undo log和redo log
先引入两个概念:
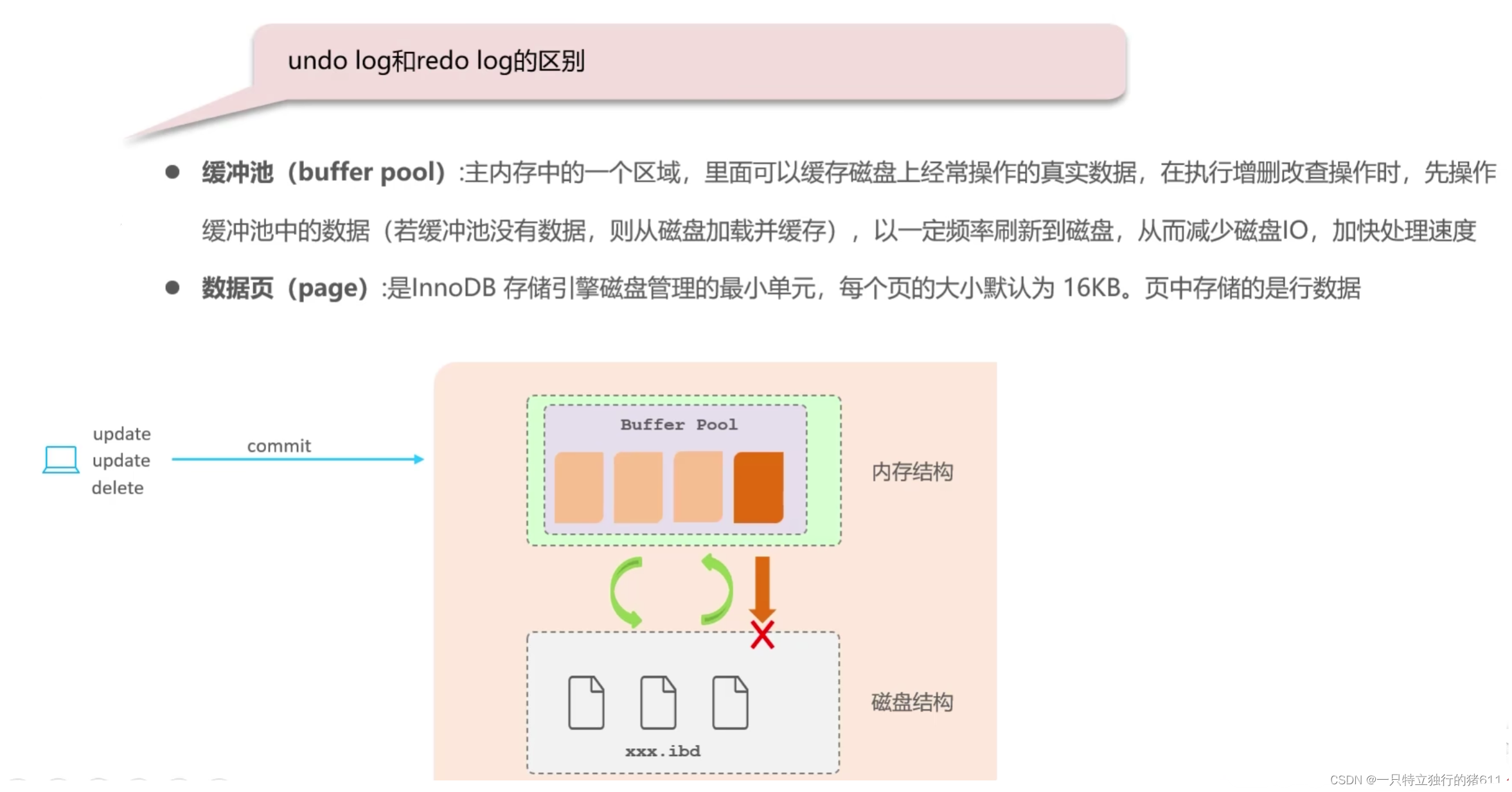
当我们做了一些操作 (update/delete/insert),提交事务后要操作MySql中的数据。
为了能够提升性能,引入了两块区域:内存结构 和磁盘结构。
磁盘结构:
主要存储的就是数据页,每个数据页存储的就是表中一行一行的数据。(一个表的数据,可能由多个数据页存储)。
但当我们做一些增删改的操作时,不会直接操作磁盘。而是先去操作内存。
内存结构:
当操作来了以后,先来操作缓冲池。从内存中的缓冲池里面先找,有没有我要操作的数据。如果没有,就会把磁盘中的数据(某一个数据页的数据)加载到缓冲池中。这样直接操作内存,性能会更高!操作完成之后,缓冲池中数据会同步给磁盘。这样就减少磁盘的IO,加快了处理速度!
这就引出了问题:
现在内存中的数据页被操作完了,但还没同步到磁盘中 (此时这个数据页称为脏页),这个时候服务器宕机了,同步失败了。内存中的数据可能就消失了,数据丢失了。这就违背了事务持久化的特性。
解决方案:redo log (解决事务持久性)

加入Redolog buffer和Redolog file后,数据操作也会发生一点变化。
当有增删改操作之后,现在buffer pool已经发生了变化。Redolog buffer就会记录对应数据页发生的变化,一旦Redolog buffer发生变化 (说明有新的数据页变化)。就会同步给磁盘中的Redolog file中。现在一旦buffer pool对脏页数据同步失败了,就可以从Redolog file恢复数据!
注意:你可能会有疑问,这样做岂不是更麻烦了?不用这个Redolog行不行呢?比如说当buffer pool中的数据页发生变化直接进行同步不好吗?
答:这样做不好,会有严重的性能问题。当我们操作增删改的时候,会有大量的update等语句,如果我们同步刷新,对磁盘IO次数太多了,每执行一条sql可能就要进行一次连接数据库。而如果使用redolog,它进行数据同步时,都是顺序的磁盘IO (可以理解为进行了归纳,连接一次数据库会进行多条sql语句)。这样性能就可以大大提升了!
注意:
等到脏页刷新完成后,可以认为redo log不需要了,进行定期清理,等下一个事务需要的时候,又往里面填写内容,文件不会删除,而是重复利用。两个redo log文件循环写的。
undo log:回滚日志 (解决事务一致性和原子性)

二者区别:
