前言:因为我们要学习kafka,那么我们必须先安装了解下Zookeeper;
Zookeeper简介
Zookeeper是一个开源的分布式协调服务,由Apache维护,旨在为分布式系统提供一致性、可靠性和高效的数据管理。 它通过提供一系列简单易用的接口,封装了复杂且易出错的分布式一致性服务,构成了一个高效可靠的原语集。Zookeeper的设计目标包括提供高性能、高可用且具有严格顺序访问控制能力的分布式协调服务。
Zookeeper的核心特性包括:
- 顺序一致性:确保从一个客户端发起的事务请求最终会严格按照其发起顺序被应用到Zookeeper中。
- 原子性:所有事务请求的处理结果在整个集群中所有机器上都是一致的,不存在部分机器应用了该事务而另一部分没有应用的情况。
- 单一视图:所有客户端看到的服务端数据模型都是一致的。
- 可靠性:一旦服务端成功应用了一个事务,则其引起的改变会一直保留,直到被另外一个事务所更改。
- 实时性:一旦一个事务被成功应用后,Zookeeper可以保证客户端立即可以读取到这个事务变更后的最新状态的数据。
Zookeeper通过树形结构来存储数据,称为ZNode的数据节点,类似于常见的文件系统。与常见的文件系统不同,Zookeeper将数据全量存储在内存中,以实现高吞吐并减少访问延迟。Zookeeper还提供了多种类型的ZNode,包括持久化目录节点、持久化顺序编号目录节点、临时目录节点和临时顺序编号目录节点,以满足不同的应用需求。
此外,Zookeeper还支持通知机制,允许客户端注册监听它关心的目录节点。当目录节点发生变化(如数据改变、被删除、子目录节点增加或删除)时,Zookeeper会通知客户端。这种机制使得Zookeeper能够用于实现分布式系统中的多种功能,如命名服务、配置管理、集群管理、分布式锁和队列管理等。
一丶Zookeeper下载
网盘下载:链接:https://pan.baidu.com/s/1zv_s7K7Rav9cZsxgNMmz1w?pwd=DMDM
提取码:DMDM
二丶解压即安装
1.将zookeeper解压到目标目录


2.在上图目录下创建data文件夹
3.进入config目录复制zoo_sample.cfg文件,改名为zoo.cfg

4.修改配置文件 zoo.cfg,注意一定要双反斜杠

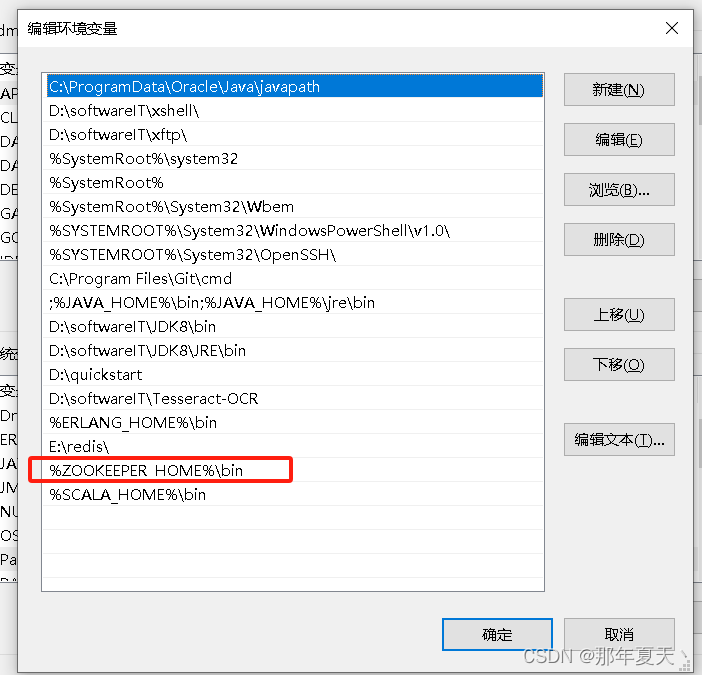
5.配置环境变量

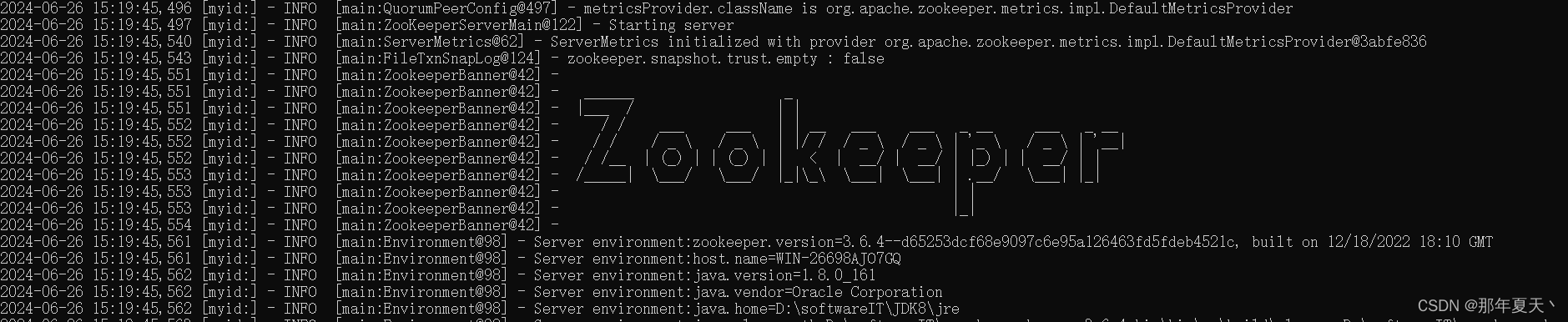
6.启动Zookeeper服务:zkServer
win+R,cmd打开黑窗口,输入zkServer,出现下图就算成功
结尾:Zookeeper的介绍就到这儿了,喜欢的朋友点个赞吧!!!