一、原子操作
原子操作保证指令以原子的方式执行,执行过程不被打断。先看一个实例,如下所示,如果thread_func_a和thread_func_b同时运行,执行完成后,i的值是多少?
`// test.c
static int i = 0;
void thread_func_a()
{
i++;
}
void thread_func_b()
{
i++;
}`有的读者认为是2,也有的读者认为是1,在给出正确的结果之前,我们先看下这段代码的汇编:
// aarch64-linux-gnu-gcc -S test.c
// vim test.s
.LFB0:
.cfi_startproc
adrp x0, i
add x0, x0, :lo12:i
ldr w0, [x0] // 加载内存地址为x0寄存器的值,也就是i的值到w0寄存器
add w1, w0, 1 // 将w0寄存器的值与1相加,结果存在w1寄存器
adrp x0, i
add x0, x0, :lo12:i
str w1, [x0] // 把w1寄存器的值,加载到x0所在的地址
nop
ret
.cfi_endproc
...可以看到虽然在我们写的代码中,i++只有一条指令,实际上汇编指令需要三条:
-
加载内存地址的值
-
修改变量的值
-
将修改后的值写回原先的地址
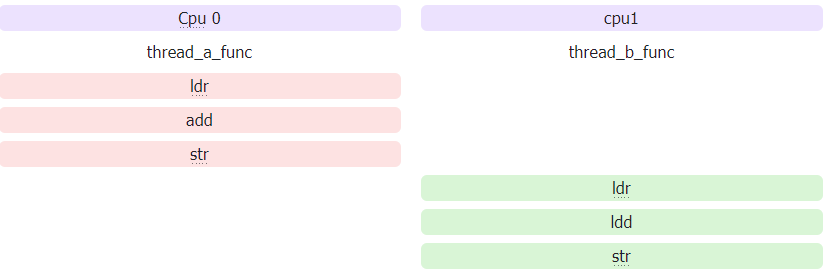
两个cpu在执行过程中,顺序是随机的,结果也是随机的,这里为了更直观,给大商家列一下实际可能的执行顺序,以及对应的结果:
可能的结果:i = 2,执行顺序如下:
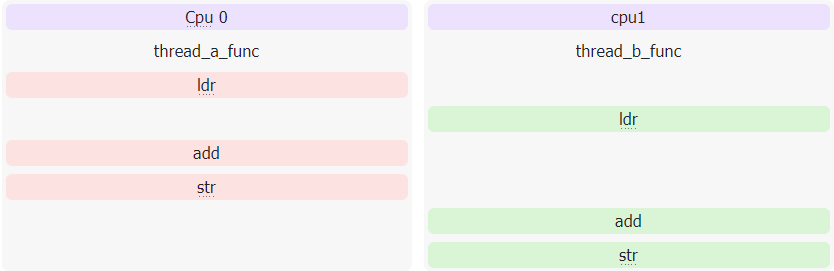
可能的结果:i = 1,执行顺序如下
针对上面的问题,linux提供了atomic_t类型的原子变量来解决,它可以保证对一个整形数据的原子性。
在内核看来,原子操作函数就像一条汇编语句,保证了操作时不被打断,如上述i++语句就可能被打断,要保证操作的原子性,通常需要原子地(不间断地)完成"读-修改-回写"机制,中间不能被打断。
二、原子变量
linux提供了atomic_t类型的原子变量,它的实现依赖于不同的架构,不同处理器的实现方式不一样。我们首先看下都有哪些原子操作可供使用,然后再针对arm64的实现方式进行解读(其他架构原理都类似,大家自己揣摩)。
2.1 原子操作函数
linux内核提供了很多操作原子变量的函数,了解这些内容,方便我们后续使用。我们以arm64为例进行讲解。
2.1.1 基本原子操作函数
接口:
ATOMIC_INIT(i)
atomic_read(const atomic_t *v)
atomic_set(atomic_t *v, int i)
实现:
// linux-6.9.1/arch/arm64/include/asm/atomic.h
#define arch_atomic_read(v) __READ_ONCE((v)->counter)
#define arch_atomic_set(v, i) __WRITE_ONCE(((v)->counter), (i))2.1.2 不带返回值的原子操作函数
接口:
atomic_add(i, v)
atomic_sub(i, v)
atomic_and(i, v)
atomic_or(i, v)
atomic_xor(i, v)
atomic_andnot(i, v)
实现
// linux-6.9.1/arch/arm64/include/asm/atomic.h
#define ATOMIC_OP(op) \
static __always_inline void arch_##op(int i, atomic_t *v) \
{ \
__lse_ll_sc_body(op, i, v); \
}
ATOMIC_OP(atomic_andnot)
ATOMIC_OP(atomic_or)
ATOMIC_OP(atomic_xor)
ATOMIC_OP(atomic_add)
ATOMIC_OP(atomic_and)
ATOMIC_OP(atomic_sub)2.1.3 带返回值的原子操作
linux内核提供了两类带返回值的原子操作函数,一类返回原子变量的新值,一类返回原子变量的旧值。 然会原子变量新值的原子操作函数如下。
接口:
atomic_add_return(i, v)
atomic_sub_return(i, v)
实现;
// linux-6.9.1/arch/arm64/include/asm/atomic.h
#define ATOMIC_FETCH_OP(name, op) \
static __always_inline int arch_##op##name(int i, atomic_t *v) \
{ \
return __lse_ll_sc_body(op##name, i, v); \
}
ATOMIC_FETCH_OPS(atomic_add_return)
ATOMIC_FETCH_OPS(atomic_sub_return)
返回原子变量旧值的原子操作函数如下:
接口:
atomic_fetch_add(i, v)
atomic_fetch_sub(i, v)
atomic_fetch_and(i, v)
atomic_fetch_or(i, v)
atomic_fetch_xor(i, v)
atomic_fetch_andnot(i, v)
实现:
// linux-6.9.1/arch/arm64/include/asm/atomic.h
#define ATOMIC_FETCH_OP(name, op) \
static __always_inline int arch_##op##name(int i, atomic_t *v) \
{ \
return __lse_ll_sc_body(op##name, i, v); \
}
ATOMIC_FETCH_OPS(atomic_fetch_andnot)
ATOMIC_FETCH_OPS(atomic_fetch_or)
ATOMIC_FETCH_OPS(atomic_fetch_xor)
ATOMIC_FETCH_OPS(atomic_fetch_add)
ATOMIC_FETCH_OPS(atomic_fetch_and)
ATOMIC_FETCH_OPS(atomic_fetch_sub)
ATOMIC_FETCH_OPS(atomic_add_return)
ATOMIC_FETCH_OPS(atomic_sub_return)3.1.4 内嵌内存屏障的原子操作函数
接口:
{}_relexd // 不内嵌内存屏障原语
{}_acquire // 内置加载-获取内存屏障原语
{}_release // 内置存储-释放内存屏障原语
实现:
// linux-6.9.1/arch/arm64/include/asm/atomic.h
#define ATOMIC_FETCH_OP(name, op) \
static __always_inline int arch_##op##name(int i, atomic_t *v) \
{ \
return __lse_ll_sc_body(op##name, i, v); \
}
#define ATOMIC_FETCH_OPS(op) \
ATOMIC_FETCH_OP(_relaxed, op) \
ATOMIC_FETCH_OP(_acquire, op) \
ATOMIC_FETCH_OP(_release, op) \
ATOMIC_FETCH_OP( , op)
ATOMIC_FETCH_OPS(atomic_fetch_andnot)
ATOMIC_FETCH_OPS(atomic_fetch_or)
ATOMIC_FETCH_OPS(atomic_fetch_xor)
ATOMIC_FETCH_OPS(atomic_fetch_add)
ATOMIC_FETCH_OPS(atomic_fetch_and)
ATOMIC_FETCH_OPS(atomic_fetch_sub)
ATOMIC_FETCH_OPS(atomic_add_return)
ATOMIC_FETCH_OPS(atomic_sub_return)2.2 原子操作的实现
2.2.1 原子操作的实现
原子操作的实现依赖处理器硬件提供支持,在不同的处理器体系结构上,原子操作会有不同的实现,例如在x86体系结构下,通常使用锁缓存/总线的方式实现原子操作。目前在ARMv8体系结构下支持两种方式来实现原子操作:
-
一种是经典的独占内存访问机制,也叫做LL/SC(Load-Link/Store-Conditional),早期ARM体系结构下的原子操作都是基于这种方式实现;
-
另一种是ARMv8.1体系结构上新增的LSE(Large System Extension)扩展,LSE提供了多种原子内存访问操作指令。
具体选择哪一种,CONFIG_ARM64_LSE_ATOMICS决定
// linux-6.9.1/arch/arm64/include/asm/lse.h
#ifdef CONFIG_ARM64_LSE_ATOMICS
#define __LSE_PREAMBLE ".arch_extension lse\n"
#include <linux/compiler_types.h>
#include <linux/export.h>
#include <linux/stringify.h>
#include <asm/alternative.h>
#include <asm/alternative-macros.h>
#include <asm/atomic_lse.h>
#include <asm/cpucaps.h>
#define __lse_ll_sc_body(op, ...) \
({ \
alternative_has_cap_likely(ARM64_HAS_LSE_ATOMICS) ? \
__lse_##op(__VA_ARGS__) : \
__ll_sc_##op(__VA_ARGS__); \
})
/* In-line patching at runtime */
#define ARM64_LSE_ATOMIC_INSN(llsc, lse) \
ALTERNATIVE(llsc, __LSE_PREAMBLE lse, ARM64_HAS_LSE_ATOMICS)
#else /* CONFIG_ARM64_LSE_ATOMICS */
#define __lse_ll_sc_body(op, ...) __ll_sc_##op(__VA_ARGS__)
#define ARM64_LSE_ATOMIC_INSN(llsc, lse) llsc
#endif /* CONFIG_ARM64_LSE_ATOMICS */
#endif /* __ASM_LSE_H */2.2.2 ll/sc方式
LL/SC机制使用多个指令,并且每个处理器都需要实现一个专有监视器,LL/SC机制利用独占内存访问指令和独占监视器共同实现原子操作。首先看下ARMv8体系结构提供的独占内存访问指令。
独占内存访问指令
ARMv8体系结构实现的独占内存访问指令为LDXR/STXR:
-
LDXR:内存独占加载指令,它从内存中以独占方式加载内存地址的值到寄存器中;
-
STXR:内存独占存储指令,它以独占的方式把数据存储到内存中。 LDXR/STXR的指令格式如下:
ldxr
, [xn | sp]
stxr, , [xn | sp]
多字节独占内存访问指令
LDXP和STXP指令是多字节独占内存访问指令,一条指令可以独占地加载和存储16字节。
ldxp <xt1>, <xt2>, [xn | sp]
stxp <ws>, <xt1>, <xt2>, [<xn | sp>]独占监视器
独占监视器是一个硬件状态机,用于跟踪读-修改-写序列,并支持Load和Store操作。当CPU执行LDXR指令时,独占监视器会把对应内存地址标记为独占访问模式,保证以独占的方式来访问这个内存地址;而STXR是有条件的存储指令,当CPU执行STRX指令将新数据写入到LDXR指令标记的独占访问内存地址时,会根据独占监视器的状态来进行处理:
-
若独占监视器为独占访问状态,那么STRX指令执行成功,并且独占监视器会切换状态到开放访问状态;
-
若独占监视器为开放访问状态,则STRX指令执行失败,数据无法存储。
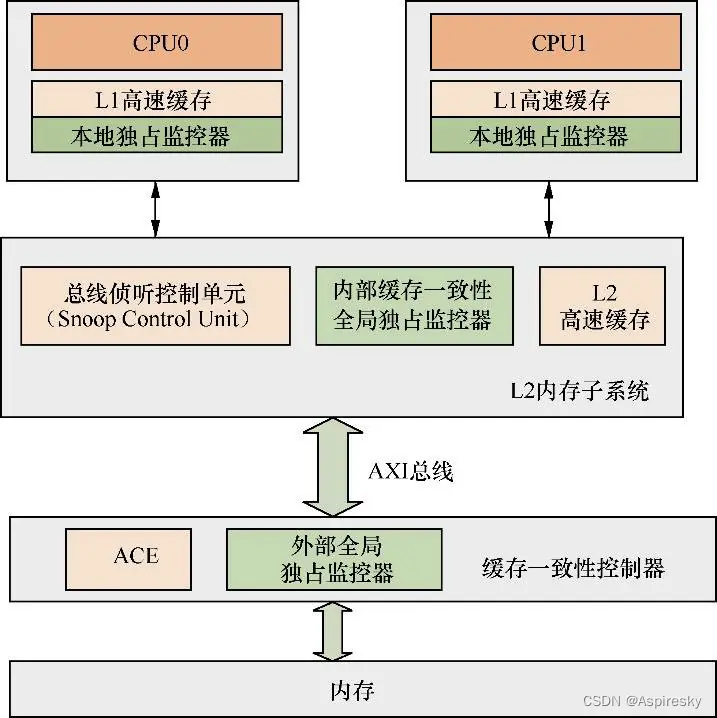
ARMv8体系提供了三类独占监视器:
-
本地独占监视器
-
内部缓存一致性全局独占监视器
-
外部全局独占监视器
这些独占监视器分别位于系统存储结构的不同层次,如下
atomic_op实现:
// linux-6.9.1/arch/arm64/include/asm/atomic_ll_sc.h
#define ATOMIC_OP(op, asm_op, constraint) \
static __always_inline void \
__ll_sc_atomic_##op(int i, atomic_t *v) \
{ \
unsigned long tmp; \
int result; \
\
asm volatile("// atomic_" #op "\n" \
" prfm pstl1strm, %2\n" \
"1: ldxr %w0, %2\n" \
" " #asm_op " %w0, %w0, %w3\n" \
" stxr %w1, %w0, %2\n" \
" cbnz %w1, 1b\n" \
: "=&r" (result), "=&r" (tmp), "+Q" (v->counter) \
: __stringify(constraint) "r" (i)); \
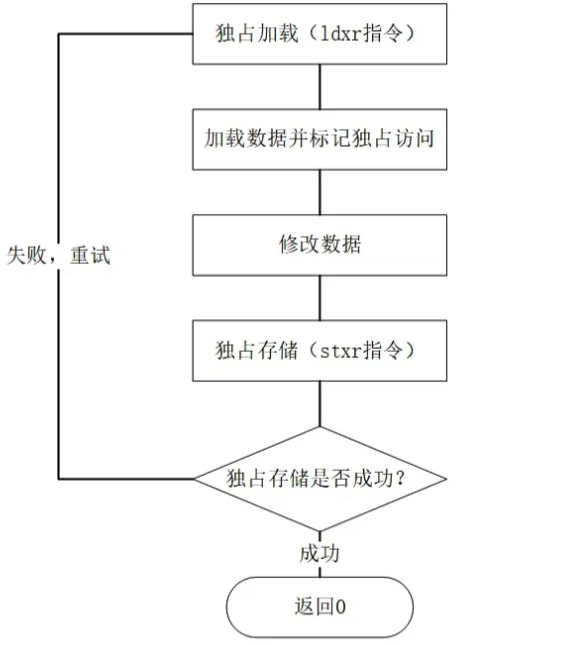
}第11行:将v->counter的值以内存独占加载的方式存储到w0寄存器,即result = v->counter
第12行:将w0的值和i的值操作(add/sub等)结果保存在w0,即result = result + i
第13行:将w0的值写回v->counter,成功的为给w1赋0,否则等于1
第14行:判断temp的值,为0代表成功;为1代表失败,跳转到ldxr。
说白了,这里也是一个自旋
2.2.3 lse方式
在ARMV8.1指令集中增加了一些新的原子操作指令,可以一个指令实现整形运算。
新增的整形原子指令:
接口:
stclr
stset
steor
stadd
实现:
#define ATOMIC_OP(op, asm_op) \
static __always_inline void \
__lse_atomic_##op(int i, atomic_t *v) \
{ \
asm volatile( \
__LSE_PREAMBLE \
" " #asm_op " %w[i], %[v]\n" \
: [v] "+Q" (v->counter) \
: [i] "r" (i)); \
}
ATOMIC_OP(andnot, stclr)
ATOMIC_OP(or, stset)
ATOMIC_OP(xor, steor)
ATOMIC_OP(add, stadd)三、总结
本篇文章首先根据一个真实的事例引出原子操作要解决的问题,然后对linux提供的原子操作的众多接口进行了解释说明,最后对arm架构上的两种原子操作的实现方式原理LL/SC、LSE进行了剖析。经过上面的学习,大家应该已经了解原子变量的使用场景以及内部的实现机理。
参考: https://jishuzhan.net/article/1763876122459639809
《奔跑吧,linux内核-卷一基础架构》
《奔跑吧,linux内核-卷二调试与案例分析》
下篇文章,将经典自旋锁进行解读,敬请期待 。
一个专注于"嵌入式知识分享"、"DIY嵌入式产品"的技术开发人员,关注我,一起共创嵌入式联盟。