

-
作者: Shaoting Zhu, Linzhan Mou, Derun Li, Baijun Ye, Runhan Huang, Hang Zhao
-
单位:清华大学交叉信息研究院,上海期智研究院,Galaxea AI,上海交通大学电子信息与电气工程学院
-
论文标题:VR-Robo: A Real-to-Sim-to-Real Framework for Visual Robot Navigation and Locomotion
-
出版信息:IEEE ROBOTICS AND AUTOMATION LETTERS, 2025
主要贡献
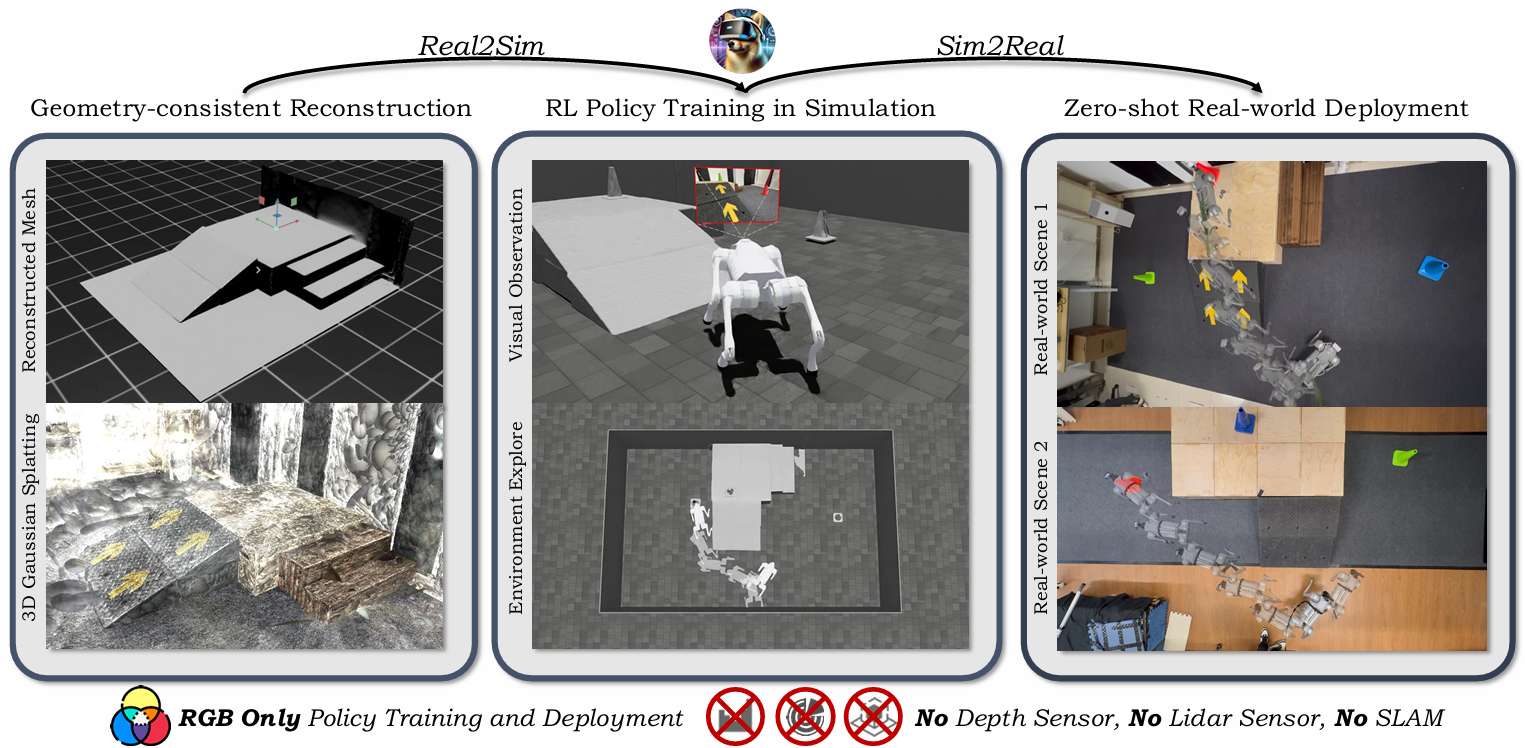
-
提出"Real-to-Sim-to-Real"训练框架:从真实环境中仅通过RGB图像重建逼真且可交互的数字孪生仿真环境,用于机器人视觉导航和运动控制策略的训练。
-
引入GS-Mesh混合建模与交互机制:结合3D Gaussian Splatting和Mesh模型,实现同时具备视觉真实感与物理交互能力的仿真环境构建。
-
实现RGB-only零样本迁移:所训练的策略无需深度/LiDAR/SLAM信息,仅依赖RGB视觉即可从仿真环境无缝部署至真实世界,展现出良好的泛化能力与鲁棒性。
-
提出场景随机化与遮挡感知机制:通过智能体-物体的随机化布置与遮挡感知场景合成,有效提升策略的探索能力与稳健性。
研究背景
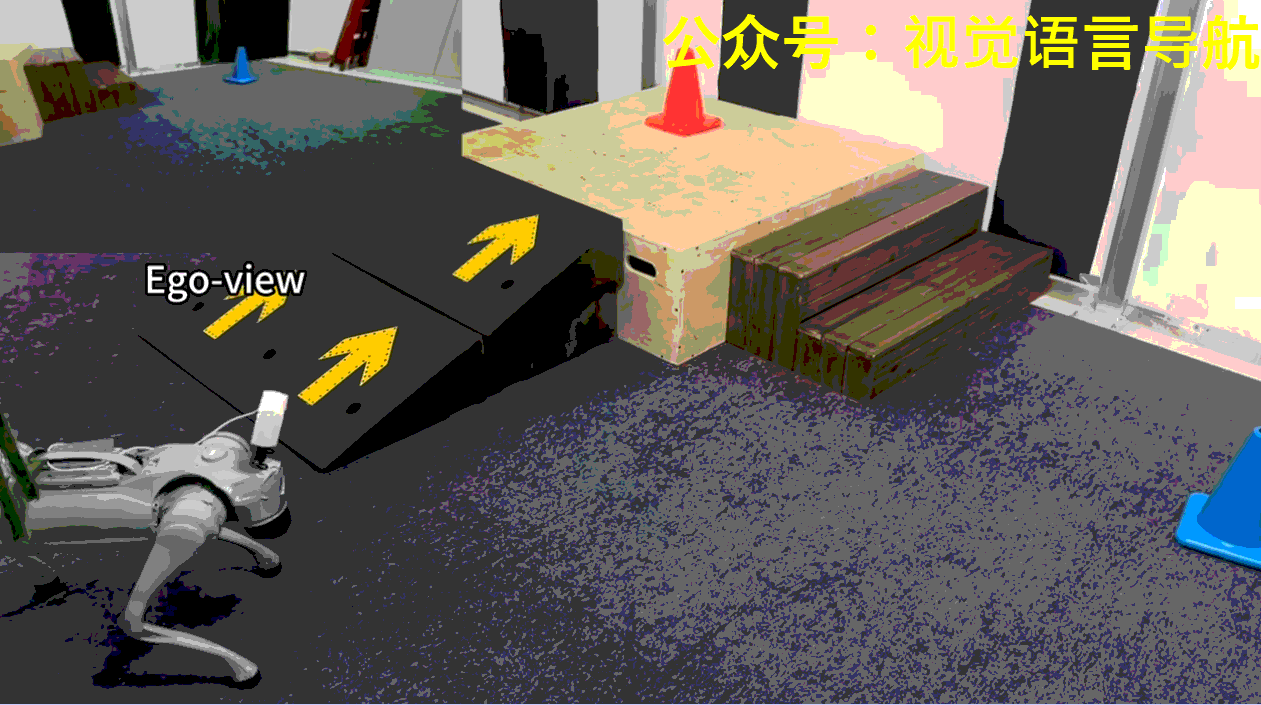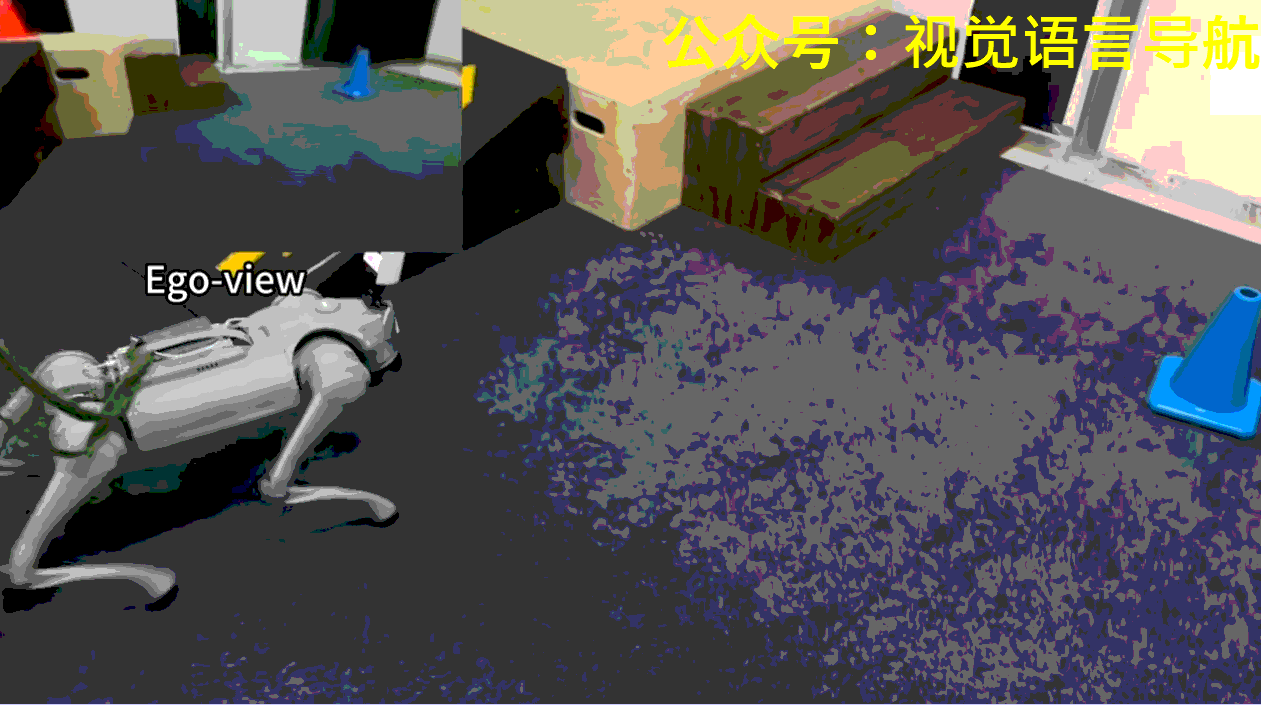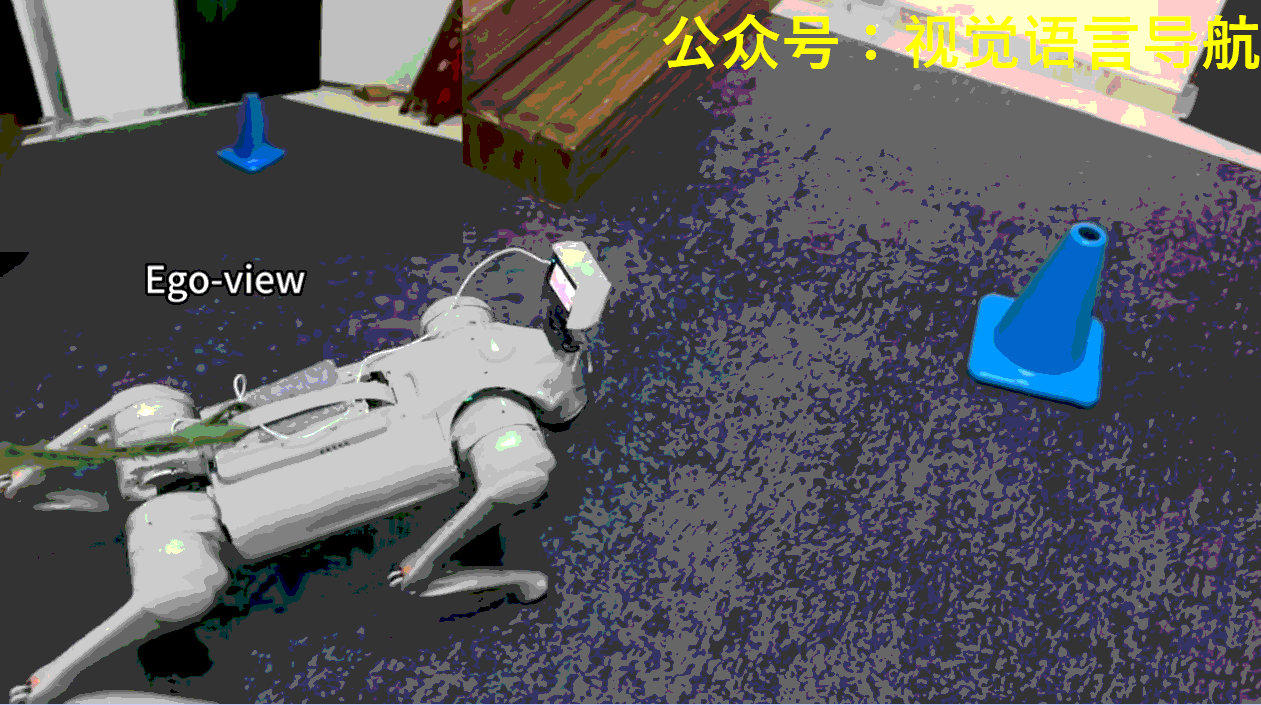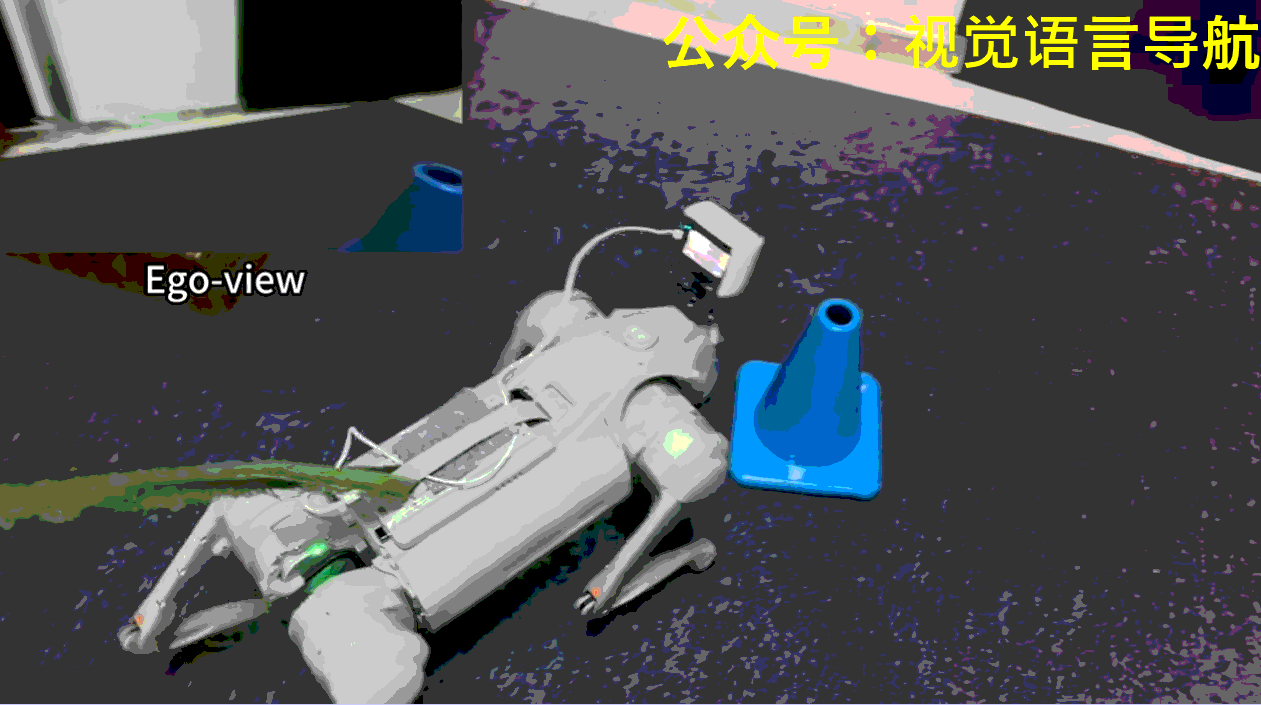
-
机器人导航和运动的重要性:机器人在物理世界中探索、感知和交互对于家庭服务和工业自动化等应用至关重要。
-
模拟训练的优势和挑战:模拟训练允许机器人在安全的环境中体验多样化的环境条件和失败案例,但将模拟中学习到的策略迁移到现实世界中仍然是一个挑战,因为模拟器通常无法复制视觉真实感和复杂的现实世界几何形状。
-
现有方法的局限性:以往的研究尝试通过跨域深度图像训练代理,但这些方法主要局限于低级运动任务,因为标准模拟器难以复制现实世界的视觉保真度和复杂几何形状。

任务定义
-
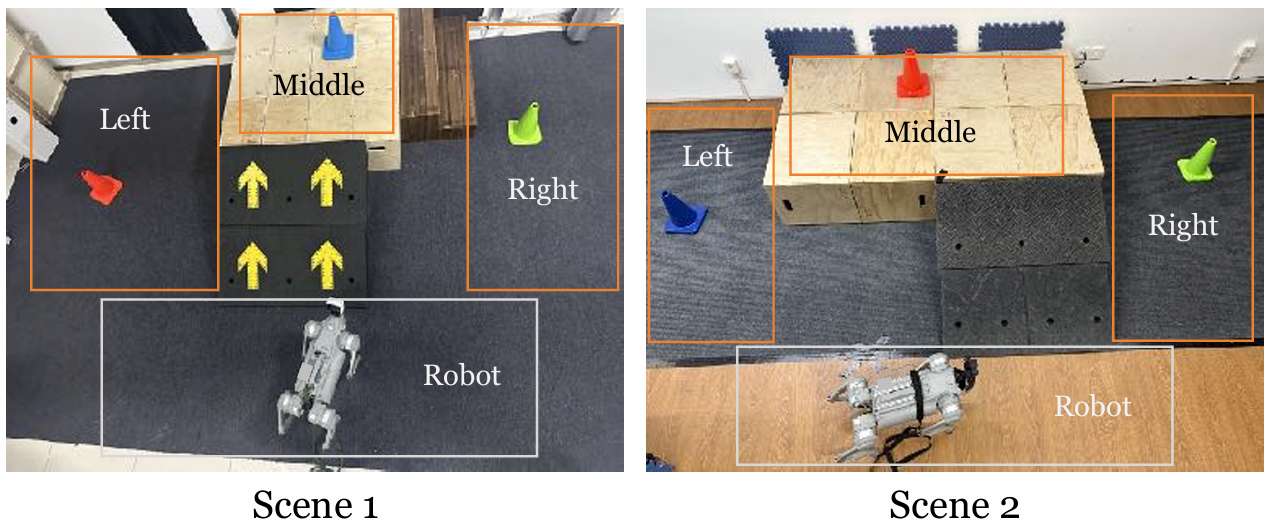
任务描述 :
-
机器人需要在场景中找到并到达指定颜色的目标锥体。每个场景中央都有一个由高台和连接地面与平台的斜坡或楼梯组成的地形。在每次试验开始时,机器人的初始位置和朝向是随机的,目标锥体则放置在左、中、右三个指定区域中的一个,位置也是随机的。
-
机器人可能一开始并不能看到目标锥体,因此需要探索环境以找到并定位正确的锥体。此外,如果目标锥体放置在高台上,机器人还需要导航至斜坡以到达平台。
-
-
任务难度 :
-
任务的难度在于机器人需要在复杂的环境中进行导航和运动控制,同时还需要识别和定位目标锥体。
-
机器人需要具备高级别的理解能力,以识别目标锥体的颜色和位置,还需要具备低级别的运动控制能力,以在复杂的地形上进行导航和运动。
-
VR-Robo框架
-
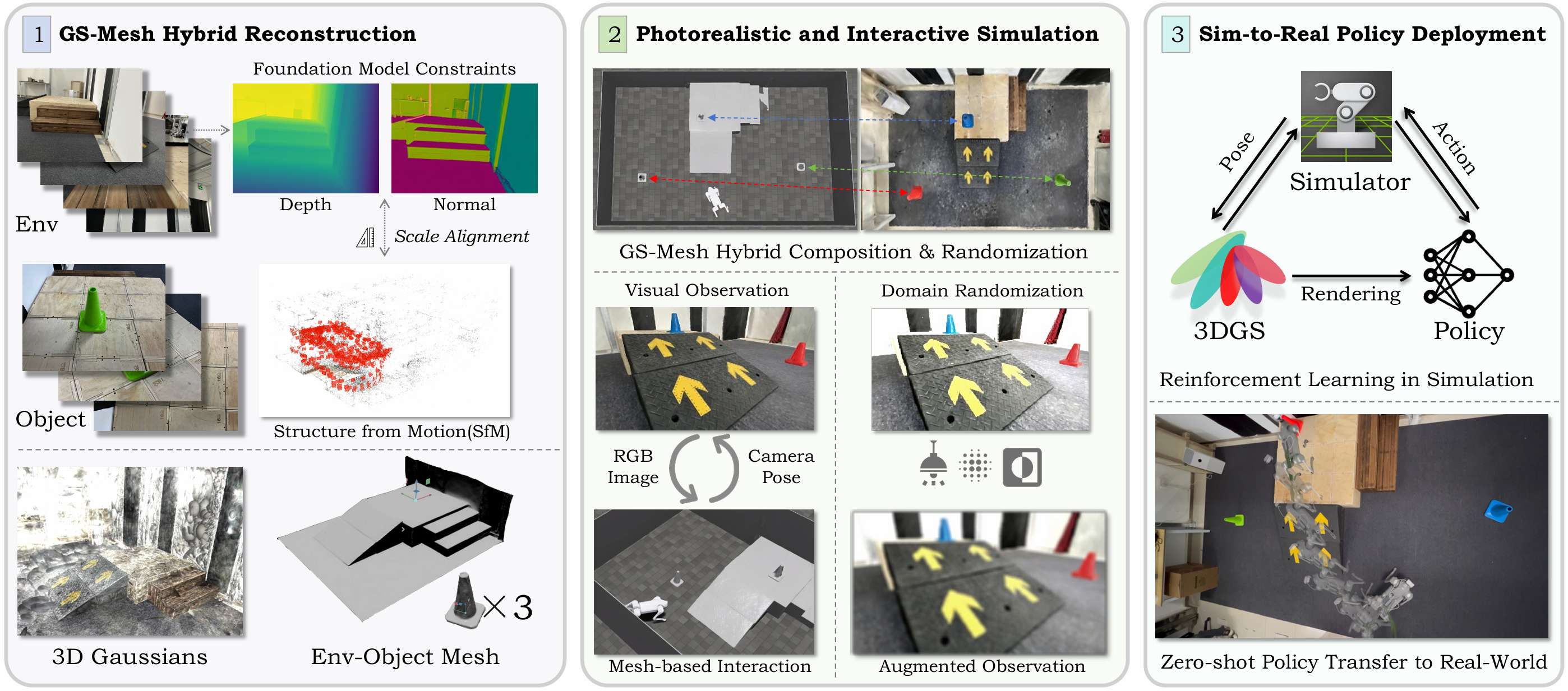
本节介绍了VR-Robo框架,这是一个从现实到模拟再到现实的系统,用于视觉导航和运动控制。
-
该框架通过从现实世界中的多视图图像重建出逼真且可物理交互的"数字孪生"模拟环境,支持以自我为中心的视觉感知和基于网格的物理交互。
几何一致性重建
-
3D Gaussian Splatting (3DGS) 介绍:3DGS通过将场景表示为一组高斯原语来实现。在优化过程中,高斯原语的协方差矩阵通过缩放矩阵和旋转矩阵进行参数化。像素的颜色值通过体积alpha混合过程渲染得到,其中alpha值表示高斯原语在空间中的透明度。
-
几何建模:通过将3D高斯椭球体展平为2D平面,增强场景的几何建模。通过最小化其最短轴的尺度来实现这一点。利用平面表示渲染平面到相机的距离图和法线图,然后通过与相应平面相交的射线将它们转换为无偏深度图。
-
几何先验约束:在纹理较少的区域(如地面和墙壁),光度损失往往不足。因此,使用现成的单目深度估计器提供密集的深度先验,并通过与稀疏结构运动(SfM)点的比较来解决估计深度和实际场景几何之间的固有尺度模糊问题。同样,采用现成的单目法线估计器为渲染的法线图提供密集的法线正则化,以实现准确的几何建模。
-
多视图一致性约束:应用基于补丁的归一化交叉相关(NCC)损失,以强制执行多视图光度一致性。这通过比较两个灰度渲染图像之间的相似性来实现,从而确保从不同视角观察到的场景具有一致性。
构建逼真且可交互的模拟
- GS-mesh混合表示:将高斯表示与网格表示相结合,以实现逼真的视觉观察和物理交互。高斯表示从机器人的自我中心视角生成逼真的视觉观察,而网格表示则便于物理交互和精确的碰撞检测。通过校准机器人相机的焦距和畸变参数,以及从Isaac Sim中获取自我视角位置和基于四元数的方向,实现Sim和Real之间的内在参数对齐。
-
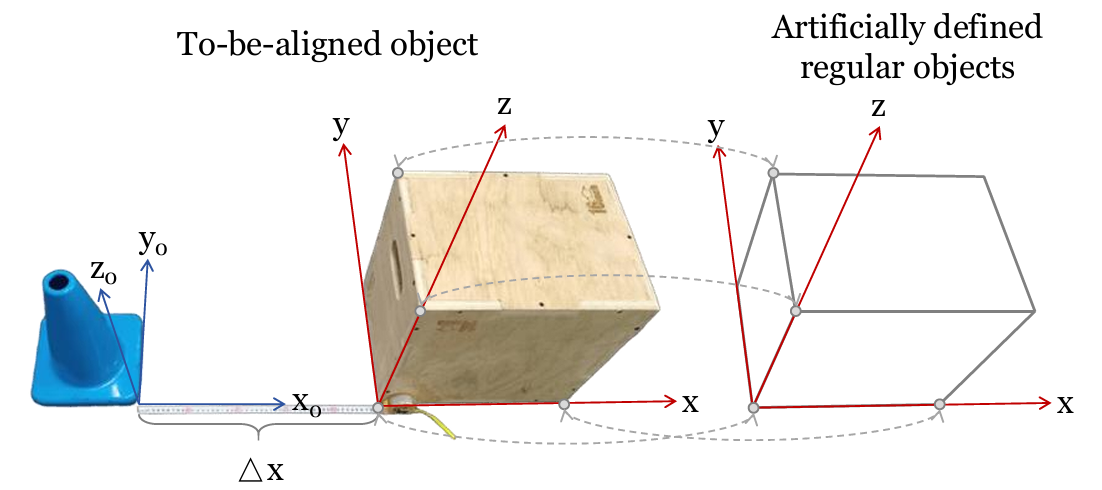
坐标对齐:通过手动匹配四个非共面点,计算齐次变换矩阵,将COLMAP坐标系统与Isaac Sim环境对齐。这种方法允许将从COLMAP重建的场景与Isaac Sim中的模拟环境精确对齐,从而确保机器人在模拟中的行为与现实世界中的行为一致。
-
高斯属性调整:对齐后的高斯点的均值、缩放和旋转进行调整,以适应新的坐标系统。这包括对高斯点的均值进行平移和旋转,以及对缩放矩阵和旋转矩阵进行相应的调整。此外,由于高斯点的球谐系数存储在世界空间中,当高斯点旋转时,需要通过Wigner D矩阵来旋转这些系数,以确保在不同视角下颜色的正确表示。
-
遮挡感知组合和随机化:使用交互式网格编辑器获取对象的3D边界框及其对应的变换矩阵。通过合并对象的高斯表示和网格表示,实现遮挡感知的场景组合。这种组合方式可以确保在模拟环境中正确地表示对象的可见性,从而提高机器人对环境的理解和交互能力。
在重建模拟环境中进行强化学习
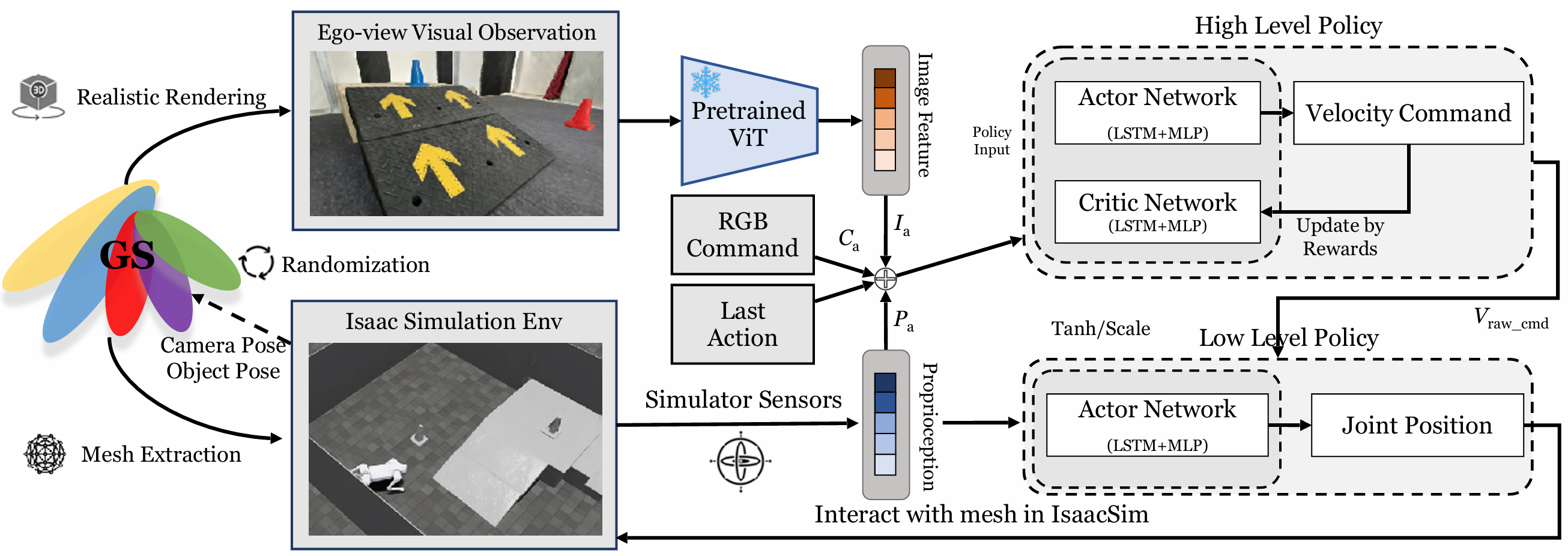
-
两级异步控制策略:由于真实机器人上的计算资源有限,采用了两级异步控制策略。高级策略以5Hz运行,低级策略以50Hz运行。高级策略通过速度命令与低级策略通信。
-
低级策略:低级策略接收速度命令和机器人本体感知作为输入,并输出期望的关节位置。该策略使四足机器人能够攀登高达15厘米的斜坡和楼梯。然而,该策略不允许机器人直接攀登超过30厘米的地形。相反,该策略教导机器人识别和利用斜坡或楼梯到达高平台,这在现实世界场景中非常有用。
-
高级策略:冻结训练好的低级策略,独立训练高级策略。高级策略的输入包括RGB图像特征、RGB命令、上一个动作和本体感知。输出是原始速度命令,该命令通过tanh层和速度范围缩放以确保安全。高级策略的训练使用强化学习(PPO)在GS-mesh混合模拟环境中进行。
-
奖励设计:总奖励包括任务奖励和正则化奖励。任务奖励包括到达目标、目标距离变化、目标垂直距离变化和目标航向。正则化奖励包括在目标处停止、跟踪线速度、跟踪角速度和动作L2范数。这些奖励设计旨在鼓励机器人有效地到达目标,并确保其行为的稳定性和效率。
-
训练过程:在每个训练周期开始时,随机采样机器人和锥体的位置和朝向。机器人从Isaac Sim中获取相机姿态和锥体姿态,并发送给对齐和可编辑的3D高斯表示以渲染逼真的图像。然后,策略根据该图像输出动作,该动作在Isaac Sim中应用以与网格交互。
实验
实验设置
-
现实到模拟重建 :
- 论文重建了6个不同的室内房间环境,每个环境都有特定的地形,并通过放置三个不同颜色(红、绿、蓝)的锥体来随机化环境。使用iPad或iPhone拍摄照片,这些设备易于获取。
-
模拟中的运动训练 :
-
在Isaac Sim中使用单个NVIDIA 4090D GPU进行策略训练。低级策略训练了80,000次迭代,使用4,096个四足机器人代理进行并行训练;高级策略训练了8,000次迭代,使用64个四足机器人代理。
-
整个训练过程大约需要三天时间。对于视觉编码,使用了"vit tiny patch16 224"模型,去掉了其最终分类头。Isaac Sim模拟器和基于3DGS光栅化的渲染器通过TCP网络通信。
-
-
从模拟到现实部署 :
-
在Unitree Go2四足机器人上部署策略,该机器人配备了NVIDIA Jetson Orin Nano(40 TOPS)作为机载计算机。
-
使用ROS2进行高级策略、低级策略和机器人之间的通信。两种策略都在机载运行。机器人从低级策略接收期望的关节位置,用于PD控制。
-
使用Insta360 Ace相机捕获RGB图像,分辨率为320×180。校准后,相机的水平视场(FOVX)为1.5701弧度,垂直视场(FOVY)为1.0260弧度。
-
模拟实验
比较实验
-
模仿学习:通过遥操作收集60个不同的真实世界轨迹,并通过监督学习使用回归优化训练策略。
-
随机背景:重新实现了LucidSim的方法,使用来自ImageNet的随机图像作为背景,同时保持目标对象不变。
消融实验
-
纹理网格:使用SuGaR重建纹理网格,并在Isaac Sim中直接支持网格渲染作为视觉观察。
-
CNN编码器:将ViT替换为CNN编码器,并移除了最后一层分类层。
实验结果
- 评估指标 :
-
在"红色锥体到达"任务中,通过成功率达到(SR)和平均到达时间(ART)来衡量性能。如果机器人在15秒内到达距离红色锥体0.25米以内的位置,则认为该事件成功。
-
对于成功的事件,记录到达锥体所需的时间;否则,分配最大时间15秒。然后计算所有试验的平均到达时间。
-
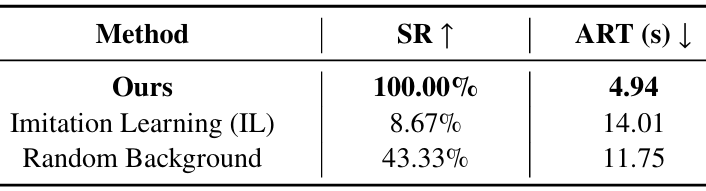
- 结果对比 :
-
该方法在所有评估指标上均优于其他方法。模仿学习(IL)基线由于数据样本不足和缺乏策略探索而表现不佳。CNN编码器难以从图像中提取精确的特征。仅从RGB图像进行重建,纹理网格在纹理较少的区域(如地面和墙壁)会出现明显的纹理膨胀。
-
这些伪影会降低渲染质量,甚至可能阻碍机器人的运动。相比之下,该方法裁剪并仅使用中心地形的网格,并从GS渲染观察结果,有效地避免了这些问题。随机背景设置丢失了原始场景的特定特征。这些特定于场景的特征对于机器人有效探索环境至关重要。
-
现实世界实验
定性实验
在不同的条件下进行定性实验,包括6种不同的场景、不同的目标锥体颜色、光照条件的变化、随机干扰、背景变化以及在不同的机器人上进行训练。补充材料中提供了详细的演示。这些实验突出了该方法的鲁棒性,展示了其适应各种环境和条件的能力。
定量实验
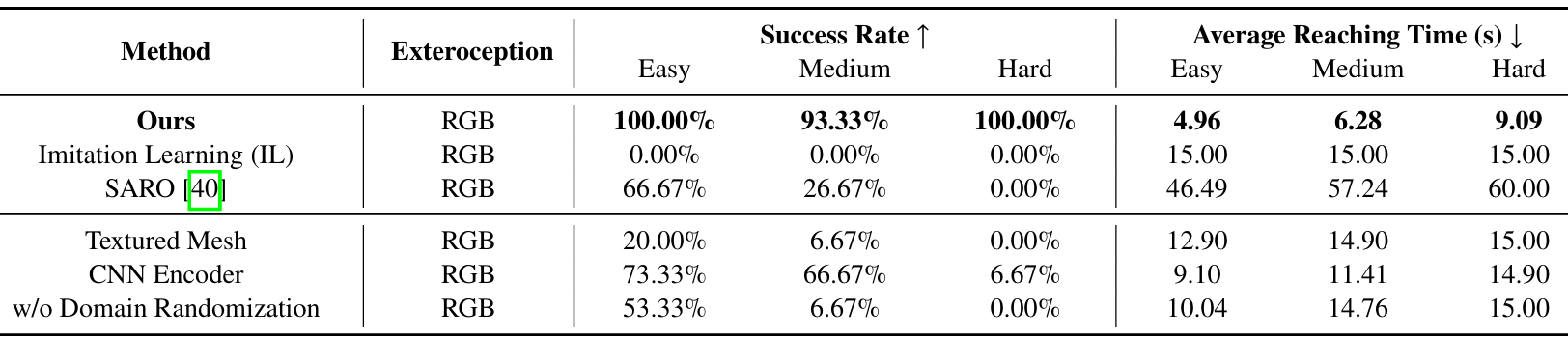
- 实验设置 :除了上述方法外,还进行了两项专门针对现实世界环境设计的基线方法的实验,这些方法不能直接与模拟环境中的实验进行比较:
-
SARO:SARO使机器人能够利用视觉语言模型(VLM)跨越三维地形进行导航。
-
无领域随机化:排除了第IV-C节中描述的领域随机化。
-
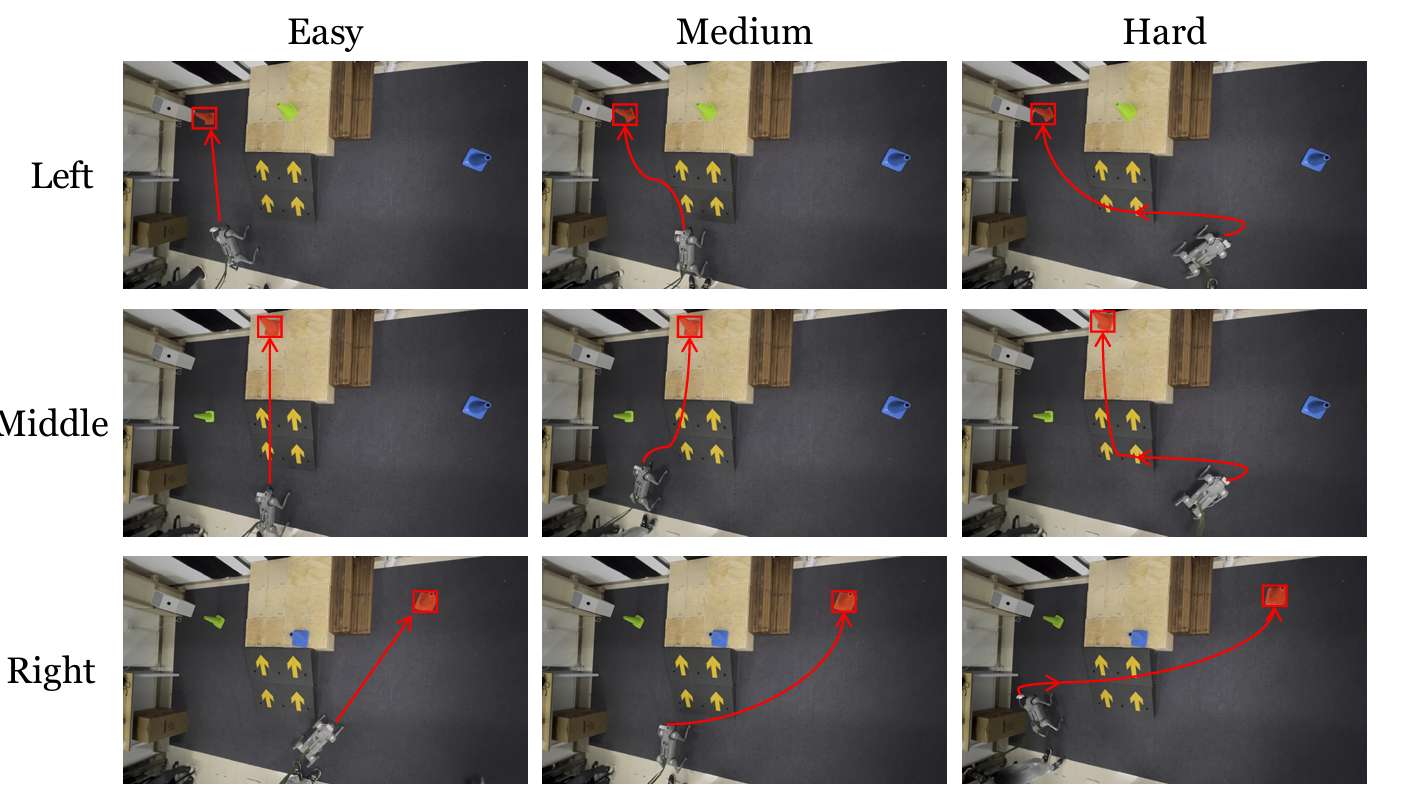
- 任务难度分类 :
-
所有现实世界的定量实验均在场景1中的"红色锥体到达"任务设置中进行。根据机器人的起始位置,将任务分为三个难度级别:简单、中等和困难。
-
对于简单任务,目标锥体直接可见;对于中等任务,机器人需要转动一定角度才能看到目标锥体;对于困难任务,机器人从锥体很远的地方开始,并且几乎背对目标锥体。
-
随机选择3组锥体位置,每组包含一个简单任务、一个中等任务和一个困难任务。对于每个任务,重复实验5次。然后计算成功率(SR)和平均到达时间(ART)。
-
对于SARO,由于视觉语言模型(VLM)所需的长推理时间,最大时间延长至60秒。在真实机器人实验中,如果机器人接触到目标锥体,则认为任务成功。
-

- 实验结果 :
-
该方法在所有难度级别上均实现了最高的成功率,并且始终记录了最短的平均到达时间,证明了其效率和鲁棒性。由于现实世界设置中的固有随机性,在中等任务中存在一个失败案例,尽管在困难任务中所有试验都成功了。
-
在其他方法中,SARO在简单任务上取得了中等的成功率(66.67%),但在中等和困难任务上表现不佳。这种表现不佳主要是由于缺乏历史上下文和在复杂场景中有限的探索能力。如果机器人最初看不到目标,则不太可能成功。
-
结论与未来工作
-
结论 :
-
VR-Robo框架能够在逼真且可交互的模拟环境中训练视觉运动策略,并成功地将这些策略零样本部署到多样化的真实世界场景中。
-
大量的实验结果表明,该框架的智能体能够成功学习到鲁棒且有效的策略,用于应对具有挑战性的高级任务,并且可以零样本部署到各种现实世界场景。
-
-
未来工作 :
- 扩展框架以适应更大规模和更复杂的环境,并将生成模型纳入场景重建中,以实现更通用的策略学习。
