生成对抗网络(Generative Adversarial Networks,GANs)是一种由 Ian Goodfellow 等人在2014年提出的深度学习模型Generative Adversarial Networks。GANs的基本思想是通过两个神经网络(生成器和判别器)的对抗过程,生成与真实数据分布相似的新数据。以下是对GANs的详细介绍。
1. 基本结构
GANs由两个主要组件构成:
1.1 生成器(Generator)
生成器的任务是从一个随机噪声(通常是高斯噪声)中生成逼真的数据样本。生成器是一个神经网络,它接受一个随机向量作为输入,并输出一个与真实数据分布相似的样本。目标是欺骗判别器,使其认为生成的数据是真实的。
1.2 判别器(Discriminator)
判别器是另一个神经网络,用于区分真实数据和生成器生成的假数据。它的输入是一个数据样本,输出是一个标量值,表示输入数据是真实的概率。判别器的目标是最大化区分真实数据和生成数据的准确性。
2. 工作原理
GANs通过生成器和判别器的对抗训练来实现目标。训练过程中,两者的目标是相反的:
- 生成器试图最大限度地欺骗判别器,使其无法区分生成数据和真实数据。
- 判别器则尽量提高区分真实数据和生成数据的能力。
这种对抗训练可以形式化为一个极小极大(minimax)问题:
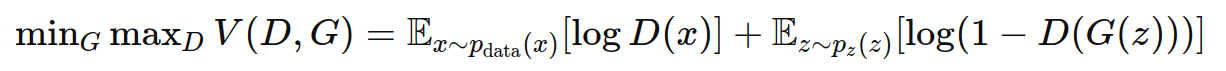
其中,D(x) 是判别器对真实数据 x 的输出, G(z) 是生成器对随机噪声 z 的输出。
3. 训练过程
- 初始化:随机初始化生成器和判别器的参数。
- 训练判别器:在固定生成器的情况下,用一批真实数据和生成数据训练判别器,更新判别器的参数。
- 训练生成器:在固定判别器的情况下,用生成器生成的假数据训练生成器,更新生成器的参数。
- 循环:重复上述步骤,直到生成器生成的数据足够逼真。
下面是一个使用TensorFlow和Keras实现简单生成对抗网络(GAN)的示例代码。该代码使用MNIST手写数字数据集来训练生成器生成类似手写数字的图像。
python
import tensorflow as tf
from tensorflow.keras import layers, models
import numpy as np
import matplotlib.pyplot as plt
# 加载MNIST数据集
(train_images, _), (_, _) = tf.keras.datasets.mnist.load_data()
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
train_images = (train_images - 127.5) / 127.5 # 将图像标准化到 [-1, 1] 区间
BUFFER_SIZE = 60000
BATCH_SIZE = 256
# 创建数据集
train_dataset = tf.data.Dataset.from_tensor_slices(train_images).shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
# 生成器模型
def make_generator_model():
model = models.Sequential()
model.add(layers.Dense(7*7*256, use_bias=False, input_shape=(100,)))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Reshape((7, 7, 256)))
assert model.output_shape == (None, 7, 7, 256) # 注意:None 是批量大小
model.add(layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False))
assert model.output_shape == (None, 7, 7, 128)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False))
assert model.output_shape == (None, 14, 14, 64)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh'))
assert model.output_shape == (None, 28, 28, 1)
return model
# 判别器模型
def make_discriminator_model():
model = models.Sequential()
model.add(layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same', input_shape=[28, 28, 1]))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Flatten())
model.add(layers.Dense(1))
return model
# 定义损失函数和优化器
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def discriminator_loss(real_output, fake_output):
real_loss = cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
total_loss = real_loss + fake_loss
return total_loss
def generator_loss(fake_output):
return cross_entropy(tf.ones_like(fake_output), fake_output)
generator = make_generator_model()
discriminator = make_discriminator_model()
generator_optimizer = tf.keras.optimizers.Adam(1e-4)
discriminator_optimizer = tf.keras.optimizers.Adam(1e-4)
# 训练步骤
@tf.function
def train_step(images):
noise = tf.random.normal([BATCH_SIZE, 100])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_output = discriminator(images, training=True)
fake_output = discriminator(generated_images, training=True)
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
# 训练过程
def train(dataset, epochs):
for epoch in range(epochs):
for image_batch in dataset:
train_step(image_batch)
# 每个epoch结束时生成并保存一些图像
generate_and_save_images(generator, epoch + 1, seed)
# 最后一个epoch生成图像
generate_and_save_images(generator, epochs, seed)
# 生成并保存图像的辅助函数
def generate_and_save_images(model, epoch, test_input):
predictions = model(test_input, training=False)
fig = plt.figure(figsize=(4, 4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i+1)
plt.imshow(predictions[i, :, :, 0] * 127.5 + 127.5, cmap='gray')
plt.axis('off')
plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
# 训练模型
EPOCHS = 50
noise_dim = 100
num_examples_to_generate = 16
seed = tf.random.normal([num_examples_to_generate, noise_dim])
train(train_dataset, EPOCHS)说明
- 数据预处理: 加载MNIST数据集并进行归一化处理。
- 模型构建 :
- 生成器: 从随机噪声生成图像。
- 判别器: 区分真实图像和生成图像。
- 损失函数: 使用二元交叉熵损失函数。
- 优化器: 使用Adam优化器。
- 训练过程: 每个训练步骤包含生成图像、判别图像,并计算和应用梯度更新。
- 结果可视化: 在训练过程中生成并保存图像。
运行上述代码后,会看到生成的手写数字图像,这些图像与真实的MNIST数据集中的手写数字非常相似。
4. 常见问题与改进
生成对抗网络(GANs)虽然在许多领域取得了显著成果,但也存在一些显著的缺点和挑战。这些缺点主要源于其对抗训练的复杂性和网络设计的固有特性。
1. 训练不稳定
原因: GANs的训练是一个极小极大(minimax)优化问题,生成器和判别器的目标是相反的,这导致了训练过程的不稳定性。
- 对抗失衡: 如果判别器太强,它会很容易区分生成的数据和真实数据,使生成器无法学习。如果生成器太强,它会欺骗判别器,使其失去鉴别能力。
- 梯度消失或爆炸: 在训练过程中,梯度可能会消失或爆炸,尤其是在深层网络中,这使得训练过程更加困难。
2. 模式崩溃(Mode Collapse)
原因: 生成器可能会找到一些特定模式的生成样本,这些样本能很好地欺骗判别器,但缺乏多样性。
- 单一输出: 生成器可能会倾向于生成几种特定的输出模式,而忽略其他可能的输出,导致生成样本缺乏多样性。
- 判别器反馈不足: 如果判别器未能有效反馈生成样本的多样性问题,生成器将持续生成相同或相似的样本。
这些缺点和挑战使得GANs在实际应用中需要进行细致的调整和改进,但也促使研究者不断提出新的方法和变体,以改善GANs的性能和稳定性:
1 条件GAN(Conditional GANs,cGANs)
通过在生成器和判别器中加入条件变量,使得生成的样本能够受控于特定的条件。例如,可以生成特定类别的图像。
2 Wasserstein GANs(WGANs)
通过使用Wasserstein距离替代原始GAN中的Jensen-Shannon散度,解决了训练不稳定的问题,使得训练过程更加平滑。
3 深度卷积GAN(Deep Convolutional GANs,DCGANs)
利用卷积神经网络(CNN)来构建生成器和判别器,提高了生成图像的质量。
5. 应用场景
GANs在许多领域都有广泛的应用,包括但不限于:
- 图像生成:生成高质量的图像,例如人脸、风景等。
- 图像修复:修复受损图像或填补缺失部分。
- 图像超分辨率:提高低分辨率图像的分辨率。
- 数据增强:在数据不足的情况下生成更多训练样本。
- 视频生成:生成逼真的视频序列。