小罗碎碎念
今日推文主题:人工智能在肿瘤/分子亚型分类中的应用

小罗观点
前两天有一位复旦的师兄私聊问了我一些问题,我看完以后觉得大家可能对于"分类"的概念有点不太熟悉,所以我决定写这篇推文系统的梳理一下"分类"和"回归"。
这俩都是机器学习的基本概念,你们理解了以后,看文献的感觉会大不一样------能看懂作者为什么要这样设计模型了。
知识点补充:分类与回归
首先明确一点,不管是分类,还是回归,其本质是一样的,都是对输入做出预测 ,并且都是监督学习。说白了,就是根据特征,分析输入的内容,判断它的类别,或者预测其值。
二者的本质区别在于输出的类型------回归问题 的输出是连续的数值,而分类问题输出的是有限、离散的类别标签。
-
分类(Classification):
- 任务目标:预测离散的标签值,即确定数据属于预定义类别中的哪一个。
- 应用场景:垃圾邮件识别、疾病诊断、图像识别等。
- 常见算法:逻辑回归、决策树、随机森林、支持向量机(SVM)、神经网络等。
-
回归(Regression):
- 任务目标:预测连续的数值,即估计输入数据与连续输出变量之间的关系。
- 应用场景:房价预测、股票价格分析、温度预测等。
- 常见算法:线性回归、岭回归、LASSO、决策树回归、神经网络等。
知识点补充:分类&回归在医学领域中的应用
分类和回归在医学领域有着广泛的应用,它们帮助提高疾病诊断的准确性、预测疾病发展、个性化治疗计划以及药物发现等。
分类在医学领域的应用:
-
疾病诊断:使用分类算法来识别患者是否患有某种疾病,例如,基于症状、体征和实验室检测结果来诊断糖尿病或癌症。
-
患者分层:根据疾病严重程度或治疗反应将患者分为不同的风险组,以便于个性化治疗。
-
病理图像分析:在病理学中,机器学习分类器可以用于识别和分类不同类型的细胞或组织,例如区分良性和恶性病变。
-
药物反应预测:预测患者对特定药物的反应,帮助医生选择最合适的药物和剂量。
-
疾病预后:评估患者疾病的预后,例如预测心脏病患者的生存率或癌症患者的复发风险。
回归在医学领域的应用:
-
疾病进展预测:使用回归模型预测疾病的发展速度,如预测肺病的恶化速度。
-
药物剂量优化:确定最合适的药物剂量,以实现治疗效果和副作用之间的最佳平衡。
-
健康指标预测:预测患者的健康指标,如血压、血糖水平等。
-
手术结果预测:预测手术成功率或术后并发症的风险。
-
医疗成本分析:估计治疗某种疾病的成本,帮助医院和保险公司进行资源规划和预算管理。
机器学习在医学领域的应用正迅速增长,随着医疗数据的积累和技术的进步,未来的应用将更加广泛和深入。
一、隐藏基因组分类器,量化肝内胆管癌的遗传异质性

一作&通讯
| 角色 | 姓名 | 单位名称(中文) |
|---|---|---|
| 第一作者 | Yi Song | 纪念斯隆凯特琳癌症中心 |
| 第一作者(*) | Thomas Boerner | 纪念斯隆凯特琳癌症中心 |
| 第一作者(*) | Esther Drill | 纪念斯隆凯特琳癌症中心 |
| 通讯作者 | William R. Jarnagin | 纪念斯隆凯特琳癌症中心 |
文献概述
这篇文章是关于一种新方法来量化肝内胆管癌(Intrahepatic Cholangiocarcinoma, IHC)的遗传异质性,这种方法被称为"隐藏基因组分类器"(Hidden-Genome Classifier)。
研究涉及对1370名患者的回顾性研究,包括IHC、肝外胆管癌(Extrahepatic Cholangiocarcinoma, EHC)、胆囊癌(Gallbladder Cancer, GBC)、肝细胞癌(Hepatocellular Carcinoma, HCC)和双表型肿瘤患者。
研究的主要目的是使用监督机器学习算法来量化肿瘤的遗传异质性,并改进肿瘤分类。研究构建了一个基于遗传相似性的隐藏基因组模型,对527个IHC进行了分类,并将其与EHC/GBC或HCC进行了比较。
研究发现:
- 410个IHC(78%)与EHC/GBC有超过50%的遗传同源性;
- 122个(23%)有超过90%的同源性,被称为"胆管类IHC",其特征是KRAS、SMAD4和CDKN2A的变异。
- 117个IHC(22%)与HCC有超过50%的遗传同源性;30个(5.7%)有超过90%的同源性,被称为"HCC类IHC",其特征是TERT的变异。
生存分析表明,胆管类IHC与非胆管类IHC相比,无论是否可切除,总体生存期(OS)都更差。此外,研究还发现,与HCC类IHC相比,胆管类IHC在不可切除疾病中的中位OS为1年,而HCC类IHC为1.8年;在可切除疾病中,胆管类IHC的中位OS为2.4年,而非胆管类IHC为5.1年。
研究的结论是,IHC的遗传学形成了一个谱系,与EHC/GBC遗传学一致的肿瘤OS较差。隐藏基因组分类器在预测OS方面优于组织学亚型,并且独立于FGFR2和IDH1的变异。这些结果可能解释了IHC在治疗响应上的差异,并可能通过在未来的临床试验中帮助分层患者来指导治疗。
文章还讨论了研究的局限性,包括可能的转诊偏差、未区分乙型和丙型肝炎状态以及大多数IHC肿瘤标本来自未接受治疗的患者。尽管如此,这项研究提供了对IHC复杂疾病遗传异质性的深入理解,并可能为未来的研究和临床实践提供信息。
重点关注
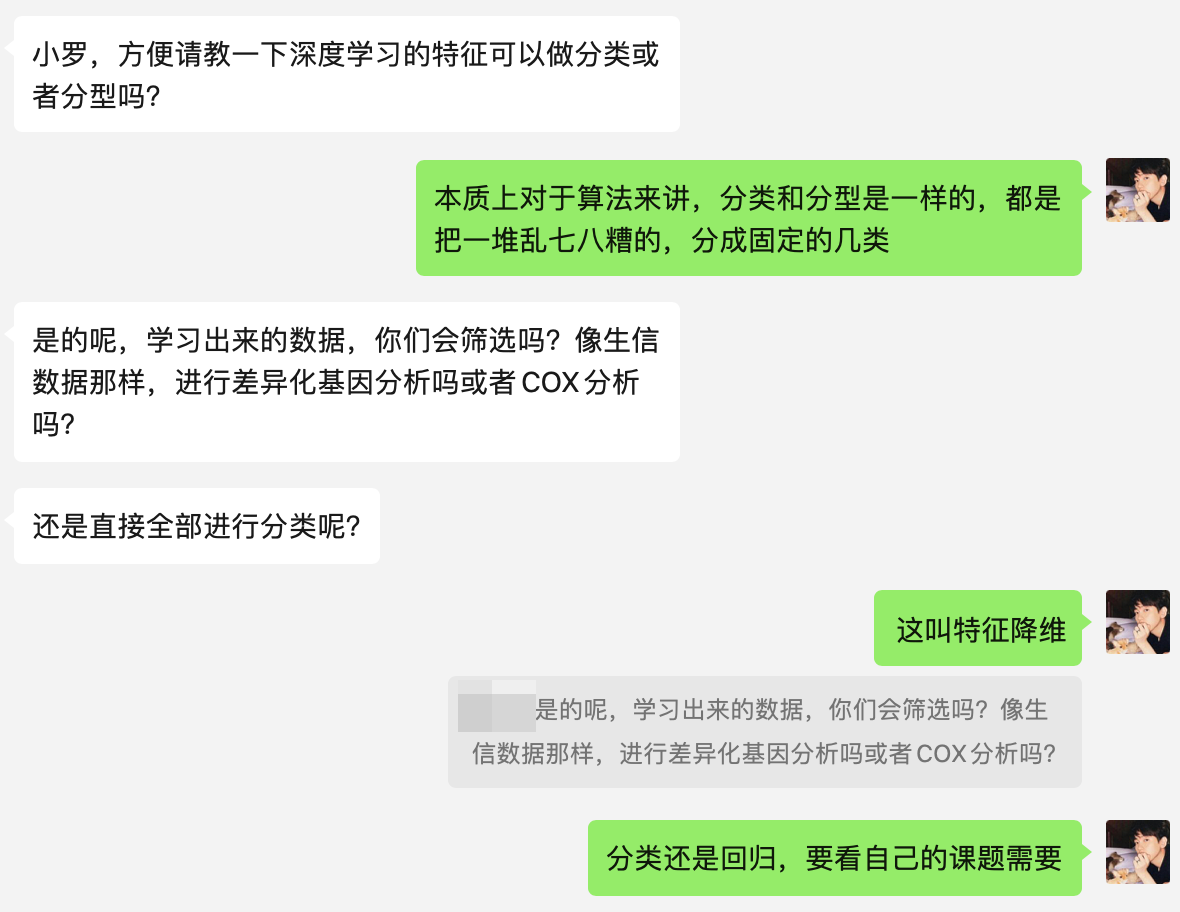
Figure 4 展示了肝内胆管癌(IHC)的组织学分析,特别是胆管类(biliary-class)和肝细胞癌类(HCC-class)的比较。
代表性的H&E染色图像如下:
- HCC类,小导管型(SD-IHC) (A) 展示了具有立方状细胞和小管状腺体相互连接的组织学特征。
- HCC类,大导管型(LD-IHC) (B) 可能偶尔出现小口径腺体的轮廓,但更常见的是含有粘液的柱状细胞质。
- HCC类,不确定形态 © 缺乏区分SD和LD的组织结构特征。
- 胆管类,小导管型(SD-IHC) (D) 与(A)类似,展示了相似的小管状结构和细胞特征。
- 胆管类,大导管型(LD-IHC) (E) 展示了典型的大腺体和柱状上皮细胞,这是大导管型的特征。
- 胆管类,不确定形态 (F) 展示了多边形细胞和不足以确定亚型的腺体形成。
这些图像反映了不同IHC肿瘤的组织学多样性。小导管型(SD-IHC)通常与较小的腺体结构相关,而大导管型(LD-IHC)则与较大的腺体和柱状细胞相关。当肿瘤的组织学特征不足以明确归类为SD-IHC或LD-IHC时,它们被归类为不确定形态。这种分类有助于理解肿瘤的生物学特性,可能影响治疗决策和预后评估。
二、Prov-GigaPath:能够处理包含数十亿像素的全切片图像的全新数字病理基础模型

一作&通讯
| 作者类型 | 姓名 | 单位名称(英文) | 单位名称(中文) |
|---|---|---|---|
| 第一作者 | Hanwen Xu | Microsoft Research | 微软研究院 |
| 第一作者 | Naoto Usuyama | University of Washington | 华盛顿大学 |
| 通讯作者 | Sheng Wang | University of Washington | 华盛顿大学 |
| 通讯作者 | Hoifung Poon | Microsoft Research | 微软研究院 |
文献概述
这篇文章是发表在《Nature》的一篇关于数字病理学领域的研究,介绍了一个名为Prov-GigaPath的全新数字病理基础模型,该模型在大规模真实世界数据上进行了预训练,能够处理包含数十亿像素的全切片图像。
主要内容包括:
-
模型介绍:Prov-GigaPath是一个在1.3亿个256×256病理图像瓦片上预训练的模型,这些图像来自美国大型医疗网络Providence的171,189个全切片,涵盖了超过30,000名患者的31种主要组织类型。
-
技术挑战:数字病理学面临的计算挑战包括处理大规模图像数据,以往的模型常常通过下采样来处理,但这样会丢失重要的全局上下文信息。
-
GigaPath架构:为了预训练Prov-GigaPath,作者提出了GigaPath,这是一种新的视觉变换器架构,适用于预训练千兆像素级别的病理切片。
-
性能评估:Prov-GigaPath在由Providence和TCGA数据组成的数字病理学基准测试中,包括9种癌症亚型任务和17种病理组学任务,表现出色,在26项任务中的25项上达到了最先进的性能。
-
多模态预训练:文章还探讨了Prov-GigaPath在病理报告的视觉-语言预训练方面的潜力,展示了其在标准视觉-语言建模任务中的性能。
-
开放性:Prov-GigaPath是一个开放权重的基础模型,包括源代码和预训练模型权重,以促进数字病理学研究的进展。
-
临床应用潜力:Prov-GigaPath在多种病理学任务上展示了其性能,表明了真实世界数据和全切片建模的重要性,有潜力协助临床诊断和决策支持。
文章还讨论了Prov-GigaPath在突变预测和癌症亚型预测方面的改进,以及在多模态视觉-语言处理方面的应用。作者强调了使用大规模预训练数据和大型模型架构的有效性,并提出了未来工作的方向,包括探索不同大小的模型架构、优化预训练过程以及将高级多模态学习框架整合到他们的工作中。
重点关注
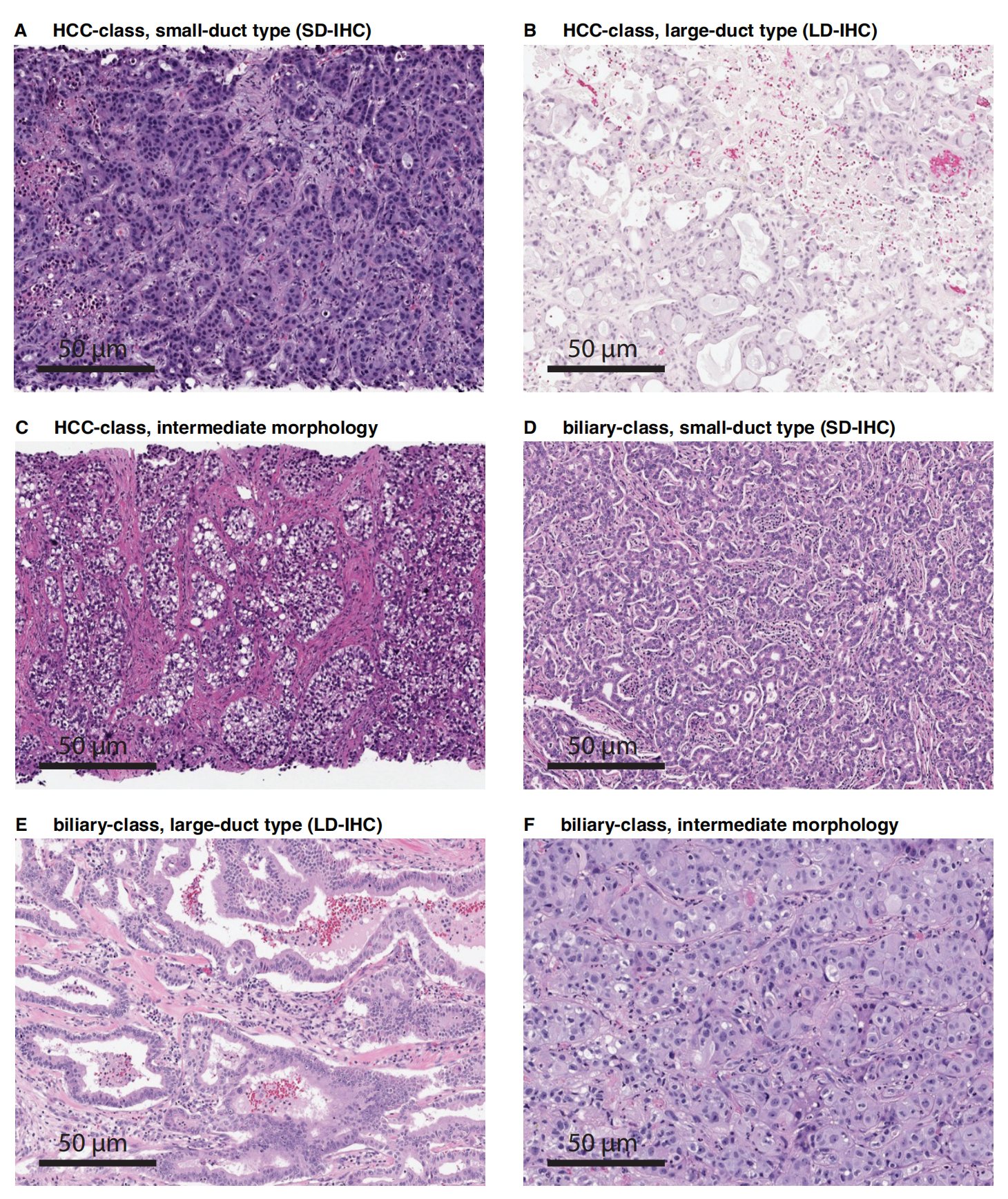
图1提供了Prov-GigaPath模型架构的概览,具体内容可以分为以下几个部分:
a. 模型架构流程图:
- Prov-GigaPath首先将每个输入的全切片图像(Whole Slide Image, WSI)序列化为按行主序排列的256×256像素图像瓦片序列。
- 使用图像瓦片级编码器(tile encoder)将每个图像瓦片转换成视觉嵌入(visual embedding)。
- 接着,Prov-GigaPath应用基于LongNet架构的切片级编码器(slide encoder),生成上下文化的嵌入(contextualized embeddings),这些嵌入可以作为各种下游应用的基础。
b. 图像瓦片级预训练:
- 使用DINOv2框架进行图像瓦片级的自监督预训练。DINOv2是一种先进的图像自监督学习框架,能够学习图像的特征表示。
c. 切片级预训练:
- 使用带有掩码的自编码器(masked autoencoder)和LongNet进行切片级的自监督预训练。LongNet是一种新开发的方法,适用于超长序列建模,能够适应数字病理学的需求。
CLS分类标记:
- 在模型中,CLS标记是分类(classification)的标记,通常用于Transformer模型中的序列分类任务。在训练过程中,这个标记会聚合整个序列的信息,以预测整个切片的标签。
总结 :
Prov-GigaPath模型通过两阶段的预训练过程来学习图像瓦片和切片级别的特征。首先,它将全切片图像分割成小的图像瓦片,并学习每个瓦片的视觉特征。然后,它使用这些瓦片的特征来生成整个切片的上下文嵌入,这些嵌入可以捕捉到切片的全局模式和局部细节,为后续的病理分析任务提供支持。这种设计使得Prov-GigaPath能够有效地处理和分析大规模的病理图像数据,并在多种病理学任务中表现出色。
三、使用人工智能(AI)进行组织病理学图像分析,区分子宫内膜癌的不同分子亚型

一作&通讯
| 作者角色 | 作者姓名 | 单位名称(中文) |
|---|---|---|
| 第一作者 | Amirali Darbandsari | 不列颠哥伦比亚大学电子与计算机工程系 |
| 第一作者(共同) | Hossein Farahani | 不列颠哥伦比亚大学生物医学工程系 |
| 第一作者(共同) | Maryam Asadi | 不列颠哥伦比亚大学生物医学工程系 |
| 通讯作者 | Ali Bashashati | 不列颠哥伦比亚大学生物医学工程系 |
| 通讯作者(共同) | David G. Huntsman | 不列颠哥伦比亚大学病理学与实验室医学系;不列颠哥伦比亚癌症研究协会分子肿瘤学系 |
| 通讯作者(共同) | Naveena Singh | 不列颠哥伦比亚大学病理学与实验室医学系;不列颠哥伦比亚癌症研究协会分子肿瘤学系(注:Naveena Singh已故) |
| 通讯作者(共同) | Jessica N. McAlpine | 不列颠哥伦比亚大学妇产科学系 |
文献概述
这篇文章是关于使用人工智能(AI)进行组织病理学图像分析来区分子宫内膜癌(Endometrial Cancer, EC)的不同分子亚型的研究。
研究团队运用AI技术分析了p53异常(ECs)和无特定分子特征(No Specific Molecular Profile, NSMP)的EC亚型,并识别出一个具有明显较差无进展生存期和疾病特异性生存率的NSMP EC患者亚群,称为"p53abn-like NSMP"。
这项研究在发现队列中的368名患者以及来自其他中心的两个独立验证队列(分别为290和614名患者)中进行了验证。通过对这些患者进行浅层全基因组测序,研究发现"p53abn-like NSMP"组比NSMP组有更高的拷贝数异常负担,表明这一组在生物学上与其他NSMP ECs不同。该研究展示了AI在检测预后不同且传统分子或病理标准难以识别的EC亚群方面的强大能力,从而改进了基于图像的肿瘤分类。
文章还讨论了传统的临床病理参数在分类EC和指导治疗方面的局限性,尤其是在高级别肿瘤中。研究提到,癌症基因组图谱(The Cancer Genome Atlas, TCGA)项目在2013年展示了使用全基因组和外显子组测序可以对EC进行分层。研究团队和其他研究小组基于此发现,开发了一个实用的临床适用的分子分类系统,将ECs分为POLE突变型、错配修复缺陷型、p53异常型和NSMP。这些亚型的分类在临床上具有指导意义,并被世界卫生组织(WHO)推荐整合到EC的标准病理报告中。
此外,文章还详细介绍了AI在处理组织病理学图像方面的技术细节,包括使用深度卷积神经网络(CNN)对肿瘤和非肿瘤区域进行分类,以及使用多种实例学习(Multiple Instance Learning, MIL)模型来区分p53abn和NSMP ECs。研究还探讨了"p53abn-like NSMP"亚型的基因组特征和基因表达谱,以及这一亚型对风险分组分配的潜在影响。
最后,文章讨论了AI在组织病理学图像分析中的应用潜力,以及如何通过AI技术提高对NSMP ECs的分层能力,从而为临床试验和深入的生物学研究提供更精确的患者分层和选择。
重点关注
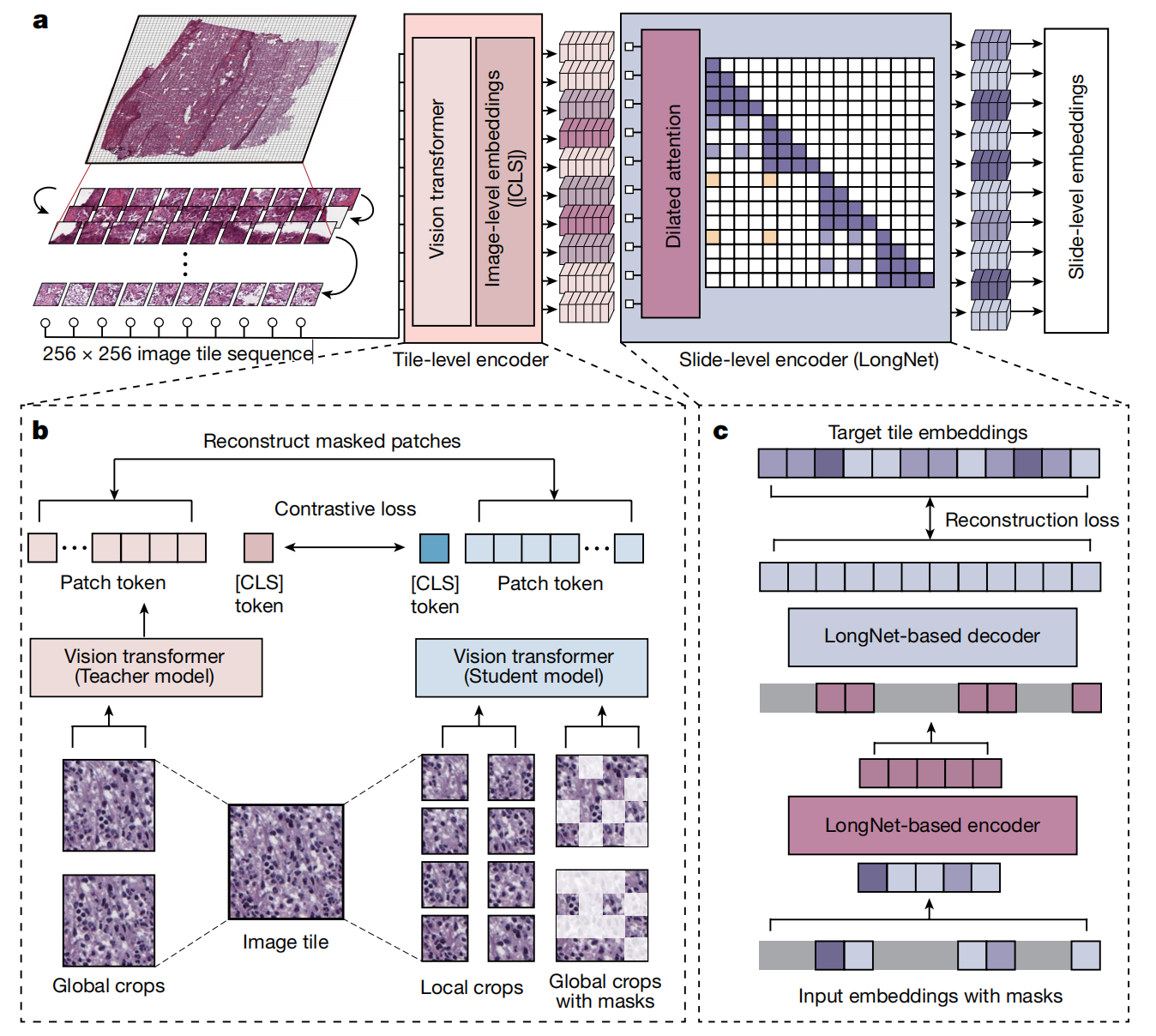
图1展示了基于AI的组织病理学图像分析的工作流程,具体步骤如下:
-
质量控制:首先使用名为HistoQC的质量控制框架来生成一个掩膜,该掩膜仅包含组织区域,并去除图像中的伪影和人为造成的误差。
-
肿瘤区域识别:接着,训练一个AI模型来识别组织病理学切片中的肿瘤区域。这一步是为了在大量的图像数据中定位到含有肿瘤细胞的部分。
-
图像分割:识别出的肿瘤区域的图像被进一步分割成较小的块(patches),这些小块通常大小为512×512像素。
-
颜色归一化:为了消除由于染色过程差异导致的图像颜色变化,对这些小块进行颜色归一化处理,确保不同图像块之间的颜色一致性。
-
深度学习特征提取:将归一化后的图像小块输入到深度学习模型中,以获得每个小块的特征表示。这一步骤是提取图像中有助于分类的特征。
-
多实例学习模型预测:最后,使用基于多实例学习(Multiple Instance Learning, MIL)的VarMIL模型,根据提取的特征来预测患者的亚型。VarMIL模型能够处理整个图像,而不仅仅是单个小块,从而在图像级别上进行更准确的分类。
整个流程是一个从原始的组织病理学图像到最终患者亚型预测的自动化过程,涉及图像预处理、特征提取和模式识别等多个环节,充分展示了AI在医学图像分析领域的应用潜力。
四、BRAIxDet:检测乳腺X光照片中的恶性病变

一作&通讯
| 角色 | 姓名 | 单位名称(中文) |
|---|---|---|
| 第一作者 | Yuanhong Chen | 澳大利亚阿德莱德大学机器学习研究所 |
| 通讯作者 | Chong Wang | 澳大利亚阿德莱德大学机器学习研究所 |
文献概述
这篇文章是关于一种新的医学图像分析方法,即BRAIxDet,它用于检测乳腺X光照片中的恶性病变。
这种方法特别关注处理现实世界中常见的不完全标注数据集,这些数据集中有一部分是完全标注的(包括病变的位置和分类),另一部分则是弱标注的(只有全局分类,没有病变定位)。
BRAIxDet通过一个两阶段的学习策略来解决这个问题:
-
预训练阶段 :使用整个数据集(包括弱标注和未标注的部分)来预训练一个多视角乳腺X光照片分类器,这个分类器基于之前提出的
BRAIxMVCCL模型。 -
半监督学生-教师学习阶段 :将预训练的分类器扩展为一个多视角检测器
BRAIxDet,使用学生-教师学习方法进行训练。学生模型从完全标注和弱标注的数据子集中学习,而教师模型则基于学生模型参数的指数移动平均值(EMA)进行训练。
文章通过在两个现实世界的乳腺X光照片数据集 上进行广泛的检测实验,展示了BRAIxDet在不完全标注的情况下,检测恶性乳腺病变方面达到了最先进的结果。此外,文章还探讨了相关的研究工作,包括在乳腺X光照片中检测病变的方法、弱监督对象检测和半监督对象检测的策略,以及医学图像分析中的预训练方法。
作者强调,BRAIxDet模型在检测乳腺病变时,即使在完全标注数据较少的情况下,也能保持较高的性能,这表明该方法在处理不同程度缺失数据的现实世界数据集时,比其他方法更有效。最后,文章指出了BRAIxDet的一些局限性,并提出了未来改进模型性能的潜在方向。
重点关注
Fig. 3 描述的是 BRAIxDet 模型的结构和工作流程,该模型用于处理两个乳腺X光图像视角(主视图和辅助视图),并从中提取特征以进行病变检测。
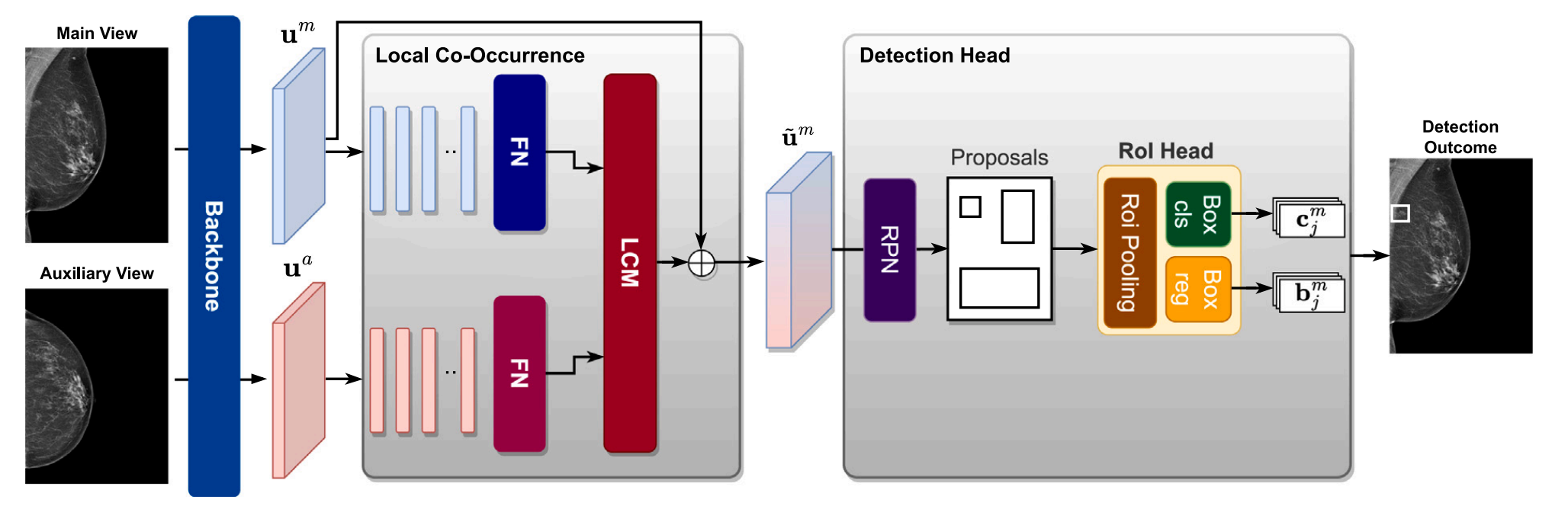
-
特征提取 :BRAIxDet 使用一个主干模型(backbone model)来从主视图(main view)和辅助视图(auxiliary view)中提取特征,分别表示为 ( u m \mathbf{u}^m um ) 和 ( \\mathbf{u}\^a )。
-
局部共生模块(Local Co-occurrence Module, LCM):
- 该模块负责模拟两个视图在局部区域的语义关系。
- 它输出跨视图特征 ( u ~ m \tilde{\mathbf{u}}^m u~m ),这是通过结合主视图和辅助视图的特征来实现的。
-
检测模块:
- 检测模块输出病变的分类结果 ( {c_{mj}} ) 和边界框预测 ( {b_{mj}} ),其中 ( j ) 表示第 ( j ) 个病变区域,( \|{\\cal N}_m\| ) 表示主视图中检测到的病变数量。
-
全连接层(FN):通常指在卷积神经网络的末尾使用的全连接神经层,用于分类或回归任务。
-
拼接操作(⊕):表示特征图的拼接操作,通常用于合并不同来源的特征图,以增加网络的表征能力。
-
区域提议网络(Region Proposal Network, RPN):
- RPN 是一种用于目标检测的网络结构,用于生成候选的区域(region proposals),这些区域可能包含目标对象。
- 在 BRAIxDet 中,RPN 负责在主视图和辅助视图的特征图上生成潜在的病变区域。
Fig. 3 中的描述强调了 BRAIxDet 模型如何通过结合两个不同视图的信息来提高病变检测的准确性。局部共生模块和检测模块是 BRAIxDet 的关键组成部分,它们共同工作以实现对乳腺X光图像中恶性病变的检测和分类。
五、基于拉曼光谱的机器学习平台,从组织切片中预测胶质瘤的不同亚型

一作&通讯
| 作者类型 | 作者姓名 | 单位名称(英文) | 单位名称(中文) |
|---|---|---|---|
| 第一作者 | Adrian Lita | National Cancer Institute, National Institutes of Health | 美国国立卫生研究院国家癌症研究所 |
| 通讯作者 | Mioara Larion | National Cancer Institute, National Institutes of Health | 美国国立卫生研究院国家癌症研究所 |
| 通讯作者 | Ion Petre | University of Turku, Department of Mathematics and Statistics | 芬兰图尔库大学数学与统计系 |
文献概述
这篇文章介绍了一个名为APOLLO(rAman-based PathOLogy of maLignant glioma)的基于拉曼光谱的机器学习平台,它能够从甲醛固定、石蜡包埋(FFPE)的组织切片中预测胶质瘤的不同亚型。
APOLLO平台通过使用自发拉曼光谱对46位已知甲基化亚型的患者的FFPE组织样本进行分子指纹鉴定,并构建了区分肿瘤/非肿瘤、IDH1野生型/IDH1突变型以及甲基化亚型的分类器。
研究使用了支持向量机和随机森林算法来识别最具区分性的拉曼频率,并利用受激拉曼光谱进行验证,同时使用胶质瘤细胞系的质谱分析和TCGA数据库来验证生物学发现。
APOLLO平台的主要发现包括:
- 能够区分肿瘤和非肿瘤组织,并识别在肿瘤中更强烈的DNA和蛋白质对应的新型拉曼峰。
- 能够区分IDH1突变型(IDH1mut)和野生型(IDH1WT)肿瘤,并发现IDH1mut胶质瘤中胆固醇酯水平高度丰富。
- 在IDH1mut类型内部,能够区分G-CIMP高和G-CIMP低的分子表型,这对于临床治疗具有重要意义。
文章强调,APOLLO平台展示了无需标记的拉曼光谱学从FFPE切片中分类胶质瘤亚型并提取有意义的生物学信息的潜力,为未来在生物库中存储的这些组织上的应用以及其他癌症的研究开辟了新的道路。
研究的重要性在于开发了一个自动化流程,能够使用未修改的FFPE组织切片、自发拉曼光谱和机器学习来识别不同胶质瘤亚型之间的生化差异。APOLLO识别了拉曼光谱中的信号,这些信号可以区分肿瘤组织和非肿瘤组织,以及IDH1WT与IDH1mut肿瘤,还有IDH1mut亚型内部的G-CIMP-high与G-CIMP-low。
这项研究展示了使用未经处理的FFPE组织以及APOLLO在识别IDH1mut与IDH1WT胶质瘤中不同改变的脂质途径方面的效用。重要的是,相同的切片可以以多重方式用于其他下游应用。APOLLO为存储在生物库中的组织的代谢和生化研究提供了新的途径,并且可以扩展到任何FFPE组织或分类类型。
重点关注
Figure 1 提供了APOLLO研究设计的概览,可以分为三个主要部分:
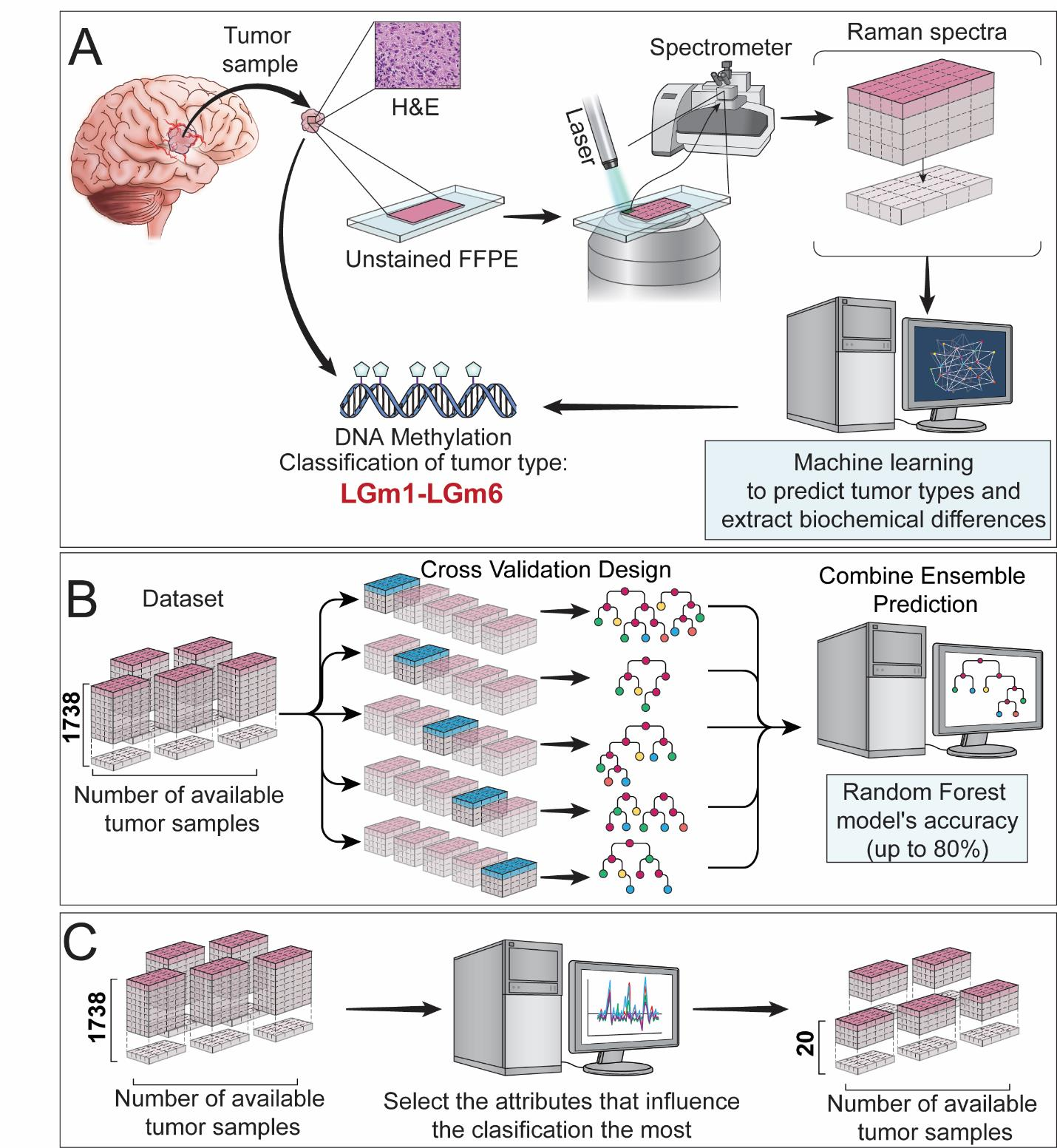
A. 研究设计:
- 对FFPE(甲醛固定、石蜡包埋)的相邻切片进行H&E(苏木精-伊红)染色,以确认感兴趣区域中的肿瘤。
- 确认甲基化亚型。
- 使用自发拉曼光谱分析样本。
B. 机器学习训练设计:
- 数据集由每个肿瘤斑点的拉曼光谱及其甲基化标签(IDH1突变型或野生型,LGm1或LGm2)组成。
- 由于数据通常不平衡,即一个类别的样本数量远多于另一个类别,研究者将数据分割成五个不相交的数据集,以准备进行5折交叉验证训练机器学习模型。
- 为了避免数据泄露,采用了肿瘤分层方法:一个样本的所有斑点都贡献给一个子集。
- 每个子集的数据分布大致遵循整个数据集的分布。
- 运行5折交叉验证,训练5个独立的随机森林模型,每个子集轮流作为验证集,其他四个作为训练集。
- 五个独立的随机森林模型的预测结果被合并为最终的随机森林模型。
C. 模型增强:
- 进一步通过在20个最重要的拉曼频率上训练支持向量分类器来增强模型。
分析:
- 目的性:研究设计具有明确的目的,即通过拉曼光谱分析来区分不同类型的胶质瘤。
- 数据预处理:包括去除噪声和基线校正,确保数据质量。
- 机器学习策略:采用交叉验证和随机森林模型来提高预测的准确性和泛化能力。
- 数据不平衡处理:通过分层抽样和过采样技术来处理类别不平衡问题。
- 特征选择:使用统计测试(ANOVA和Chi2)和随机森林模型来识别最重要的拉曼频率,这些频率对于区分肿瘤亚型至关重要。
- 模型融合:通过结合多个模型的预测来提高最终模型的性能和鲁棒性。
- 模型优化:在随机森林模型的基础上,进一步使用支持向量机对关键特征进行建模,以增强模型的分类能力。
Figure 1 展示了一个全面且系统的研究方法,从样本准备到数据分析,再到机器学习模型的训练和优化,每一步都旨在提高结果的准确性和可靠性。
六、基于互学习变换器的无监督全切片图像分类方法

一作&通讯
| 作者角色 | 姓名 | 单位名称(英文) | 单位名称(中文) |
|---|---|---|---|
| 第一作者 | Sajid Javed | Department of Computer Science, Khalifa University of Science and Technology, Abu Dhabi, P.O. Box 127788, United Arab Emirates | 哈利法科技大学计算机科学系,阿布扎比,阿拉伯联合酋长国 |
| 通讯作者 | Naoufel Werghi | Department of Computer Science, Khalifa University of Science and Technology, Abu Dhabi, P.O. Box 127788, United Arab Emirates | 哈利法科技大学计算机科学系,阿布扎比,阿拉伯联合酋长国 |
文献概述
这篇文章是关于一种新型的无监督学习算法,即基于互学习变换器(Unsupervised Mutual Transformer Learning, UMTL)的超高画质像素的全切片图像(Whole Slide Images, WSIs)分类方法。
该算法由Sajid Javed、Arif Mahmood、Talha Qaiser、Naoufel Werghi和Nasir Rajpoot等人共同开发,旨在提高计算病理学领域中对吉像素级WSIs分类的准确性,这在癌症检测和细胞突变预测等临床应用中非常重要。
文章首先指出,大多数现有的深度学习方法需要专家病理学家进行昂贵且耗时的手动注释。为了解决这个问题,研究者们提出了一种基于变换器的伪标签生成器和清洁器的全无监督WSI分类算法。该算法利用从WSIs中提取的实例(即图像块)在潜在空间的转换和逆变换,通过变换损失生成伪标签,并通过变换器标签清洁器进行清理。伪标签生成器和清洁器模块在无监督的方式下相互迭代训练,引入了一种提高正常与癌细胞实例标记能力的判别学习机制。
文章详细介绍了算法的四个主要部分:
- 特征提取
- 变换器伪标签生成器(TPLG)
- 变换器伪标签清洁器(TLC)
- 判别学习机制和实例级标签平滑处理
研究者们还在四个公开可用的数据集上进行了广泛的实验,结果显示所提出的算法在WSI分类性能上优于现有的最先进方法。
此外,文章还讨论了在弱监督设置下对UMTL算法进行训练(称为W-UMTL),以及如何使用下游分析任务(称为D-UMTL)对癌症亚型进行分类。在这些实验中,所提出的算法一致地超越了现有的最先进方法。
最后,文章总结了主要贡献,并讨论了未来的研究方向,例如使用所提出的算法进行生存预测等临床任务。
重点关注
图 1 展示了用于全切片图像(WSI)分类任务的不同类型的监督方法之间的比较。
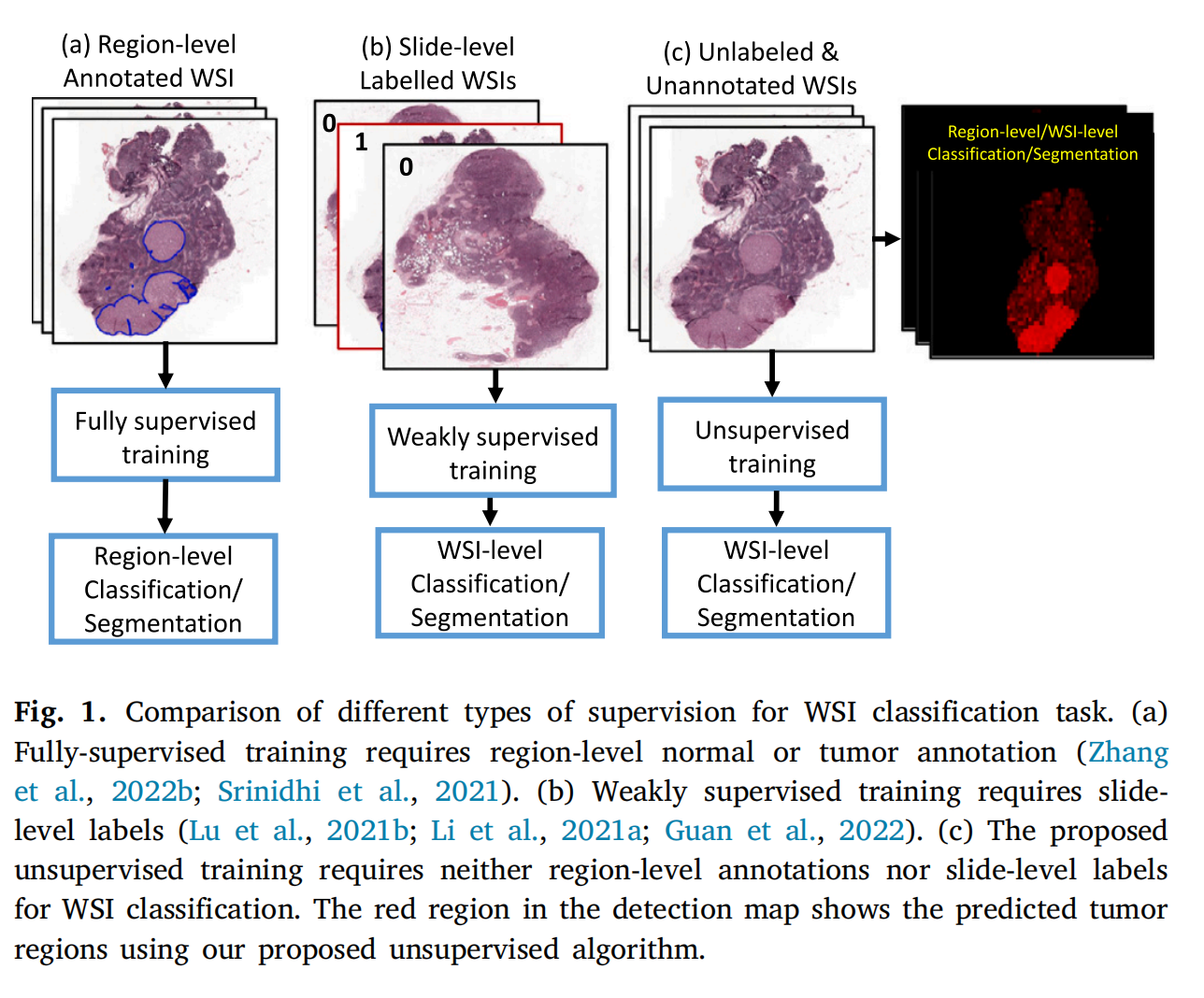
(a) 全监督训练:此方法要求在区域级别上进行正常或肿瘤的标注。这意味着需要专家精确地标记出图像中每个感兴趣区域(ROI)是正常细胞还是癌细胞。这种类型的标注是详尽且耗时的,因为它涉及到对WSI中可能数百万个细胞的逐个检查。引用了Zhang等人(2022b)和Srinidhi等人(2021)的工作,这些研究可能使用了类似的全监督方法。
(b) 弱监督训练:此方法需要在切片级别上的标签。这比全监督训练的区域级别标注要少一些工作量,因为只需要对整个WSI分配一个标签,表明它是否包含肿瘤。然而,这仍然需要专家对每个WSI进行审查以确定其标签。Lu等人(2021b)、Li等人(2021a)和Guan等人(2022)的研究可能采用了这种方法。
© 提出的无监督训练:与上述两种方法不同,提出的无监督学习方法不需要任何形式的标注------无论是区域级别的详细标注还是切片级别的简单标签。该方法能够自动预测WSI中的肿瘤区域,如图中的红色区域所示,这是使用新算法预测出的肿瘤区域。
无监督训练的优势在于,它消除了获取专家标注的成本,使得分类系统可以在没有人类干预的情况下部署。这对于提升病理图像分析的效率和可扩展性具有重要意义,尤其是在资源有限或专家病理学家时间宝贵的情况下。此外,无监督方法可能有助于减少因标注错误而引起的模型性能问题,提高模型的泛化能力。