Transformer是一种深度学习模型,最早由Vaswani等人在2017年的论文《Attention is All You Need》中提出。它最初用于自然语言处理(NLP)任务,但其架构的灵活性使其在许多其他领域也表现出色,如计算机视觉、时间序列分析等。以下是对Transformer模型的详细介绍。
一、基本结构
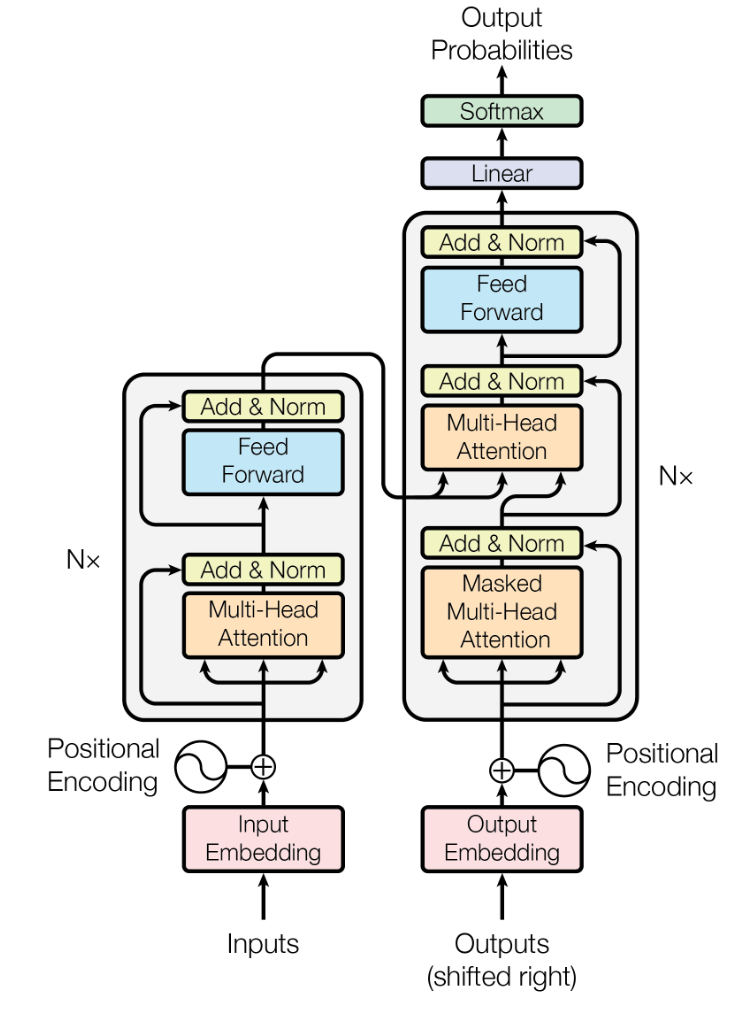
Transformer模型主要由两个部分组成:编码器(Encoder)和解码器(Decoder)。
编码器(Encoder)
- 输入嵌入(Input Embedding):将输入的词汇转换为高维向量表示。
- 位置编码(Positional Encoding):由于Transformer没有循环结构或卷积结构,因此需要显式地加入位置信息。位置编码可以帮助模型了解序列中各个词汇的位置。
- 多头自注意力机制(Multi-Head Self-Attention):自注意力机制可以捕捉序列中不同位置之间的依赖关系。多头机制允许模型关注不同的子空间。
- 前馈神经网络(Feed-Forward Neural Network):两个线性变换和一个ReLU激活函数,独立地应用于每个位置。
- 层归一化(Layer Normalization)和残差连接(Residual Connection):每个子层的输出都进行层归一化,并通过残差连接加入子层输入。
编码器包含多个(通常是6个)这样的子层堆叠。
解码器(Decoder)
解码器的结构与编码器类似,但增加了一个用于接收编码器输出的注意力层。
- 输入嵌入、位置编码、多头自注意力机制、前馈神经网络、层归一化和残差连接:与编码器相同。
- 掩码多头自注意力机制(Masked Multi-Head Self-Attention):防止解码器当前位置注意到未来位置的信息。
- 编码器-解码器注意力机制(Encoder-Decoder Attention):使解码器能关注编码器的输出,从而将编码器捕捉到的上下文信息用于生成目标序列。
解码器也包含多个(通常是6个)这样的子层堆叠。
二、详细机制
注意力机制(Attention Mechanism)
自注意力机制是Transformer的核心。它的计算过程如下:
-
计算查询(Query)、键(Key)、值(Value)矩阵 :
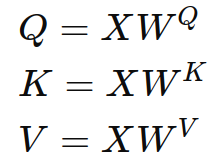
其中,X 是输入序列,WQ、WK、WV是可训练的权重矩阵。
-
计算注意力分数 :
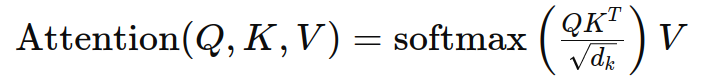
其中:
- dk是键向量的维度。
- KT 是键矩阵的转置
-
多头机制 :
多头注意力机制将输入映射到多个子空间,通过多个注意力头来捕捉不同的特征。然后将这些头的输出连接起来:
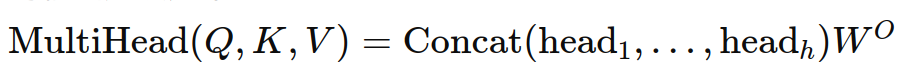
其中,每个头是独立的注意力机制,WO 是可训练的线性变换矩阵。
三、Transformer的优点
- 并行计算:不同于RNN的序列处理方式,Transformer允许并行计算,提高了训练速度。
- 长程依赖:通过自注意力机制,Transformer能够直接捕捉序列中任意位置之间的依赖关系。
- 灵活性:Transformer架构可以轻松扩展到不同任务,如语言翻译、文本生成、图像处理等。
四、变种和改进
自从Transformer被提出以来,已经出现了许多改进和变种,例如:
- BERT(Bidirectional Encoder Representations from Transformers):双向编码器,适用于多种NLP任务。
- GPT(Generative Pre-trained Transformer):生成模型,专注于文本生成任务。
- T5(Text-to-Text Transfer Transformer):将所有NLP任务统一为文本到文本的形式。
- Vision Transformer(ViT):将Transformer应用于图像分类任务。
五、应用领域
Transformer模型在以下领域表现出色:
- 自然语言处理(NLP):如机器翻译、文本生成、问答系统等。
- 计算机视觉:如图像分类、目标检测等。
- 时间序列分析:如股票预测、天气预报等。
- 推荐系统:通过捕捉用户与物品之间的复杂关系来提供个性化推荐。
六、代码示例
以下是一个使用TensorFlow实现简单Transformer的代码示例:
python
import tensorflow as tf
import numpy as np
# 注意力机制
def scaled_dot_product_attention(q, k, v, mask):
matmul_qk = tf.matmul(q, k, transpose_b=True)
dk = tf.cast(tf.shape(k)[-1], tf.float32)
scaled_attention_logits = matmul_qk / tf.math.sqrt(dk)
if mask is not None:
scaled_attention_logits += (mask * -1e9)
attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1)
output = tf.matmul(attention_weights, v)
return output, attention_weights
# 多头注意力
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
assert d_model % self.num_heads == 0
self.depth = d_model // self.num_heads
self.wq = tf.keras.layers.Dense(d_model)
self.wk = tf.keras.layers.Dense(d_model)
self.wv = tf.keras.layers.Dense(d_model)
self.dense = tf.keras.layers.Dense(d_model)
def split_heads(self, x, batch_size):
x = tf.reshape(x, (batch_size, -1, self.num_heads, self.depth))
return tf.transpose(x, perm=[0, 2, 1, 3])
def call(self, v, k, q, mask):
batch_size = tf.shape(q)[0]
q = self.wq(q)
k = self.wk(k)
v = self.wv(v)
q = self.split_heads(q, batch_size)
k = self.split_heads(k, batch_size)
v = self.split_heads(v, batch_size)
scaled_attention, attention_weights = scaled_dot_product_attention(q, k, v, mask)
scaled_attention = tf.transpose(scaled_attention, perm=[0, 2, 1, 3])
concat_attention = tf.reshape(scaled_attention, (batch_size, -1, self.d_model))
output = self.dense(concat_attention)
return output, attention_weights
# 前馈神经网络
def point_wise_feed_forward_network(d_model, dff):
return tf.keras.Sequential([
tf.keras.layers.Dense(dff, activation='relu'),
tf.keras.layers.Dense(d_model)
])
# 编码器层
class EncoderLayer(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, dff, rate=0.1):
super(EncoderLayer, self).__init__()
self.mha = MultiHeadAttention(d_model, num_heads)
self.ffn = point_wise_feed_forward_network(d_model, dff)
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = tf.keras.layers.Dropout(rate)
self.dropout2 = tf.keras.layers.Dropout(rate)
def call(self, x, training, mask):
attn_output, _ = self.mha(x, x, x, mask)
attn_output = self.dropout1(attn_output, training=training)
out1 = self.layernorm1(x + attn_output)
ffn_output = self.ffn(out1)
ffn_output = self.dropout2(ffn_output, training=training)
out2 = self.layernorm2(out1 + ffn_output)
return out2
# 解码器层
class DecoderLayer(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, dff, rate=0.1):
super(DecoderLayer, self).__init__()
self.mha1 = MultiHeadAttention(d_model, num_heads)
self.mha2 = MultiHeadAttention(d_model, num_heads)
self.ffn = point_wise_feed_forward_network(d_model, dff)
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-
6)
self.layernorm3 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = tf.keras.layers.Dropout(rate)
self.dropout2 = tf.keras.layers.Dropout(rate)
self.dropout3 = tf.keras.layers.Dropout(rate)
def call(self, x, enc_output, training, look_ahead_mask, padding_mask):
attn1, attn_weights_block1 = self.mha1(x, x, x, look_ahead_mask)
attn1 = self.dropout1(attn1, training=training)
out1 = self.layernorm1(x + attn1)
attn2, attn_weights_block2 = self.mha2(enc_output, enc_output, out1, padding_mask)
attn2 = self.dropout2(attn2, training=training)
out2 = self.layernorm2(out1 + attn2)
ffn_output = self.ffn(out2)
ffn_output = self.dropout3(ffn_output, training=training)
out3 = self.layernorm3(out2 + ffn_output)
return out3, attn_weights_block1, attn_weights_block2
# 编码器
class Encoder(tf.keras.layers.Layer):
def __init__(self, num_layers, d_model, num_heads, dff, input_vocab_size, rate=0.1):
super(Encoder, self).__init__()
self.d_model = d_model
self.num_layers = num_layers
self.embedding = tf.keras.layers.Embedding(input_vocab_size, d_model)
self.pos_encoding = positional_encoding(1000, self.d_model)
self.enc_layers = [EncoderLayer(d_model, num_heads, dff, rate) for _ in range(num_layers)]
self.dropout = tf.keras.layers.Dropout(rate)
def call(self, x, training, mask):
seq_len = tf.shape(x)[1]
x = self.embedding(x)
x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))
x += self.pos_encoding[:, :seq_len, :]
x = self.dropout(x, training=training)
for i in range(self.num_layers):
x = self.enc_layers[i](x, training, mask)
return x
# 解码器
class Decoder(tf.keras.layers.Layer):
def __init__(self, num_layers, d_model, num_heads, dff, target_vocab_size, rate=0.1):
super(Decoder, self).__init__()
self.d_model = d_model
self.num_layers = num_layers
self.embedding = tf.keras.layers.Embedding(target_vocab_size, d_model)
self.pos_encoding = positional_encoding(1000, self.d_model)
self.dec_layers = [DecoderLayer(d_model, num_heads, dff, rate) for _ in range(num_layers)]
self.dropout = tf.keras.layers.Dropout(rate)
def call(self, x, enc_output, training, look_ahead_mask, padding_mask):
seq_len = tf.shape(x)[1]
attention_weights = {}
x = self.embedding(x)
x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))
x += self.pos_encoding[:, :seq_len, :]
x = self.dropout(x, training=training)
for i in range(self.num_layers):
x, block1, block2 = self.dec_layers[i](x, enc_output, training, look_ahead_mask, padding_mask)
attention_weights[f'decoder_layer{i+1}_block1'] = block1
attention_weights[f'decoder_layer{i+1}_block2'] = block2
return x, attention_weights
# Transformer模型
class Transformer(tf.keras.Model):
def __init__(self, num_layers, d_model, num_heads, dff, input_vocab_size, target_vocab_size, rate=0.1):
super(Transformer, self).__init__()
self.encoder = Encoder(num_layers, d_model, num_heads, dff, input_vocab_size, rate)
self.decoder = Decoder(num_layers, d_model, num_heads, dff, target_vocab_size, rate)
self.final_layer = tf.keras.layers.Dense(target_vocab_size)
def call(self, inp, tar, training, enc_padding_mask, look_ahead_mask, dec_padding_mask):
enc_output = self.encoder(inp, training, enc_padding_mask)
dec_output, attention_weights = self.decoder(tar, enc_output, training, look_ahead_mask, dec_padding_mask)
final_output = self.final_layer(dec_output)
return final_output, attention_weights
# 位置编码
def positional_encoding(position, d_model):
angle_rads = get_angles(np.arange(position)[:, np.newaxis], np.arange(d_model)[np.newaxis, :], d_model)
angle_rads[:, 0::2] = np.sin(angle_rads[:, 0::2])
angle_rads[:, 1::2] = np.cos(angle_rads[:, 1::2])
pos_encoding = angle_rads[np.newaxis, ...]
return tf.cast(pos_encoding, dtype=tf.float32)
def get_angles(pos, i, d_model):
angle_rates = 1 / np.power(10000, (2 * (i // 2)) / np.float32(d_model))
return pos * angle_rates
# 掩码
def create_padding_mask(seq):
seq = tf.cast(tf.math.equal(seq, 0), tf.float32)
return seq[:, tf.newaxis, tf.newaxis, :]
def create_look_ahead_mask(size):
mask = 1 - tf.linalg.band_part(tf.ones((size, size)), -1, 0)
return mask
# 超参数
num_layers = 4
d_model = 128
dff = 512
num_heads = 8
input_vocab_size = 8500
target_vocab_size = 8000
dropout_rate = 0.1
# 创建Transformer模型
transformer = Transformer(num_layers, d_model, num_heads, dff, input_vocab_size, target_vocab_size, dropout_rate)
# 损失函数和优化器
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True, reduction='none')
def loss_function(real, pred):
mask = tf.math.logical_not(tf.math.equal(real, 0))
loss_ = loss_object(real, pred)
mask = tf.cast(mask, dtype=loss_.dtype)
loss_ *= mask
return tf.reduce_sum(loss_) / tf.reduce_sum(mask)
learning_rate = tf.keras.optimizers.schedules.ExponentialDecay(1e-4, decay_steps=100000, decay_rate=0.9, staircase=True)
optimizer = tf.keras.optimizers.Adam(learning_rate)
# 编译模型
transformer.compile(optimizer=optimizer, loss=loss_function)
# 示例输入
sample_input = tf.constant([[1, 2, 3, 4, 0, 0]])
sample_target = tf.constant([[1, 2, 3, 4, 0, 0]])
# 训练模型
transformer.fit([sample_input, sample_target], epochs=10)解释
- 注意力机制:定义了计算注意力权重的函数和多头注意力机制。
- 前馈神经网络:实现了前馈神经网络的部分。
- 编码器和解码器层:定义了编码器和解码器的基本层。
- 编码器和解码器:实现了编码器和解码器的堆叠。
- Transformer模型:集成了编码器和解码器,定义了完整的Transformer模型。
- 位置编码:为输入序列添加位置信息。
- 掩码:定义了填充掩码和前瞻掩码,用于处理输入和目标序列中的填充和防止信息泄露。