前言
向量数据库在 AI 与大模型(LLM) 领域中是个至关重要的组件,主要承担"记忆与检索"的角色,其解决了大模型不能长期存储海量知识、推理效率受限的问题,无论是 RAG、推荐系统还是智能搜索,向量数据库都提供了"相似度搜索"的能力,让模型能找到相关上下文,而不仅仅依赖参数记忆。这其中,pgvector 则是个比较独特的存在,选择站在 PostgreSQL 的基础上,高屋建瓴,而不是另起炉灶。随着版本的不断革新,pgvector 正在从一个实验性扩展,成长为 PostgreSQL 生态中"通用的向量搜索引擎",成为 LLM/RAG/AI 应用的基础组件。
Roadmap
从 pgvector 的 roadmap 中,不难看出,pgvector 在规模化落地场景下,不断在尝试与优化,pgvector 正在从"能用"走向"高效、可扩展、适合大规模 AI 应用"的阶段。

v0.4.x:
改进 IVFFlat 计划代价估算:优化了执行计划的成本模型,让查询优化器更合理地选择是否使用 IVFFlat 索引。
增加向量维度上限:支持更高维度的向量存储,无论在表还是索引中,都能容纳更大维度的 embedding。
v0.5.x:
新增 HNSW 索引:引入 Hierarchical Navigable Small World 图索引,大幅提升高维向量相似度搜索性能。
距离函数性能优化:加快余弦、内积等相似度度量的计算速度。
并行 IVFFlat 构建:支持并行化创建 IVFFlat 索引,提高大规模索引构建效率。
v0.6.x:
并行 HNSW 构建:在 HNSW 索引上引入并行化构建机制,适合海量数据集场景。
内存构建优化:提升了索引构建时的内存使用效率,加快索引建立速度并减少资源消耗。
v0.7.x:
halfvec 类型:支持 2 字节浮点(半精度 float16),节省存储空间并加快计算。
bit(n) 索引支持:支持对 bit 向量进行索引。
sparsevec 类型 :稀疏向量支持,维度上限可达 10 亿,适合大规模稀疏 embedding,应用范围越来越广,说明 pgvector 正在从"文本 embedding"走向多模态应用(文本、图像、音频、二进制特征)
量化(Quantization):支持 scalar/binary 量化,进一步压缩存储和加速检索。
新距离度量:支持 Jaccard / Hamming 距离。
显式 SIMD :利用 CPU SIMD 指令集进行加速,显式 SIMD 则说明团队在尝试利用底层硬件优化计算,未来版本会更注重 高维、大规模 embedding 的低成本存储和高效计算。
v0.8.x:
Iterative Index Scan:提升带过滤条件查询时的召回率。
HNSW 优化:改进索引构建与查询性能。
云平台支持:如 Aurora、Cloud SQL 等主流云服务都已集成。
迭代扫描
0.8.0 中的迭代扫描,是我十分喜欢的特性,在 ANN 场景中,我们往往不会在全表里暴力搜索,而是要加上过滤条件,再在符合条件的数据里做向量相似度计算,但是这样就会遇到典型的 pre-filter 和 post-filter 的问题:
Pre-filtering:先应用业务过滤条件,然后在过滤后的子集里做向量相似度检索,检索空间小,结果更符合业务语义;但是只能用暴力搜索,因为过滤后的子集不再能直接利用 ANN 索引 (IVFFlat/HNSW);缺乏可扩展性,大规模数据下速度慢;
Post-filtering:先在全量数据里使用 ANN 索引做向量近似搜索,得到候选集合,再对结果应用业务过滤条件。好处是能用上 ANN 索引,查询速度快,适合大规模数据;但可能会导致过滤后结果不足。
 Optimizing Filtered Vector Search in MyScale | Medium
Optimizing Filtered Vector Search in MyScale | Medium
pgvector 0.8.0 引入的 Iterative Index Scans,其实就是为了解决刚才提到的 Post-filter 与 Pre-filter 的矛盾,一个折中方案,先用 ANN 索引检索一批候选 (例如 Top-K),再应用过滤条件。如果过滤后结果还不够,就继续从索引里取更多候选,再过滤,直到得到足够的结果,或者索引没有更多候选。这样的话,好处十分明显:可以用上 ANN 索引(速度快),并且保证过滤条件被应用,同时还避免了 Post-filter 一次性取 N 条候选但可能不够的情况,大幅提升了带过滤条件的向量查询在 PostgreSQL 里的可用性和扩展性。
量化
0.7.0 以后还支持 Quantization 减少索引的大小,量化在实际应用中是一种存储与性能的平衡手段,适合大规模 embedding 场景。量化是指将高精度浮点向量压缩成更低精度的表示,以减少存储和加快计算,代价是精度损失(Recall 降低),但通过 rerank可恢复精度。其中量化又分为:
Scalar Quantization (标量量化):例如把 4 字节 float 压缩成 2 字节 half-float,甚至 1 字节整数。
Binary Quantization (二值量化):将向量编码为比特串,用汉明距离比较。

根据实验,Scalar (2-byte float):索引大小减半 (7.7GB→3.8GB),查询速度稍有提升,Recall 几乎不变。Binary:索引极小 (7.7GB→0.47GB),构建速度更快,QPS 大幅提高,但 Recall 降低,需要 rerank 补偿。
IVFFlat Index Vs. HNSW Index
另外一个老生常谈的问题便是索引的选择了,什么时候选择 IVFFlat?什么时候选择 HNSW?
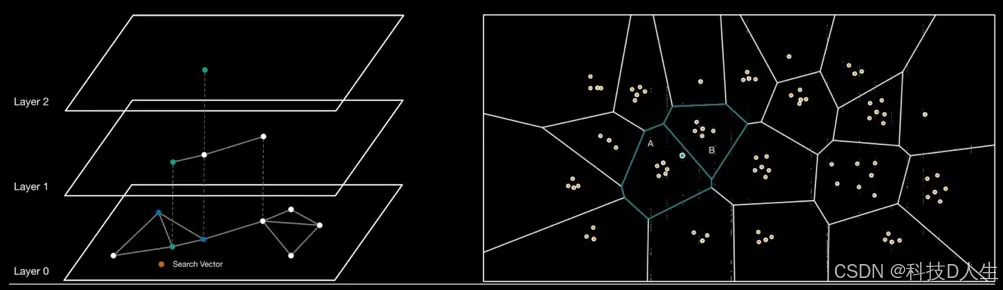
IVFFLAT:
建索引时需要训练步骤,即必须有一定数量的数据;
插入新数据后,如果分布发生变化,索引可能需要重建,尤其是频繁变更的场景,需要定期重建;
检索速度快,但召回率受限于簇的划分与搜索范围(由 probes 参数控制)。
典型场景:离线批量语义搜索、企业知识库、冷数据索引。
HNSW:
不需要聚类训练,可以随时插入;
插入时间会随着数据量增加而变慢;
查询速度和 recall 表现优异;
索引体积和内存消耗较大。
典型场景:在线推荐、对话检索(RAG)、个性化搜索、需要低延迟的实时应用。
其中在创建 HNSW 索引的时候,还有 m 和 ef_construction 选项:m 用于控制索引图的稠密程度(每个点的邻居数);ef_construction 则是用于控制建索引时的候选规模,影响建图质量与召回率;就像"面试时你愿意筛选多少简历"。筛得越多,找到最佳候选的概率越大,但耗费的时间也越多。两者都越大,召回率越高,但内存和构建开销越大。
总结
pgvector 正在从一个实验性扩展,成长为 PostgreSQL 生态中"通用的向量搜索引擎",成为 LLM/RAG/AI 应用的基础组件。根据奥卡姆剃刀原理,PostgreSQL 以其先进性、可扩展性等,当之无愧为 AI 时代的数据库首选。
参考:
https://github.com/pgvector/pgvector
Best practices for using pgvector
PostgreSQL 上的向量搜索实践