问题
当用户访问量比较大时,某个业务功能需要频繁查询数据库,会让数据库访问压力增大,会导致系统响应慢,用户体验差
解决
通过Redis来缓存数据,减少数据库查询操作
实例
当我们在小程序点餐时,每次都需要通过查询数据库来获取菜品的数据,那么当用户量一多的时候,就会让数据库的访问压力增大,导致系统响应慢,现在就需要通过Redis来缓存菜品数据。
思路

注意: 数据库中的数据有变更时要及时清理缓存 数据,否则会造成数据不一致
代码实现
登录后复制
java
/**
* 根据分类id查询菜品
*
* @param categoryId
* @return
*/
@GetMapping("/list")
@ApiOperation("根据分类id查询菜品")
public Result<List<DishVO>> list(Long categoryId) {
//构造key
String key = "dish_" + categoryId;
//查询redis总是否存在菜品数据
List<DishVO> list = (List<DishVO>)redisTemplate.opsForValue().get(key);
//如果存在,直接返回,无须查询数据库
if(list !=null && list.size() >0){
return Result.success(list);
}
Dish dish = new Dish();
dish.setCategoryId(categoryId);
dish.setStatus(StatusConstant.ENABLE);//查询起售中的菜品
//如果不存在,查询数据库,将查询的数据放入redis中
list = dishService.listWithFlavor(dish);
redisTemplate.opsForValue().set(key,list);
return Result.success(list);
}
当我们改变后台数据时,我们会发现小程序端的数据并没有改变
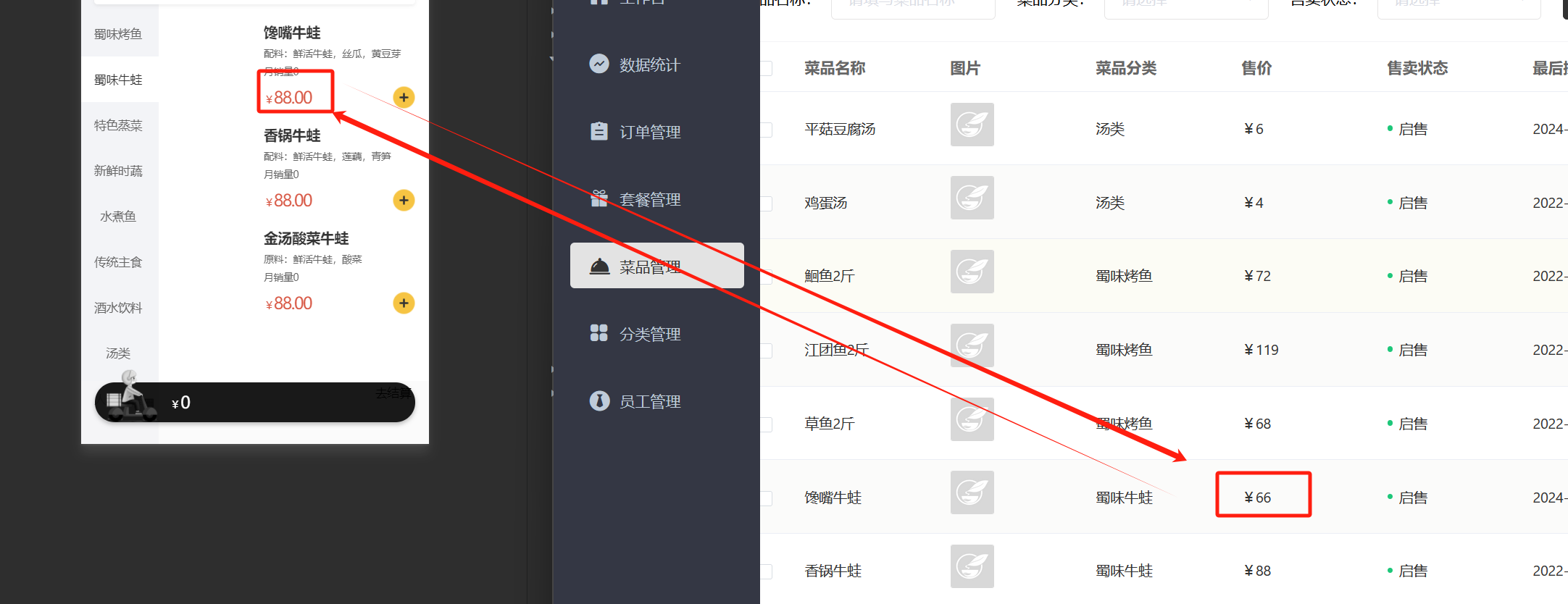
这就是不清理缓存而导致数据不一致
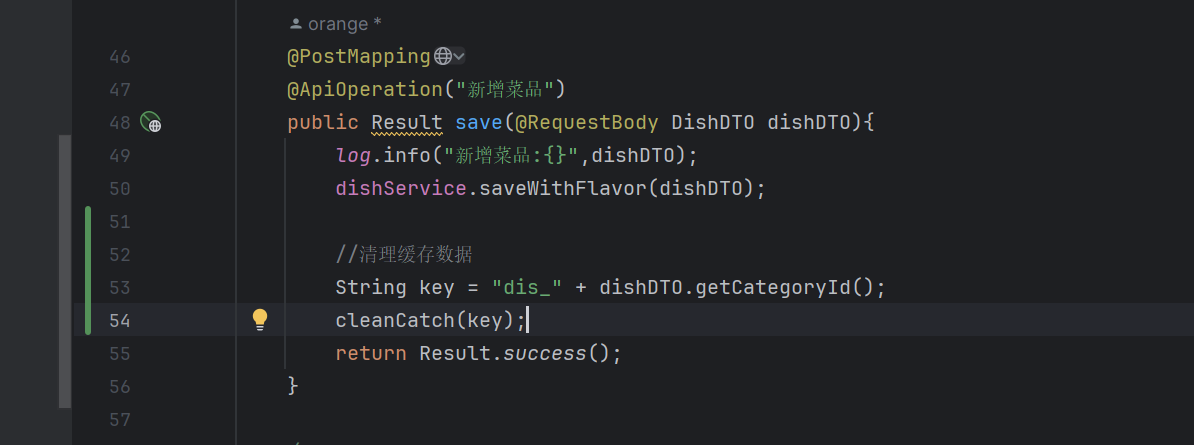
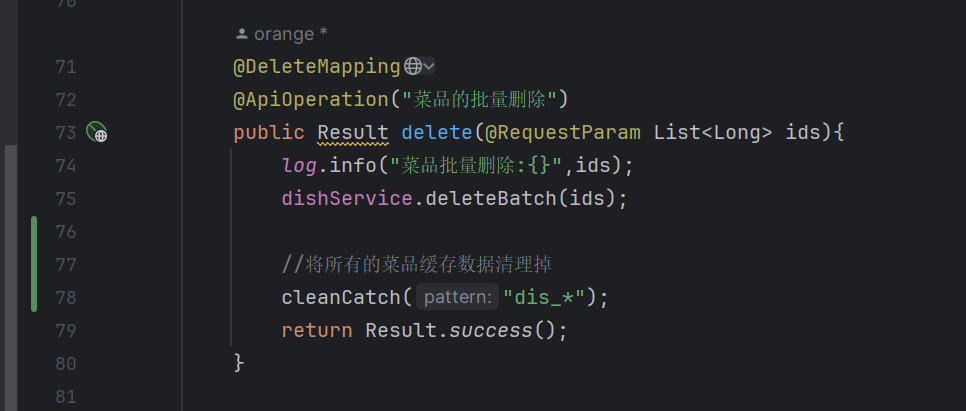
当新增菜品、修改菜品、批量删除菜品、起售停售菜品都需要加入清理缓存的逻辑(管理端)
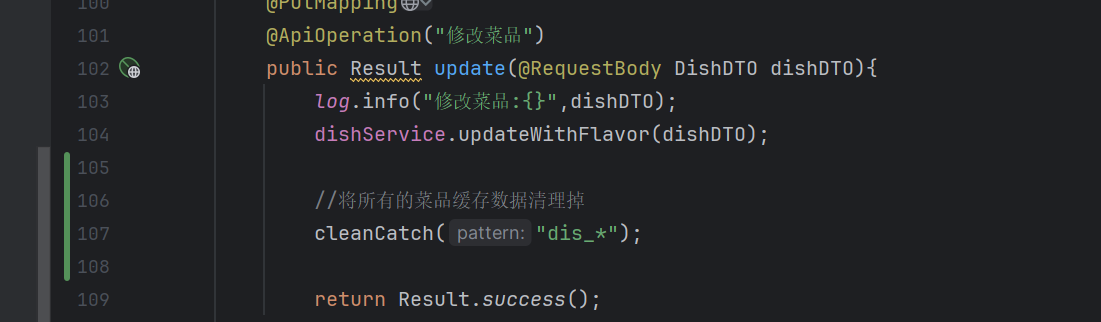
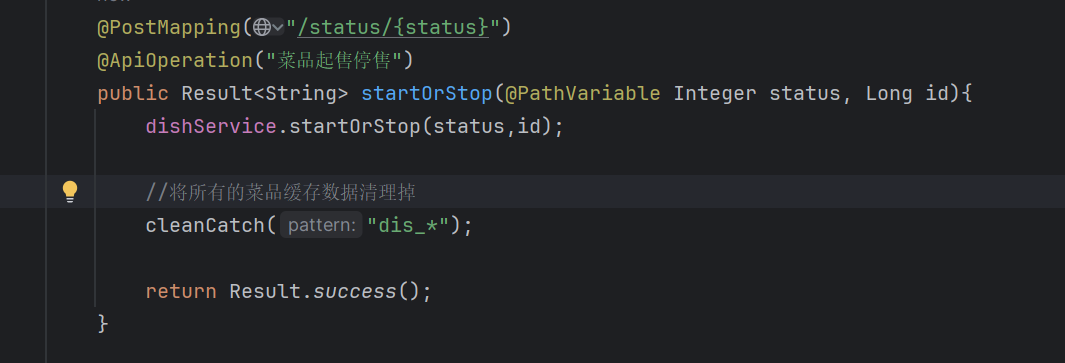
登录后复制
plain
/**
* 统一清理缓存数据
* @param pattern
*/
private void cleanCatch(String pattern){
Set keys = redisTemplate.keys(pattern);
redisTemplate.delete(keys);
}Spring Catch
Spring Cache是一个框架,实现了基于注解的缓存功能,只需要简单地加一个注解,就能实现缓存功能。
Spring Cache提供了一层抽象,底层可以切换不同的缓存实现,例如:
- EHCache
- Caffeine
- Redis
常用注解
- @EnableCaching
开启缓存注解功能,通常加在启动类上
- @Cacheable
在方法执行前先查询缓存中是否有数据,如果有数据,则直接返回缓存数据;如果没有缓存数据,调用方法并将方法返回值放到缓存中
- @CachePut
将方法的返回值放到缓存中
- @CacheEvict
将一条或多条数据从缓存中删除
实例
登录后复制
java
/**
* 条件查询
*
* @param categoryId
* @return
*/
@GetMapping("/list")
@ApiOperation("根据分类id查询套餐")
@Cacheable(cacheNames = "setmealCatch",key = "#categoryId")//setmealCatch::100
public Result<List<Setmeal>> list(Long categoryId) {
Setmeal setmeal = new Setmeal();
setmeal.setCategoryId(categoryId);
setmeal.setStatus(StatusConstant.ENABLE);
List<Setmeal> list = setmealService.list(setmeal);
return Result.success(list);
}在管理端增删改都加(key要对应上)
- @CacheEvict
登录后复制
plain
/**
* 新增套餐
* @param setmealDTO
* @return
*/
@PostMapping
@ApiOperation("新增套餐")
@CacheEvict(cacheNames = "setmealCatch",key="setmealDTO.categoryId")
public Result save(@RequestBody SetmealDTO setmealDTO) {
setmealService.saveWithDish(setmealDTO);
return Result.success();
}
/**
* 批量删除套餐
* @param ids
* @return
*/
@DeleteMapping
@ApiOperation("批量删除套餐")
@CacheEvict(cacheNames = "setmealCatch",allEntries = true)
public Result delete(@RequestParam List<Long> ids){
setmealService.deleteBatch(ids);
return Result.success();
}
/**
* 修改套餐
*
* @param setmealDTO
* @return
*/
@PutMapping
@ApiOperation("修改套餐")
@CacheEvict(cacheNames = "setmealCatch",allEntries = true)
public Result update(@RequestBody SetmealDTO setmealDTO) {
setmealService.update(setmealDTO);
return Result.success();
}
/**
* 套餐起售停售
* @param status
* @param id
* @return
*/
@PostMapping("/status/{status}")
@ApiOperation("套餐起售停售")
@CacheEvict(cacheNames = "setmealCatch",allEntries = true)
public Result startOrStop(@PathVariable Integer status, Long id) {
setmealService.startOrStop(status, id);
return Result.success();
}为什么实体类需要implements Serializable接口这个接口
首先我们需要明白什么是序列化
序列化
序列化是将对象状态转换为可保持或传输的格式的过程,与序列化相对的是反序列化,它将流转换为对象。这两个过程结合起来,可以轻松地存储和传输数据。
为什么要序列化
首先
把对象 转换为字节 序列的过程称为对象的序列化
把字节 转换为对象 的的过程称为对象的反序列化
序列化对于面向对象的编程语言来说是非常重要的,因为无论什么编程语言,其底层涉及IO操作的部分还是由操作系统其帮其完成的,而底层IO操作都是以字节流的方式进行的,所以写操作都涉及将编程语言数据类型转换为字节流,而读操作则又涉及将字节流转化为编程语言类型的特定数据类型。
Serializable接口是什么?
Serializable是一个对象序列化的接口,一个类只有实现了Serializable接口,它的对象才能被序列化,Serializable是java,io包中定义的、用于实现JAVA类的序列化操作而提供的的一个语义级别的接口。 Serializable序列化接口没有任何方法或者字段,只是用于标识可序列化的语义
实现了Serializable接口的类可以被ObjectOutputStream转换为字节流,同时也可以通过ObjectInputStream再将其解析为对象
什么情况下需要序列化
当我们需要把对象的状态信息通过网络进行传输,或者需要将对象的状态信息持久化,以便将来使用时都需要把对象进行序列化。
那为什么还要继承Serializable。那是存储对象在存储介质中,以便在下次使用的时候,可以很快捷的重建一个副本。
或许你会问,我在开发过程中,实体并没有实现序列化,但我同样可以将数据保存到mysql、Oracle数据库中,为什么非要序列化才能存储呢?
我们看看Serializable长什么样
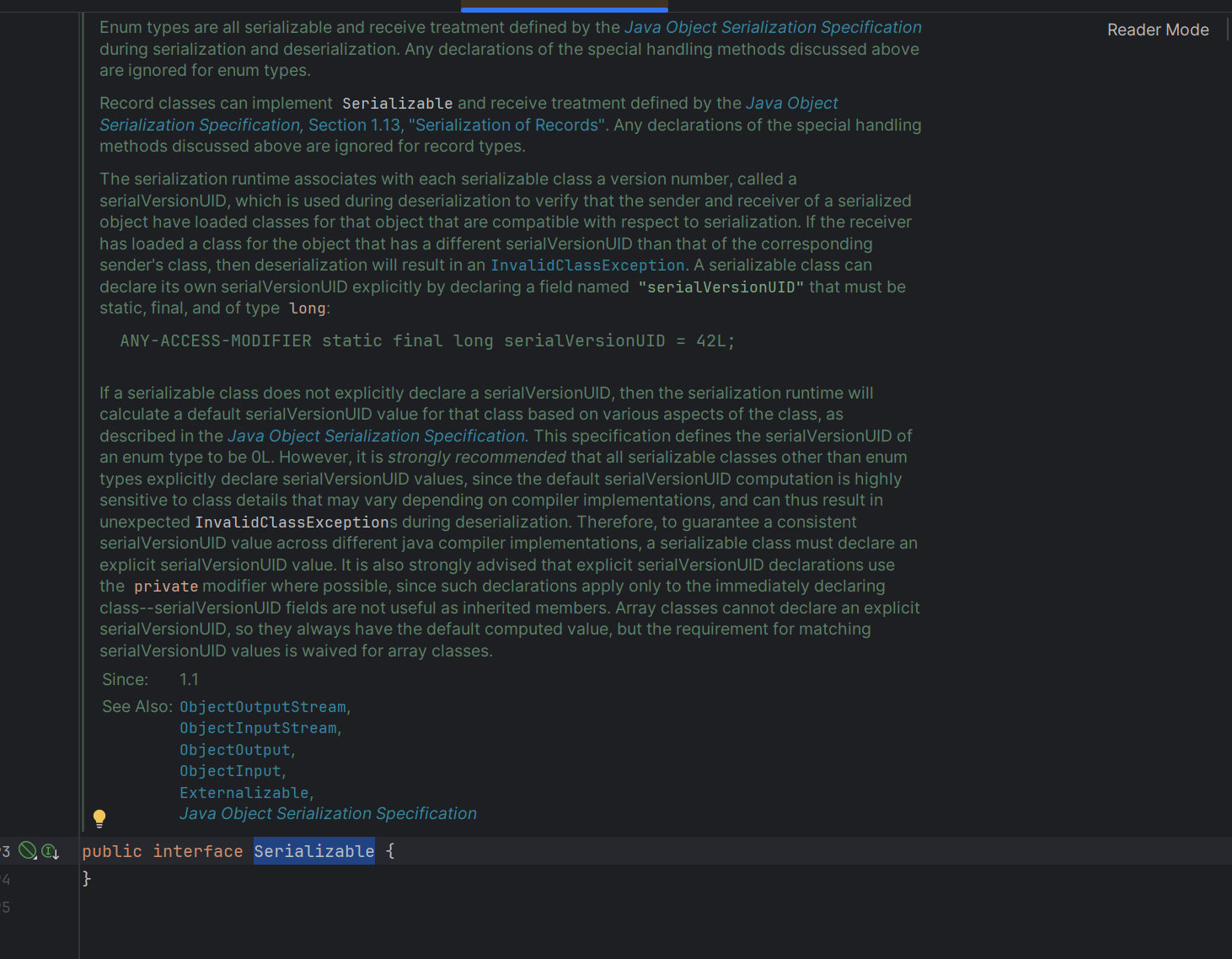
这里面什么都没有,我们可以把它理解成一个标识接口
比如说你在工作室遇到问题了,去请教别的同学,那个同学给你解决了。这时候去请教这个动作就是一个标识,自己解决不了的去请教同学解决。在JAVA中Serializable接口就是请教这个标识,但它是给JVM看的,通知JVM我不对这个类做序列化,你(JVM)帮我序列化