文章目录
- 0写在前面
- 1优化器
- 2训练类的构建
-
- 2.1训练类的初始化
- 2.2训练类的拟合模块
-
- 2.2.1去重操作remove_duplicate
- 2.2.2反向传播过程
-
- [2.2.2.1 SoftmaxWithLoss层的反向传播](#2.2.2.1 SoftmaxWithLoss层的反向传播)
- 2.2.2.2其它层的反向传播
- 2.3训练类的损失可视化模块
- 3训练结果输出
0写在前面
- 之前的笔记中,我们已经基于数据构建了语料库、单词与ID之间的映射;并基于语料库(就一个句子)构建了CBOW模型学习所需要的数据,即上下文及其对应的目标词;并将其转换为独热编码的形式;
- 接着,我们也构建了简单CBOW模型的网络结构;并根据创建的CBOW模型类创建了模型实例;
- 接下来我们来看让模型进行学习的代码实现
1优化器
-
本书中提供了多个不同优化器的简单实现;关于优化器的细节这里就不说了;网上也有很多博客;可自行学习;
-
优化器的代码如下;根据代码可以知道优化器的作用为:根据给定的学习率、计算的梯度、参数更新公式对参数进行更新;这里的Adam优化器中还在每一个时间步长先对学习率进行了调整。
pythondef __init__(self, lr=0.001, beta1=0.9, beta2=0.999): self.lr = lr self.beta1 = beta1 self.beta2 = beta2 self.iter = 0 self.m = None self.v = None def update(self, params, grads): if self.m is None: self.m, self.v = [], [] for param in params: self.m.append(np.zeros_like(param)) self.v.append(np.zeros_like(param)) self.iter += 1 # 调整学习率 lr_t = self.lr * np.sqrt(1.0 - self.beta2**self.iter) / (1.0 - self.beta1**self.iter) for i in range(len(params)): self.m[i] += (1 - self.beta1) * (grads[i] - self.m[i]) self.v[i] += (1 - self.beta2) * (grads[i]**2 - self.v[i]) # 用调整后的学习率更新每个参数 params[i] -= lr_t * self.m[i] / (np.sqrt(self.v[i]) + 1e-7) -
有了优化器,就可以构建一个优化器的实例:
optimizer = Adam(); -
然后我们就可以将之前创建的CBOW模型实例
CBOW_model和优化器实例optimizer传入到训练类Trainer中,进行学习;
2训练类的构建
包括模型训练拟合、损失可视化模块。
2.1训练类的初始化
-
初始化函数如下所示:
pythonclass Trainer: def __init__(self, model, optimizer): self.model = model # CBOW模型实例对象 self.optimizer = optimizer # 优化器实例对象 self.loss_list = [] # 存放训练过程中的损失 self.eval_interval = None # 评价间隔;即每隔多少个epoch计算一次训练的平均损失 self.current_epoch = 0 # 当前是第几个epoch
2.2训练类的拟合模块
-
需要传入的参数有:
x:输入数据;即上下文单词,维度为[6,2,7];t:真实标签;即目标词向量;维度为[6,7];max_epoch: 最大迭代轮数batch_size: 批处理大小
-
在开始迭代训练前需要做以下事情:
pythondef fit(self, x, t, max_epoch=10, batch_size=32, max_grad=None, eval_interval=20): ''' :param x:输入数据;即上下文单词,维度为[6,2,7] :param t:真实标签;即目标词向量;维度为[6,7] :param max_epoch: 最大迭代轮数 :param batch_size: 批处理大小 :param max_grad: 最大梯度;用于梯度裁剪 :param eval_interval: 评价间隔;即每隔多少个epoch计算一次训练的平均损失 :return: ''' data_size = len(x) max_iters = data_size // batch_size # 每个epoch训练完所有数据所需要的step self.eval_interval = eval_interval model, optimizer = self.model, self.optimizer total_loss = 0 loss_count = 0- 主要是计算
max_iters;因为每一个epoch所有的训练数据都是要进行训练的; len(x):x是一个维度为[6,2,7]的ndarray数组,使用len方法则返回第一个维度的大小;即数据总量;
- 主要是计算
-
开始训练时每一个
epoch的数据要进行打乱:pythonfor epoch in range(max_epoch): # 每个epoch,打乱数据集的顺序 idx = numpy.random.permutation(numpy.arange(data_size)) # (6,)一维数组 # 基于打乱的顺序重新组织输入和真实标签 x = x[idx] # idx这个一维数组可以起到索引[6,2,7]的x的第一个维度,实现shuffle t = t[idx]
- 通过随机化数据顺序,每次训练时模型接收到的数据分布都略有不同,这有助于模型学习到更加鲁棒的特征,从而在未见过的数据上表现更好
- 在pytorch里面可以直接通过设置
shuffle属性来实现同样的目的;这里因为全部都是手动实现,所以需要自己写一下;
-
然后在当前
epoch中,遍历所有的数据,每次取出一个mini-batch的数据:pythonfor iters in range(max_iters): # 遍历数据集,每次取出一个batch的数据 # [0,batch_size),[batch_size,2*batch_size),[2*batch_size,3*batch_size),... batch_x = x[iters * batch_size:(iters + 1) * batch_size] # [3,2,7] batch_t = t[iters * batch_size:(iters + 1) * batch_size] # [3,7] -
然后调用CBOW模型的
forward方法进行模型的前向计算:- 即依次计算输入层到中间层、合并上下文计算结果作为中间层结果;然后计算输出层、并使用
softmax转换为概率;最后基于交叉熵损失计算损失值并返回; - 这一过程已在1.4自然语言的分布式表示-word2vec实操-CSDN博客中讲述过;
pythonloss = model.forward(batch_x, batch_t) - 即依次计算输入层到中间层、合并上下文计算结果作为中间层结果;然后计算输出层、并使用
-
然后调用
SimpleCBOW类的backward方法,进行梯度的反向传播【稍后讲述过程】pythonmodel.backward() -
反向传播之后,模型的梯度会被保存;此时
model.params,model.grads的结构如下所示:- 都是列表;里面分别是两个输入层、一个输出层的参数和梯度;
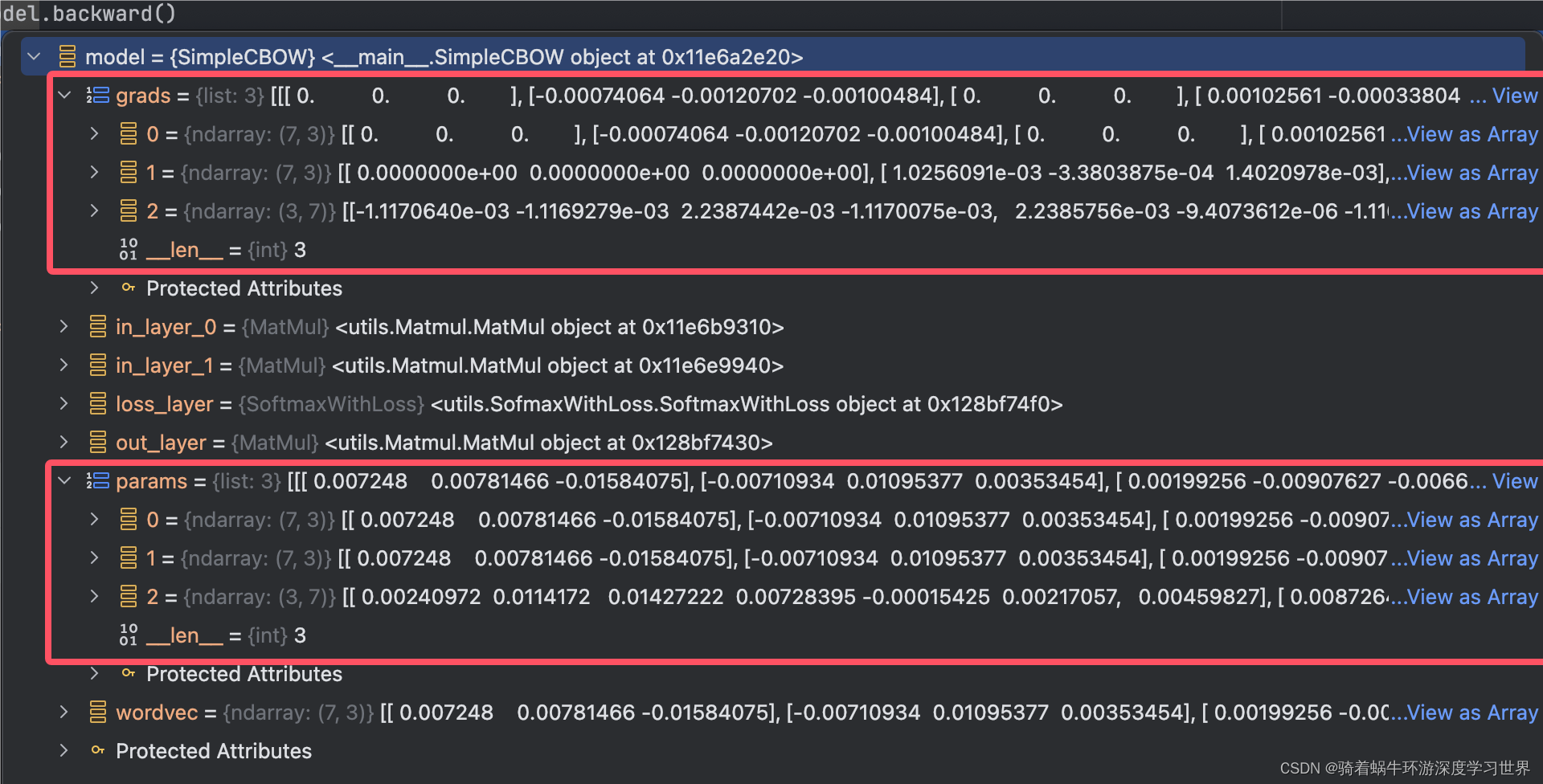
-
【重点】前面说本书中窗口大小为
1时输入有两个向量,因此需要使用两个输入层;而本书采用的方式为构建了两个输入层,这两个输入层共享权重;而共享权重存在一些问题;这一步的去重操作就是为了缓解这个问题;【稍后详解remove_duplicate】pythonparams, grads = remove_duplicate(model.params, model.grads)-
去重后参数和梯度就只剩俩:输入层和输出层:
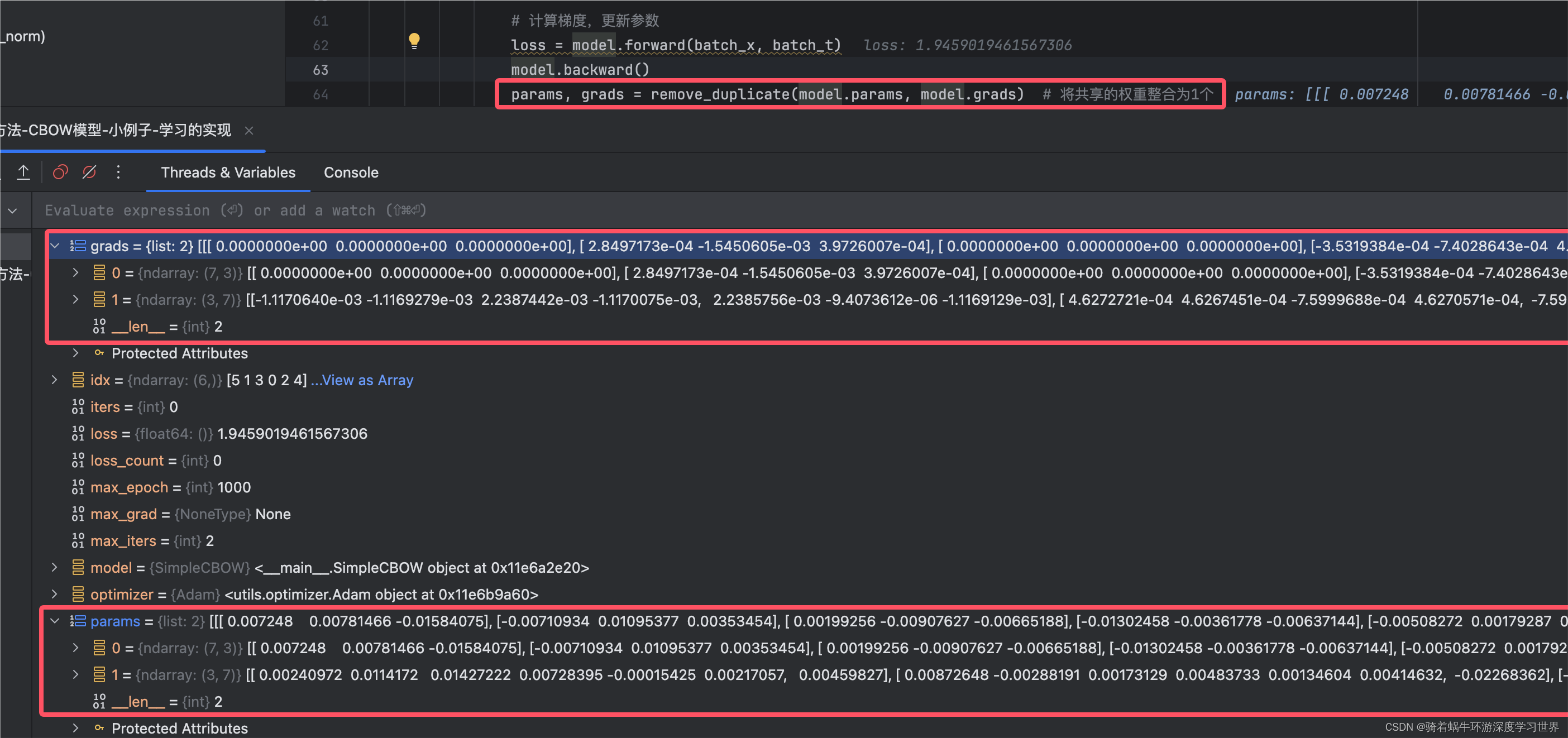
-
-
梯度裁剪:
- 这里默认不进行梯度裁剪;
- 梯度裁剪目的:梯度裁剪是一种在训练神经网络时常用的技术,主要用于防止梯度爆炸问题。梯度爆炸是指在训练过程中,梯度的值变得非常大,以至于更新后的权重会使模型的学习过程变得不稳定;
-
然后调用上述
Adam优化器的update方法对参数进行更新; -
最后就是记录损失;并根据设置的
eval_interval输出模型训练信息:- 主要是输出一下
eval_interval个mini-batch的平均损失;并将平均损失存到self.loss_list中 - 但是目前数据量只有
6条;因此这里暂时默认不执行;
pythondef fit(self, x, t, max_epoch=10, batch_size=32, max_grad=None, eval_interval=20): for epoch in range(max_epoch): for iters in range(max_iters): if (eval_interval is not None) and (iters % eval_interval) == 0: avg_loss = total_loss / loss_count elapsed_time = time.time() - start_time print('| epoch %d | iter %d / %d | time %d[s] | loss %.2f' % (self.current_epoch + 1, iters + 1, max_iters, elapsed_time, avg_loss)) self.loss_list.append(float(avg_loss)) total_loss, loss_count = 0, 0 - 主要是输出一下
-
通过不断地迭代,完成模型的学习;
- 这里比较简单,就是完成设置的迭代轮数之后就返回了;并没有去检查是否需要提前停止之类的;
-
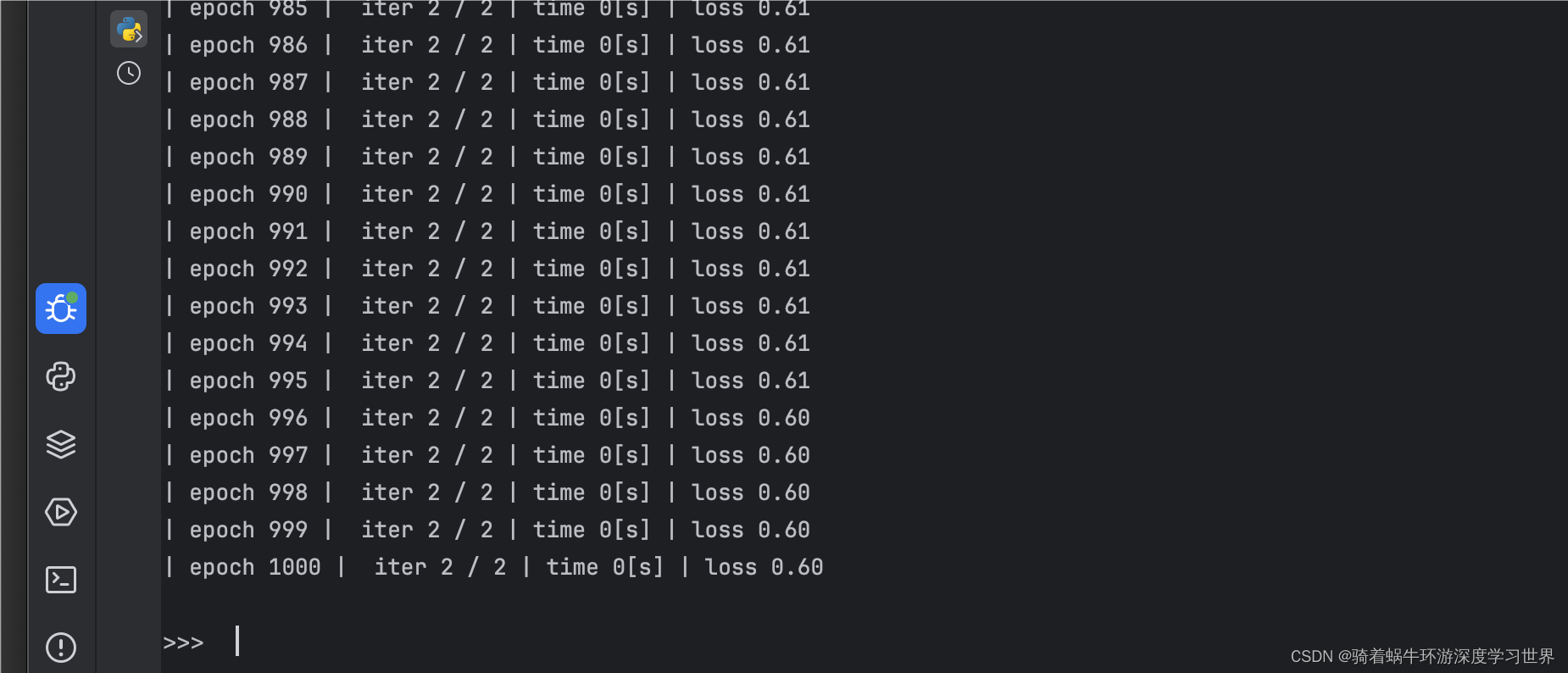
下图为训练过程中打印的损失信息:
2.2.1去重操作remove_duplicate
-
去重思路为:遍历参数列表里的每一项,将该项与其他项进行比较;如果相同则删除一个;直到没有重复的参数为止;代码如下:
pythondef remove_duplicate(params, grads): ''' 将参数列表中重复的权重整合为1个, 加上与该权重对应的梯度 ''' params, grads = params[:], grads[:] # copy list while True: find_flg = False L = len(params) # 总参数个数为3 for i in range(0, L - 1): for j in range(i + 1, L): # 在共享权重的情况下就累加这两相同参数的梯度 if params[i] is params[j]: grads[i] += grads[j] # 加上梯度 find_flg = True # 删除掉其中一份重复的参数及其梯度 params.pop(j) grads.pop(j) # 在作为转置矩阵共享权重的情况下(weight tying) elif params[i].ndim == 2 and params[j].ndim == 2 and params[i].T.shape == params[j].shape and np.all(params[i].T == params[j]): grads[i] += grads[j].T find_flg = True params.pop(j) grads.pop(j) if find_flg: break if find_flg: break if not find_flg: break return params, grads -
一些需要解释和注意的地方:
- 存在两种共享权重的情况
- 像本书的例子中这样,输入层有两个,维度相同,共享权重;
- 还存在一种是编码器和解码器共享权重,多出现于自编码器中
- 在自编码器中,编码器负责将输入数据编码到一个较低维度的隐藏表示中,而解码器则将这个隐藏表示解码回原始数据空间。通过共享权重,即让编码器和解码器使用相同(或某些情况下为转置关系)的权重矩阵,可以帮助模型学习到更加有效的数据表示,同时减少模型的参数数量
- 代码中设置了find_flg参数,每当发现一个重复项时就会设置
find_flg = True从而跳出两层循环;因为如果存在相同项,会从参数和梯度列表中弹出其中一个,此时列表的大小已经发生了变化;跳出两层循环可以让循环重新开始,不遗漏任何一个重复项。 - 去重之前,是需要将一个重复项的梯度值累加到保留下来的那个参数项的;这和pytorch里面自动累加梯度是一致的;
- 存在两种共享权重的情况
2.2.2反向传播过程
- 关键要会画计算图;
- 然后掌握计算图中常用节点类型在反向传播时梯度是怎么传递的即可;
-
在训练类中调用反向传播时将进入
SimpleCBOW类的backward方法;代码如下;pythondef backward(self, dout=1): ds = self.loss_layer.backward(dout) da = self.out_layer.backward(ds) da = da * 0.5 self.in_layer_0.backward(da) # 输入层计算完最终梯度之后会将梯度保存在梯度列表里面;因此这里就不需要返回值了 self.in_layer_1.backward(da)
2.2.2.1 SoftmaxWithLoss层的反向传播
先说结论:对于输入
x=[a1,a2,a3],经过SoftmaxWithLoss层的计算;反向传播时传到这里的梯度为:
a 1 a_1 a1节点处的梯度为:
y 1 − t 1 = e x p ( a 1 ) S − t 1 = e x p ( a 1 ) e x p ( a 1 ) + e x p ( a 2 ) + e x p ( a 3 ) − t 1 y_1-t_1=\frac{exp(a_1)}{S}-t_1=\frac{exp(a_1)}{exp(a_1)+exp(a_2)+exp(a_3)}-t_1 y1−t1=Sexp(a1)−t1=exp(a1)+exp(a2)+exp(a3)exp(a1)−t1其中
[t1,t2,t3]是该条数据对应的真实标签;且是独热编码形式; y 1 y_1 y1就是独热编码向量中当前位置经过softmax概率化之后的结果;类似地, a 2 a_2 a2、 a 3 a_3 a3节点处的梯度分别为 y 2 − t 2 y_2-t_2 y2−t2、 y 3 − t 3 y_3-t_3 y3−t3。
下图是
SoftmaxWithLoss层的正向传播和反向传播的计算图:

-
首先调用
loss_layer的backward方法:即SoftmaxWithLoss层的反向传播;该层依次是softmax层、交叉熵损失计算层;关于这里的反向传播过程详见《深度学习入门-基于Python的理论与实现》一书的附录A,其中有详细的使用计算图进行梯度计算的过程(计算过程详见Softmax-with-Loss层的计算图);这里主要补充以下几点:-
使用计算图进行反向传播时,梯度传播法则为:
输入侧梯度=输出侧梯度*局部梯度;【即链式求导法则】 -
在复杂计算图中,++计算当前结点输入侧的梯度时,就是把输入侧看做单个x,而不是x的函数++ ;例如下图: y 1 y_1 y1是再往前的参数计算过来的,即 y 1 y_1 y1是参数的函数,而不是单纯的一个变量;但是在这里反向求梯度时就是把 y 1 y_1 y1看成与其它参数无关的变量;所以这个结点就相当于是 z = x + y + z z=x+y+z z=x+y+z;对每个变量求偏导结果都是
1,因此就用输出侧的梯度-1乘上每个分支的局部梯度即可;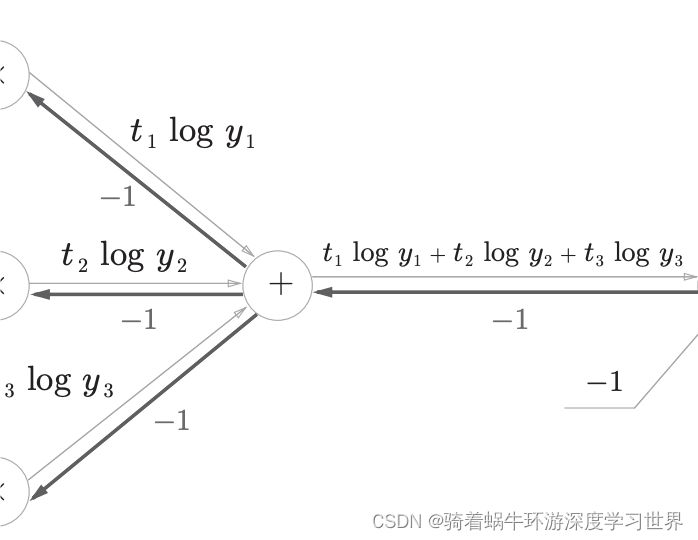
-
计算图中常见的节点类型:
-
加法节点:正向传播时各路分支结果正常相加得到输出;反向传播时输出层的梯度建立多个副本,分别进入输入侧各路分支;当然,这是针对局部梯度为
1的情形;实际上是各路分支的梯度=输出侧梯度*当前位置的局部梯度;下图是一个例子( z = x + y z=x+y z=x+y, z z z对 x x x和 y y y的偏导数都是常数1);这里是两路分支做加法,也可以多路,即求和;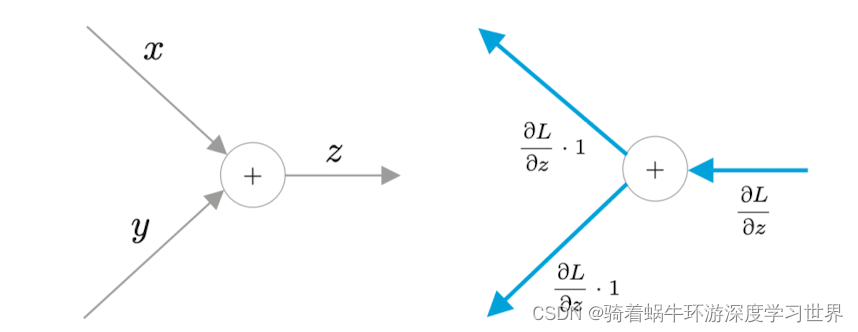
-
乘法节点(主要指 z = x y z=xy z=xy的情形,即都是变量间的乘法,不是向量矩阵的乘法):乘法节点反向传播时,因为 ∂ z ∂ x = y \frac{\partial{z}}{\partial{x}}=y ∂x∂z=y, ∂ z ∂ y = x \frac{\partial{z}}{\partial{y}}=x ∂y∂z=x;所以乘的局部梯度正好是两个分支输入交换之后的结果;
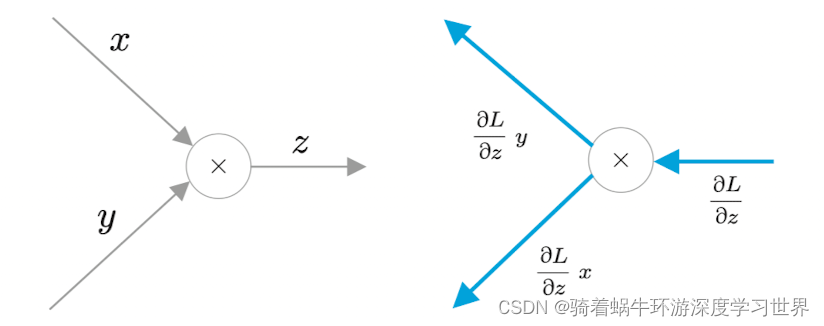
-
分支节点:正向传播时是直接复制到各路分支;反向传播时则是将梯度累加;如下图所示:
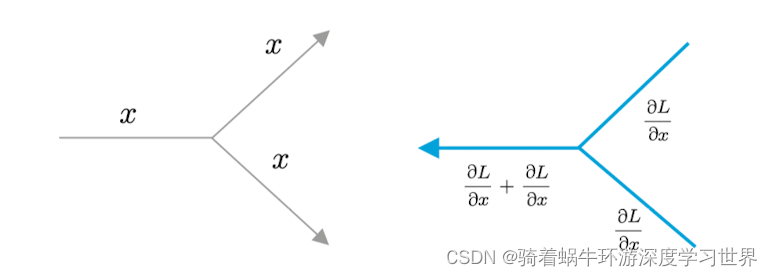
-
-
这里的
SoftmaxWithLoss层的反向传播计算图的一些补充解释:-
反向传播的初始值为常数
1;由此我们可以知道,当我们确定了网络结构、输出层以及损失计算函数之后,反向传播时只需要计算一次计算图中各个节点的导数;之后没读取一次mini-batch的数据,就能获得参数的梯度从而进行参数的更新;而模型输出的损失更像是我们之后用来可视化模型训练效果的数据而已; -
交叉熵损失函数在求导时,默认是以
e为底数的对数; -
softmax层的计算图中的除法节点:该结点可以用 y = 1 x y=\frac{1}{x} y=x1来表示,求导后 ∂ y ∂ x = − 1 x 2 \frac{\partial{y}}{\partial{x}}=-\frac{1}{x^2} ∂x∂y=−x21,结合计算图中的符号,局部梯度为 − 1 S 2 -\frac{1}{S^2} −S21;由于在正向传播时这个除法计算完之后形成了三个分支,因此反向传播时要先累加梯度,再乘上局部梯度;如下图所示: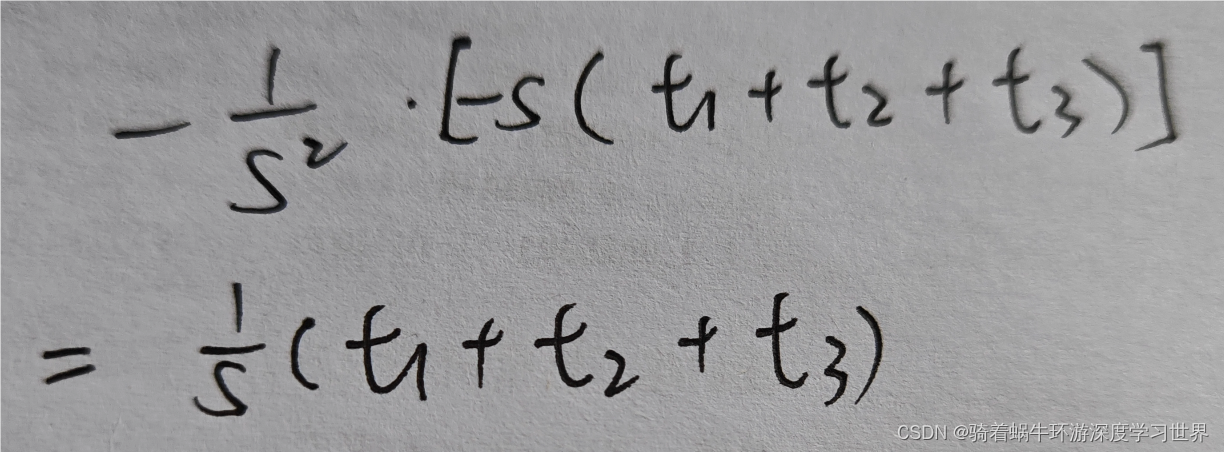
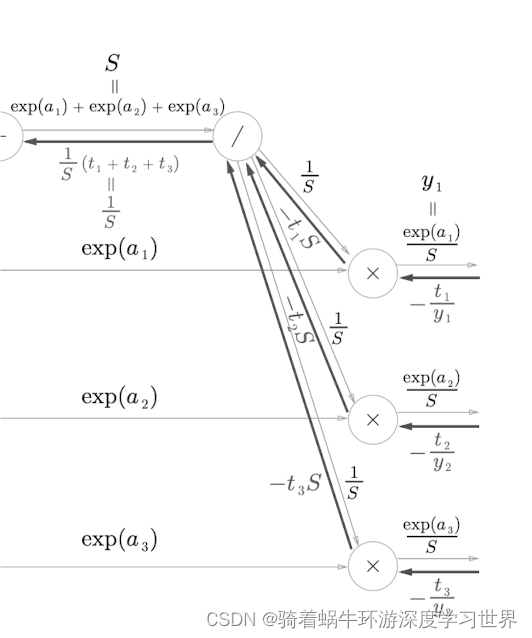
-
softmax层的计算图中的exp节点:注意这里是先计算了指数,再形成两个分支的;因此需要先累加梯度;然后乘上exp节点的局部梯度;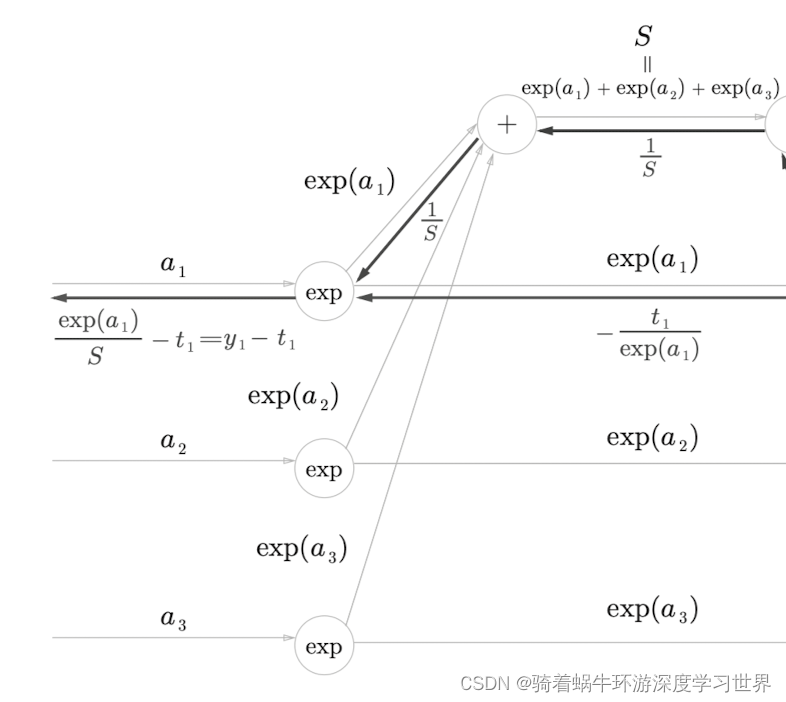
-
-
-
从代码层面来看,计算过程如下所示:
pythonclass SoftmaxWithLoss: def backward(self, dout=1): batch_size = self.t.shape[0] # 6 dx = self.y.copy() # 模型的输出;维度为[6,7] dx[np.arange(batch_size), self.t] -= 1 # dx中每条数据真实标签的那个值要减去1(为什么);维度为[6,7];这里其实就是局部梯度 dx *= dout # SoftmaxWithLoss层输入侧的梯度=输出侧的梯度*局部梯度 dx = dx / batch_size return dx # 维度为[3,7]- 由于上面反向传播推导的结论是:
SoftmaxWithLoss层输入侧的梯度是 y 1 − t 1 y_1-t_1 y1−t1,因此dx首先拷贝自self.y,而self.y= softmax(x)就是概率化的结果; - 然后依然是根据 y 1 − t 1 y_1-t_1 y1−t1(即反向传播的梯度可以简化为模型输出(概率)与真实标签之间的差值 )将
dx中每条数据的真是样本对应的概率减去1;其他概率不用减,因为其他概率在真实标签向量中对应的那个元素值为0,不需要操作; dx *= dout其实不需要,因为反向传播时梯度的初始值为1;写在这里也是进一步说明了一下梯度传播法则为:输入侧梯度=输出侧梯度*局部梯度;【即链式求导法则】- 因为损失是所有样本损失的平均,所以梯度也需要平均,以反映对每个样本的平均影响;所以需要执行
dx = dx / batch_size;
- 由于上面反向传播推导的结论是:
2.2.2.2其它层的反向传播
-
输出层的反向传播:
-
输出层是矩阵乘法,梯度的求导可看这篇博客:【深度学习】7-矩阵乘法运算的反向传播求梯度_矩阵梯度公式-CSDN博客;
-
执行的结果为:
pythonda = self.out_layer.backward(ds) # [3,3],即[mini-batch大小,中间层神经元个数]
-
-
接着是两个输入层相加取平均的操作,可以用上述计算图来表示;
-
取平均的操作结果就是
pythonda = da * 0.5 -
相加的操作结果就是:梯度复制两份,分别传入两个输入层;即执行:
pyself.in_layer_0.backward(da) # 输入层计算完最终梯度之后会将梯度保存在梯度列表里面;因此这里就不需要返回值了 self.in_layer_1.backward(da)
-
-
两个输入层的反向传播同输出层;
-
不过,需要特别指出的是,
MatMul层最后保存梯度时执行的是:pythonself.grads[0][...] = dW # [...]表示所有元素 # 而不是语句: self.grads[0] = dW-
两个语句达到的目的是一样的,都是赋值;
-
但是省略号的方法可以在不改变
self.grads[0]所在的内存地址的前提下完成梯度的更新;这样,在SimpleCBOW类中,只需要在__init__函数中执行一次参数汇总的操作(如下代码所示)即可;因为梯度数值在更新,但是内存地址没变,之后依然可以通过这里汇总的参数变量来访问被更新的梯度数值;pythonclass SimpleCBOW(): def __init__(self, vocab_size, hidden_size): ... for layer in layers: self.params += layer.params self.grads += layer.grads
-
2.3训练类的损失可视化模块
-
代码如下:
pythondef plot(self, ylim=None): x = numpy.arange(len(self.loss_list)) # 作为横轴[1000] if ylim is not None: # 默认不执行 plt.ylim(*ylim) plt.plot(x, self.loss_list, label='train') # loss_list维度为[1000] plt.xlabel('iterations (x' + str(self.eval_interval) + ')') plt.ylabel('loss') plt.show() -
得到下图所示曲线:
- 与书上不一样是因为我设置
eval_interval=2,因为本示例中max_iters=2;

- 与书上不一样是因为我设置
3训练结果输出
-
输入层的权重可以用来表示单词的分布式表示;
-
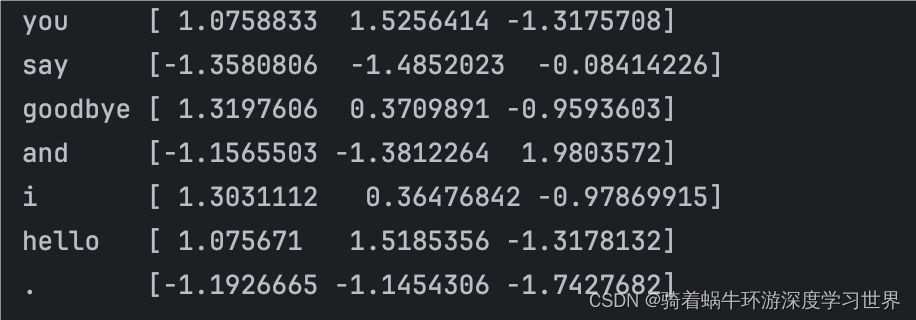
因此通过以下代码打印密集向量表示:
python# 获取训练后的单词密集向量表示 word_vecs=CBOW_model.wordvec max_word_length = max(len(word) for word in id_to_word.values()) for word_id, word in id_to_word.items(): print(f"{word:<{max_word_length}} {word_vecs[word_id]}") -
输出结果如下图所示:
-
总结:
- 目前语料库就一个句子;显然不够;
- 当前这个CBOW模型的实现在处理效率方面存在几个问题;后续学习过程中我们再一起进行修改;