1、介绍
MobileViT 轻量级的分类识别网络,结合了CNN卷积和Transformer 混合的网络架构
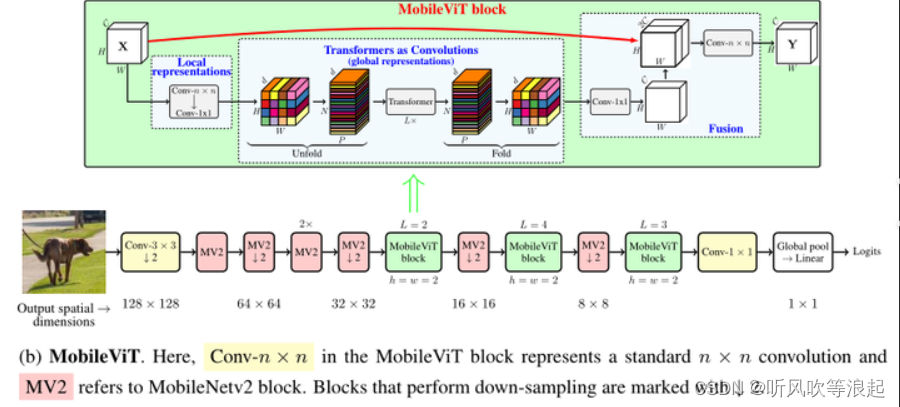
关于更多介绍可以自行百度,本文通过pytorch+python进行实现
更多基础的图像分类网络,参考:图像分类_听风吹等浪起的博客-CSDN博客
2、相关代码及展示
目录如下:代码下载:基于MobileViT的xxs、xs、s版本实现的30种球类运动迁移学习分类实战【包含数据集+完整代码+训练结果】资源-CSDN文库

mobileViT 官方好像有三种大小:xxs、xs、s,对应不同大小,这里一并实现
2.1 数据集
数据集的放置仍然采用目录的形式,需要自行划分训练集+验证集+测试集
训练集用于网络训练、验证集用于微调训练参数、测试集用于评估网络性能
数据集如下:
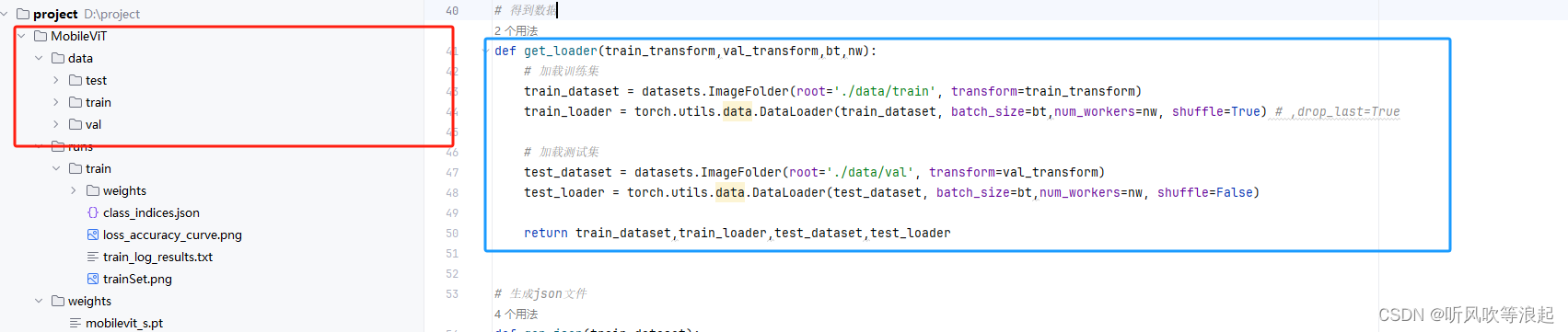
这里把路径名称写好了,可以改代码,或者觉得麻烦,直接按照参考命名数据集即可
这里的图像增强就是简单的翻转,如下:
def data_trans(train_mean=[0.485, 0.456, 0.406], train_std=[0.229, 0.224, 0.225]):
# 预处理
train_transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.RandomHorizontalFlip(p=0.5), # 水平翻转
transforms.RandomVerticalFlip(p=0.5), # 垂直翻转
transforms.ToTensor(),
transforms.Normalize(train_mean, train_std)])
val_transform = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),
transforms.ToTensor(),transforms.Normalize(train_mean, train_std)])
return train_transform,val_transform2.2 训练脚本
训练的超参数如下:脚本为train.py
冻结权重,是指只训练分类器的部分,否则全部重头训练。
这里选择xxs、xs、s版本后,会自动导入官方的预训练权重,因此冻结参数也可以
不需要指定网络分类的个数,代码会根据数据集自动生成!
parser = argparse.ArgumentParser(description="image classification")
parser.add_argument("--model", default='s', type=str,help='xxs,xs,s') # 选择版本
parser.add_argument("--batch-size", default=8, type=int)
parser.add_argument("--epochs", default=5, type=int)
parser.add_argument('--lr', default=0.0002, type=float)
parser.add_argument('--freeze-layers', type=bool, default=True) # 是否冻结权重优化器采用AdamW,损失为多元交叉熵损失
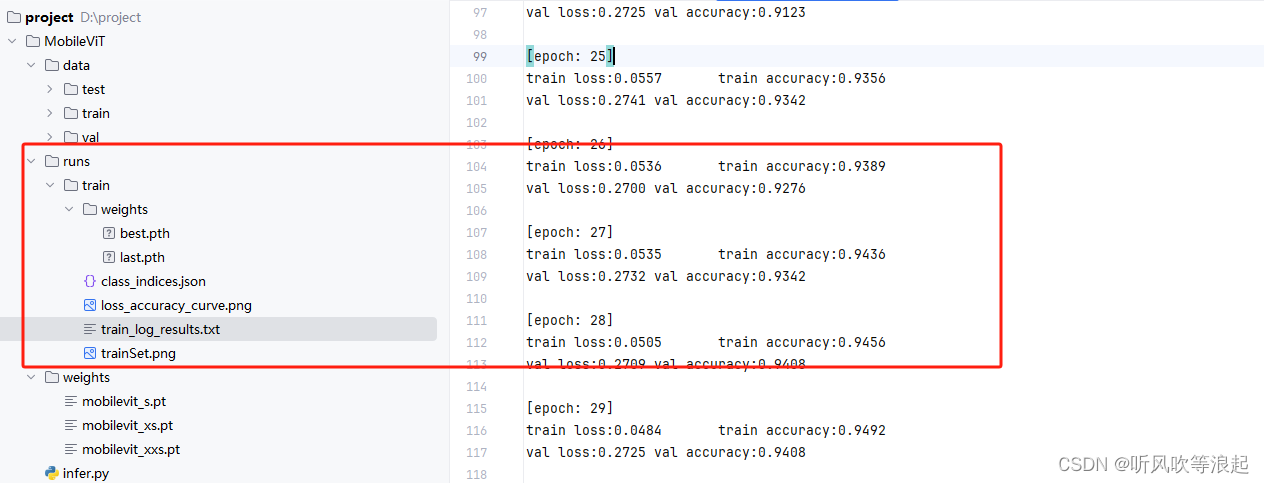
训练过程如下:
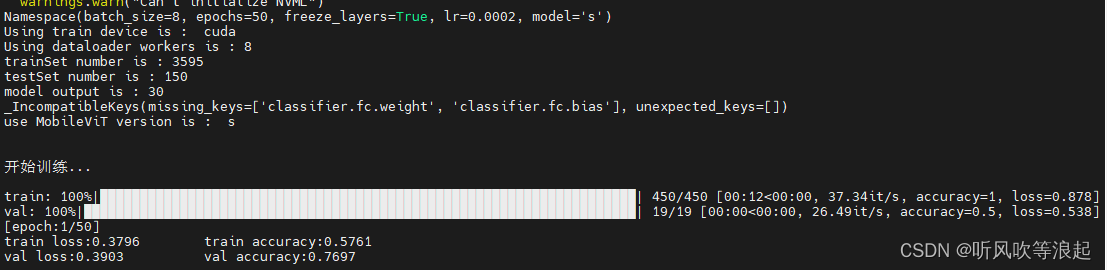

这里可视化进度条的描述,是每个batch的正确率和损失,下面打印的是整个数据集的准确率和损失
结果曲线为:
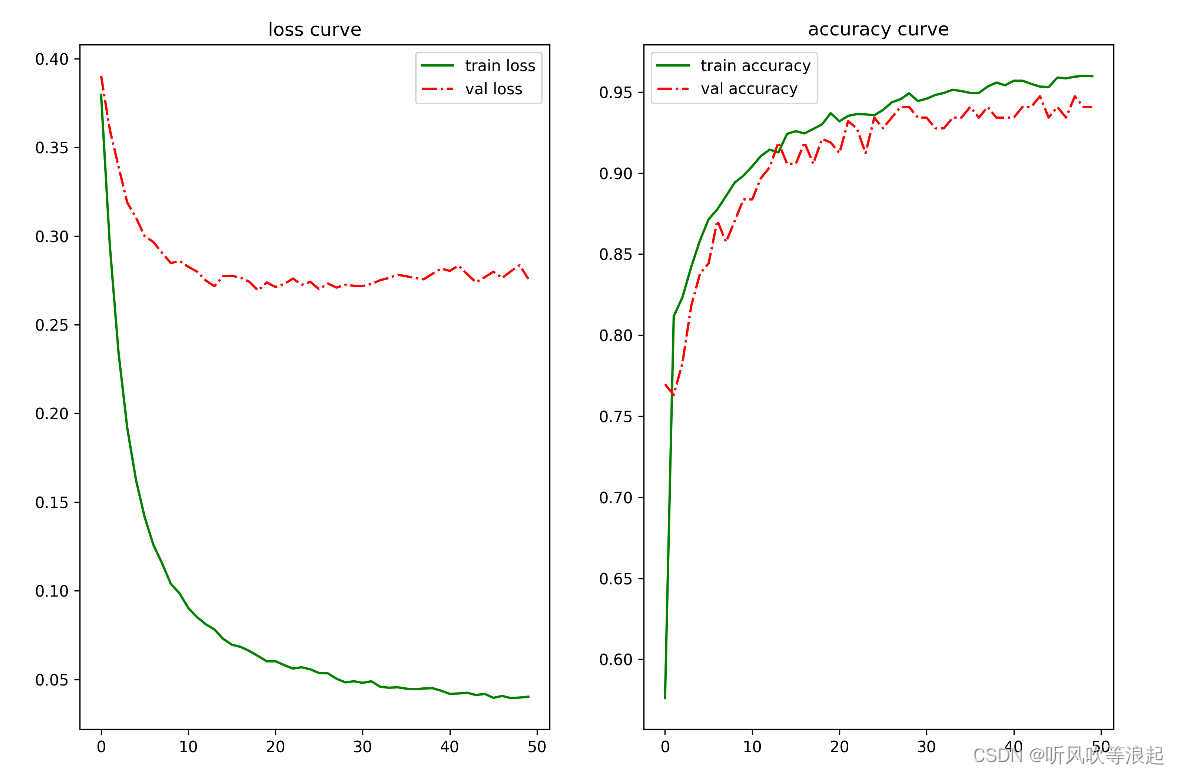
生成结果:
2.3 验证脚本
验证脚本为:val.py 函数
parser.add_argument("--model", default='s', type=str,help='xxs,xs,s') # 选择版本
parser.add_argument("--pth", default='runs/train/weights/best.pth', type=str,help='best,last')
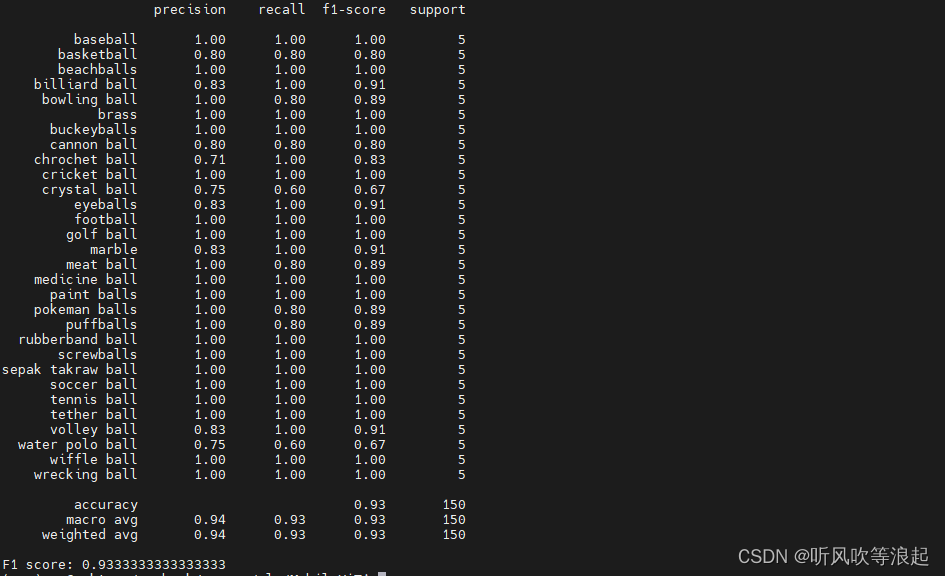
parser.add_argument("--data", default='data/val', type=str,help='data path')这里自动载入最好的结果进行评估网络,结果如下
2.4 推理脚本
脚本为 infer.py
parser.add_argument("--model", default='s', type=str,help='xxs,xs,s') # 选择版本
parser.add_argument("--pth", default='runs/train/weights/best.pth', type=str,help='best,last')
parser.add_argument("--data", default='test.jpg', type=str,help='image path')传入单张图片即可进行推理:
