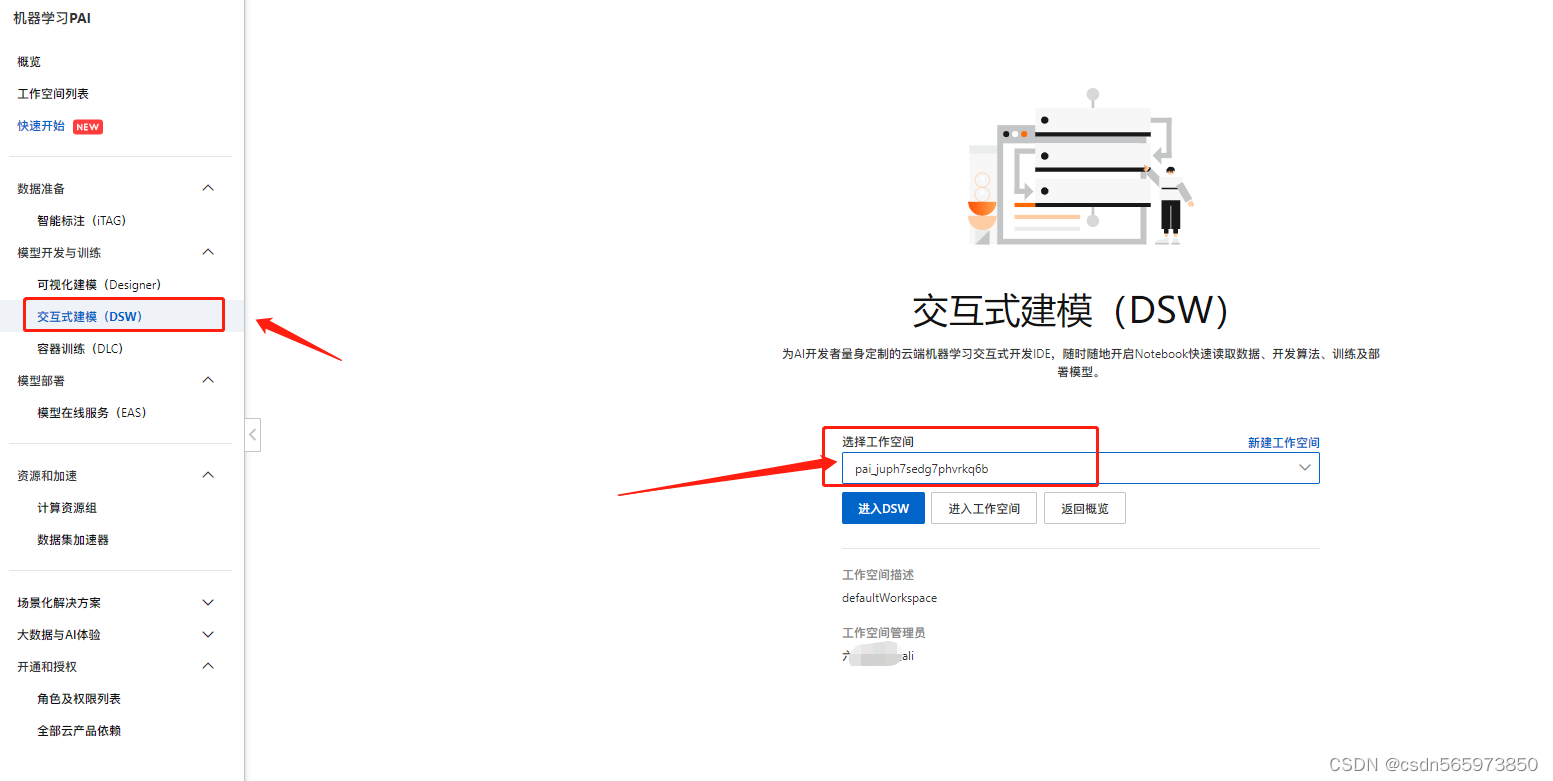
创建DSW实例
这里会默认选中我们刚才创建的工作空间,点击【进入DSW】
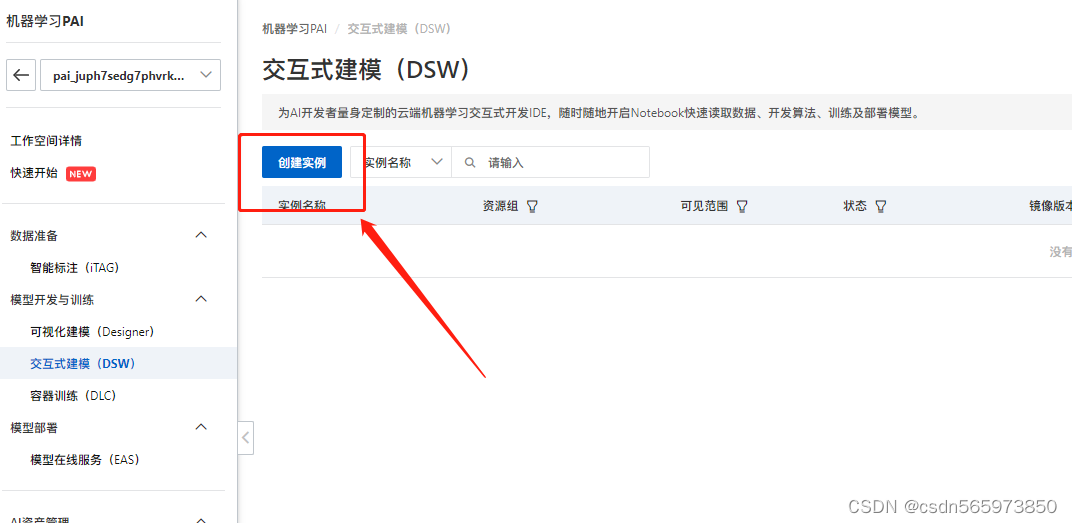
点击【创建实例】
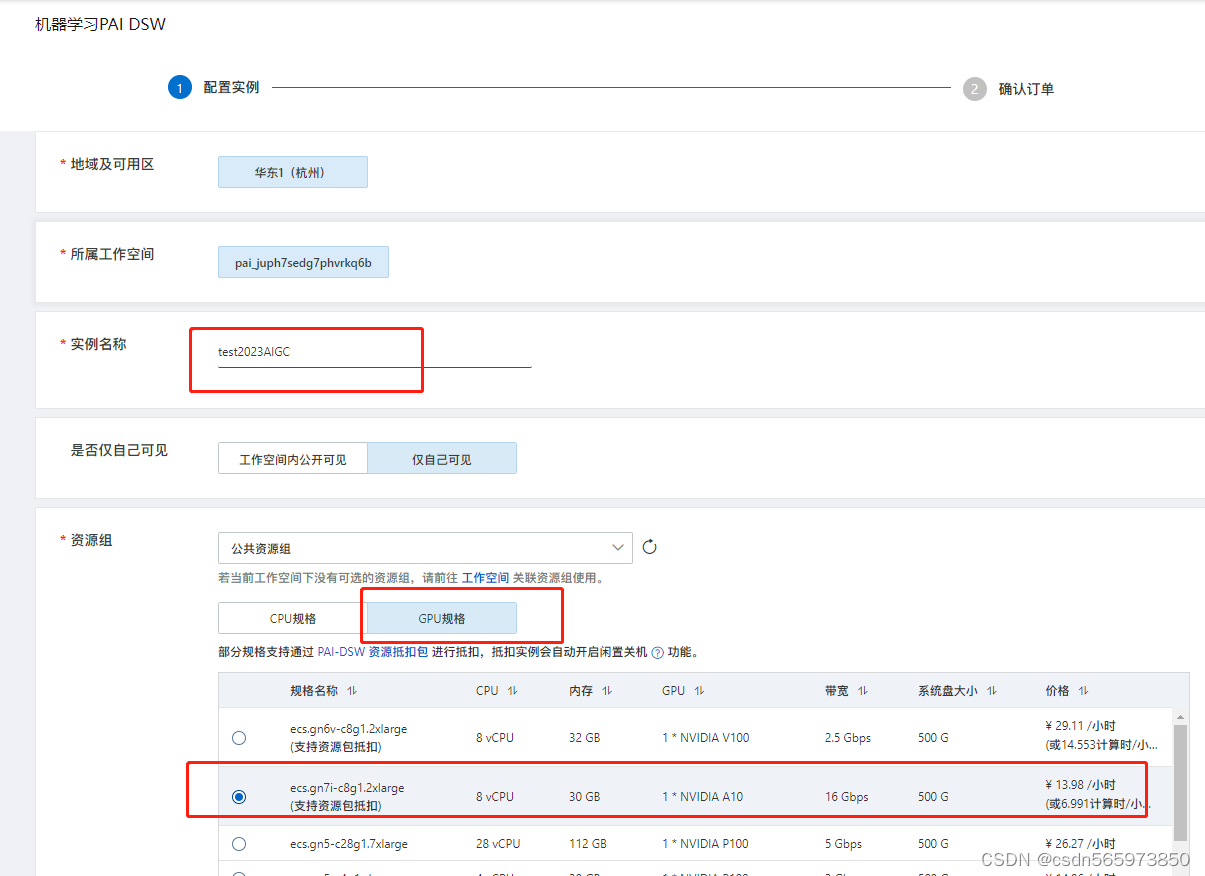
输入实例名称,点击tab 【GPU规格】,选择规格【ecs.gn7i-c8g1.2xlarge】
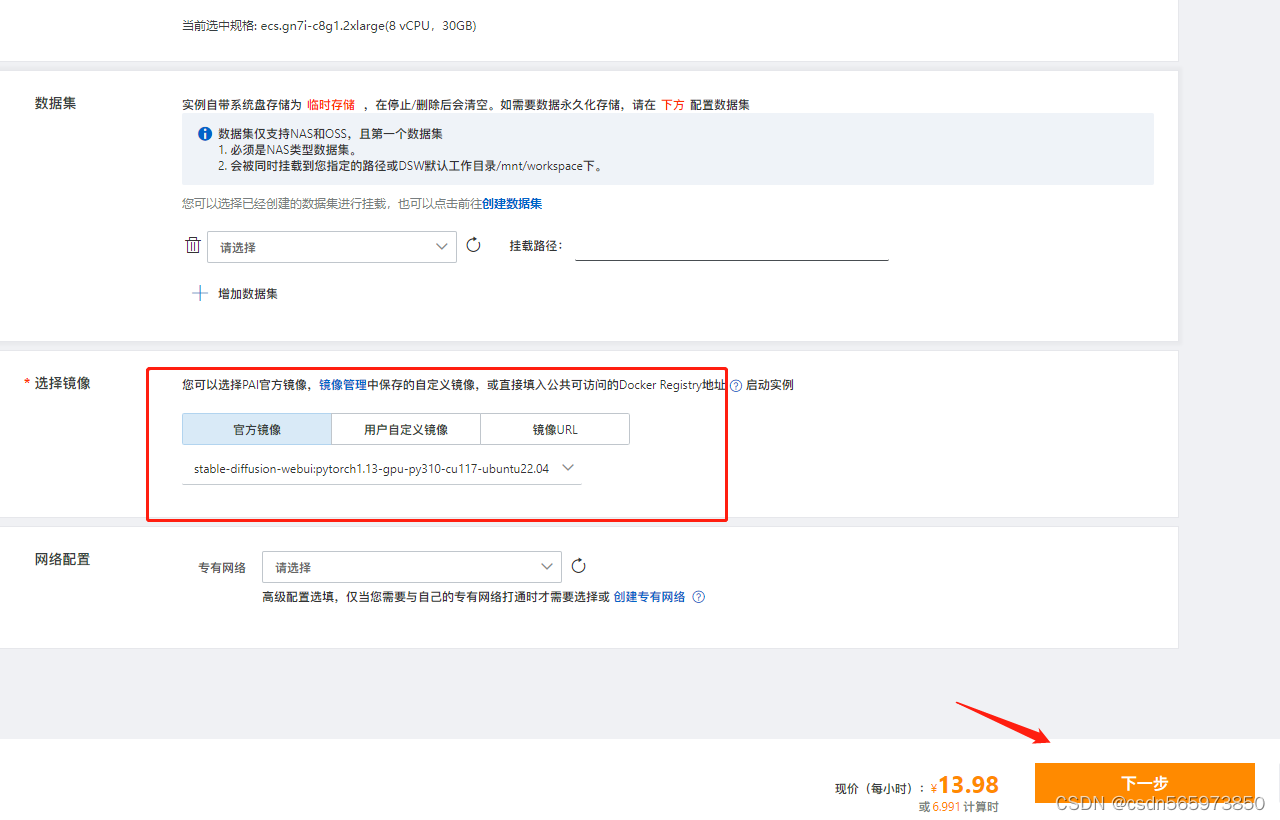
继续选择镜像【stable-diffusion-webui-env:pytorch1.13-gpu-py310-cu117-ubuntu22.04】点击【下一步】
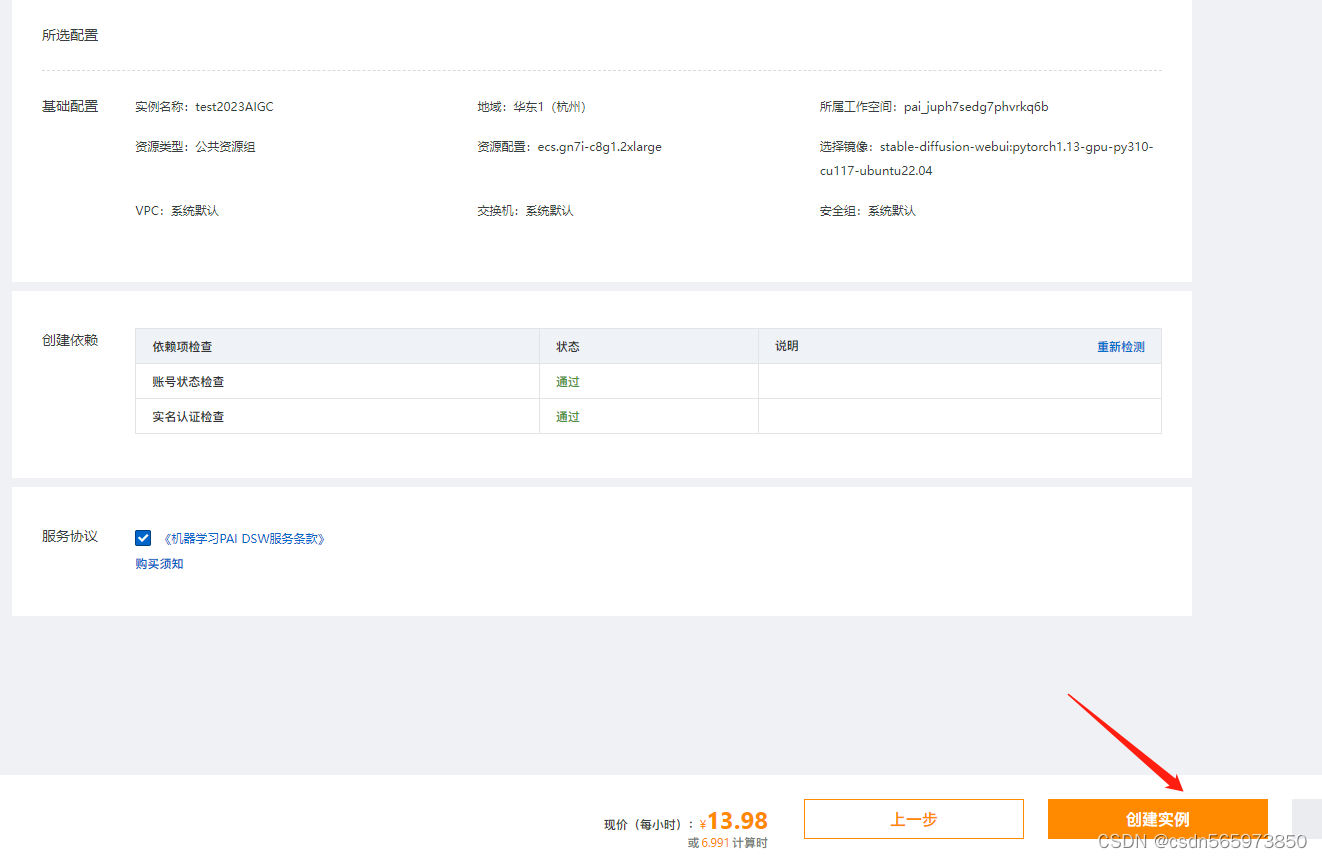
确认完信息之后点击【创建实例】
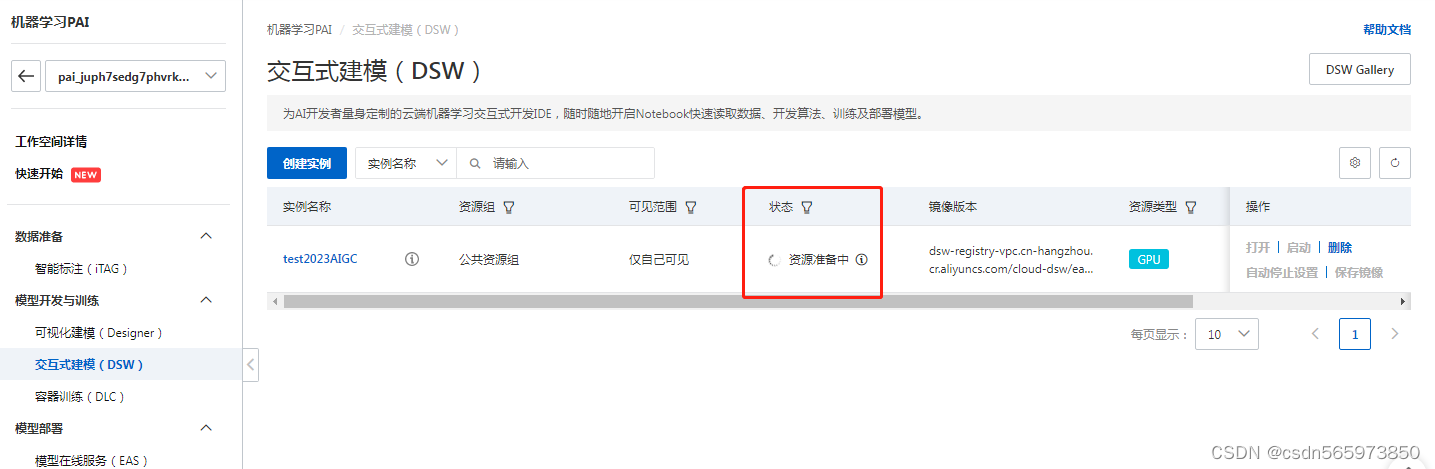
安装Diffusers
下载Diffusers开源库并安装,为后续下载stable-diffusion-webui开源库做准备。
点击【打开】

Notebook,选择【Python3】如图
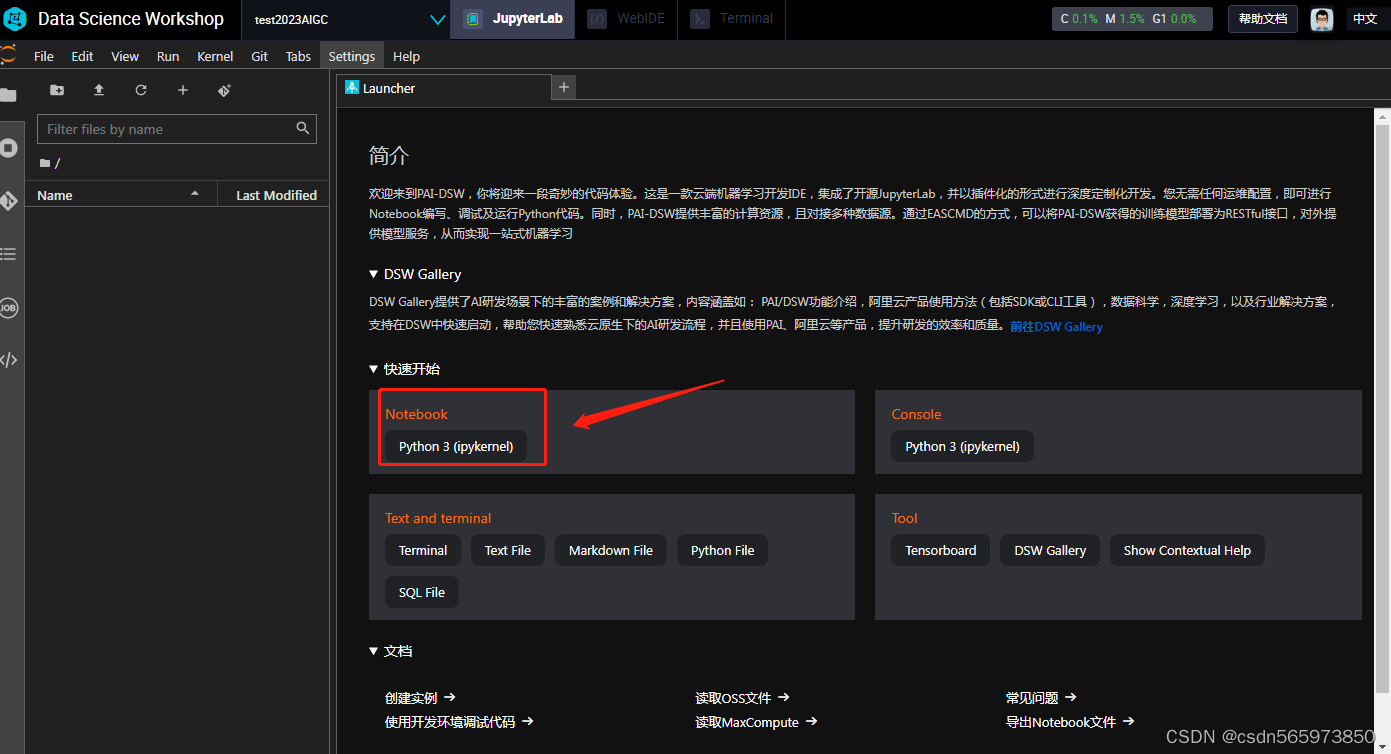
输入命令下载Diffusers开源库
shell
! git clone https://github.com/huggingface/diffusers下载开源库过程中,如果遇到超时的情况可以再次执行下载即可
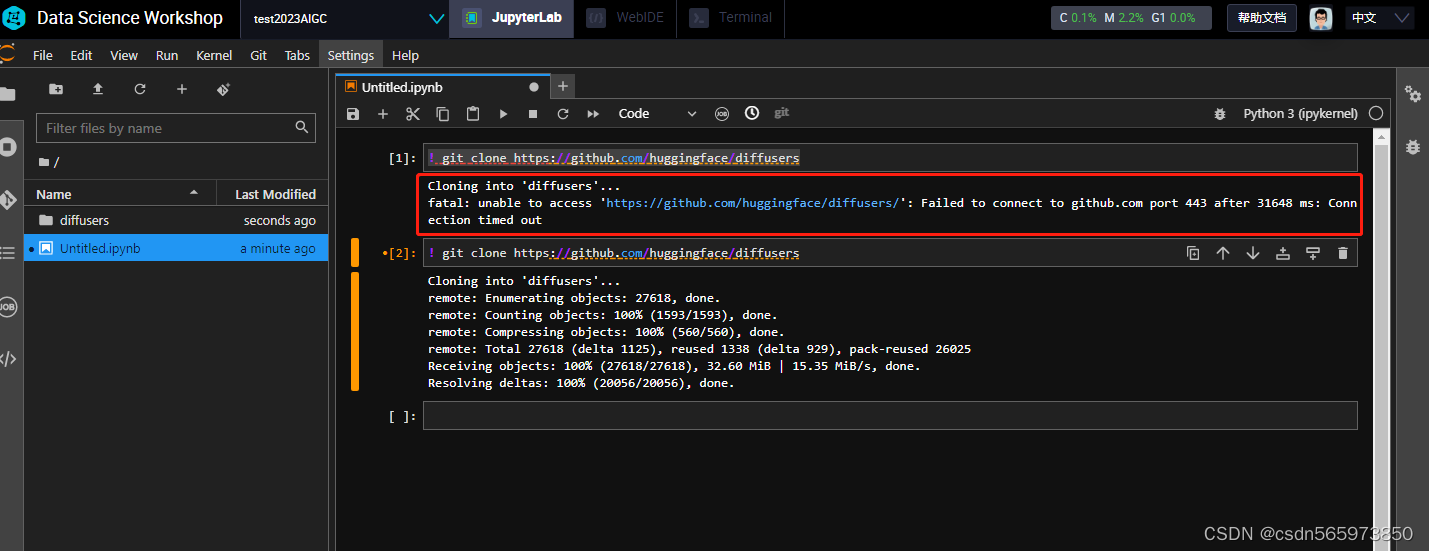
验证一下是否安装成功
shell
import diffusers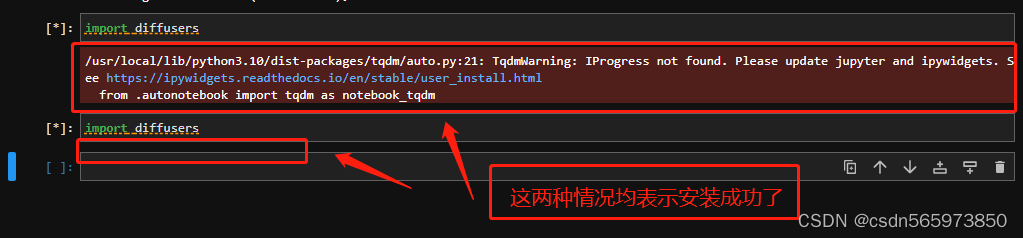
配置accelerate,选择Terminal输入配置命令
shell
accelerate config确认之后,通过键盘上下键选中This machine并确认
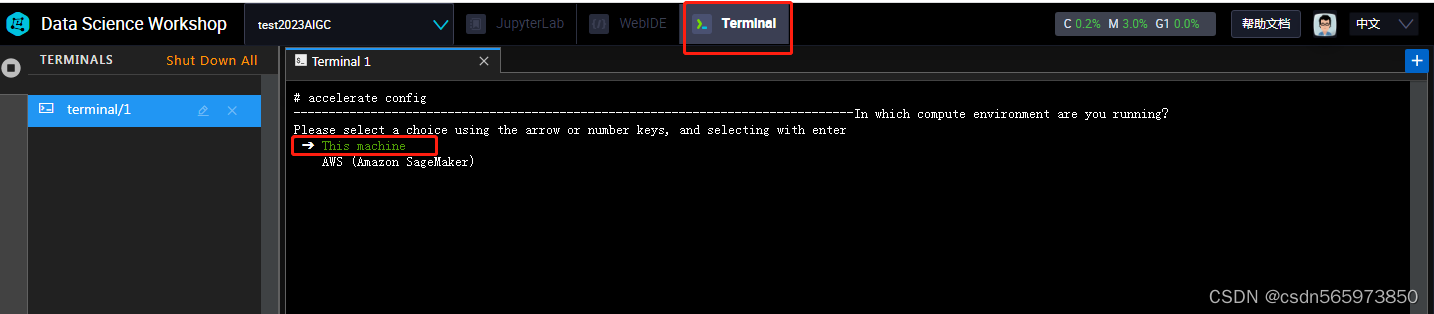
然后在选择multi-GPU
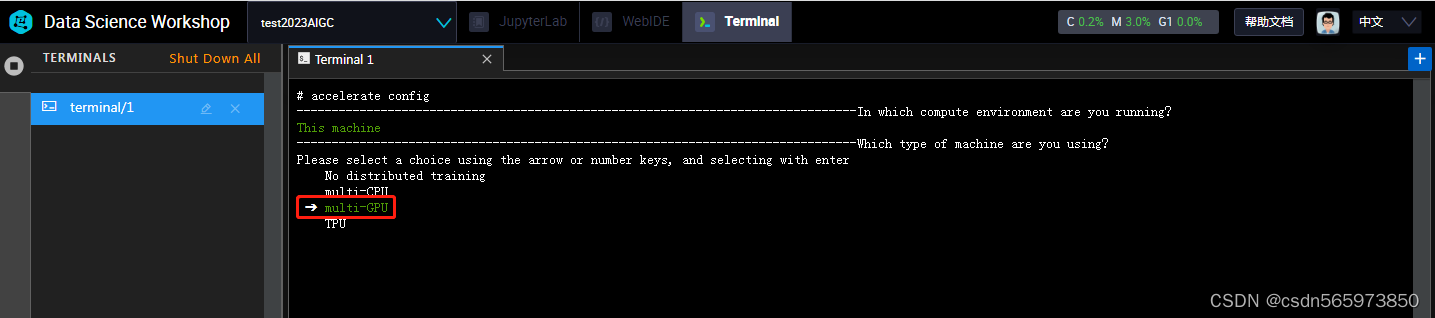
选中之后确认,后面的一次按截图的内容选择即可
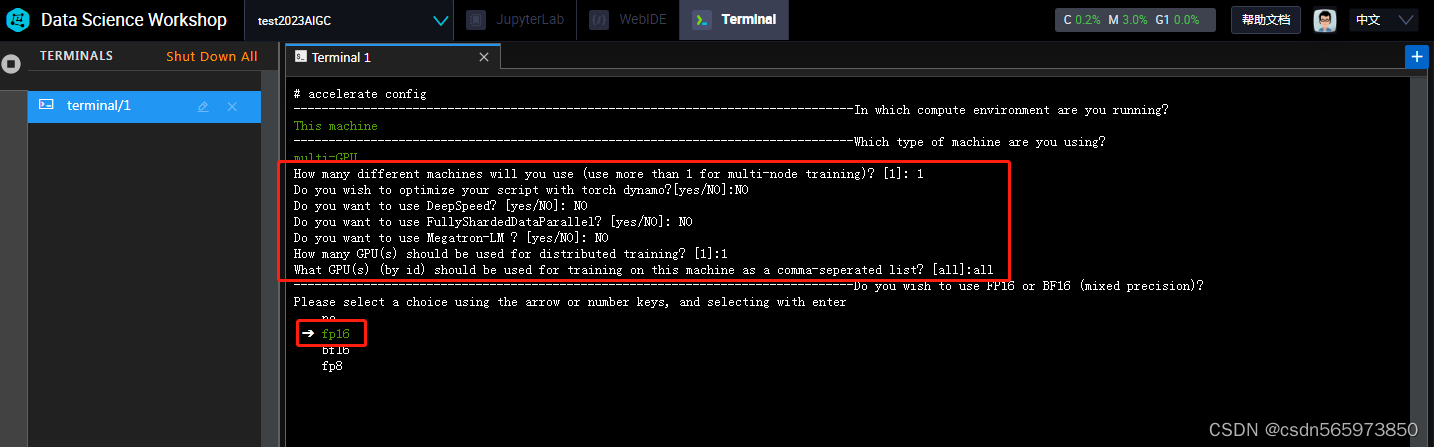
最后选中fp16 点击确认

此时可以看到accelerate配置完成了。下面继续回到python3页面安装文生图算法相关依赖库
shell
! cd diffusers/examples/text_to_image && pip install -r requirements.txt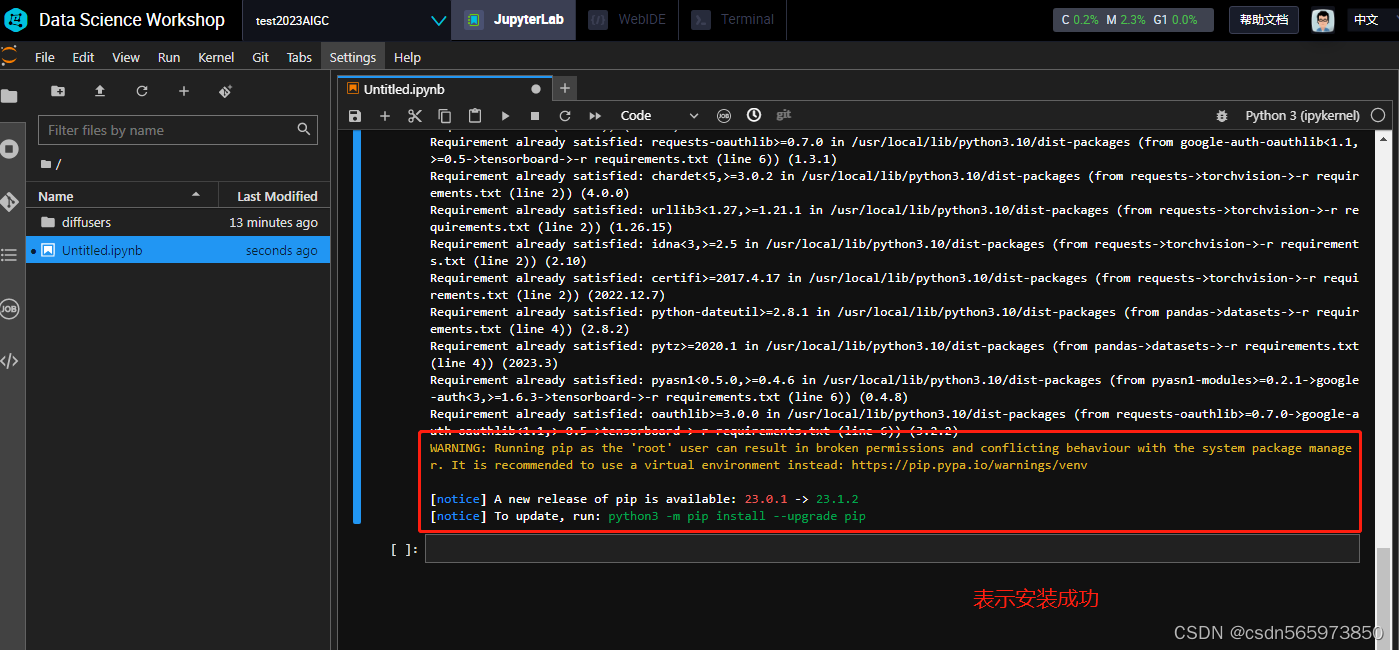
下面开始下载stable-diffusion-webui开源库,执行命令
shell
! git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git && \
cd stable-diffusion-webui && \
git checkout a9fed7c364061ae6efb37f797b6b522cb3cf7aa2
! cd stable-diffusion-webui && mkdir -p repositories && cd repositories && \
git clone https://github.com/sczhou/CodeFormer.git下载过程中如果遇到这种情况,再次执行以下命令就可以了
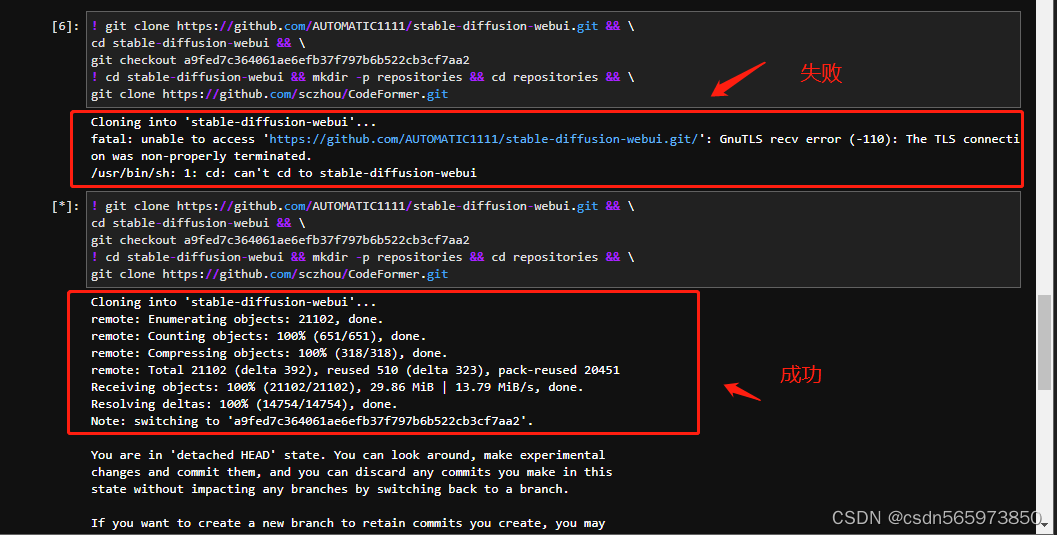
最后下载完成。继续下载示例数据集,后续会使用该数据集进行模型训练。执行如下命令
shell
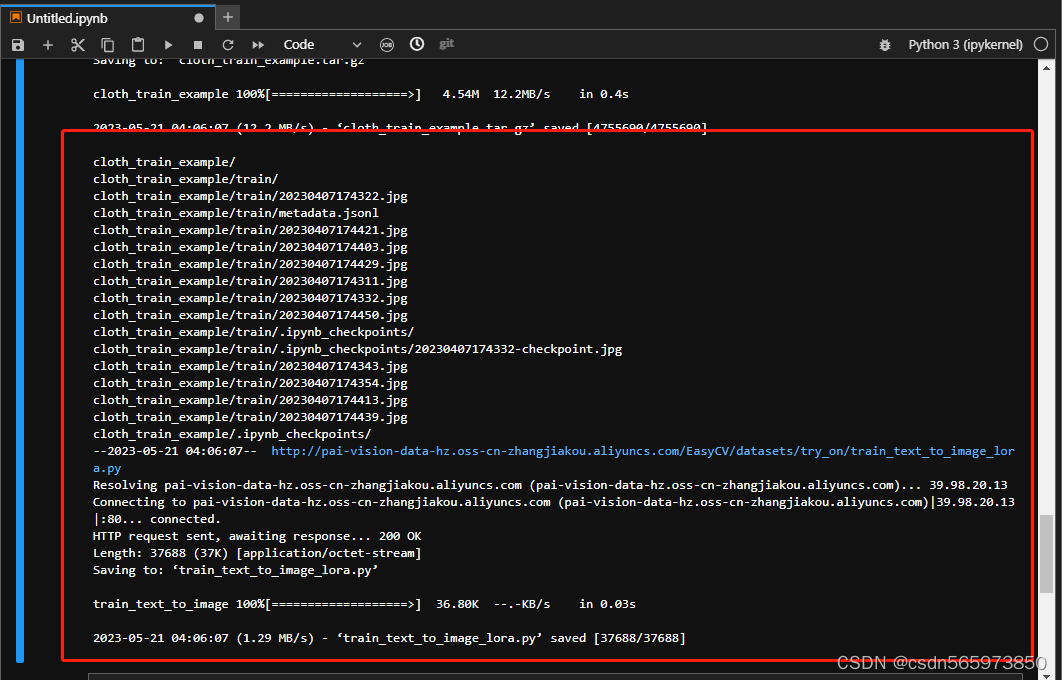
! wget http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/datasets/try_on/cloth_train_example.tar.gz && tar -xvf cloth_train_example.tar.gz
! wget http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/datasets/try_on/train_text_to_image_lora.py数据集下载完成之后可以看到
查看一下示例服装,执行命令
shell
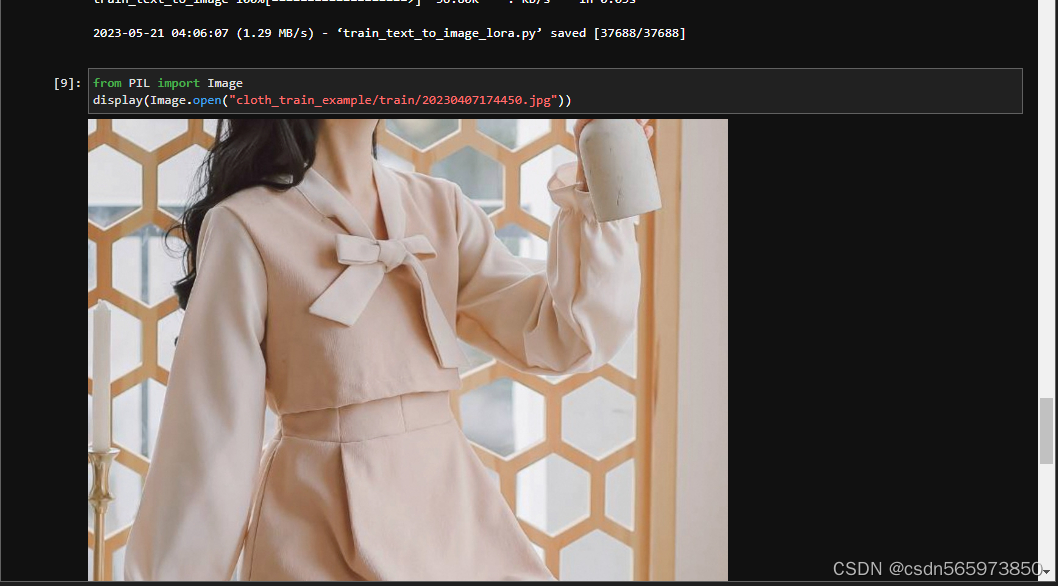
from PIL import Image
display(Image.open("cloth_train_example/train/20230407174450.jpg"))执行结果可以看到
继续下载预训练模型并转化成diffusers格式,执行命令
shell
! cd stable-diffusion-webui/models/Stable-diffusion && wget -c https://huggingface.co/naonovn/chilloutmix_NiPrunedFp32Fix/resolve/main/chilloutmix_NiPrunedFp32Fix.safetensors -O chilloutmix_NiPrunedFp32Fix.safetensors
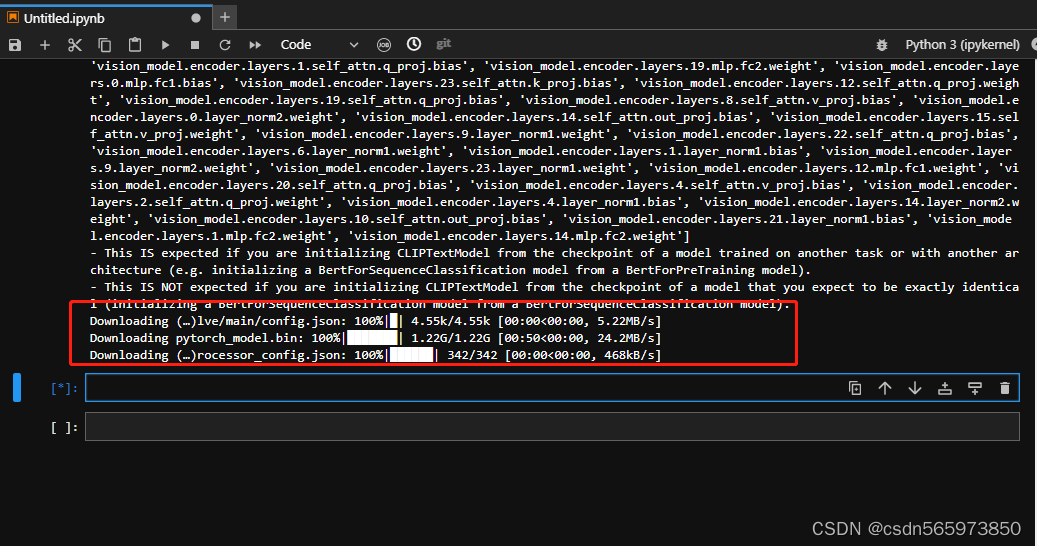
! python diffusers/scripts/convert_original_stable_diffusion_to_diffusers.py \
--checkpoint_path=stable-diffusion-webui/models/Stable-diffusion/chilloutmix_NiPrunedFp32Fix.safetensors \
--dump_path=chilloutmix-ni --from_safetensors执行结果如图
执行命令,设置num_train_epochs为200,进行lora模型的训练
shell
! export MODEL_NAME="chilloutmix-ni" && \
export DATASET_NAME="cloth_train_example" && \
accelerate launch --mixed_precision="fp16" train_text_to_image_lora.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_NAME --caption_column="text" \
--width=640 --height=768 --random_flip \
--train_batch_size=1 \
--num_train_epochs=200 --checkpointing_steps=5000 \
--learning_rate=1e-04 --lr_scheduler="constant" --lr_warmup_steps=0 \
--seed=42 \
--output_dir="cloth-model-lora" \
--validation_prompt="cloth1" --validation_epochs=100训练完成之后可以看到
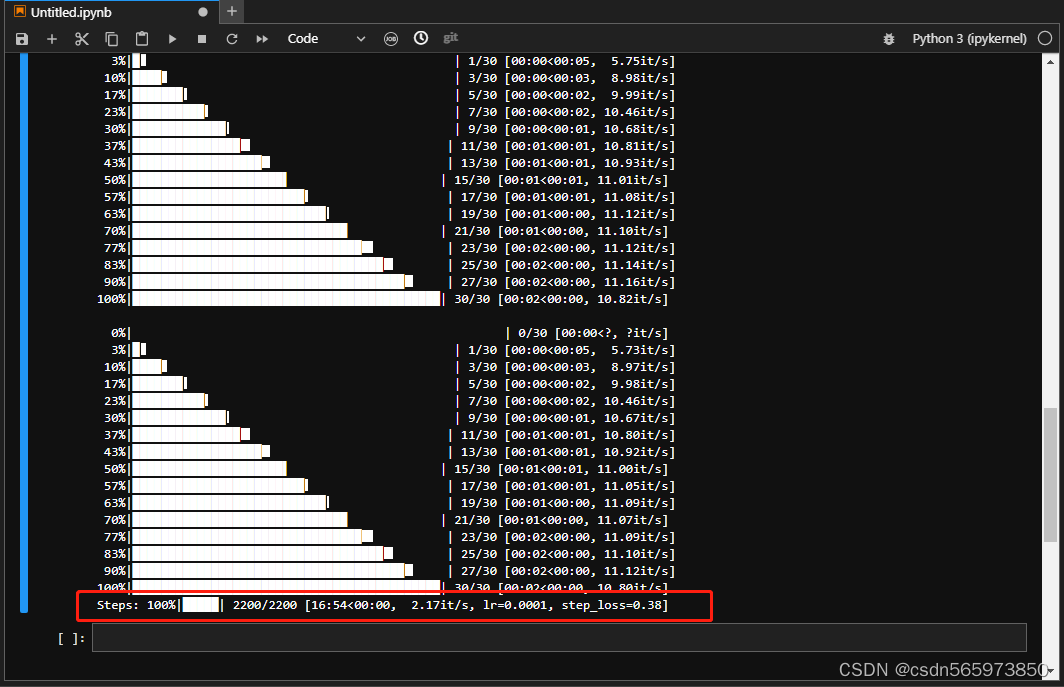
然后将lora模型转化成WebUI支持格式并拷贝到WebUI所在目录
shell
! wget -c http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/datasets/convert-to-safetensors.py
! python convert-to-safetensors.py --file='cloth-model-lora/pytorch_lora_weights.bin'
! mkdir stable-diffusion-webui/models/Lora
! cp cloth-model-lora/pytorch_lora_weights_converted.safetensors stable-diffusion-webui/models/Lora/cloth_lora_weights.safetensors执行结果如图
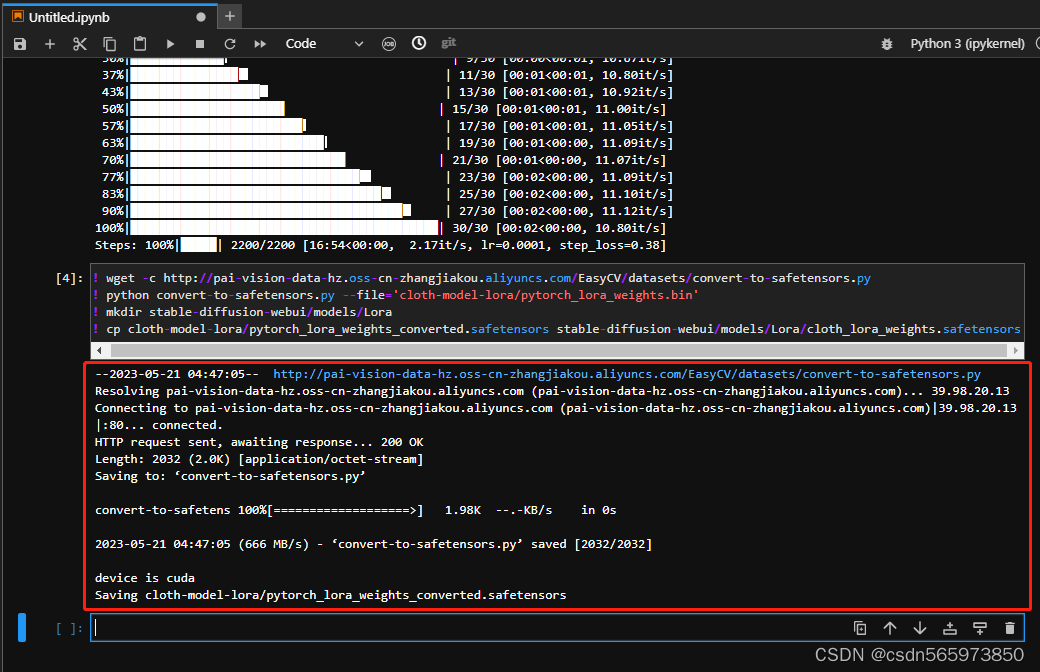
准备其他模型文件
shell
! mkdir stable-diffusion-webui/models/Codeformer
! cd stable-diffusion-webui/repositories/CodeFormer/weights/facelib/ && \
wget -c http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/datasets/try_on/detection_Resnet50_Final.pth && \
wget -c http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/datasets/try_on/parsing_parsenet.pth
! cd stable-diffusion-webui/models/Codeformer && wget -c http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/datasets/try_on/codeformer-v0.1.0.pth
! cd stable-diffusion-webui/embeddings && wget -c http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/datasets/try_on/ng_deepnegative_v1_75t.pt
! cd stable-diffusion-webui/models/Lora && wget -c https://huggingface.co/Kanbara/doll-likeness-series/resolve/main/koreanDollLikeness_v10.safetensors执行结果如图
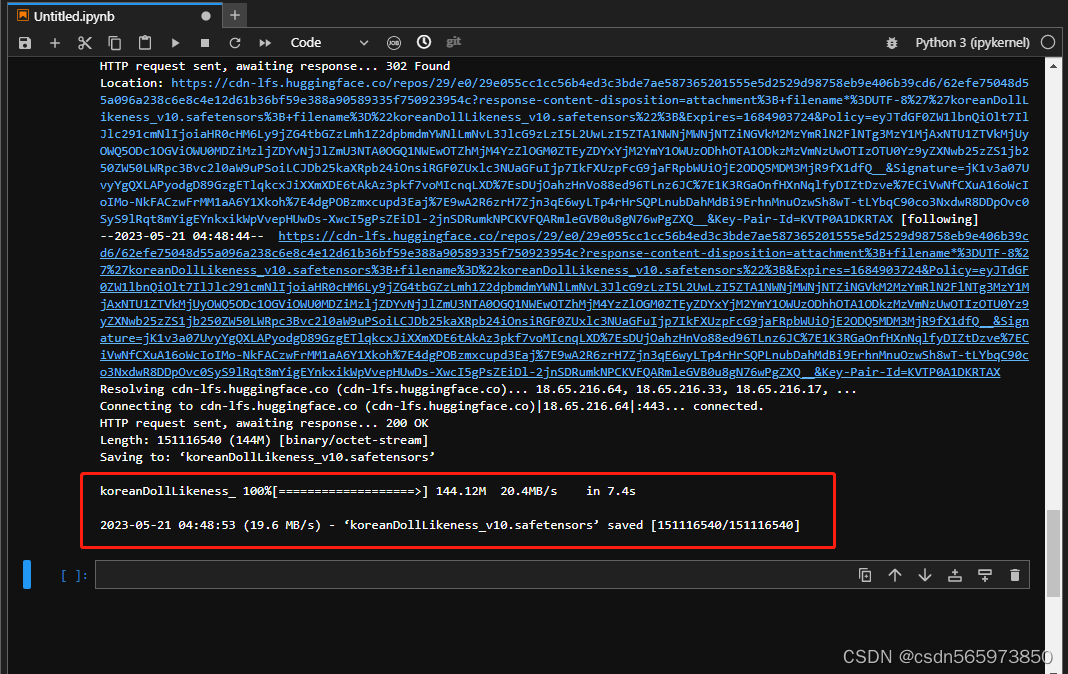
启动WebUI
在Notebook中,执行如下命令,启动WebUI
shell
! cd stable-diffusion-webui && python -m venv --system-site-packages --symlinks venv
! cd stable-diffusion-webui && \
sed -i 's/can_run_as_root=0/can_run_as_root=1/g' webui.sh && \
./webui.sh --no-download-sd-model --xformers这个命令执行过程中可能会遇到多种情况的错误,每次遇到错误情况时重新执行命令即可,错误情况比如
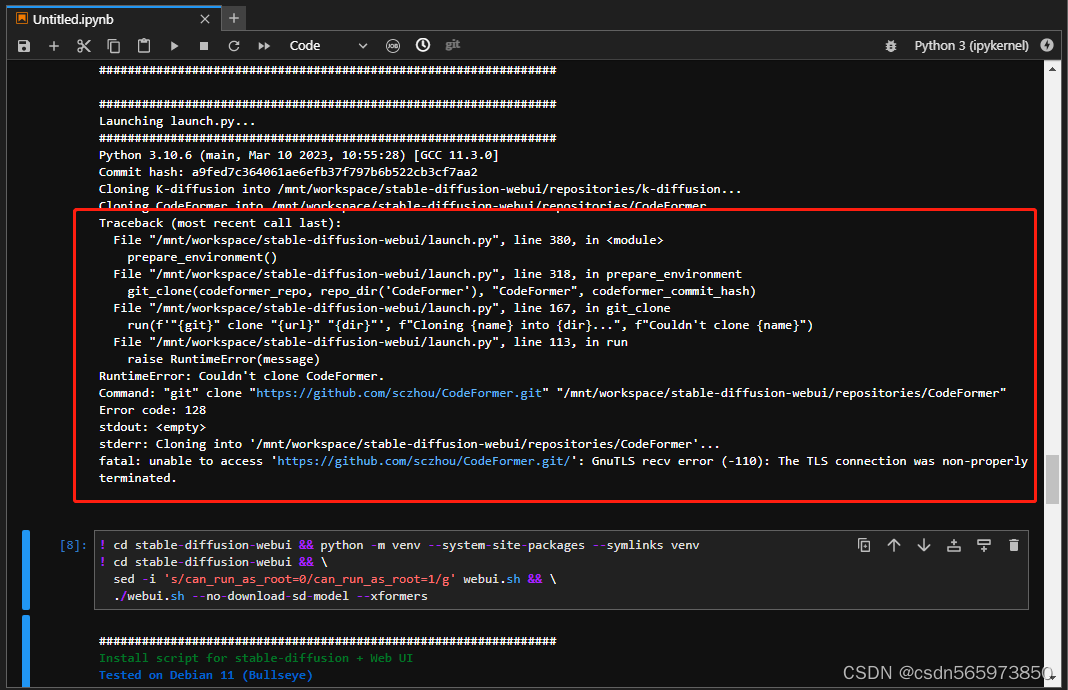
或者是
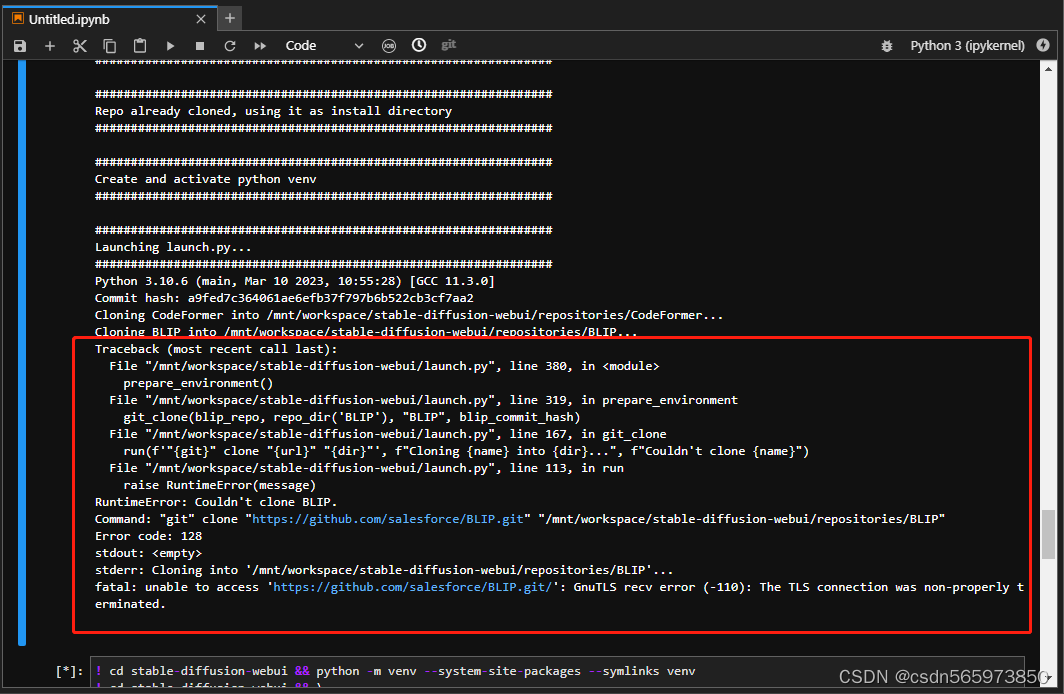
最后执行成功的界面如下
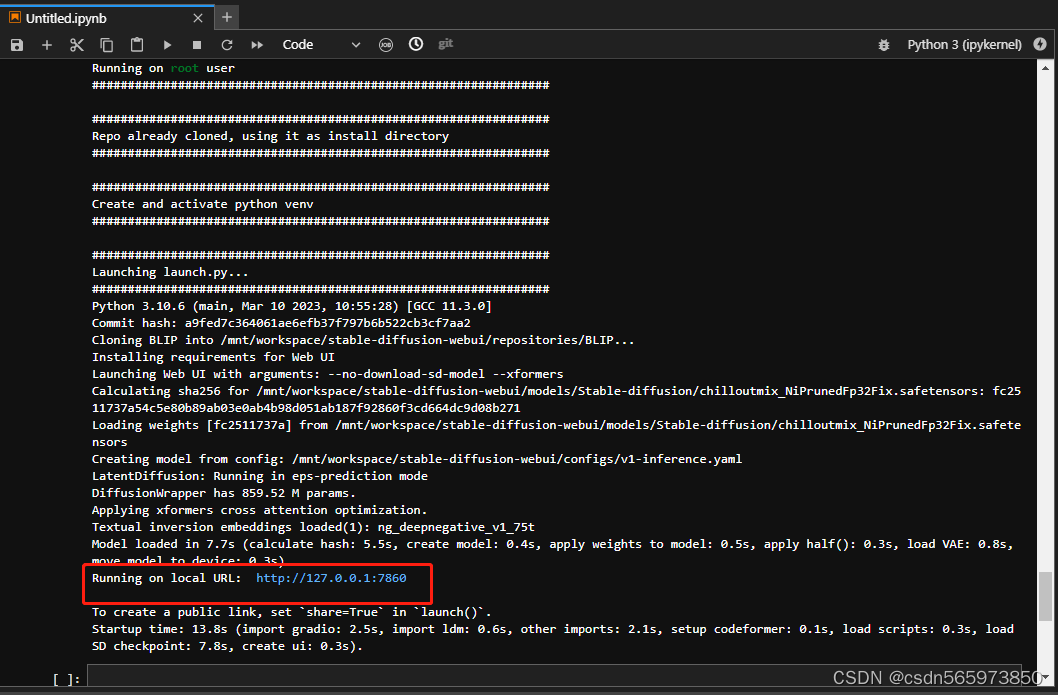
启动成功之后单机链接地址进入模型训练页面
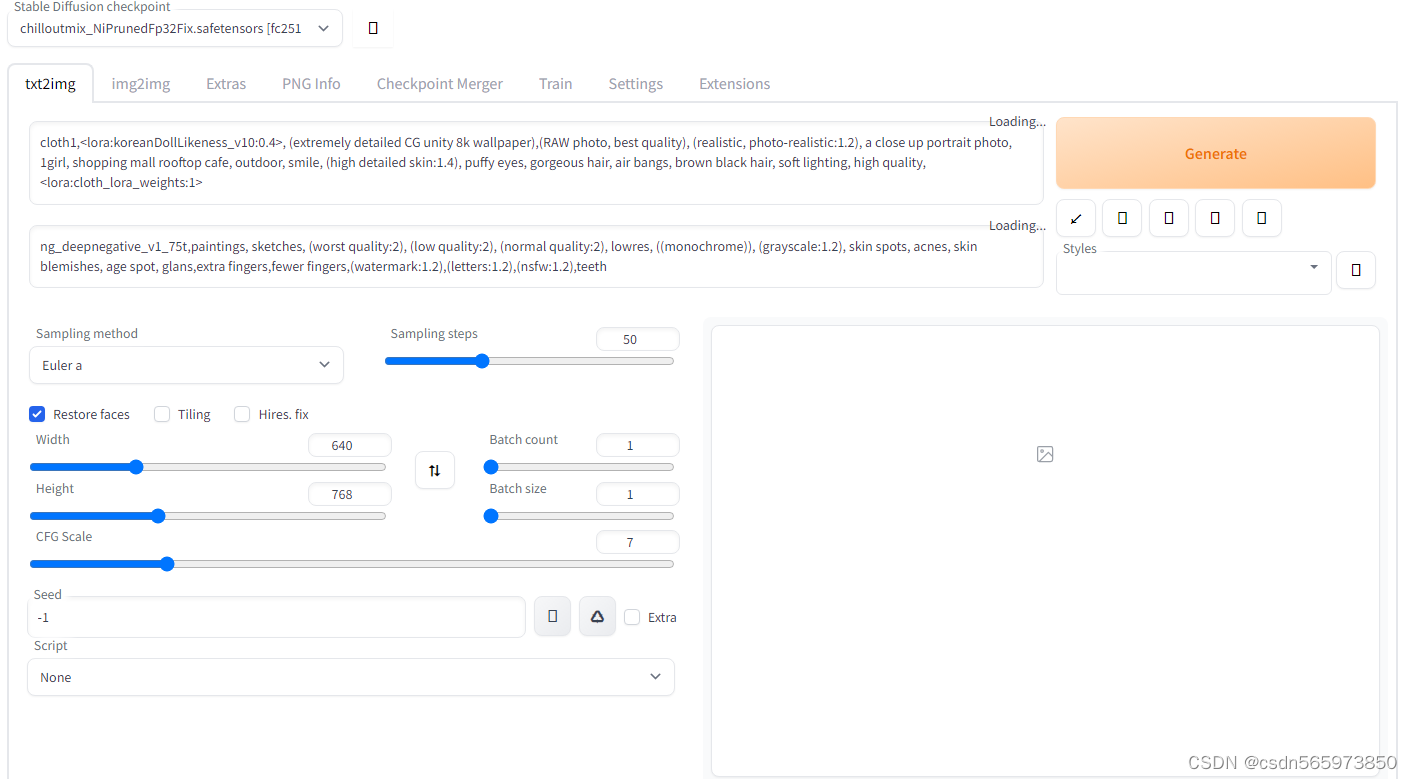
输入待生成模型文本等待生成结果。
写在最后
整体来说,本次操作的时间会耗时比较久,两个小时左右,在部署过程中可能会遇到各种不成功的情况,不用担心,再次执行命令即可。
另外,对于AIGC文生图的操作,对于生成图像与文字描述是否匹配,这个主要还是取决于你当前使用的文生图模型的训练程度,模型训练的结果直接决定了AIGC文生图的准确度,由此及彼的来看,对于AIGC文生图、图生文、文生视频、文生音频等的操作,随着模型训练的不断丰富话,后续想要生成更加准确的切合文字内容的图片及视频都是很有可能的,目前一直希望可以准确生成《少年闰土》中的一段情节
:深蓝的天空中挂着一轮金黄的圆月,下面是海边的沙地,都种着一望无际的碧绿的西瓜。其间有一个十一二岁的少年,项戴银圈,手捏一柄钢叉,向一匹猹用力地刺去。那猹却将身一扭,反从他的胯下逃走了。多方查找还没找到比较生成图比较接近的,后续会继续尝试基于其他云产品的AIGC服务。
活动推广:https://developer.aliyun.com/huodong/dashiblogger?userCode=fkssw94w