目录
[1 SSH免密登录](#1 SSH免密登录)
[1.1 修改主机名称](#1.1 修改主机名称)
[1.2 修改hosts文件](#1.2 修改hosts文件)
[1.3 创建hadoop用户](#1.3 创建hadoop用户)
[1.4 生成密钥对免密登录](#1.4 生成密钥对免密登录)
[2 搭建hadoop环境与jdk环境](#2 搭建hadoop环境与jdk环境)
[2.1 将下载好的压缩包进行解压](#2.1 将下载好的压缩包进行解压)
[2.2 编写hadoop环境变量脚本文件](#2.2 编写hadoop环境变量脚本文件)
[2.3 修改hadoop配置文件,指定jdk路径](#2.3 修改hadoop配置文件,指定jdk路径)
[2.4 查看环境是否搭建完成](#2.4 查看环境是否搭建完成)
[3 hadoop的启动](#3 hadoop的启动)
[3.1 Hadoop 启动需要修改的配置文件](#3.1 Hadoop 启动需要修改的配置文件)
[3.2 配置文件的修改](#3.2 配置文件的修改)
[3.3 启动hadoop与权限修改](#3.3 启动hadoop与权限修改)
[3.4 再次启动hadoop](#3.4 再次启动hadoop)
Rocky Linux 9.4 (CentOS同样适用)
hadoop版本 3.3.6
java : jdk1.8
1 SSH免密登录
1.1 修改主机名称
root@localhost \~# hostnamectl set-hostname hadoop
退出重新登录
root@localhost \~# exit
1.2 修改hosts文件

root@hadoop \~# vim /etc/hosts

1.3 创建hadoop用户
bash
[root@hadoop ~] useradd -m hadoop -s /bin/bash
[root@hadoop ~] ls /home/
hadoop rocky
# 设置用户密码
[root@hadoop ~] passwd hadoop
更改用户 hadoop 的密码 。
新的密码:
重新输入新的密码:
passwd:所有的身份验证令牌已经成功更新。
[root@hadoop ~] ssh hadoop@hadoop
hadoop@hadoop's password:
Last failed login: Sat Jun 29 15:08:33 CST 2024 from 192.168.239.131 on ssh:notty
There were 2 failed login attempts since the last successful login.
[hadoop@hadoop ~]$ exit
注销1.4 生成密钥对免密登录
使用su - hadoop 登录hadoop 账户
bash
[root@hadoop /]# su - hadoop
# 创建秘钥对,为免密登录做准备
[hadoop@hadoop ~]$ ssh-keygen -t rsa -b 4096
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoop/.ssh/id_rsa
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub
The key fingerprint is:
SHA256:NVZ+2Ur09zHUadG9KMNkwOnh1wodT3SUpR9ae6xM+wo hadoop@hadoop1
The key's randomart image is:
+---[RSA 4096]----+
| ..o o.o=X|
| + * ooO+|
| o X * B==|
| * B *o=B|
| S o +.o.=|
| . o o.|
| E + |
| . . |
| ...|
+----[SHA256]-----+
[hadoop@hadoop ~]$ ssh-copy-id root@hadoop
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/hadoop/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@hadoop1's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'root@hadoop1'"
and check to make sure that only the key(s) you wanted were added.
# 给本机免密登录
[hadoop@hadoop1 ~]$ ssh-copy-id hadoop
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/hadoop/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
hadoop@hadoop1's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'hadoop1'"
and check to make sure that only the key(s) you wanted were added.
# 测试免密登录是否成功
[hadoop@hadoop1 ~]$ ssh hadoop1
Last login: Sat Jun 29 15:32:19 2024 from fe80::20c:29ff:fe33:d160%ens160
[hadoop@hadoop1 ~]$ exit
注销命令行输入 ssh hadoop 不需要密码即成功

2 搭建hadoop环境与jdk环境
2.1 将下载好的压缩包进行解压
解压路径为
hadoop : /opt/hadoop
jdk : /opt/jdk
bash
[root@hadoop ~] ls
hadoop-3.3.6.tar.gz jdk-8u162-linux-x64.tar.gz 公共 模板 视频 图片 文档 下载 音乐 桌面 anaconda-ks.cfg test
[root@hadoop ~] mkdir -p /opt/jdk
[root@hadoop ~] mkdir -p /opt/hadoop
[root@hadoop ~] tar -xzf jdk-8u162-linux-x64.tar.gz -C /opt/jdk
[root@hadoop ~] tar -xzf hadoop-3.3.6.tar.gz -C /opt/hadoop
[root@hadoop ~] cd /opt
[root@hadoop opt] ls
hadoop jdk rh soft2.2 编写hadoop环境变量脚本文件
添加路径到path环境变量中
hadoop@hadoop \~$ exit
root@hadoop \~ # vim /etc/profile.d/hadoop-eco.sh
创建脚本文件,加入以下环境变量路径
bash
JAVA_HOME=/opt/jdk
PATH=$JAVA_HOME/bin:$PATH
HADOOP_HOME=/opt/hadoop
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
# HADOOP_USER
export HDFS_NAMENODE_USER=hadoop
export HDFS_DATANODE_USER=hadoop
export HDFS_SECONDARYNAMENODE_USER=hadoop
export YARN_RESOURCEMANAGER_USER=hadoop
export YARN_NODEMANAGER_USER=hadoop
export HDFS_JOURNALNODE_USER=hadoop
export HDFS_ZKFC_USER=hadoop
HDFS_NAMENODE_USER=hadoop:指定HDFS NameNode服务的运行用户。NameNode负责管理文件系统的命名空间,包括文件和目录的元数据。
HDFS_DATANODE_USER=hadoop:指定HDFS DataNode服务的运行用户。DataNodes存储实际的数据块,是HDFS数据存储的主要组成部分。
HDFS_SECONDARYNAMENODE_USER=hadoop:指定HDFS Secondary NameNode服务的运行用户。Secondary NameNode并不存储集群的实时状态,但它定期合并NameNode的fsimage和editlogs文件,减少NameNode的启动时间。
YARN_RESOURCEMANAGER_USER=hadoop:指定YARN ResourceManager服务的运行用户。ResourceManager是YARN中的主控服务,负责集群资源的分配和管理工作。
YARN_NODEMANAGER_USER=hadoop:指定YARN NodeManager服务的运行用户。NodeManagers运行在每个集群节点上,负责容器的生命周期管理。
HDFS_JOURNALNODE_USER=hadoop:指定HDFS JournalNode服务的运行用户。JournalNodes用于在HA(High Availability)配置中存储NameNode状态的编辑日志,以保证数据的一致性。
HDFS_ZKFC_USER=hadoop:指定ZooKeeper Failover Controller(ZKFC)的运行用户。ZKFC用于监控NameNode的状态,并在检测到故障时触发failover,切换到备用NameNode。通过设置这些环境变量,你确保了Hadoop的各个服务将以
hadoop用户的身份运行,而不是以root或其他用户运行。这不仅增强了系统的安全性,还便于管理和审计。在Hadoop的启动脚本中,这些变量会被读取并应用到相应的服务启动过程中
2.3 修改hadoop配置文件,指定jdk路径
root@hadoop \~# vim /opt/hadoop/etc/hadoop/hadoop-env.sh
这个变量指定了 Java 的安装位置。Hadoop 依赖于 Java 运行,因此必须正确设置此变量,指向你的 Java 安装目录。
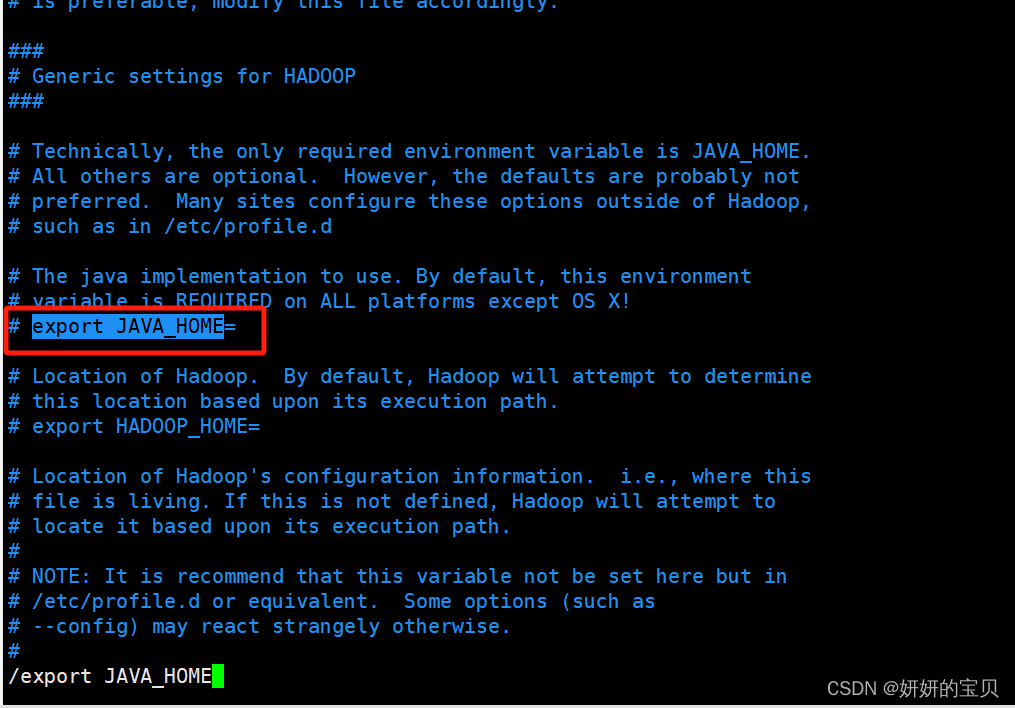
增加以下行,注意此路径为java环境变量的路径
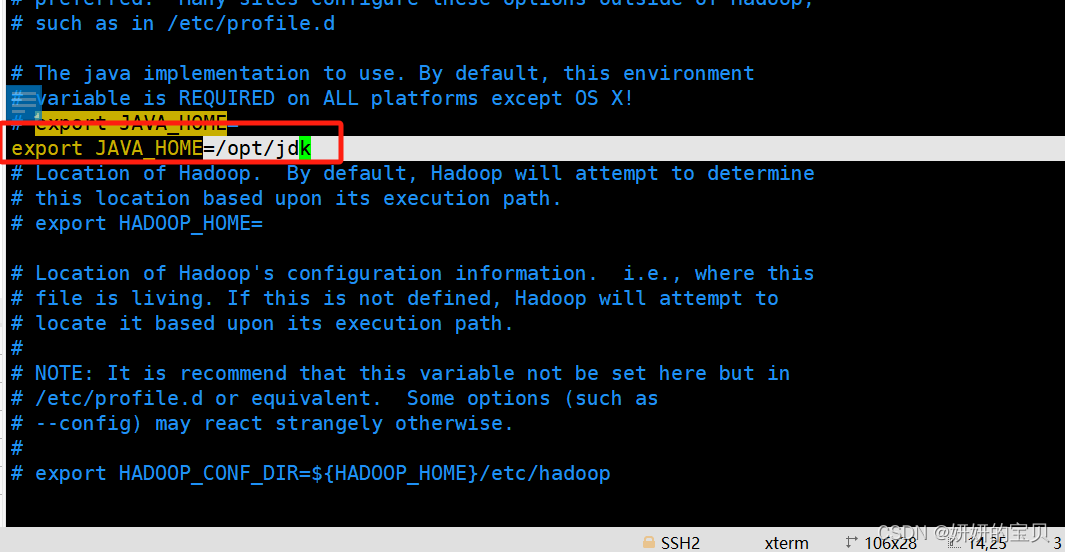
运行修改后的脚本
bash
[root@hadoop ~] source /opt/hadoop/etc/hadoop/hadoop-env.sh2.4 查看环境是否搭建完成
输入hadoop version 和 java -version 查询版本号,检查环境是否配好
bash
[root@hadoop ~] hadoop version
Hadoop 3.3.6
Source code repository https://github.com/apache/hadoop.git -r 1be78238728da9266a4f88195058f08fd012bf9c
Compiled by ubuntu on 2023-06-18T08:22Z
Compiled on platform linux-x86_64
Compiled with protoc 3.7.1
From source with checksum 5652179ad55f76cb287d9c633bb53bbd
This command was run using /opt/hadoop/share/hadoop/common/hadoop-common-3.3.6.jar
bash
[root@hadoop ~] java -version
java version "1.8.0_162"
Java(TM) SE Runtime Environment (build 1.8.0_162-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.162-b12, mixed mode)3 hadoop的启动
3.1 Hadoop 启动需要修改的配置文件
1、core-site.xml
fs.defaultFS
hadoop.tmp.dir
2、hdfs-site.xml
dfs.replication => 1
dfs.namenode.name.dir
dfs.datanode.data.dir
3、mapred-site.xml
mapreduce.framework.name =>yarn
4、yarn-site.xml
yarn.resourcemanager.hostname => localhost
yarn.nodemanager.aux-services => mapreduce_shuffle
3.2 配置文件的修改
1、core-site.xml
bash
[root@hadoop hadoop] vim /opt/hadoop/etc/hadoop/core-site.xml在configuration块中添加以下信息
XML
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:///opt/hadoop-record/tep</value>
</property>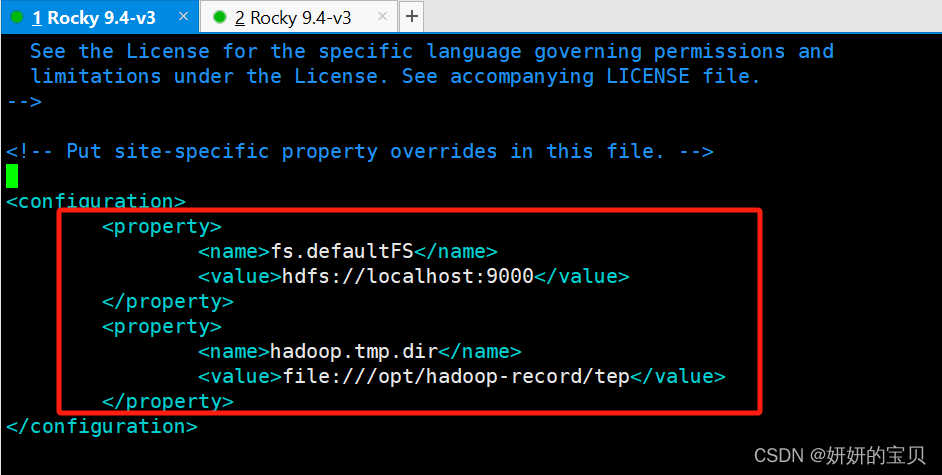
<configuration>这是Hadoop配置文件的根标签,用于包含所有的配置属性。
<property>这个标签用于定义一个具体的配置项,包括名称(
<name>)和值(<value>)两部分。
<name>fs.defaultFS</name>这个配置项指定了Hadoop的默认文件系统。在你的例子中,
hdfs://localhost:9000表示Hadoop将使用运行在本地主机上的Hadoop分布式文件系统(HDFS),端口号为9000。
<name>hadoop.tmp.dir</name>这个配置项定义了Hadoop存放临时文件的目录。这里设置为
file:///opt/hadoop-record/tep,意味着所有Hadoop产生的临时文件将存储在本地文件系统的/opt/hadoop-record/tep目录下。这些配置通常被写入到Hadoop的核心配置文件
core-site.xml中,该文件位于Hadoop的配置目录$HADOOP_HOME/etc/hadoop/内。通过修改这些配置,可以指定Hadoop如何存储数据以及临时文件的存放位置,这对于优化性能和管理数据至关重要。
2、hdfs-site.xml
bash
[root@hadoop hadoop] vim /opt/hadoop/etc/hadoop/hdfs-site.xml在configuration块中添加以下配置
XML
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///opt/hadoop-record/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///opt/hadoop-record/data</value>
</property>
<property>每一个
<property>标签都定义了一个具体的配置项,包括配置项的名称和对应的值。
<name>dfs.replication</name>
功能描述:此配置项决定了HDFS中数据块的默认复制因子。复制因子是指一个数据块在HDFS集群中存储的副本数量。
你的设置 :你将其设置为
1,这意味着数据块只在一个节点上保存一份副本,不进行冗余备份。在生产环境中,这通常是不推荐的做法,因为如果存储数据的节点出现故障,数据可能会丢失。但在测试或开发环境中,为了节省资源,有时会采用这种方式。
<name>dfs.namenode.name.dir</name>
功能描述:此配置项指定了NameNode存储元数据信息的本地文件系统目录。
你的设置 :将其设置为
file:///opt/hadoop-record/name,这意味着NameNode的元数据将存储在本地文件系统的/opt/hadoop-record/name目录下。
<name>dfs.datanode.data.dir</name>
功能描述:此配置项指定了DataNode存储实际数据块的本地文件系统目录。
你的设置 :你将其设置为
file:///opt/hadoop-record/data,这意味着DataNode的数据块将存储在本地文件系统的/opt/hadoop-record/data目录下。
3、mapred-site.xml
bash
[root@hadoop hadoop] vim /opt/hadoop/etc/hadoop/mapred-site.xml在configuration块中添加以下配置
XML
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<configuration>这是Hadoop配置文件中的根元素,用于封装所有的配置项。
<property>此标签定义了一个具体的配置属性,包含了属性的名称和值。
<name>mapreduce.framework.name</name>
功能描述:此配置项指定了MapReduce作业执行时所依赖的资源管理和调度框架。在Hadoop生态系统中,YARN(Yet Another Resource Negotiator)是一个通用的资源管理系统,它不仅可以管理MapReduce作业,还可以支持其他类型的计算框架。
设置 :将其设置为
yarn,这意味着MapReduce作业将通过YARN来进行资源管理和调度。这是Hadoop 2.x版本及以后版本的默认设置,YARN提供了一个更加灵活和强大的平台,允许多种计算框架共存于同一集群中。
4、yarn-site.xml
bash
[root@hadoop hadoop] vim /opt/hadoop/etc/hadoop/yarn-site.xml 在configuration块中添加以下配置
XML
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>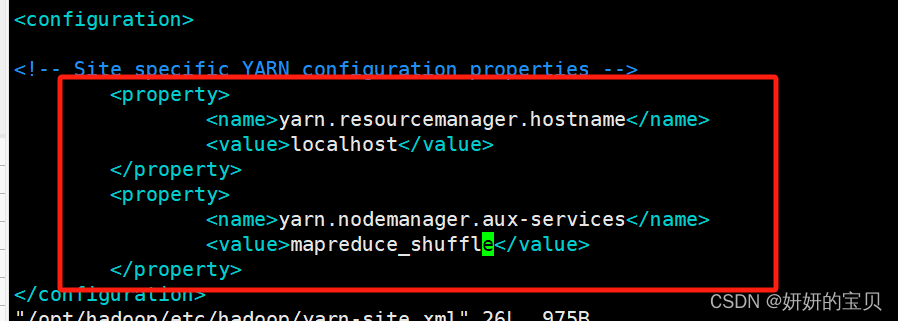
3.3 启动hadoop与权限修改
格式化namenode
root@hadoop \~# hdfs namenode -format
root@hadoop \~# start-all.sh
接下来启动hadoop会有可能发现以下问题,这是由于hadoop用户权限不足
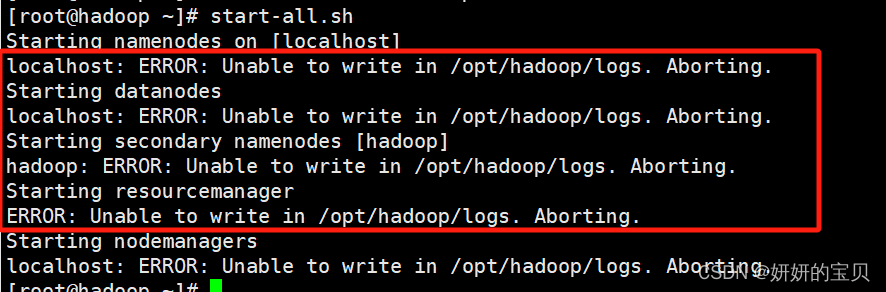
修改权限
root@hadoop \~# chown -R hadoop:hadoop /opt/hadoop
3.4 再次启动hadoop
root@hadoop opt# start-all.sh

jsp 命令输出显示了当前运行在你的 hadoop 节点上的 Java 进程及其进程ID(PID)
root@hadoop opt# jps
9824 NameNode
10738 NodeManager
13539 Jps
10020 DataNode
10582 ResourceManager
10329 SecondaryNameNode

关闭防火墙
root@hadoop opt# systemctl stop firewalld
浏览器打开虚拟机的ip+端口号
