自从OpenAI的ChatGPT横空出世以来,国内外各类大语言模型(LLM)层出不穷,其中不乏Google的Gemini、Claude、文心一言等等。相较于竞争激烈的商业模型赛道,以Llama为代表的开源大模型的进步速度也十分惊人。
伴随着大语言模型的百花齐放,如何评价一个模型的各项指标与综合能力成了新的问题,其中大规模多任务语言理解(MMLU-Massive Multitask Language Understanding)是评估语言模型能力最常用和权威的基准之一,它由约 16,000 个多项选择题组成,涵盖数学、哲学、法律和医学等 57 个学科。
在最新的以MMLU为基准的大语言模型排行榜上,国产的开源大模型通义千问Qwen2和零一万物Yi-Large在与Claude3、ChatGPT4o、Gemini等商业模型的竞争中不遑多让,名列前茅。
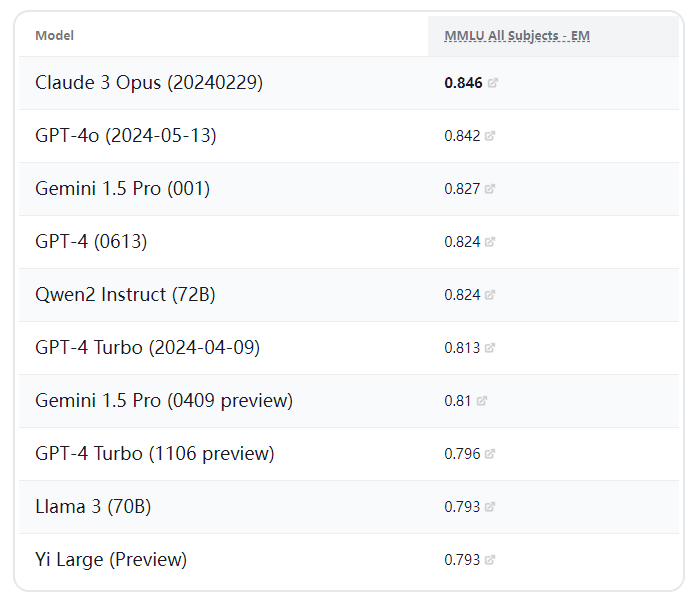
通常情况下我们都是在线使用大语言模型,难免会遇到网络不便、账号受限等问题,既然国产开源大模型已经有了如此强大的性能,能否将其部署在本地来使用呢?
答案是可以的,而且对计算机配置的需求比各位想象的低很多。
本地大模型框架ollama介绍
既然想要在本地计算机或服务器配置大模型,就不得不提到一个神器 --- Ollama
Ollama是一个开源框架,专门设计用于在本地运行大型语言模型。 它的主要特点是将模型权重、配置和数据捆绑到一个包中,从而优化了设置和配置细节,包括GPU使用情况,简化了在本地运行大型模型的过程。
Ollama一开始仅支持macOS和Linux操作系统,近期也推出了支持Windows系统的预览版。
这里以Windows系统为例,首先在官网或GitHub下载并安装Ollama,注意系统版本要求Windows 10及以上
下载完成后进行安装
ollama没有GUI,安装完成后需要在PowerShell或命令行进行使用。
在PowerShell运行命令:ollama help将显示 Ollama 中的可用命令。
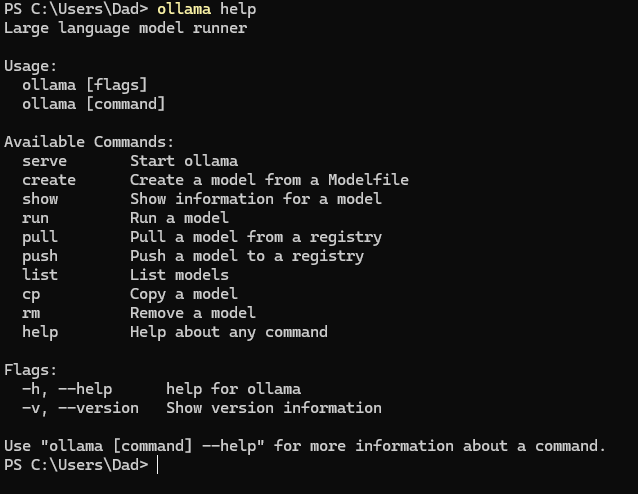
通过输入"ollama + 可用命令"即可对ollama进行操作,例如:
ollama list:显示模型列表。ollama show:显示模型的信息ollama pull:拉取模型ollama push:推送模型ollama cp:拷贝一个模型ollama rm:删除一个模型ollama run:运行一个模型
安装并运行本地模型
完成ollama的安装并熟悉了基本操作后,可以开始安装所需的模型了。
在ollama官方网站的模型页面可以浏览支持的开源模型列表。
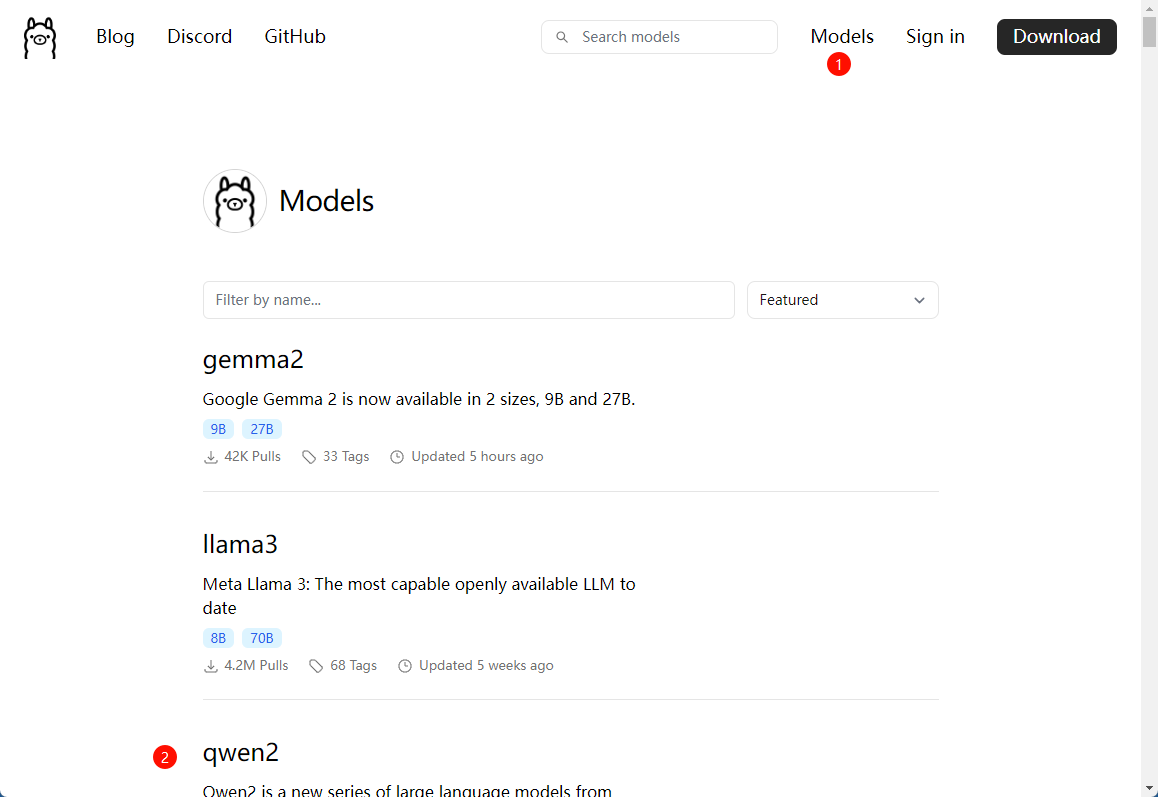
这里选择国产qwen2模型,ollama支持0.5b、1.5b、7b、72b四种参数规模(b即billion,十亿参数量),可根据个人硬件配置与存储空间进行选择,经过实测,拥有NVidia独显的笔记本电脑完全可以跑的动7b模型。
硬件需求:
- RAM: 7B模型推荐16GB,70B需要64GB或更多。
- GPU: 具有至少8GB 显存的GPU,最好是支持CUDA的NVIDIA GPU。
在下图标记1出选择对应参数的模型,标记2处会自动切换至该模型的安装命令,复制命令并在PowerShell中运行即可进行下载安装。
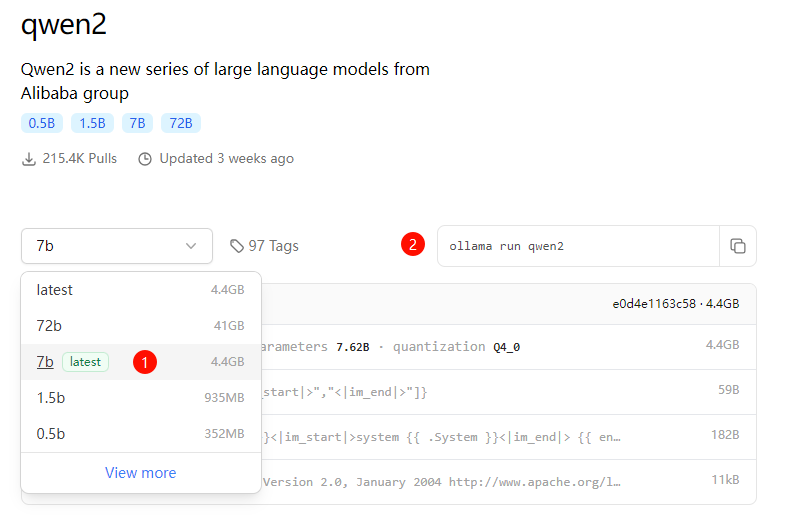
这里选择安装qwen2:7b模型。
模型文件的保存路径为:
C:\Users\"你的用户名"\.ollama\models\安装完成后即可进行对话。
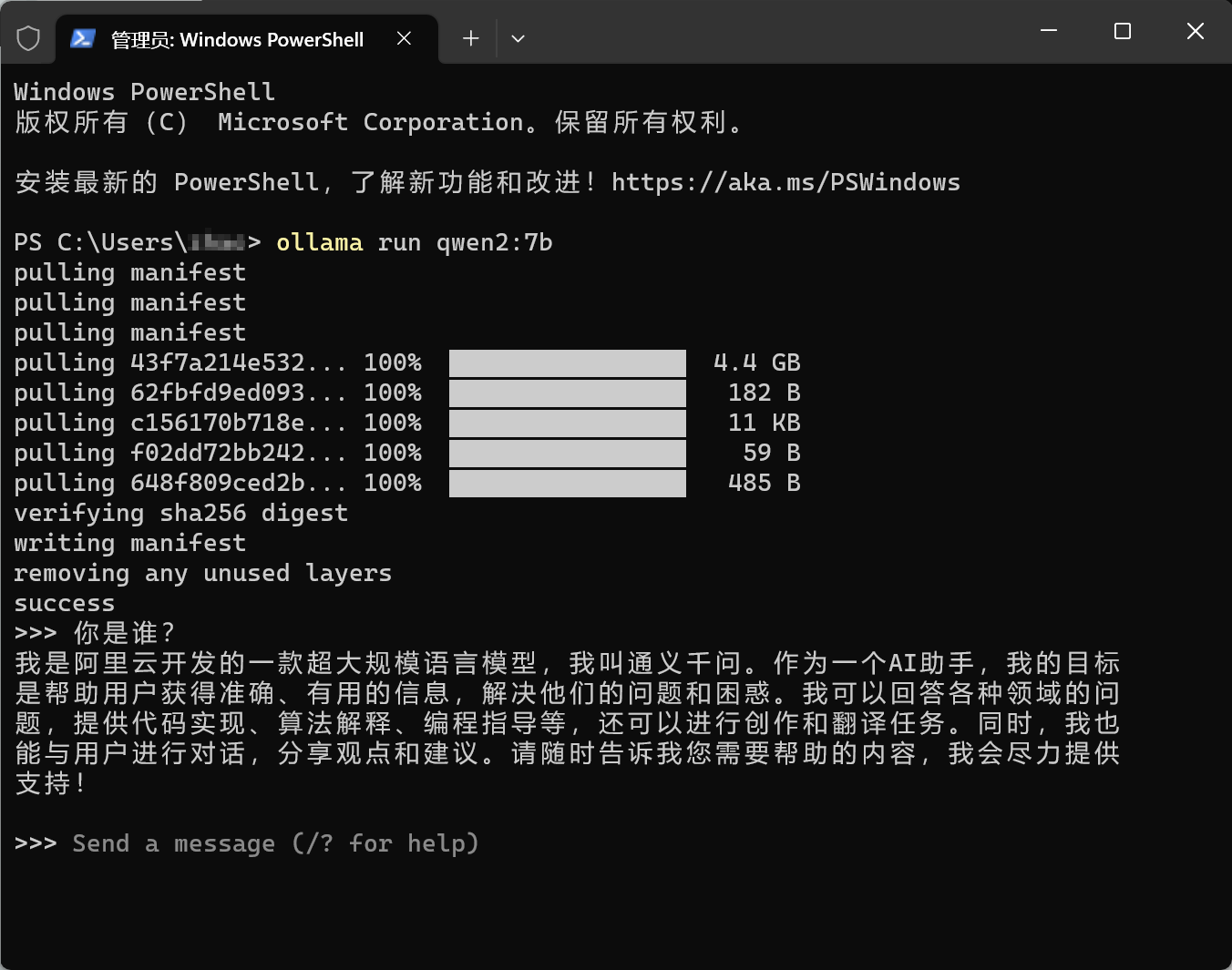
在每次使用前请先确认ollama服务已经开启,可在开始菜单启动ollama或创建快捷方式,ollama启动后会在系统任务栏显示图标。
接着在PowerShell通过ollama run qwen2启动模型。
进阶使用方法
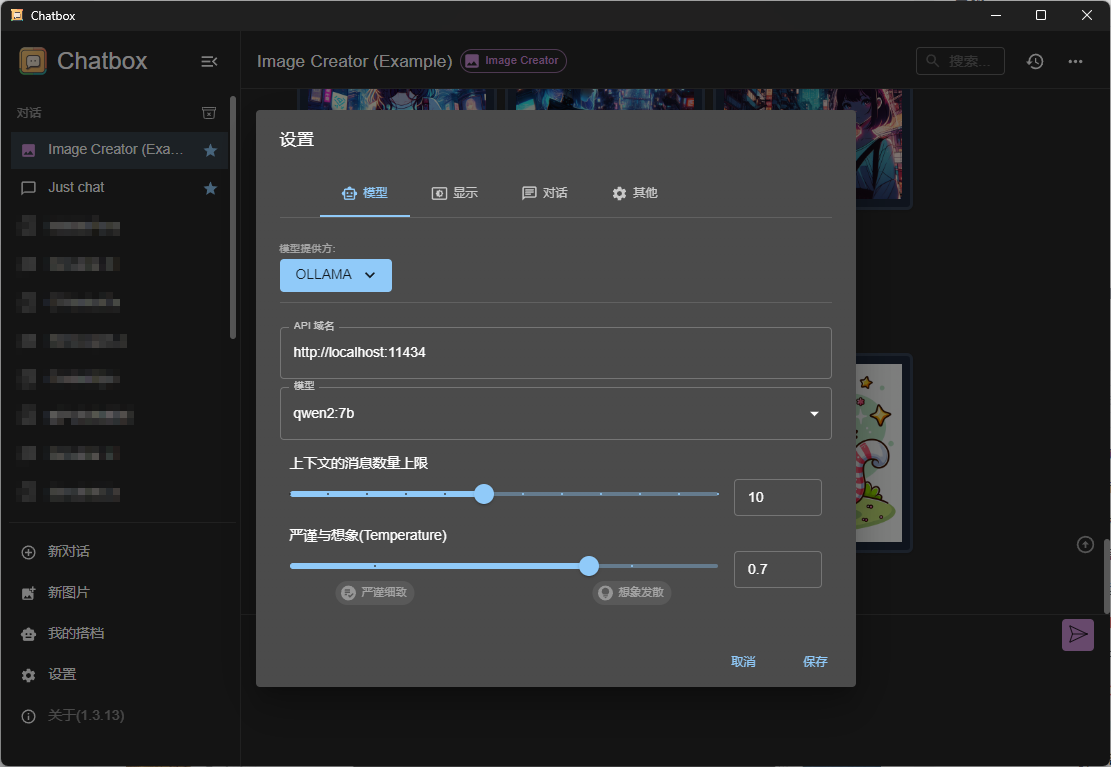
很显然,通过PowerShell与本地大模型进行对话不是那么的方便,ollama支持很多桌面客户端通过端口进行调用,其默认使用11434端口,可通过 http://localhost:11434 访问。
聊天对话推荐使用chatbox,可实现无需部署,开箱即用,内置大量prompt可以最大程度的发挥模型的能力。
翻译、润色、总结等功能推荐使用OpenAI Translator,其最初是ChatGPT API 的划词翻译浏览器插件和跨平台桌面端应用,但目前同样支持ollama的本地模型。

总结
ollama不仅可以让我们在本地随时随地使用大语言模型不受网络、账户等限制,同时可以利用ollama提供的api接口开发基于各类大语言模型的应用与服务,并且ollama支持安装多个模型,方便我们进行对比和使用。
ollama的特点可以总结为:
- 开源:开源推动项目的持续发展。
- 开箱即用:一条命令的方式,简化了大量的工作,降低了门槛。
- 可扩展:可以和很多工具进行集成使用,有更多的玩法。
- 轻量化:不需要太多的资源,个人电脑完全可以胜任。